FastViT: Hybrid Vision Transformer with Structural Reparameterization

In the constantly evolving field of computer vision, recent advancements in machine learning have paved the way for remarkable growth and innovation.
A prominent development in this area has been the rise of Vision Transformers (ViTs), which have demonstrated significant capabilities in handling various vision tasks. These ViTs have begun to challenge the long-standing prominence of Convolutional Neural Networks (CNNs), thanks in part to the introduction of hybrid models that seamlessly combine the advantages of both ViTs and CNNs.
This blog post explores the innovative FastViT model, a hybrid vision transformer that employs structural reparameterization. This approach leads to notable improvements in speed, efficiency, and proficiency in representation learning, marking an exciting development in the field.
Vision Transformers
Vision Transformers, initially introduced by Dosovitskiy et al. in the paper "An Image is Worth 16x16 Words" revolutionized computer vision by directly applying the transformer architecture to image data. Instead of relying on convolutional layers like traditional CNNs, ViTs process images as sequences of tokens, enabling them to capture global context efficiently. However, ViTs often demand substantial computational resources, limiting their real-time application potential.
Hybrid Vision Transformers
Hybrid models combine the best of both worlds – the strong feature extraction capabilities of CNNs and the attention mechanisms of transformers. This synergy leads to improved efficiency and performance. Hybrid Vision Transformers utilize the feature extraction capabilities of CNNs as their backbone and integrate this with the self-attention mechanism inherent in transformers.
Structural Reparameterization
FastViT introduces an innovative concept known as structural reparameterization. This technique optimizes the architecture's structural elements to enhance efficiency and runtime. By carefully restructuring the model, FastViT reduces memory access costs, resulting in significant speed improvements, especially at higher resolutions. The reparameterization strategy aligns with the "less is more" philosophy, underscoring that a well-designed architecture can outperform complex counterparts.
FastViT Architecture
The FastViT architecture builds upon the hybrid concept and structural reparameterization. Instead of using the complex mesh regression layers typically seen in 3D hand mesh estimation models, it employs a more streamlined regression module. This module predicts weak perspective camera, pose, and shape parameters, demonstrating that powerful feature extraction backbones can alleviate the challenges in mesh regression.
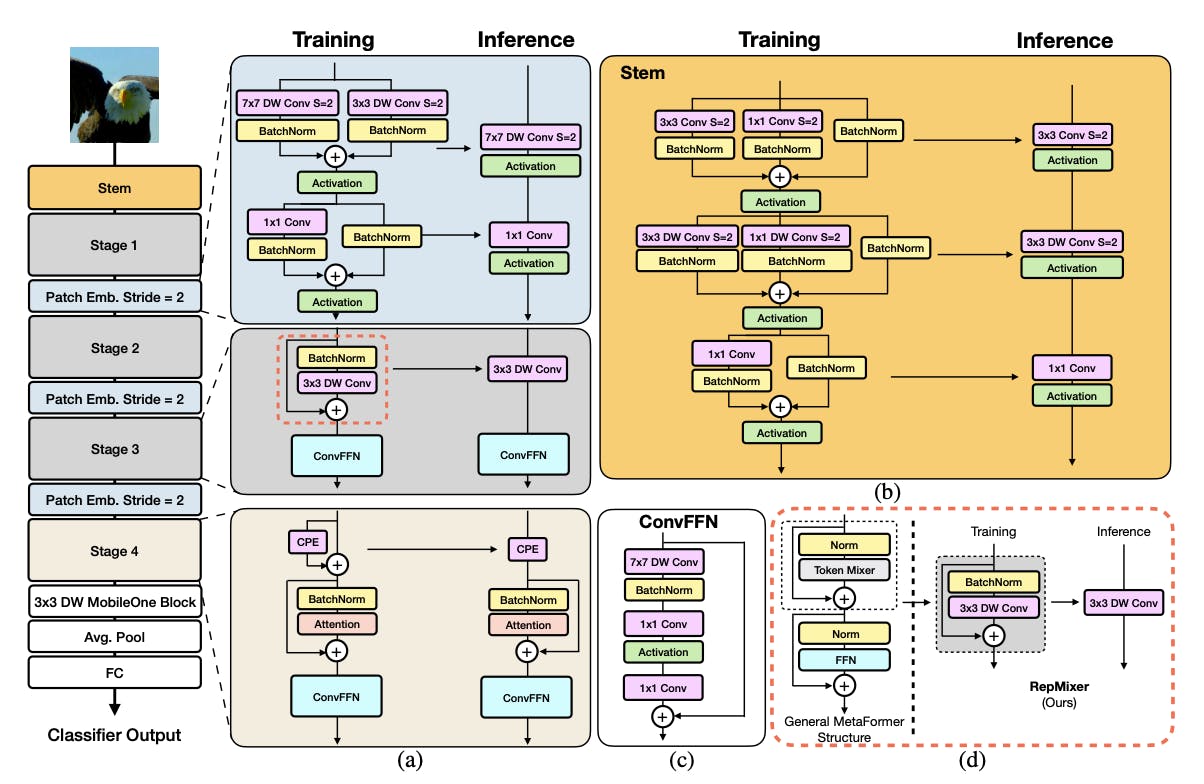
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
FastViT Experiments
In experiments, FastViT showcases speed enhancements, operating 3.5 times faster than CMT, a recent state-of-the-art hybrid transformer architecture. It also surpasses EfficientNet by 4.9 times and ConvNeXt by 1.9 times in speed on a mobile device, all the while maintaining consistent accuracy on the ImageNet dataset. Notably, when accounting for similar latency, FastViT achieves a 4.2% improvement in Top-1 accuracy on ImageNet when compared to MobileOne. These findings highlight the FastViT model's superior efficiency and performance relative to existing alternatives.
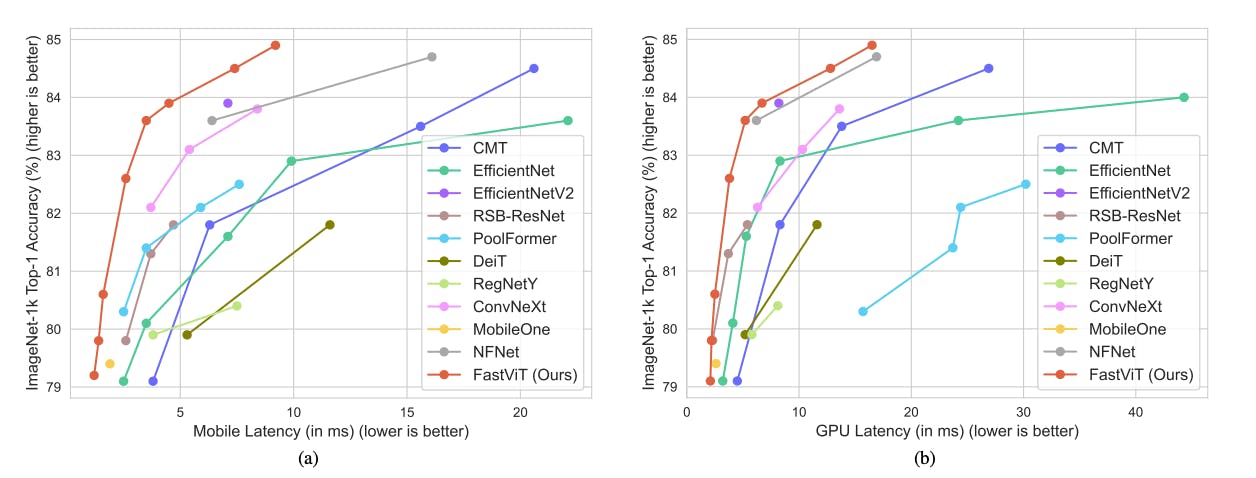
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
Image Classification
FastViT is evaluated against the widely-used ImageNet-1K dataset. The models are trained for several epochs using the AdamW optimizer. The results highlight FastViT's ability to strike an impressive balance between accuracy and latency. It outperforms existing models on both desktop-grade GPUs and mobile devices, showcasing its efficiency and robustness.
Robustness Evaluation
Robustness is vital for practical applications. In this regard, FastViT stands out. It exhibits superior performance against rival models, especially in challenging scenarios where robustness and generalization are crucial. This emphasizes its proficiency in representation learning across diverse contexts.
3D Hand Mesh Estimation
FastViT also performs well in 3D hand mesh estimation, a critical task in gesture recognition. Unlike other techniques that depend on complicated mesh regression layers, FastViT's structural reparameterization allows for a simpler regression module that yields superior results. This approach outperforms existing real-time methods, showcasing its accuracy and efficiency.
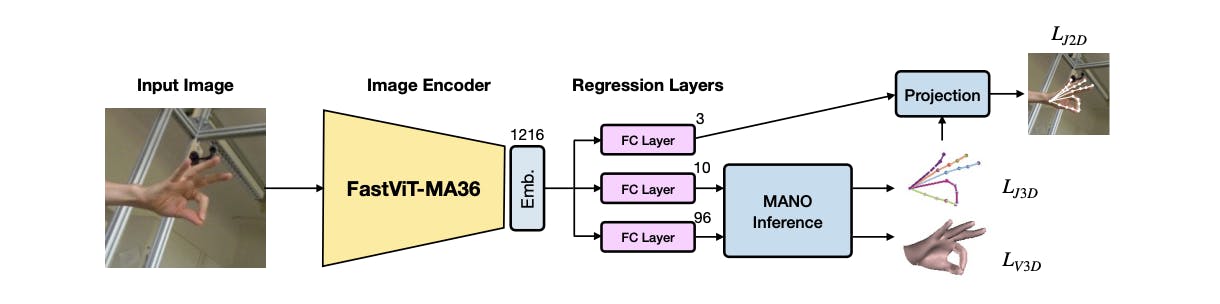
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization as Image Encoder.
Semantic Segmentation & Object Detection
The efficiency of FastViT is also evident in semantic segmentation and object detection tasks. Its performance on the ADE20k dataset and MS-COCO dataset demonstrates versatility and competitiveness in diverse computer vision applications.
FastViT: Key Takeaways
- Efficient Hybrid Vision Transformer: FastViT combines the strengths of Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) to create an efficient hybrid architecture.
- Structural Reparameterization: FastViT introduces a groundbreaking concept known as structural reparameterization, which optimizes the model's architecture for enhanced efficiency and runtime.
- Memory Access Optimization: Through structural reparameterization, FastViT reduces memory access costs, resulting in significant speed improvements, especially for high-resolution images.
- Global Context and Efficiency: FastViT leverages the attention mechanisms of transformers to capture global context efficiently, making it an ideal candidate for a wide range of computer vision tasks.
