Dual-Stream Diffusion Net for Text-to-Video Generation

Even in the rapidly advancing field of artificial intelligence, converting text to captivating video content remains a challenge. The introduction of Dual-Stream Diffusion Net (DSDN) represents a significant innovation in text-to-video generation, creating a solution that combines text and motion to create personalized and contextually rich videos.
In this article, we will explore the intricacies of Hugging Face’s new Dual-Stream Diffusion Net, decoding its architecture, forward diffusion process, and dual-stream mechanism. By examining the motion decomposition and fusion process, we can understand how DSDN generates realistic videos. With empirical evidence from experiments, we establish DSDN's superiority.
DSDN’s implications reach beyond technology; it also marks a step forward in the future of content creation and human-AI collaboration. Far from being simply a video-generation tool, DSDN contributes to crafting experiences that resonate with audiences, revolutionizing entertainment, advertising, education, and more.
Text-to-Video Generation
Transforming textual descriptions into visual content is both an exciting and challenging task. This endeavor not only advances the field of natural language processing but also unlocks extensive possibilities for various applications like entertainment, advertising, education, and surveillance.
While text-to-image generation has been well researched, AI text-to-video generation introduces an additional layer of complexity. Videos carry not only spatial content but also dynamic motion, making the generation process more intricate. Although recent progress in diffusion models have offered promising solutions, challenges such as flickers and artifacts in generative in generated videos remain a bottleneck.
Dual-Stream Diffusion Net: Architecture
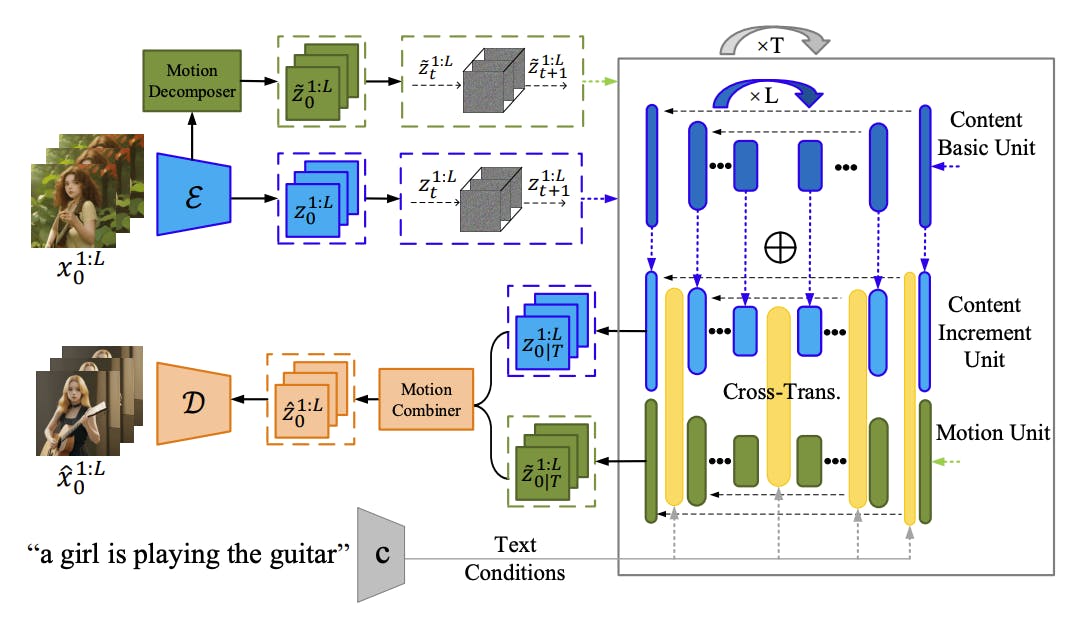
To address the limitations of existing methods, Hugging Face has proposed a novel approach called the Dual-Stream Diffusion Net (DSDN). Specifically engineered to improve consistency in content variations within generated videos, DSDN integrates two independent diffusion streams: a video content branch and a motion branch. These streams operate independently to generate personalized video variations while also being aligned to ensure smooth and coherent transitions between content and motion.
Dual-Stream Diffusion Net for Text-to-Video Generation
Forward Diffusion Process
The foundation of DSDN lies in the Forward Diffusion Process (FDP), a key concept inspired by the Denoising Diffusion Probabilistic Model (DDPM). In the FDP, latent features undergo a noise perturbation through a Markov process. The shared noising schedule between the two streams ensures that the content and motion branches progress in harmony during the diffusion process. This prepares the priors necessary for the subsequent denoising steps.
Personalized Content Generation Stream
The content generation process leverages a pre-trained text-to-image conditional diffusion model and an incremental learning module introduced by DSDN. The model dynamically refines content generation through a content basic unit and a content increment unit. This combination not only maintains the content's quality but also ensures that personalized variations align with the provided text prompts.
Personalized Motion Generation Stream
Motion is addressed through a Personalized Motion Generation Stream. The process utilizes a 3D U-Net based diffusion model to generate motion-coherent latent features. These features are generated alongside content features and are conditioned on both content and textual prompts. This method ensures that the generated motion is aligned with the intended content and context.
Dual-Stream Transformation Interaction
One of DSDN’s distinct features is the Dual-Stream Transformation Interaction module. By employing cross-transformers, this module establishes a connection between the content and motion streams. During the denoising process, information from one stream is integrated into the other, enhancing the overall continuity and coherence of the generated videos. This interaction ensures that content and motion are well-aligned, resulting in smoother and more realistic videos.
Motion Decomposition and Combination
DSDN introduces motion decomposition and combination techniques to manage motion information more effectively. The system employs a motion decomposer that extracts motion features from adjacent frames, capturing the inter-frame dynamics. These motion features are subsequently combined with content features using a motion combiner. This approach enhances the generation of dynamic motion while maintaining content quality.
Dual-Stream Diffusion Net: Experiments
The experimental evaluation of the Dual-Stream Diffusion Net (DSDN) highlights it promise in the field of text-to-video generation relative to comparable models such as CogVideo and Text2Video-Zero. DSDN emerges as a definitive frontrunner, surpassing established benchmarks with its remarkable performance and innovative approach.

Dual-Stream Diffusion Net for Text-to-Video Generation
DSDN's exceptional ability to maintain frame-to-frame consistency and text alignment makes it stand out. For the assessment, CLIP image embeddings are computed. Unlike its counterparts that exhibit discrepancies in contextual alignment, DSDN masters the art of integrating textual inputs flawlessly into the visual narrative. This unparalleled ability underscores DSDN's deep comprehension of linguistic subtleties, yielding videos that remain faithful to the essence of the input text.
In terms of content quality and coherence, DSDN shows promising results. Where CogVideo and Text2Video-Zero may struggle with maintaining motion coherence and generating content that resonates with user preferences, DSDN excels. Its unique dual-stream architecture, combined with stable diffusion techniques, ensures that the generated videos possess both visual appeal and contextual accuracy. This dynamic fusion transforms synthetic content into captivating visual stories, a feat that other models struggle to achieve.
Dual-Stream Diffusion Net: Key Takeaways
- The Dual-Stream Diffusion Net (DSDN) architecture combines personalized content and motion generation for context-rich video creation.
- DSDN's dual-stream approach enables simultaneous yet cohesive development of video content and motion, yielding more immersive and coherent videos.
- Through meticulous motion decomposition and recombination, DSDN achieves seamless integration of elemental motion components, enhancing visual appeal.
- DSDN explores the interaction between content and motion streams, iteratively refining their fusion to produce highly realistic and personalized videos.
- Empirical experiments demonstrate DSDN's superiority, surpassing existing methods in contextual alignment, motion coherence, and user preference in content generation, signifying its transformative potential in content generation.
