Data Refinement Strategies for Computer Vision

Data refinement strategies for computer vision are integral for improving the data quality used to train machine learning-based models.
Computer vision is becoming increasingly mission-critical across dozens of sectors, from facial recognition on social media platforms to self-driving cars. However, developing effective computer vision models is a challenging task. One of the key challenges in computer vision is dealing with large amounts of data and ensuring that the data is of high quality. This is where data refinement strategies come in.
In this blog post, we will explore the different data refinement strategies in computer vision and how they can be used to improve the performance of machine learning models. We will also discuss the tools and techniques for creating effective data refinement strategies.
Model-centric vs. Data-centric Computer Vision
In computer vision, there are two paradigms: model-centric and data-centric.
Both of these paradigms share a common goal of improving the performance of machine learning models, but they differ in their approach to achieving this objective.

Model-centric computer vision relies on developing, experimenting, and improving complex machine learning (ML) models to accomplish tasks like object detection, image recognition, and semantic segmentation. Here the datasets are considered static, and changes are added to the model (architecture, hyperparameters, loss functions, etc.) to improve performance.
Data-centric computer vision: In recent years, there has been a growing focus on data-centric computer vision as researchers and engineers recognize the significance of high-quality data in building effective ML, AI, and CV models. The models, their hyperparameters, etc., play only a minor role in the machine learning pipeline. On the other hand, data-centric computer vision prioritizes the quality and quantity of data used to train these models.

Why Do We Need Data Refinement Strategies?
Data refinement strategies are crucial in improving the quality of data and labels used to train machine learning models, as the quality of data and labels directly impacts the model's performance. Here are some ways data refinement strategies can help:
Identifying Outliers
Outliers are data points that do not follow the typical distribution of the dataset. Outliers can cause the model to learn incorrect patterns, leading to poor performance. By removing outliers, the model can focus on learning the correct patterns, leading to better performance.
Identifying and Removing Noisy Data
Noisy data refers to data that contains irrelevant or misleading information, such as duplicates or low-quality images. These data points can cause models to learn incorrect patterns, leading to inaccurate predictions.
Identifying and Correcting Label Errors
Label errors occur when data points are incorrectly labeled or labeled inconsistently, leading to misclassifying objects in images or videos. Correcting label errors ensures that the model receives accurate information during training, improving its ability to predict and classify objects accurately.
 💡Read how to find and fix label errors
💡Read how to find and fix label errors Assisting in Model Performance Optimization and Debugging
Data refinement strategies help preserve and debug the best-performing model by correcting incorrect labels that could affect the model’s performance evaluation metrics. You can get a more accurate and effective model by improving the data quality used to train the model.
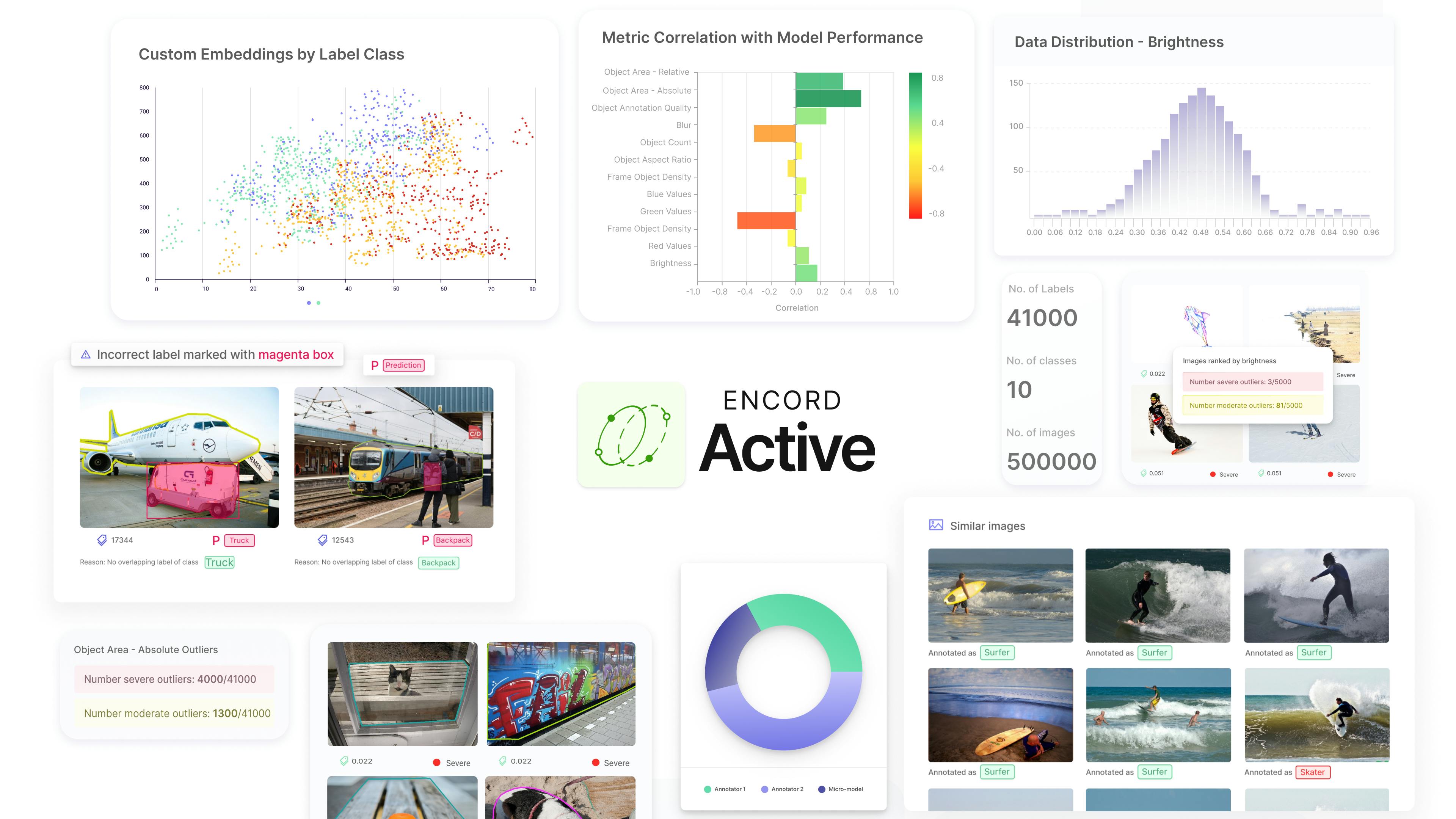
💡You can try the different refinement strategies with Encord Active on GitHub today Common Data Refinement Strategies in Computer Vision
Computer vision has made great strides in recent years, with applications across industries from healthcare to autonomous vehicles. However, the data quality used to train machine learning models is critical to their success.
There are several common data refinement strategies used in computer vision. These strategies are designed to improve the data quality used to train machine learning models. The once we will cover today are:
- Smart data sampling
- Improving data quality
- Improving label quality
- Finding model failure modes
- Active learning
- Semi-supervised learning (SSL)
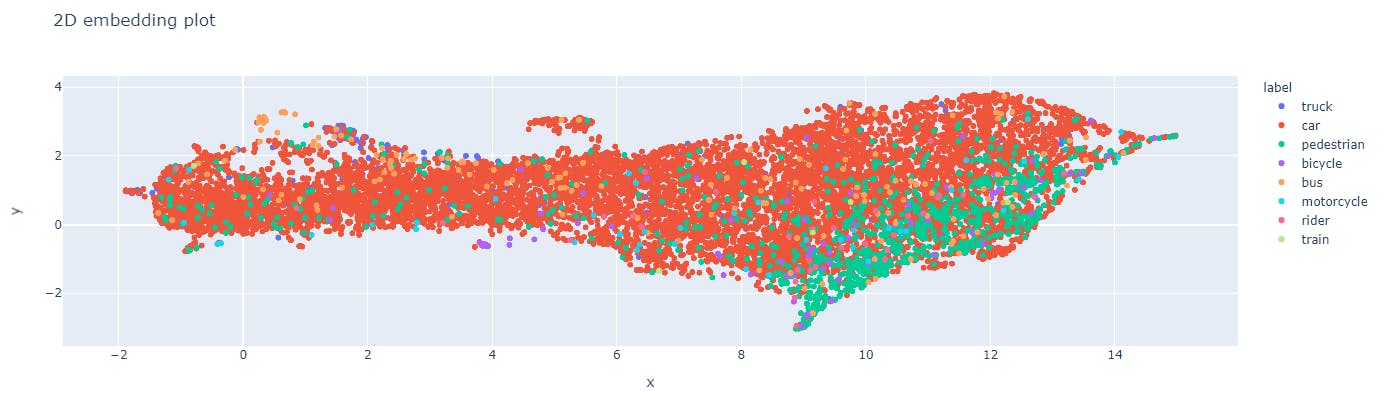
💡With Encord Active, you can visualize image embeddings, show images from a particular cluster, and export them for relabeling. Smart Data Sampling
It involves identifying relevant data and removing irrelevant data. Rather than selecting data randomly or without regard to specific characteristics, smart data sampling involves using a systematic approach to choose data points most representative of the entire dataset.
For example, if you train a model to recognize cars, we would want to select the cars in the street-view data.
The goal of smart data sampling is to reduce the amount of data needed for training without sacrificing model accuracy. This technique can be advantageous when dealing with large datasets requiring significant computational resources and processing time. For example, image embeddings can be used for smart data sampling by clustering similar images based on their embeddings.
These clusters can be used to filter out the images which have duplicates in the dataset and eliminate them. This reduces the amount of data needed for training while ensuring that the dataset is representative of the overall dataset. K-means and hierarchical clustering are two approaches to using image embeddings for smart data sampling.
Improving Data Quality
Improving the quality of data in the data refinement stage of machine learning, various techniques can be used, including data cleaning, data augmentation, balancing the dataset, and data normalization. These techniques help to ensure that the model is accurate, generalizes well on unseen data, and is not biased towards a particular class or category.
💡Read this post next if you want to find out how to improve the quality of labeled data Improving Label Quality
Label errors can occur when the data is mislabeled or when the labels are inconsistent. You also need to ensure that all classes in the dataset are adequately represented to avoid biases and improve the model's performance in classifying minority classes.
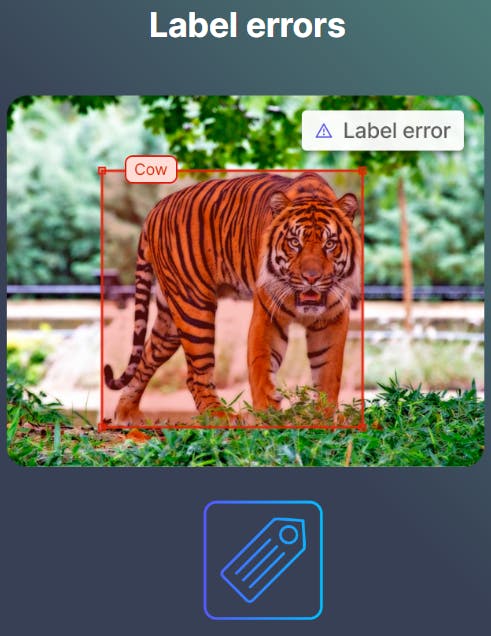
Improving label quality ensures that computer vision algorithms accurately identify and classify objects in images and videos. To improve label quality, data annotation teams can use complex ontological structures that clearly define objects within images and videos.
You can also use AI-assisted labeling tools to increase efficiency and reduce errors, identify and correct poorly labeled data through expert review workflows and quality assurance systems, and improve annotator management to ensure consistent and high-quality work.
Organizations can achieve higher accuracy scores and produce more reliable outcomes for their computer vision projects by continually assessing and improving label quality.
Finding Model Failure Modes
Machine learning models can fail in different ways. For example, the model may struggle to recognize certain types of objects or may have difficulty with images taken from certain angles.
Finding model failure modes is a critical first step in the testing process of any machine learning model. Thoroughly testing a model requires considering potential failure modes, such as edge cases and outliers, that may impact its performance in real-world scenarios. These scenarios may include factors that could impact the model's performance, such as changing lighting conditions, unique perspectives, or environmental variations.
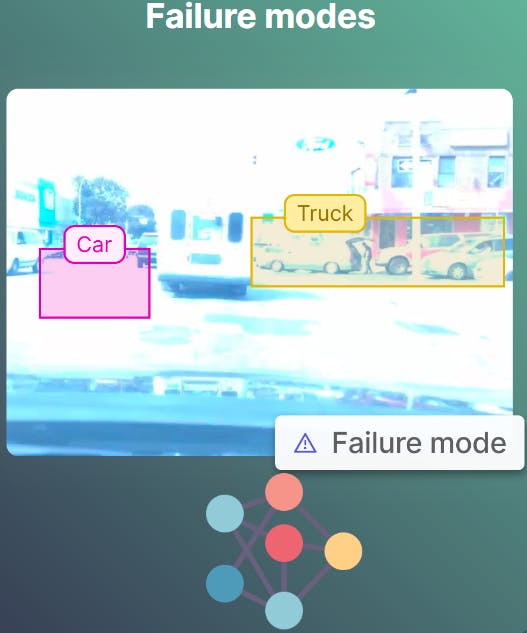
By identifying scenarios where a model might fail, one can develop test cases that evaluate the model's ability to handle these scenarios effectively. It's important to note that identifying model failure modes is not a one-time process and should be revisited throughout the development and deployment of a model. As new scenarios arise, it may be necessary to add new test cases to ensure that a model continues to perform effectively in all possible scenarios.
💡Read more to find out how to evaluate ML models using model test cases. Active Learning
Active learning is another strategy to improve your data and your model performance. Active learning involves iteratively selecting the most informative data samples for annotation by human annotators, thereby reducing the annotation effort and cost.
This strategy is advantageous when large datasets need to be annotated, as it allows for more efficient use of resources. By selecting the most valuable samples for annotation, active learning can help improve the quality of the dataset and the accuracy of the resulting machine learning models.
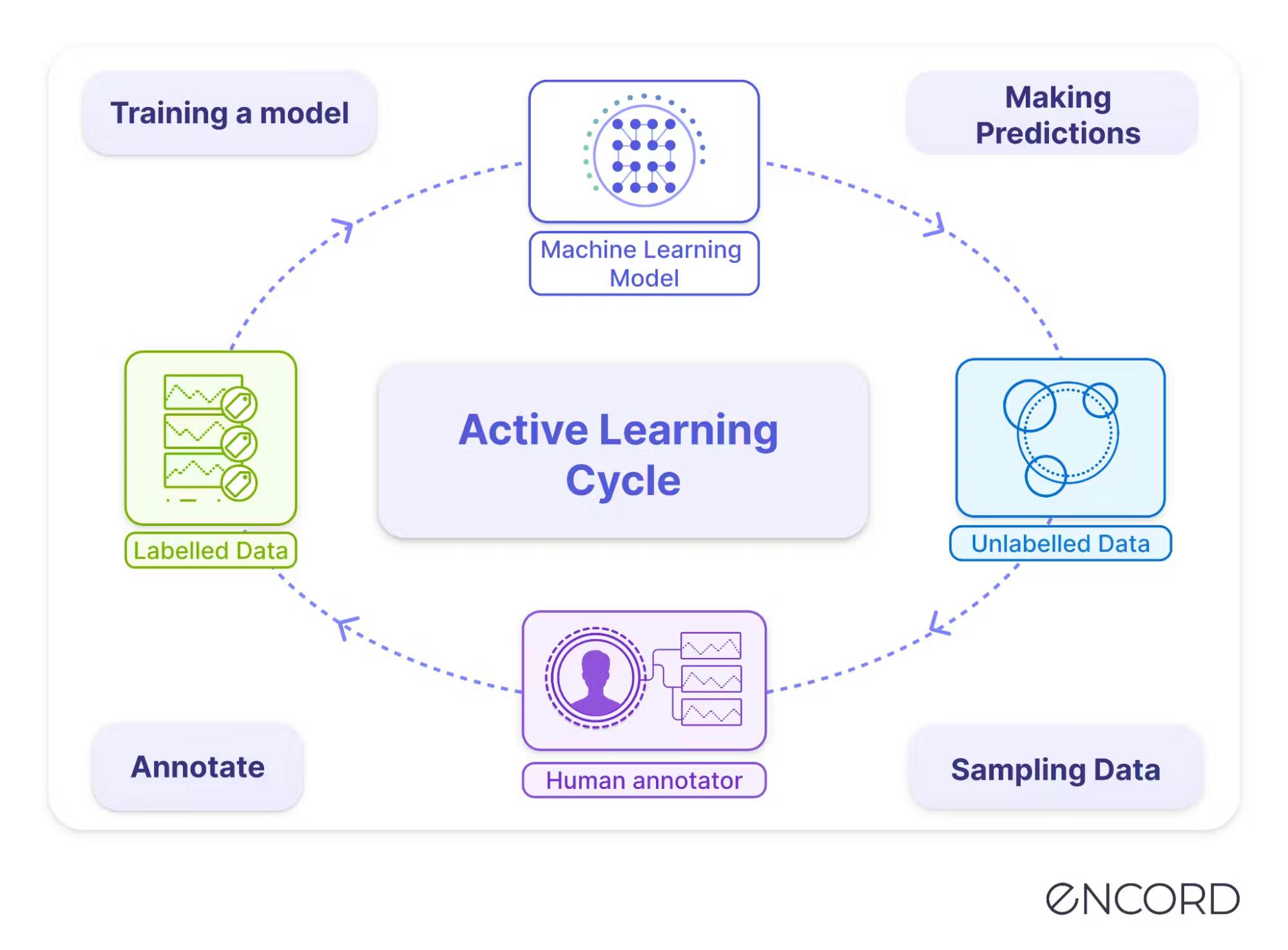
To implement active learning in computer vision, you first train a model on a small subset of the available data.
The model then selects the most informative data points for annotation by a human annotator, who labels the data and adds it to the training set.
This process continues iteratively, with the model becoming more accurate as it learns from the newly annotated data.
There are several benefits to using active learning in computer vision:
- It reduces the amount of data that needs to be annotated, saving time and reducing costs.
- It improves the accuracy of the machine learning model by focusing on the most informative data points.
- Active learning enables the model to adapt to changes in the data distribution over time, ensuring that it remains accurate and up-to-date.
💡Read this post to learn about the role of active learning in computer vision Semi-Supervised Learning
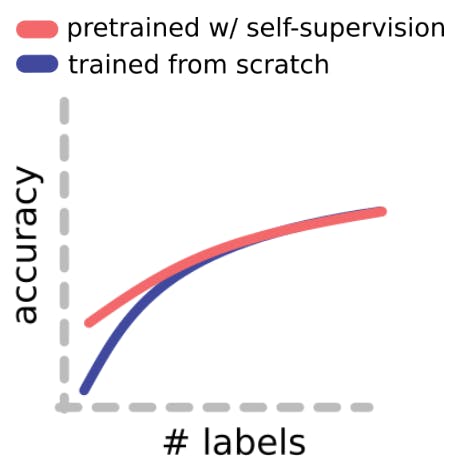
In semi-supervised learning (SSL), a combination of labeled and unlabeled data is used to train the model. The model leverages a large amount of unlabeled data to learn the underlying distribution and subsequently utilizes the labeled data to refine its hyperparameters and enhance the model’s overall performance.
SSL can be particularly useful when obtaining labeled data is expensive or time-consuming (see the figure below). If you want to learn more about the current state of semi-supervised learning, you can read A Cookbook for Self-supervised Learning co-authored by Yann LeCun.
💡Note: The data refinement strategies are inclusive of one another. They can be used in combination. For example, active learning and semi-supervised learning can be used together. What Do You Need to Create Data Refinement Strategies?
To create effective data refinement strategies, you will need: data, labels, model predictions, intuition, and the right tooling:
Data and Labels
A large amount of high-quality data is required to train the machine learning model accurately. The data must be clean, relevant, and representative of the target population.
Labels are used to identify the objects in the images, and these labels must be accurate and consistent. It is critical to develop a clear labeling schema that is comprehensive and allows for the identification of all relevant features.
Model Predictions
Evaluating the performance of a machine learning model is necessary to identify areas that require improvement. Model predictions provide valuable insights into the accuracy and robustness of the model. Moreover, your model predictions combined with your model embedding are very useful when detecting detect data and labeling outliers and errors.
Intuition
Developing effective data refinement strategies requires a deep understanding of the data and the machine learning model. This understanding comes from experience and familiarity with the data and the technology. Expertise in your problem is critical for identifying relevant features and ensuring that the model effectively solves the problem.
Tools
A range of tools can be used to create effective data refinement strategies. For example, the Encord Active platform provides a range of metrics-based data and label quality improvement tools. These include labeling, evaluation, active learning, and experiment-tracking tools.
Primary Methods for Data Refinement
There are three primary methodologies for data refinement in computer vision.
Refinement by Image
This approach involves a meticulous manual review and selection of individual images to be included in the training dataset for the machine learning model. Each image is carefully analyzed for its suitability and relevance before being incorporated into the dataset. Although this method can yield highly accurate and well-curated data, it is often labor-intensive and costly, making it less feasible for large-scale projects or when resources are limited.
Refinement by Class
In this method, data refinement is based on the class or category of objects present in the images. The process involves selecting and refining data labels associated with specific classes or categories, ensuring that the machine learning model is trained with accurate and relevant information.
This approach allows for a more targeted refinement process, focusing on the specific object classes that are of interest in the computer vision task. This method can be more efficient than the image-by-image approach, as it narrows the refinement process to relevant object classes.
Refinement by Quality Metrics
This methodology focuses on selecting and enhancing data according to predefined quality metrics. These metrics may include factors such as image resolution, clarity of labels, or the perspective from which the images are taken.
By establishing and adhering to specific quality criteria, this approach ensures that only high-quality images are included in the training dataset, thus reducing the influence of low-quality images on the model's performance. This method can help streamline the refinement process and improve the overall effectiveness of the machine learning model.
Alternatively, this process can be automated with active learning tools and pre-trained models. We will cover this in the next section.
Practical Example of Data Refinement
Encord Active is an open-source active learning toolkit designed to facilitate identifying and correcting label errors in computer vision datasets.
With its user-friendly interface and a variety of visualization options, Encord Active streamlines the process of investigating and understanding failure modes in computer vision models, allowing users to optimize their datasets efficiently.
To install Encord Active using pip, we need to run a command:
pip install encord-active
For more installation information, please read the documentation.
You can import a COCO project to Encord Active with a single-line command:
encord-active import project --coco -i ./images_folder -a ./annotations.json
Executing this command will create a local Encord Active project and pre-calculate all associated quality metrics for your data. Quality metrics are supplementary parameters for your data, labels, and models, providing semantically meaningful and relevant indices for these elements.
Encord Active offers a variety of pre-computed metrics that can be incorporated into your projects.
Additionally, the platform allows you to create custom metrics tailored to your specific needs. A local Encord Active instance will be available upon successfully importing the project, enabling you to examine and analyze your dataset thoroughly.
To open the imported project, just run the command:
encord-active visualize
Filtering Data and Label Outliers
For data analysis, begin by navigating to the Data Quality → Summary tab. Here, you can examine the distribution of samples about various image-level metrics, providing valuable insights into the dataset's characteristics.
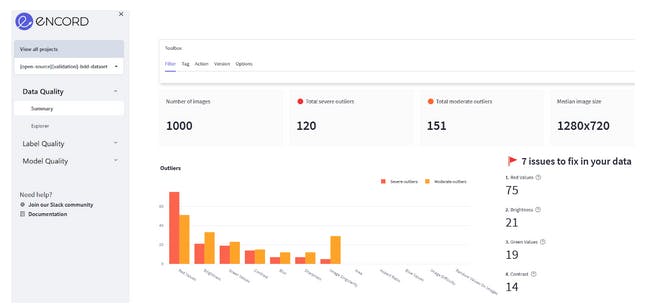
Data Quality Summary page of Encord Active
Using the summary provided by Encord Active, you can identify properties exhibiting significant outliers, such as extreme green values, which can be crucial for assessing the dataset's quality. The platform offers features that enable you to either distribute the outliers evenly when partitioning the data into training, validation, and test datasets or to remove the outliers entirely if desired.
For label analysis, navigate to the Label Quality → Summary tab. Here, you can examine your dataset's quality of label-level metrics.
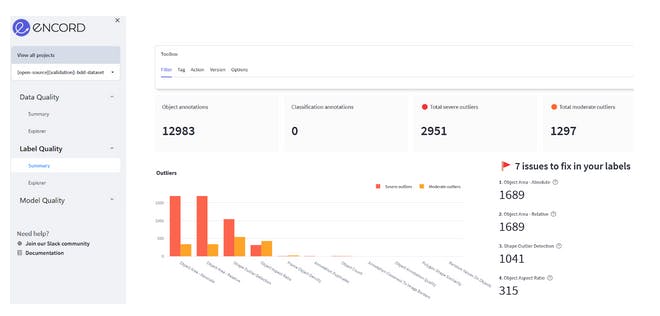
Below the label quality summary, you can find the label distribution of your dataset
On both Summary tabs, you can scroll down to get detailed information and visualization of the detected outliers and which metric to focus on.

Image outliers detected based on brightness quality metric
Once the outlier type has been identified, you would want to fix it. You can go to Data Quality → Explorer and filter images by the chosen metric value (brightness). Next, you can tag these images with the tag "high brightness" and download the data labels with added tags or directly send data for relabeling in Encord Annotate.
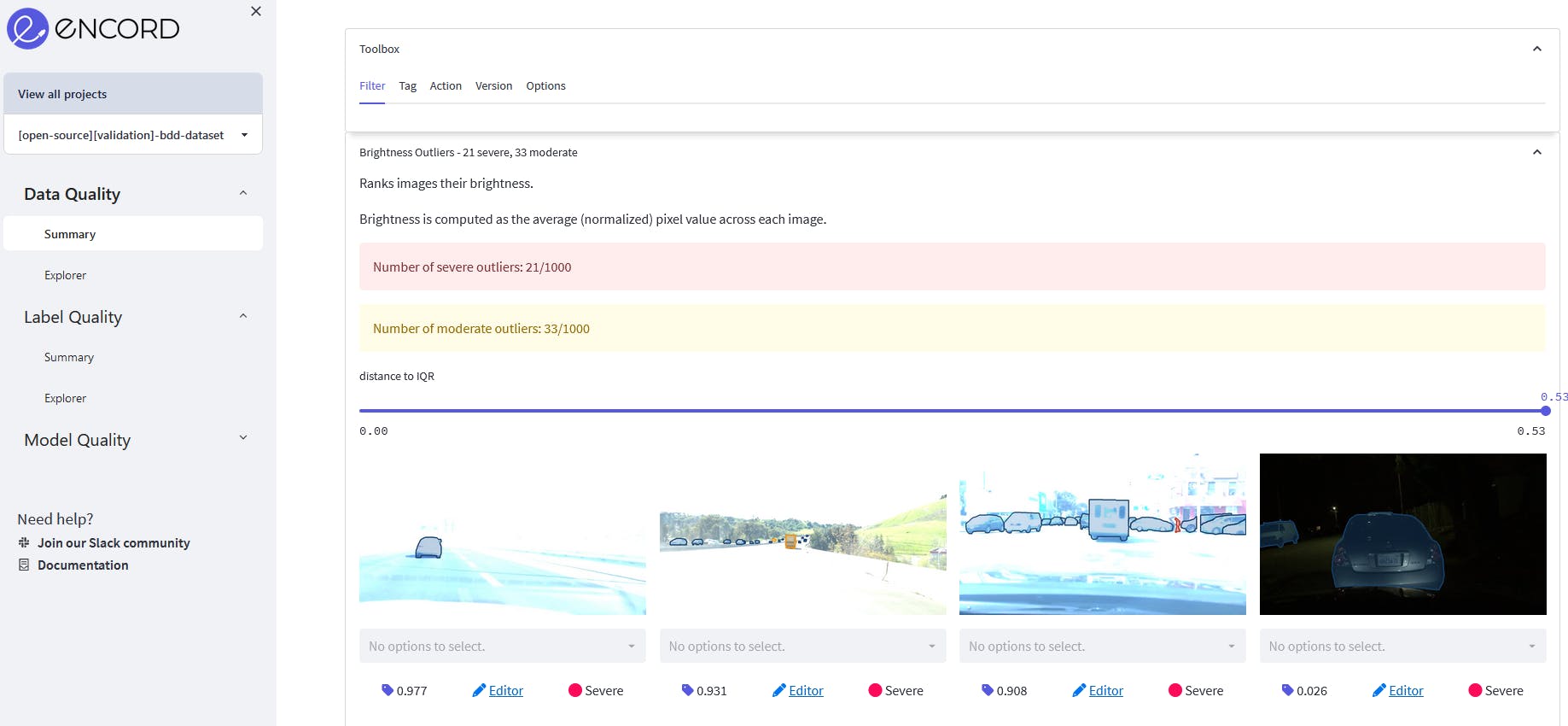
Images filtered by brightness values and added the tag "high brightness"
Finding Label Errors with a Pre-Trained Model and Encord Active
As your computer vision projects advance, you can utilize a trained model to detect label errors in your data annotation pipeline. To achieve this, follow a straightforward process:
- Use a pre-trained model on newly annotated samples to generate model predictions.
- Import the model predictions into Encord Active. Click here to find further instructions.
encord-active import predictions --coco results.json
- Overlay model predictions and ground truth labels for visualization within the Encord Active platform.
- Sort by high-confidence false-positive predictions and compare them against the ground truth labels.
- Once discrepancies are identified, flag the incorrect or missing labels and forward them for re-labeling using Encord Annotate.
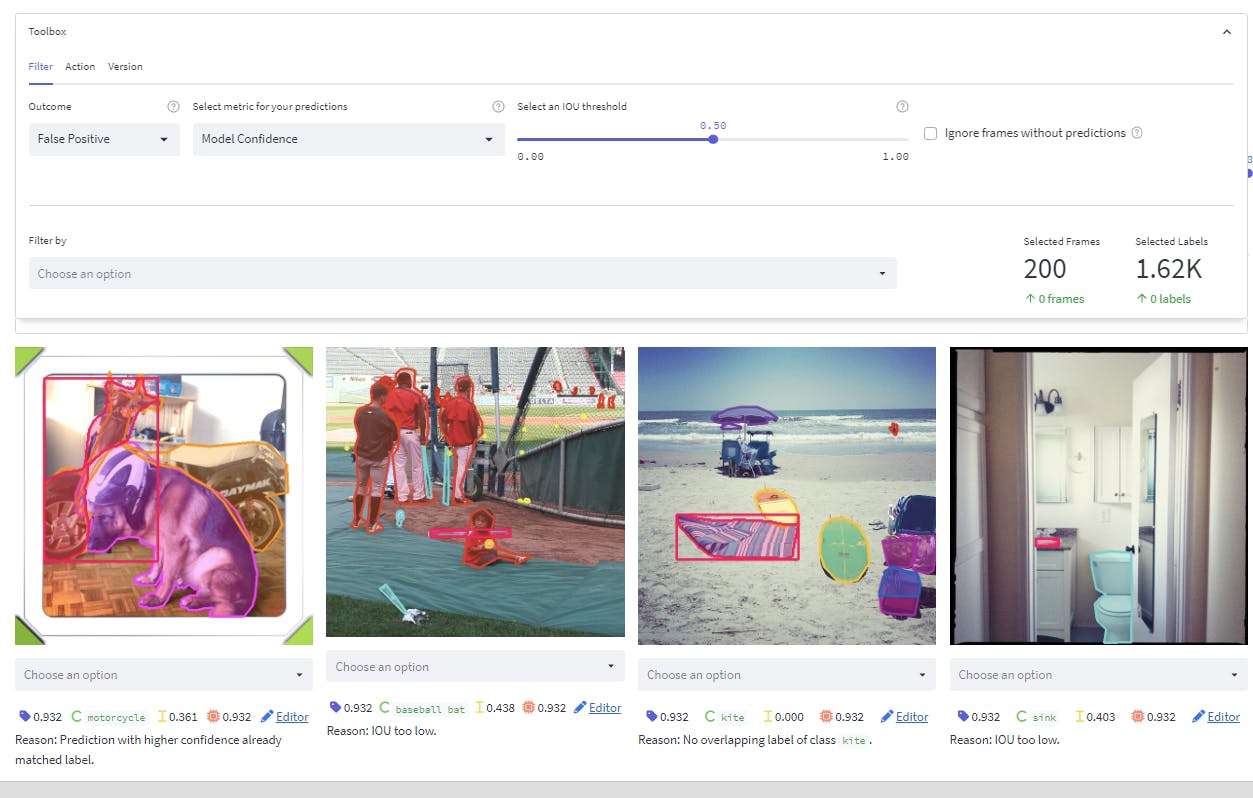
Model Quality page of Encord Active
To ensure the integrity of the process, it is crucial that the computer vision model employed to generate predictions has not been trained on the newly annotated samples under investigation.

Conclusion
In summary, the success of machine learning models in computer vision heavily relies on the quality of data used to train them.
Data refinement strategies, such as active learning, smart data sampling, improving data and label quality, and finding model failure modes, are crucial in ensuring that the models produce reliable and accurate results. These strategies require high-quality data, accurate and consistent labels, and a deep understanding of the data and the technology.
Using effective data refinement strategies, you can achieve higher model accuracy and produce more reliable outcomes for your computer vision model. It is essential to continually assess and refine data quality throughout the development and deployment of machine learning models to ensure that they remain accurate and up-to-date in real-world scenarios.
Ready to improve the data refinement of your CV models?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Frequently asked questions
In Encord, data curation involves analyzing various modalities of data, such as images, videos, and audio files. We utilize metadata and several metrics, including brightness and object density, to filter and prioritize data for annotation. Additionally, we employ advanced techniques, like embeddings, to identify the most impactful data that will enhance model performance.
Encord can handle a variety of data types for agricultural research, including RGB images, monochromatic images, LiDAR data, stereo depth vision, and hyperspectral data. This flexibility allows users to analyze and annotate diverse datasets effectively, enhancing insights into plant responses and yield predictions.
Encord supports a wide variety of data types, including images, videos, and sensor data, which are essential for training models in defense technology applications. This flexibility allows users to tailor their datasets to meet specific project requirements and improve model performance.
Encord supports various types of data for annotation, including images, videos, and other formats that require spatial or temporal labeling. The platform is designed to handle complex datasets, such as those containing multiple objects or scenes with high human activity.
If certain images in a dataset are missing specific metadata fields, Encord's system accommodates this by not displaying those images in the filtered results. This ensures that users can focus on relevant data without encountering issues related to missing metadata.
Encord's platform includes tools designed specifically for annotating construction tech data, such as building scans and 3D models. These features streamline the annotation process, making it faster and more efficient, which is crucial for timely project execution.
Encord can manage various types of data, including images, raw text, and JSON representations of documents. This versatility allows users to effectively handle visual representations, textual content, and the layout of documents for comprehensive annotation.
Encord allows for the integration of multiple data types, including point cloud files from Lidar and radar, as well as RGB data. This combination provides a comprehensive view for annotating objects and scenes, enhancing the quality and accuracy of the data.
Encord assists users in determining which data to annotate by providing tools and expertise to analyze project requirements. This support helps clients make informed decisions about their annotation strategies, ensuring they focus on the most critical data.
Encord supports various data types, including images, videos, point clouds, and cuboids. The platform is equipped with tools tailored for each data type, ensuring that your annotation process is efficient and effective.