Training vs. Fine-tuning: What is the Difference?

Product Manager at Encord
Training and fine-tuning are crucial stages in the machine learning model development lifecycle, serving distinct purposes. This article explains the intricacies of both methodologies, highlighting their differences and importance in ensuring optimal model performance.
Training in the context of deep learning and neural networks refers to the phase where a new model learns from a dataset. During this phase, the model adjusts its model weights based on the input data and the corresponding output, often using embeddings and activation functions. While embeddings and activation functions play significant roles in certain model architectures and tasks, they are not universally employed during the training phase of all deep learning models. It's crucial to understand the specific context and model architecture to determine their relevance.
The objective is to diminish the discrepancy between the anticipated and factual output, frequently termed error or loss. This is predominantly achieved using algorithms like backpropagation and optimization techniques like gradient descent.
Fine-tuning, conversely, follows the initial training, where a pre-trained model (previously trained on a vast dataset like ImageNet) is trained on a smaller, task-specific dataset. The rationale is to leverage the knowledge the model has acquired from the initial training process and tailor it to a more specific task. This becomes invaluable, especially when the new dataset for the new task is limited, as training from scratch might lead to overfitting.
As training stars, the neural network's weights are randomly initialized or set using methods like He or Xavier initialization. These weights are fundamental in determining the model's predictions. As the training progresses, these weights adjust to minimize the error, guided by a specific learning rate.
Conversely, during fine-tuning, the model starts with pre-trained weights from the initial training, which are then fine-tuned to suit the new task better, often involving techniques like unfreezing certain layers or adjusting the batch size.
The training aims to discern patterns and features from the data, creating a base model that excels on unseen data and is often validated using validation sets. Fine-tuning, however, zeroes in on adapting a generalized model for a specific task, often leveraging transfer learning to achieve this.
While training focuses on generalizing models, fine-tuning refines this knowledge to cater to specific tasks, making it a crucial topic in NLP with models like BERT, computer vision tasks like image classification, and, more recently, the proliferation of foundation models.
The Training Process
Initialization of Weights
Random Initialization
In deep learning, initializing the weights of neural networks is crucial for the training process. Random initialization is a common method where weights are assigned random values. This method ensures a break in symmetry among neurons, preventing them from updating similarly during backpropagation. However, random initialization can sometimes lead to slow convergence or the vanishing gradient problem.
He or Xavier Initialization
Specific strategies, like He or Xavier initialization, have been proposed to address the challenges of random initialization. He initialization, designed for ReLU activation functions, initializes weights based on the size of the previous layer, ensuring that the variance remains consistent across layers. On the other hand, Xavier initialization, suitable for tanh activation functions, considers the sizes of the current and previous layers. These methods help with faster and more stable convergence.
Backpropagation and Weight Updates
Gradient Descent Variants
Backpropagation computes the gradient of the loss function concerning each weight by applying the chain rule. Various gradient descent algorithms update the weights and minimize the loss. The most basic form is the Batch Gradient Descent. However, other variants like Stochastic Gradient Descent (SGD) and Mini-Batch Gradient Descent have been introduced to improve efficiency and convergence.
Role of Learning Rate
The learning rate is a hyperparameter that dictates the step size during weight updates. A high learning rate might overshoot the optimal point, while a low learning rate might result in slow convergence. Adaptive learning rate methods like Adam, RMSprop, and Adagrad adjust the learning rate during training, facilitating faster convergence without manual tuning.
Regularization Techniques
Dropout
Overfitting is a common pitfall in deep learning, where the model performs exceptionally well on the training data but needs to improve on unseen data. Dropout is a regularization technique that mitigates overfitting. During training, random neurons are "dropped out" or deactivated at each iteration, ensuring the model does not rely heavily on any specific neuron.
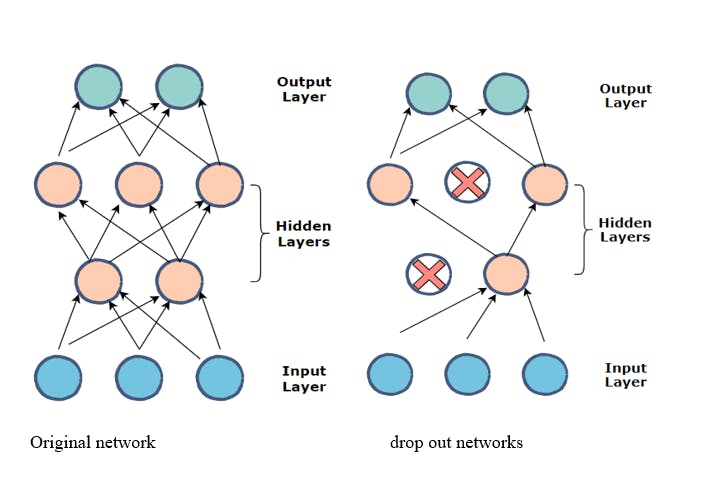
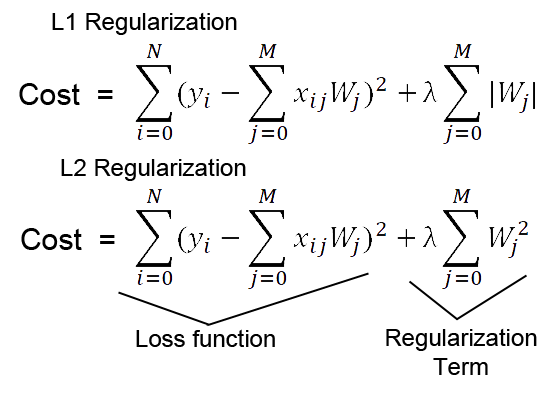
L1 and L2 Regularization
L1 and L2 are other regularization techniques that add a penalty to the loss function. L1 regularization adds a penalty equivalent to the absolute value of the weights' magnitude, which aids feature selection. L2 regularization adds a penalty based on the squared magnitude of weights, preventing weights from reaching extremely high values. Both methods help in preventing overfitting, penalizing complex models, and producing a more generalized model.
The Fine-tuning Process
Transfer Learning: The Backbone of Fine-tuning
Transfer learning is a technique where a model developed for a task is adapted for a second related task. It is a popular approach in deep learning where pre-trained models are used as the starting point for computer vision and natural language processing tasks due to the extensive computational resources and time required to train models from scratch.
Pre-trained models save the time and resources needed to train a model from scratch. They have already learned features from large datasets, which can be leveraged for a new task with a smaller dataset. This is especially useful when acquiring labeled data is challenging or costly.
When fine-tuning, it's common to adjust the deeper layers of the model while keeping the initial layers fixed. The rationale is that the initial layers capture generic features (like edges or textures), while the deeper layers capture more task-specific patterns. However, the extent to which layers are fine-tuned can vary based on the similarity between the new task and the original task.
Strategies for Fine-tuning
One of the key strategies in fine-tuning is adjusting the learning rates. A lower learning rate is often preferred because it makes the fine-tuning process more stable. This ensures the model retains the previously learned features without drastic alterations.
Another common strategy is freezing the initial layers of the model during the fine-tuning process. This means that these layers won't be updated during training. As mentioned, the initial layers capture more generic features, so fixing them is often beneficial.
Applications and Use Cases
Domain Adaptation
Domain adaptation refers to the scenario where the source and target tasks are the same, but the data distributions differ. Fine-tuning can be used to adapt a model trained on source data to perform well on target data.
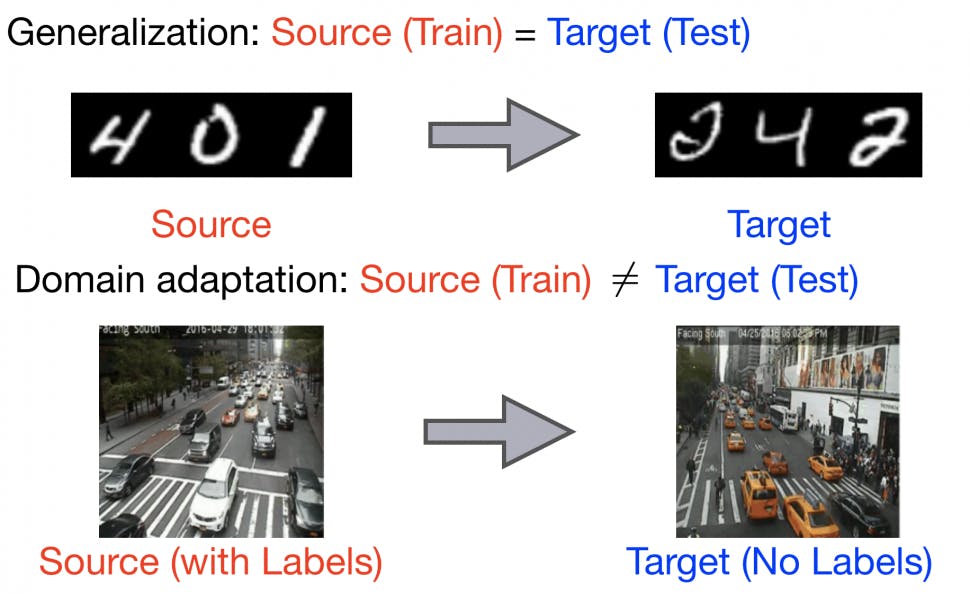
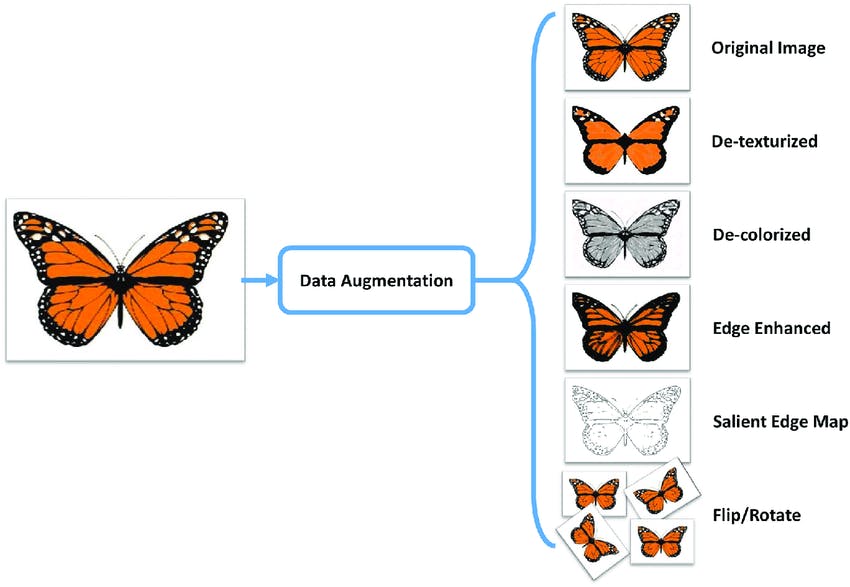
Data Augmentation
Data augmentation involves creating new training samples by applying transformations (like rotations, scaling, and cropping) to the existing data. Combined with fine-tuning, it can improve the model's performance, especially when the available labeled data is limited.
Comparative Analysis
Benefits of Training from Scratch
- Customization: Training a model from scratch allows complete control over its architecture, making it tailored specifically for the task.
- No Prior Biases: Starting from scratch ensures the model doesn't inherit any biases or unwanted features from pre-existing datasets.
- Deep Understanding: Training a model from the ground up can provide deeper insights into the data's features and patterns, leading to a more robust model for specific datasets.
- Optimal for Unique Datasets: For datasets significantly different from existing ones, training from scratch might yield better results as the model learns features unique to that dataset.
Limitations of Training from Scratch
This approach requires more time as the model learns features from the ground up and requires a large, diverse dataset for optimal performance. With the right data and regularization, models can easily fit.
- Extended Training Time: Starting from the basics means the model has to learn every feature, leading to prolonged training durations.
- Data Dependency: Achieving optimal performance mandates access to a vast and varied dataset, which might only sometimes be feasible.
- Risk of Overfitting: Without adequate data and proper regularization techniques, models can overfit, limiting their generalization capabilities on unseen data.
Advantages of Fine-Tuning
- Efficiency in Training: Utilizing pre-trained models can expedite the training process, as they have already grasped foundational features from extensive datasets.
- Data Economy: Since the model has undergone training on vast datasets, fine-tuning typically demands a smaller amount of data, making it ideal for tasks with limited datasets.
Limitations of Fine-Tuning
- Compatibility Issues: Ensuring that the input and output formats, as well as the architectures and frameworks of the pre-trained model, align with the new task can be challenging.
- Overfitting: Fine-tuning on a small dataset can lead to overfitting, which reduces the model's ability to generalize to new, unseen data.
- Knowledge Degradation: There's a risk that the model might forget some of the features and knowledge acquired during its initial training, a phenomenon often referred to as "catastrophic forgetting."
- Bias Propagation: Pre-trained models might carry inherent biases. When fine-tuned, these biases can be exacerbated, especially in applications that require high sensitivity, such as facial recognition.
Research Breakthroughs Achieved Through Fine-tuning
Fine-tuning in NLP
BERT (Bidirectional Encoder Representations from Transformers) has been a cornerstone in the NLP community. Its architecture allows for capturing context from both directions (left-to-right and right-to-left) in a text, making it highly effective for various NLP tasks.
In 2023, we have seen advancements in BERT and its variants. One such development is "Ferret: Refer and Ground Anything Anywhere at Any Granularity." This Multimodal Large Language Model (MLLM) can understand the spatial reference of any shape or granularity within an image and accurately ground open-vocabulary descriptions. Such advancements highlight the potential of fine-tuning pre-trained models like BERT to achieve specific tasks with high precision.
Fine-tuning in Computer Vision
Models like ResNet and VGG have been foundational in computer vision. These architectures, with their deep layers, have been pivotal in achieving state-of-the-art results on various image classification tasks.
In 2023, a significant breakthrough, "Improved Baselines with Visual Instruction Tuning," was introduced. This research emphasized the progress of large multimodal models (LMM) with visual instruction tuning. Such advancements underscore the importance of fine-tuning in adapting pre-trained models to specific tasks or datasets, enhancing their performance and utility.

Training vs Fine-tuning: Key Takeaways
Training and fine-tuning are pivotal processes in deep learning and machine learning. While training involves initializing model weights and building a new model from scratch using a dataset, fine-tuning leverages pre-trained models and tailors them to a specific task.
Opting for training from scratch is ideal when you have a large dataset vastly different from available pre-trained models like those on Imagenet. It's also the preferred strategy when there's an absence of pre-existing models on platforms like TensorFlow Hub, PyTorch Zoo, or Keras that align with the task.
On the flip side, fine-tuning is advantageous when the dataset at hand is smaller or when the new task mirrors the objectives of the pre-trained model. This approach, backed by optimization techniques like adjusting the learning rate, allows for swifter convergence and frequently culminates in superior performance, especially in scenarios with limited training data.
Future Trends and Predictions: The deep learning community, including platforms like OpenAI, is progressively gravitating towards fine-tuning, especially with the advent of large language models and transformers. This inclination is anticipated to persist, especially with the ascent of transfer learning and the triumph of models like BERT in NLP and ResNet in computer vision. As neural networks evolve and datasets expand, hybrid methodologies that amalgamate the strengths of both training and fine-tuning paradigms may emerge, potentially blurring the demarcation between the two.
Frequently asked questions
Fine-tuning, a cornerstone in natural language processing and image classification, is frequently favored as it leverages the knowledge acquired by pre-trained models. This means that rather than starting training from scratch, the model begins with substantial prior understanding, facilitating rapid convergence and often superior outcomes, especially when the dataset for the new task is constrained.
Theoretically, fine-tuning can be applied to any neural network architecture. Nonetheless, its efficacy predominantly hinges on the similarity between the original task of the pre-trained model and the new task. Architectures like BERT in NLP and ResNet in computer vision have demonstrated adaptability across diverse tasks via fine-tuning.
The decision regarding which layers to fine-tune frequently rests on the task and the magnitude of the dataset. If the new task closely resonates with the foundational objective of the pre-trained model, fine-tuning merely the top layers would suffice.
Conversely, if the tasks diverge significantly, it could be necessary to fine-tune the similarity between the original task of the pre-trained model and the new task, or potentially the entire network. It's routinely advised to begin by fine-tuning the top layers and experimenting with adjusting additional layers if necessary.
Encord enables effective model training by providing robust annotation tools and workflows that support continuous feedback from human annotators. This ensures that the data used for training is not only accurate but also reflective of real-world scenarios, enhancing model performance.
Encord enhances annotation throughput by allowing teams to work concurrently on tasks, with features to auto-assign and manage workloads effectively. This ensures that both fast and slower annotators can contribute to the project based on their availability and speed.
Encord employs rigorous quality control measures and integrates feedback loops within its platform to maintain high annotation standards. This helps teams ensure that their training data is accurate and reliable for machine learning applications.