Model Robustness: Building Reliable AI Models

ML Lead at Encord
Today, organizations are increasingly deploying artificial intelligence (AI) systems in highly sensitive and critical domains, such as medical diagnosis, autonomous driving, and cybersecurity.
Reliance on AI models to perform vital tasks has opened up the possibility of large-scale failure with damaging consequences, such as in the event of malicious attacks or compromised infrastructure.
AI incidents are growing significantly, reportedly averaging 79 incidents yearly from 2020 to 2023. For instance, Tessa, a healthcare chatbot, reportedly gave harmful advice to people with eating disorders; Tesla’s autonomous car did not recognize a pedestrian on the crosswalk; and Clearview AI’s security system wrongly identified an innocent person as a criminal.
These disasters question the efficacy of AI systems and call for developing robust models resistant to vulnerabilities.
So, what is model robustness in AI? And how can AI practitioners ensure that a model is robust? In this article, you will:
- Understand the significance of robustness in AI applications,
- Learn about the challenges of building robustness into AI systems,
- Learn how Encord Active can help improve the robustness of your ML models.
What is Model Robustness?
Model robustness is a machine-learning (ML) model’s ability to withstand uncertainties and perform accurately in different contexts. A model is robust if it performs strongly on datasets that differ from the training data.
For instance, in advanced computer vision (CV) and large language models (LLMs), robustness ensures reliable predictions on unseen textual and image data generated from diverse sources. Real-world images can be blurry, distorted, noisy, etc., interfering with a CV model’s prediction performance and causing fatal accidents in safety-critical applications such as self-driving cars and medical diagnosis. Achieving robustness in such models will help mitigate these issues.
However, robustness may not always lead to high accuracy, as accuracy is usually calculated based on how well the model fits on a validation dataset. This means a highly accurate model may not generalize well to entirely new data that was not present in the validation set. The diagram below illustrates the point.
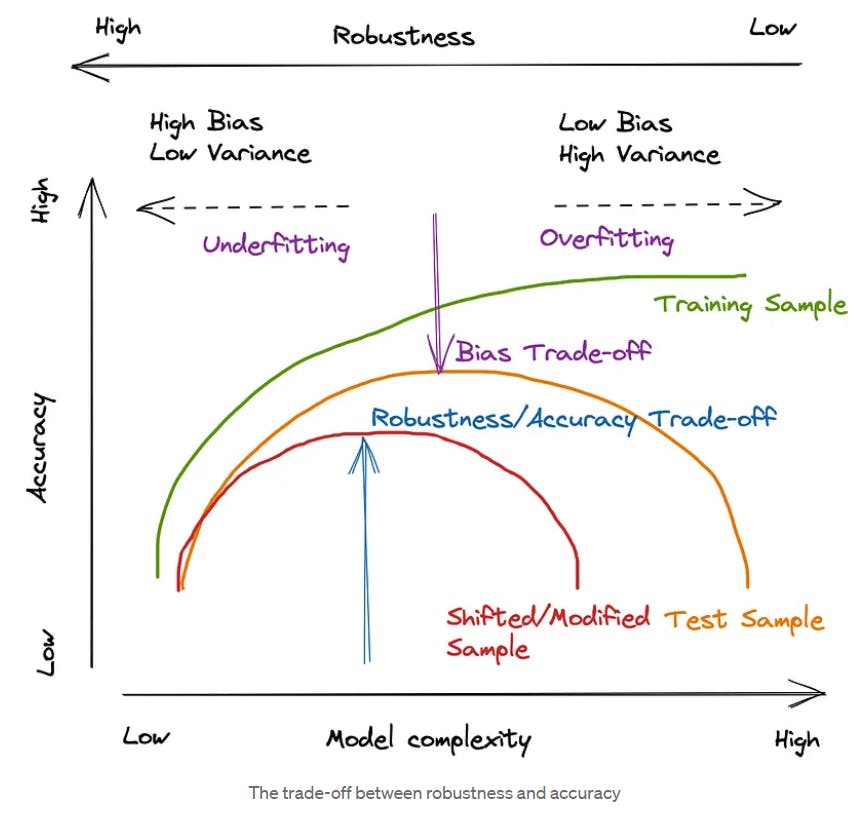
Optimizing a model for robustness may imply lower accuracy and model complexity than required in the case of optimizing for low variance. That’s because robustness aims to create a model that can perform well on novel data distributions that significantly differ from test data.
Significance of Model Robustness
Ensuring model robustness is necessary as we increase our reliance on AI models to perform critical jobs. Below are a few reasons why model robustness is crucial in today’s highly digitalized world.
- Reduces sensitivity to outliers: Outliers can adversely affect the performance of algorithms like regression, decision trees, k-nearest neighbors, etc. Ensuring model robustness will make these models less sensitive to outliers and improve generalization performance.
- Protects models against malicious attacks: Adversarial attacks distort input data, forcing the model to make wrong predictions. For instance, an attacker can change specific images to trick the model into making a classification error. Robustness allows you to build models that can resist such attacks.
- Fairness: Robustness requires training models on representative datasets without bias. This means robust models generate fairer predictions and perform well on data that may contain inherent biases.
- Increases trust: Multiple domains, such as self-driving cars, security, medical diagnosis, business decision-making, etc., rely on AI to perform mission and safety-critical tasks. Robustness is essential in these areas to maintain high model performance by eliminating the chance of harmful errors.
- Reduces cost of retraining models: In robust models, data variations (distribution shifts) have minimal effect on performance. Hence, retraining is less frequent, reducing the computational resource load required to collect, preprocess, and train new data.
- Improves regulatory compliance: As data security and AI fairness laws become more stringent, data science teams must ensure regulatory compliance to avoid costly fines. Robust models are helpful as they mitigate the effects of adversarial attacks by maintaining stable performance when faced with attempts to exploit model vulnerabilities and perform optimally on new data, reducing data collection needs and the chances of a data breach.
Now that we understand the importance of model robustness, let’s explore how you can achieve it in your ML pipelines.
How to Achieve Model Robustness?
Making machine learning models robust involves several techniques to ensure strong performance on unseen data for diverse use cases. The following section discusses the factors that contribute significantly to achieving model robustness.
Data Quality
High data quality enables efficient model training by ensuring the data is clean, diverse, consistent, and accurate. As such, models can quickly learn underlying data patterns and perform well on unseen samples without exhibiting bias, leading to higher robustness.
Automated data pipelines are necessary to improve data quality as they help with data preprocessing to bring raw data into a usable format. The pipelines can include statistical checks to assess diversity and ensure the training data’s representativeness of the real-world population.
Moreover, data augmentation, which artificially increases the training set by modifying input samples in a particular way, can also help reduce model overfitting. The illustration below shows how augmentation works in CV.
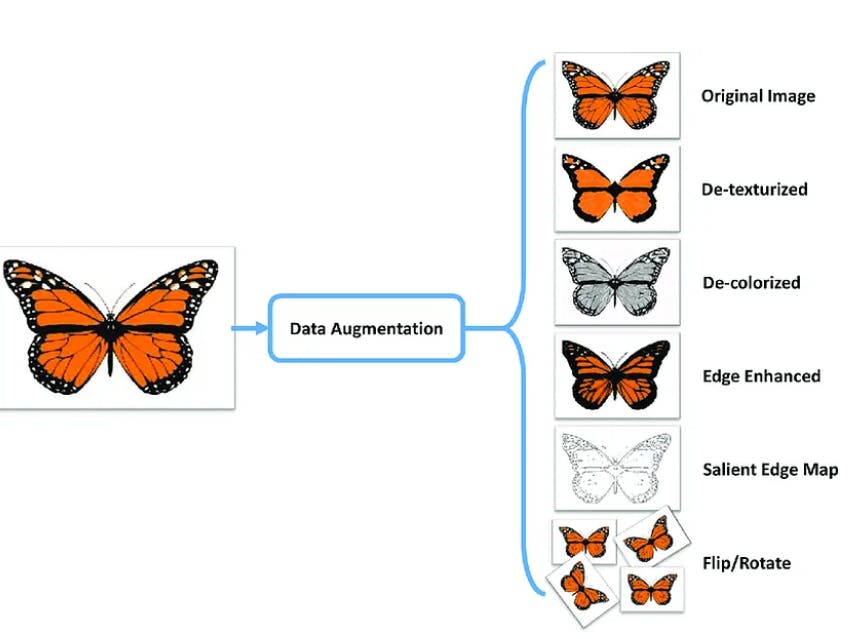
Lastly, the pipeline must include a vigorous data annotation process, as model performance relies heavily on label quality. Labeling errors can cause the model to generate incorrect predictions and become vulnerable to adversarial attacks.
A clear annotation strategy with detailed guidelines and a thorough review process by domain experts can help improve the labeling workflow. Using active learning and consensus-based approaches such as majority voting can also boost quality by ensuring consistent labels across samples.
Adversarial Training
Adversarial robustness makes a model resistant to adversarial attacks. Such attacks often involve small perturbations to input data, causing the model to generate incorrect output. The attacker aims to steal or copy the model by understanding its inner workings.
Types of Adversarial Attacks
Adversarial attacks consist of multiple methodologies, such as:
- Evasion attacks involve perturbing inputs to cause incorrect model predictions. For instance, the fast gradient sign method (FGSM) is a popular perturbation technique that adds the sign of the loss function’s gradient to modify an input instance.
- Poisoning attacks occur when an adversary directly manipulates the input by changing labels or injecting harmful data into the training set.
- Model inversion attacks aim to reconstruct the training data samples using a target classifier. Such attacks can cause serious privacy breaches as attackers can discover sensitive data samples for training a particular model.
- Model extraction attacks occur when adversaries query a model’s Application Programming Interface (API) to collect output samples to create a synthetic dataset. The adversary can use the fake dataset to train another model that copies the functionality of the original learning algorithms.
Let’s explore some prominent techniques to prevent these adversarial attacks.
Robustness and Model Security
AI practitioners can use various techniques to prevent adversarial attacks and make models more robust. The following are a few options.
- Adversarial training: This method involves training models on adversarial examples to prevent evasion attacks.
- Gradient masking: Building ML models that do not rely on gradients, such as k-nearest neighbors, can prevent attacks that use gradients to perturb inputs.
- Data cleaning: This simple technique helps prevent poisoning attacks by ensuring that training data does not contain malicious examples or samples with incorrect labels.
- Outlier detection: Identifying and removing outliers can also help make models robust to poisoning attacks.
- Differential privacy: The techniques involved in differential privacy add noise to data during model training, making it challenging for an attacker to extract information regarding a specific individual.
- Data encryption: Techniques like homomorphic encryption allow you to train models on encrypted data and prevent breaches.
- Output perturbation: You can avoid data leakage by adding noise to a deep learning model’s output.
- Watermarking: You can add outliers to your data by including watermarks in your input data. The model overfits these outliers, allowing you to identify your model’s replica.

Domain Adaptation
With domain adaptation, you can tailor a model to perform well on a target domain with limited labeled data, using knowledge from another source domain with sufficient data.
For instance, you can have a classifier model that correctly classifies land animal images (source domain). However, you can use domain adaptation techniques to fine-tune the model, so it also classifies marine animals (target domain).
This way, you can improve the model’s generalization performance for new classes to increase its robustness.
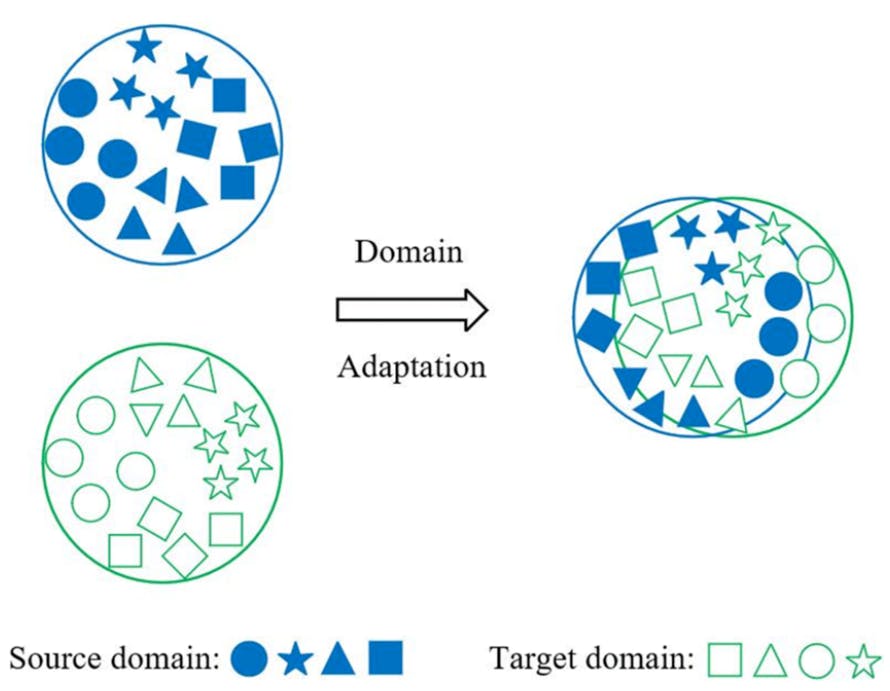
Domain Adaptation Illustration
Moreover, domain adaptation techniques make your model robust to domain shifts that occur when underlying data distributions change. For instance, differences between training and validation sets indicate a domain shift.
You can broadly categorize domain adaptation as follows:
- Supervised, semi-supervised, and unsupervised domain adaptation: In supervised domain adaptation, the data in the target domain is completely labeled. In semi-supervised domain adaptation, only a few data samples have labels, while in unsupervised domain adaptation, no labels exist in the target domain.
- Heterogenous and homogenous domain adaptation: In heterogeneous domain adaptation, the target and source feature spaces are different, while they are the same in homogeneous domain adaptation.
- One-step and multi-step domain adaptation: In one-step domain adaptation, you can directly transfer the knowledge from the source to the target domain due to the similarity between the two. However, you introduce additional knowledge transfer steps in multi-step adaptation to smoothen the transition process. Multi-step techniques help when target and source domains differ significantly.
Lastly, domain adaptation techniques include feature-based learning, where deep learning models learn invariable underlying domain features and use the knowledge to make predictions on the target domain. Other methods involve mapping the source domain to the target domain using generative adversarial networks (GANs). The technique works by learning to map a source image to another domain using a target domain label.
Regularization
Regularization helps prevent your model from overfitting and makes it more robust by reducing the generalization error.
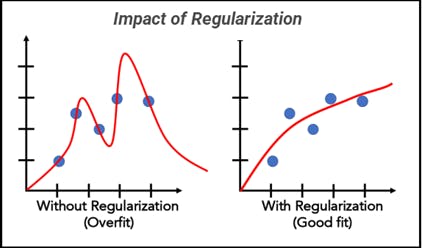
The Effect of Regularization on the Model
Common regularization techniques include:
- Ridge regression: In ridge regression, you add a penalty to the loss function that equals the sum of the squares of the weights.
- Lasso regression: In lasso regression, the penalty term is the sum of the absolute value of all the weights.
- Entropy: The penalty term equals the entropy of the output distribution.
- Dropout: You can use the dropout technique in neural networks to randomly turn off or drop layers and nodes to reduce model complexity and improve generalization.
Explainability
Explainable AI (XAI) is a recent concept that allows you to understand how a machine learning system behaves and enhances model interpretability.
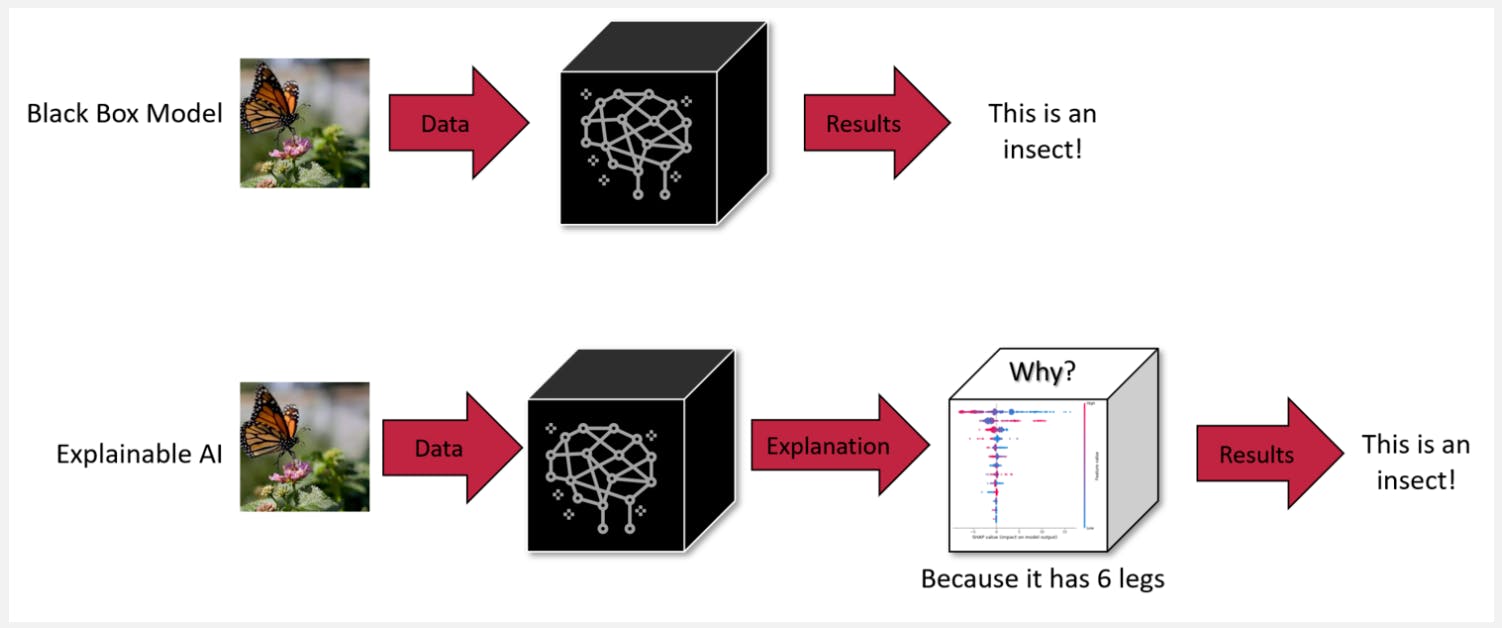
Explainable Model vs. Black Box Model Illustration
XAI techniques help make a model robust by allowing you to see the inner workings of a model and identify and fix any biases in the model’s decision-making process.
XAI includes the following techniques:
- SHAP: Shapley Additive Explanations (SHAP) is a technique that computes Shapley values for features to represent their importance in a particular prediction.
- LIME: Local interpretable model-agnostic explanation (LIME) perturbs input data and analyzes the effects on output to compute feature importance.
- Integrated gradients: This technique establishes feature importance by computing gradients of features with respect to input data.
- Permutation importance: You can evaluate a feature’s importance by removing it and observing the effect on a particular performance metric, such as F1-score, precision, recall, etc.
- Partial dependence plot: This plot shows the marginal effect of features on a model’s output. It helps interpret whether the feature and the output have a simple or more complex relationship.
Evaluation Strategies
Model evaluation techniques help increase a model’s robustness by allowing you to assess performance and quickly identify issues during model development.
While traditional evaluation metrics, such as the F1-score, precision, recall, etc., let you evaluate the performance of simple models against established benchmarks, more complex methods are necessary for modern LLMs and other foundation models.
For instance, you can evaluate an LLM’s output using various automated scores, such as BLEU, ROUGE, CIDEr, etc. You can complement LLM evaluation with human feedback for a more robust assessment.
In contrast, intersection-over-union (IoU), panoptic quality, mean average precision (mAP), etc., are some common methods for evaluating CV models.
Challenges of Model Robustness
While model robustness is essential for high performance, maintaining it is significantly challenging. The list below mentions some issues you can encounter when building robust models:
- Data volume and variety: Modern data comes from multiple sources in high volumes. Preprocessing these extensive datasets demands robust data pipelines and expert staff to identify issues during the collection phase.
- Increased model complexity: Recent advancements in natural language processing and computer vision modeling call for more sophisticated explainability techniques to understand how they process input data.
- Feature volatility: Model decay is a recurrent issue in dynamic domains with frequent changes in feature distribution. Keeping track of these distributional shifts calls for complex monitoring infrastructure.
- Evaluation methods: Developing the perfect evaluation strategy is tedious as you must consider several factors, such as the nature of a model’s output, ground-truth availability, the need for domain experts, etc.
Achieving Model Robustness with Encord Active
You can mitigate the above challenges by using an appropriate ML platform like Encord Active that helps you increase model robustness through automated evaluation features and development tools.
Encord Active automatically identifies labeling errors and boosts data quality through relevant quality metrics and vector embeddings. It also helps you debug models through comprehensive explainability reports, robustness tests, and model error analysis. In addition, the platform features active learning pipelines to help you identify data samples that are crucial for your model and streamline the data curation process.
Evaluate the Quality of the Data
You can use Encord Active to improve the quality of your data and, subsequently, enhance the robustness of vision models through several key features. Encord Active offers various features like data exploration, label exploration, similarity search, quality metrics (both off-the-shelf and custom), data and label tagging, image duplication detection, label error detection, and outlier detection. It supports various data types and labels and integrates seamlessly with Encord Annotate.
Data curation workflow
The platform supports curating images using embeddings and quality metrics to find data of bad quality for your model to learn from or low-quality samples you might want to test your model on. Here is an example using the Embeddings View within Encord Active to surface images that are too bright from the COCO 2017 dataset:
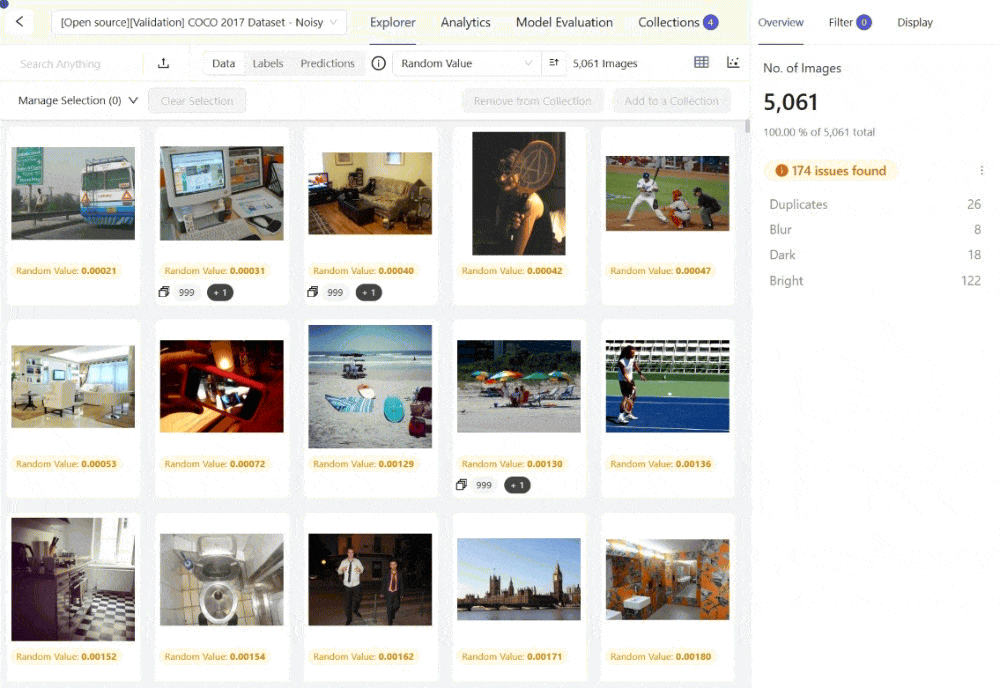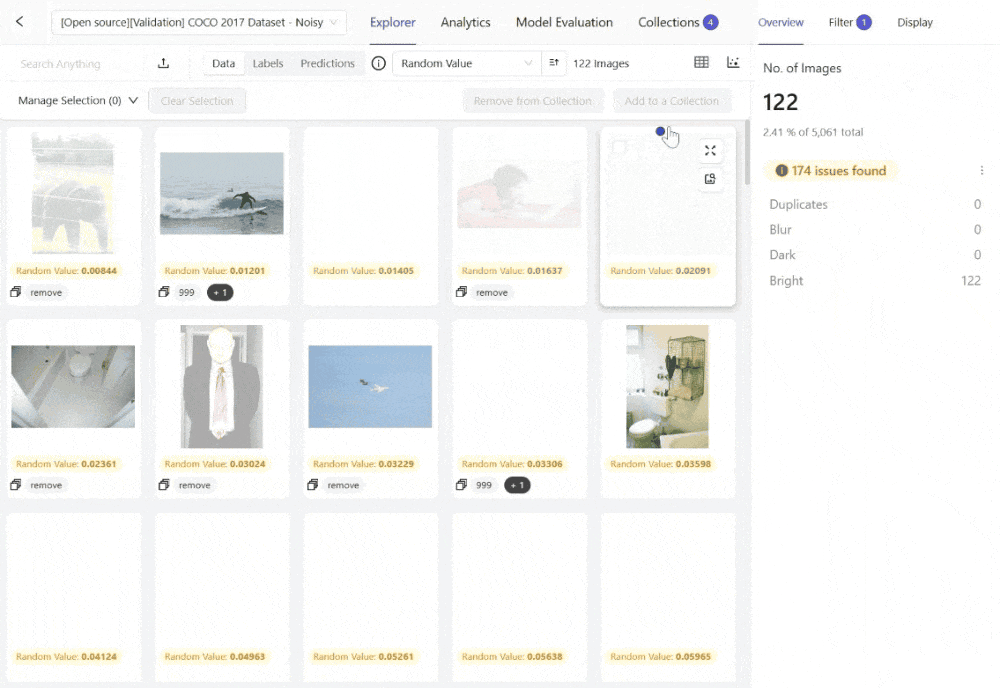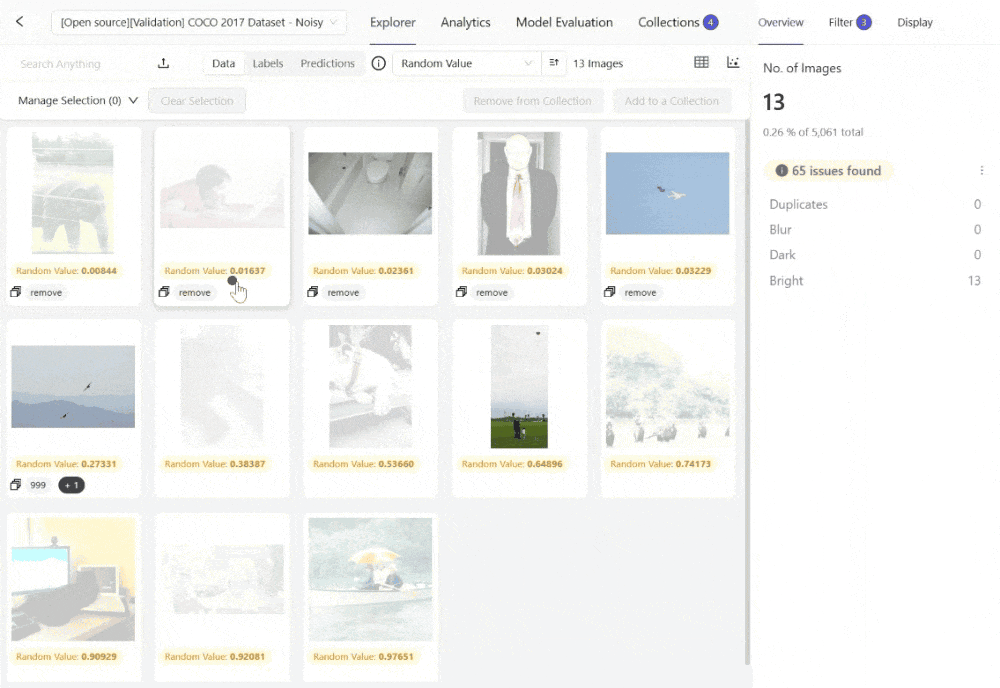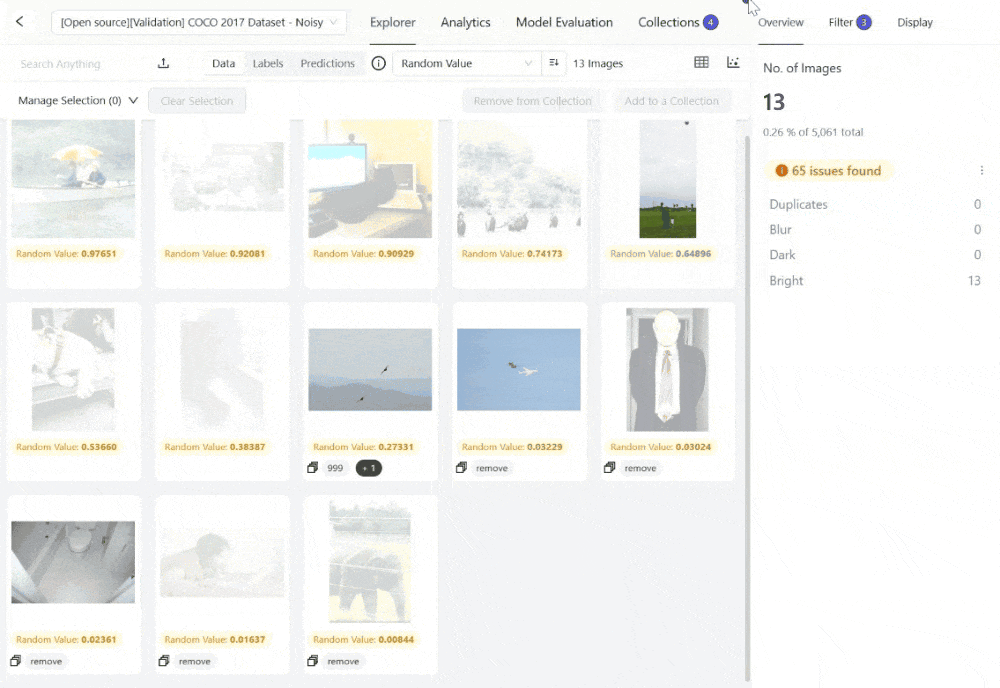
You can also explore the embedding plots and filter the images by a quality metric like "Area" for instances where you might want to find the largest or smallest images from your set, among other off-the-shelf or custom quality metrics.
Finding and Flagging Label Errors
Within Encord Active, you can surface duplicate labels that could be overfitting or lead to misleading high-performance metrics during training and validation. Because the model may recognize repeated instances rather than learn generalizable patterns. After identifying such images, you can add them to a “Collection” and send them to Encord Annotate for re-labeling or removing the duplicates.
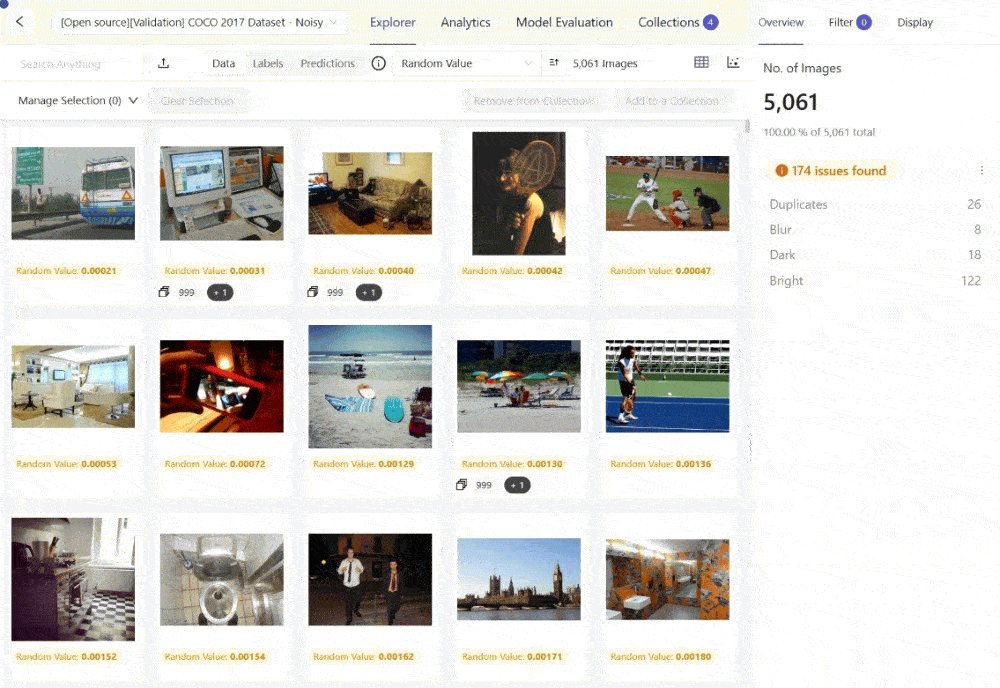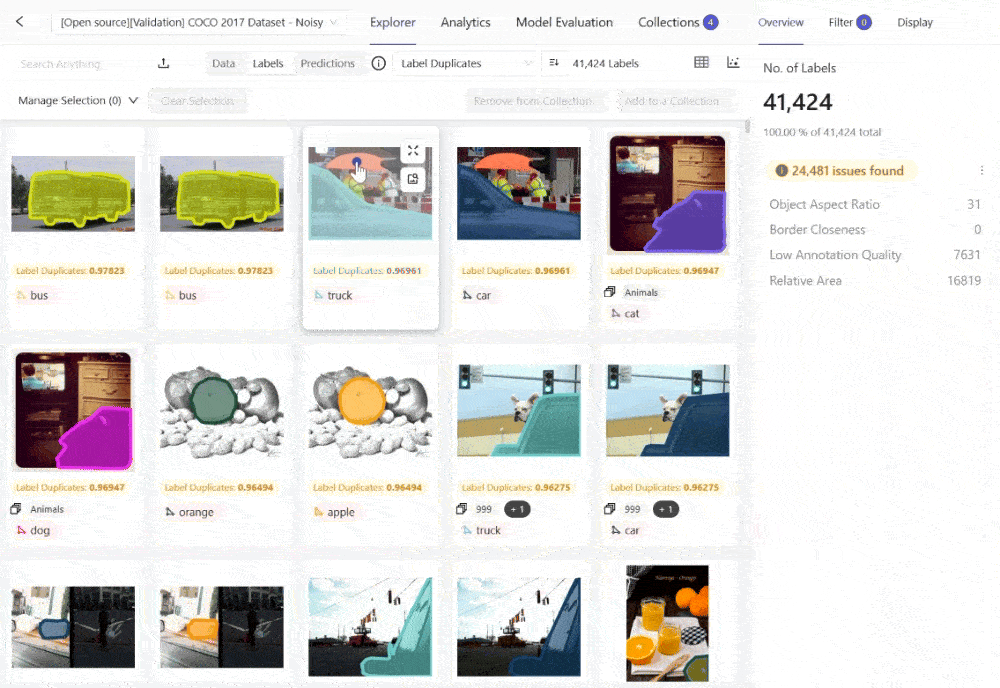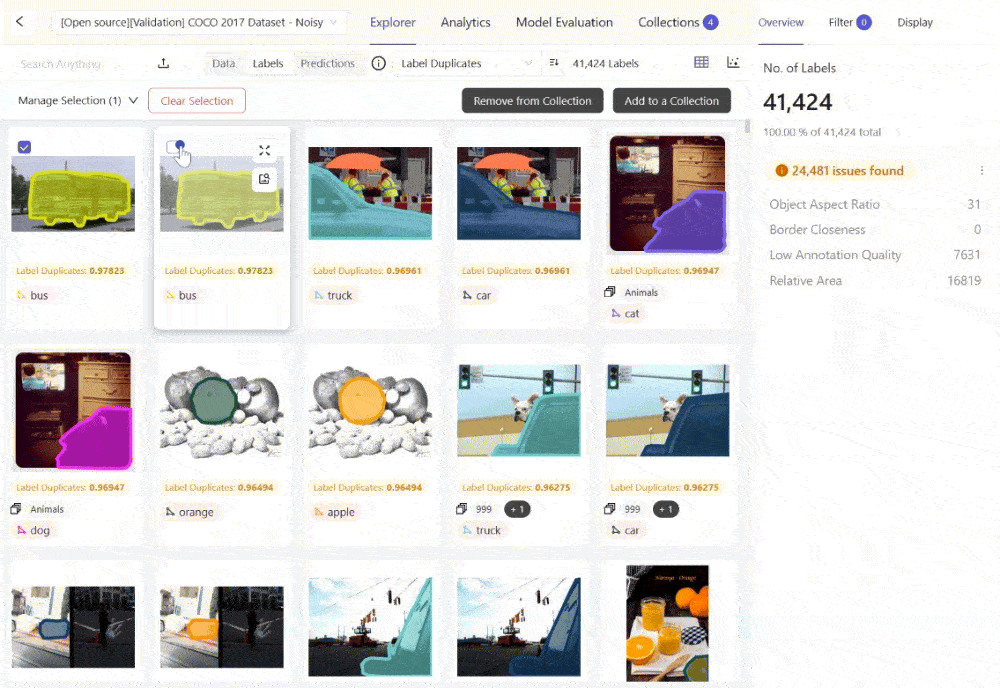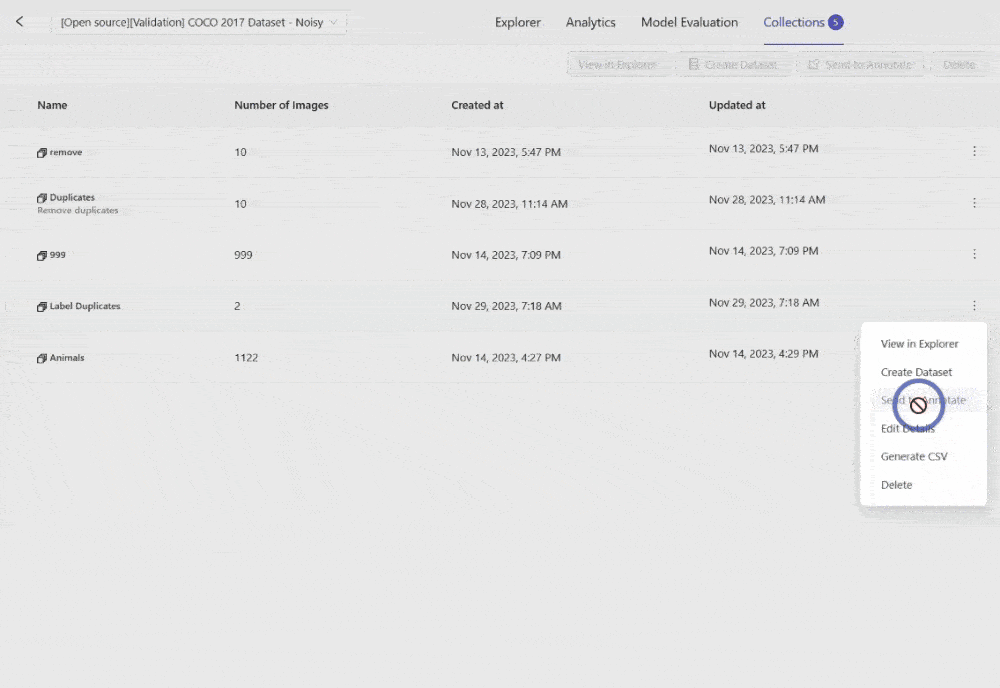

Evaluating Model Quality
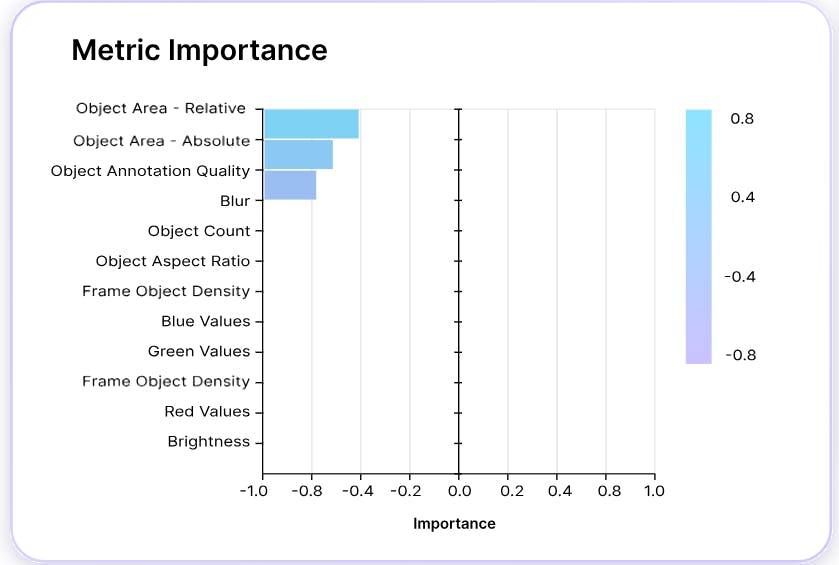
Encord Active also allows you to determine which metrics influence your model's performance the most. You can import your model’s prediction to get a 360° view of the quality of your model across performance metrics and data slices.
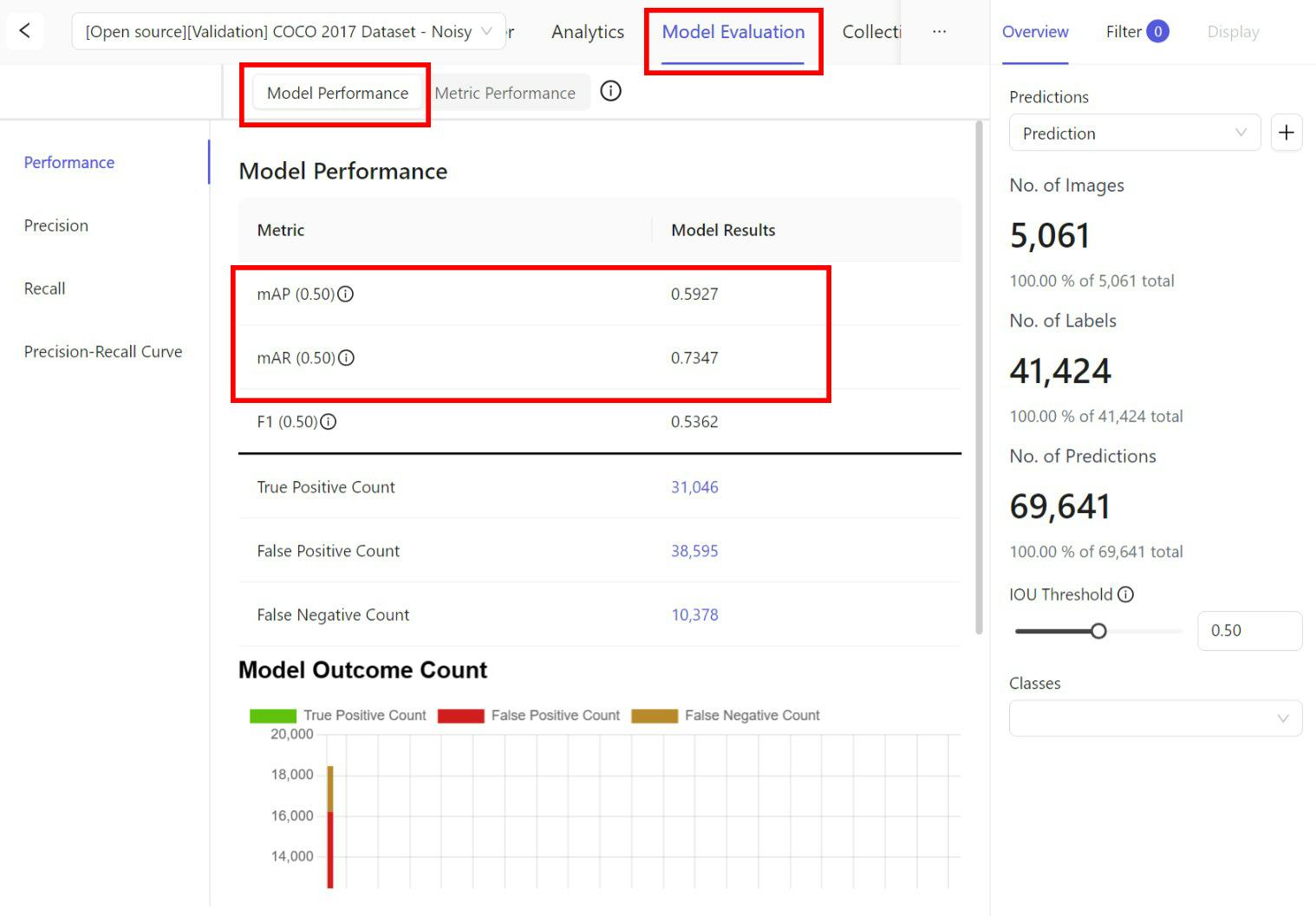
You can also inspect the metric impact on your model's performance. This can help you better understand how the model performs across metrics like the diversity of the data, label duplicates, brightness, and so on.
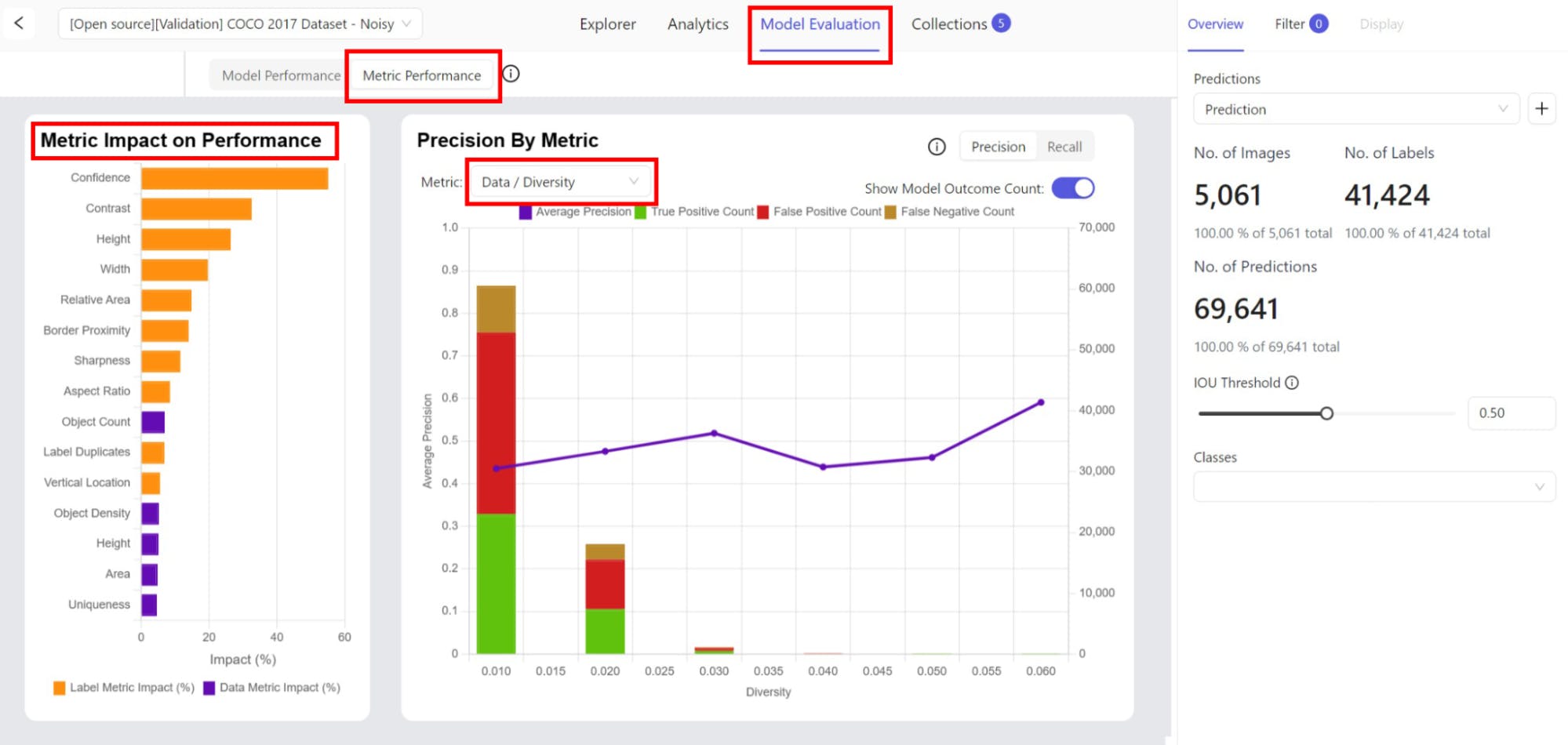
These features collectively ensure that data quality is significantly improved, contributing to the development of more robust and accurate vision models. The focus on active learning and the ability to handle various stages of the data and model lifecycle make Encord Active a comprehensive tool for improving data quality in computer vision applications.
Model Robustness: Key Takeaways
Building robust models is the only way to leverage AI’s full potential to boost profitability. A few important things to remember about model robustness are:
- A robust model can maneuver uncertain real-world scenarios appropriately and increase trust in the AI system.
- Achieving model robustness can imply slightly compromising accuracy to reduce generalization errors.
- Ensuring model robustness helps you prevent adversaries from stealing your model or data.
- Improved data quality, domain adaptation techniques, and regularization's reduction of generalization error can all contribute to model robustness.
- Model explainability is essential for building robust models as it helps you understand a model’s behavior in detail.
- A specialized ML platform can help you overcome model robustness challenges such as increased model complexity and feature volatility.

Frequently asked questions
Model robustness refers to the model’s generalization capability. The higher the robustness, the better the model generalizes to unseen data.
Model robustness ensures your models produce consistent, reliable, and bias-free results. It also prevents your model from malicious attacks.
Data quality improvements, adversarial training, ensemble learning, explainability, domain adaptation, and regularization can help you improve robustness.
Robust models have high predictive accuracy on new data. However, models with high accuracy scores during the training and validation phase may not be robust enough to perform equally well on unseen data.
In white-box attacks, the adversary knows the model’s architecture and parameters, while in black-box attacks, the attacker has limited or no information regarding the model’s inner workings.
Robustness testing captures vulnerabilities and ensures stable performance before models are released to the real world, where data is noisy and unexpected.
The performance of a robust model does not deviate significantly on different data. Hence, they are resilient to adversarial attacks, thereby enhancing model security.
Robust models contribute to fairer results because they ensure consistent performance across diverse datasets.
In the context of machine learning models, robustness is the ability of models to perform well on unseen data.
Encord provides robust tools that facilitate the creation of ground truth for regression testing. These features allow users to maintain high accuracy in model evaluations and adapt to the evolving requirements of machine learning, especially in environments where traditional labeling methods are less applicable.
Encord supports organizations in navigating fast-evolving threat landscapes by providing tools that facilitate quick adaptations and retraining of models. With a focus on streamlining processes, Encord helps teams stay ahead of emerging threats, ensuring their systems remain effective and secure.