Guide to Vision-Language Models (VLMs)

Product Manager at Encord
In this article, we explore the architectures, evaluation strategies, and mainstream datasets used in developing VLMs, as well as the key challenges and future trends in the field. By understanding these foundational aspects, readers will gain insights into how VLMs can be applied across industries, including healthcare, robotics, and media, to create more sophisticated, context-aware AI systems.
For quite some time, the idea that artificial intelligence (AI) could understand visual and textual cues as effectively as humans seemed far-fetched and unimaginable.
However, with the emergence of multimodal AI, we are seeing a revolution where AI can simultaneously comprehend various modalities, such as text, image, speech, facial expressions, physiological gestures, etc., to make sense of the world around us. The ability to process multiple modalities has opened up various avenues for AI applications.
One exciting application of multimodal AI is Vision-Language Models (VLMs). These models can process and understand the modalities of language (text) and vision (image) simultaneously to perform advanced vision-language tasks, such as Visual Question Answering (VQA), image captioning, and Text-to-Image search.
In this article, you will learn about:
- VLM architectures.
- VLM evaluation strategies.
- Mainstream datasets used for developing vision-language models.
- Key challenges, primary applications, and future trends of VLMs.
Let’s start by understanding what vision-language models are.
What Are Vision Language Models?
A vision-language model is a fusion of vision and natural language models. It ingests images and their respective textual descriptions as inputs and learns to associate the knowledge from the two modalities. The vision part of the model captures spatial features from the images, while the language model encodes information from the text.
The data from both modalities, including detected objects, the spatial layout of the image, and text embeddings, are mapped to each other. For example, if the image contains a bird, the model will learn to associate it with a similar keyword in the text descriptions.
This way, the model learns to understand images and transforms the knowledge into natural language (text) and vice versa.
Training VLMs
Building VLMs involves pre-training foundation models and zero-shot learning. Transfer learning techniques, such as knowledge distillation, can be used to fine-tune the models for more specific downstream tasks.
These are simpler techniques that require smaller datasets and less training time while maintaining decent results.
Modern frameworks, on the other hand, use various techniques to get better results, such as
- Contrastive learning.
- Masked language-image modeling.
- Encoder-decoder modules with transformers and more.
These architectures can learn complex relations between the various modalities and provide state-of-the-art results. Let’s discuss these in detail.
{{Feb_light_CTA}}
Vision Language Models: Architectures and Popular Models
Let’s look at some VLM architectures and the learning techniques that mainstream models such as CLIP, Flamingo, and VisualBert, among others, use.
Contrastive Learning
Contrastive learning is a technique that learns data points by understanding their differences. The method computes a similarity score between data instances and aims to minimize contrastive loss. It’s most useful in semi-supervised learning, where only a few labeled samples guide the optimization process to label unseen data points.

For example, one way to understand what a cat looks like is to compare it to a similar cat image and a dog image. Contrastive learning models learn to distinguish between a cat and a dog by identifying features such as facial structure, body size, and fur. The models can determine which image is closer to the original, called the “anchor,” and predict its class.
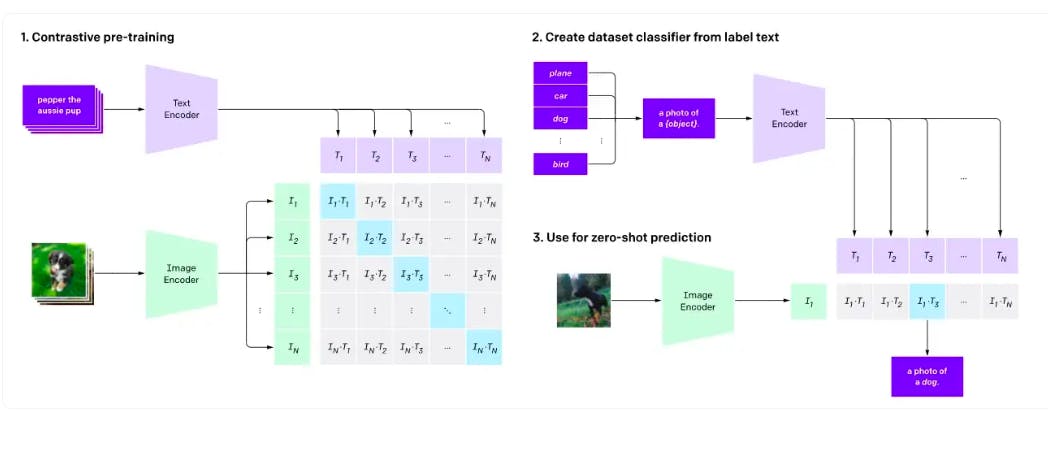
CLIP is an example of a model that uses contrastive learning by computing the similarity between text and image embeddings using textual and visual encoders. It follows a three-step process to enable zero-shot predictions.
- Trains a text and image encoder during pretraining to learn the image-text pairs.
- Converts training dataset classes into captions.
- Estimates the best caption for the given input image for zero-shot prediction.
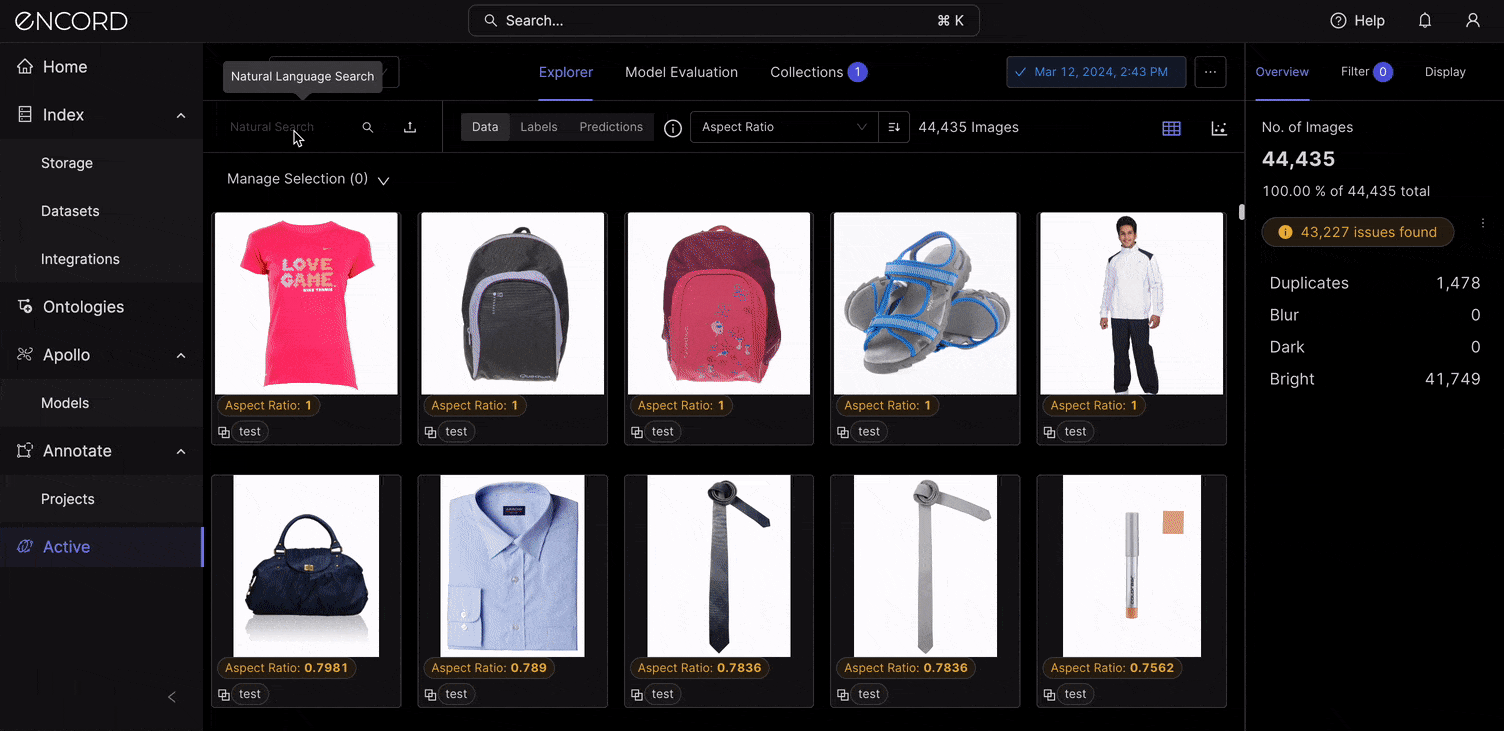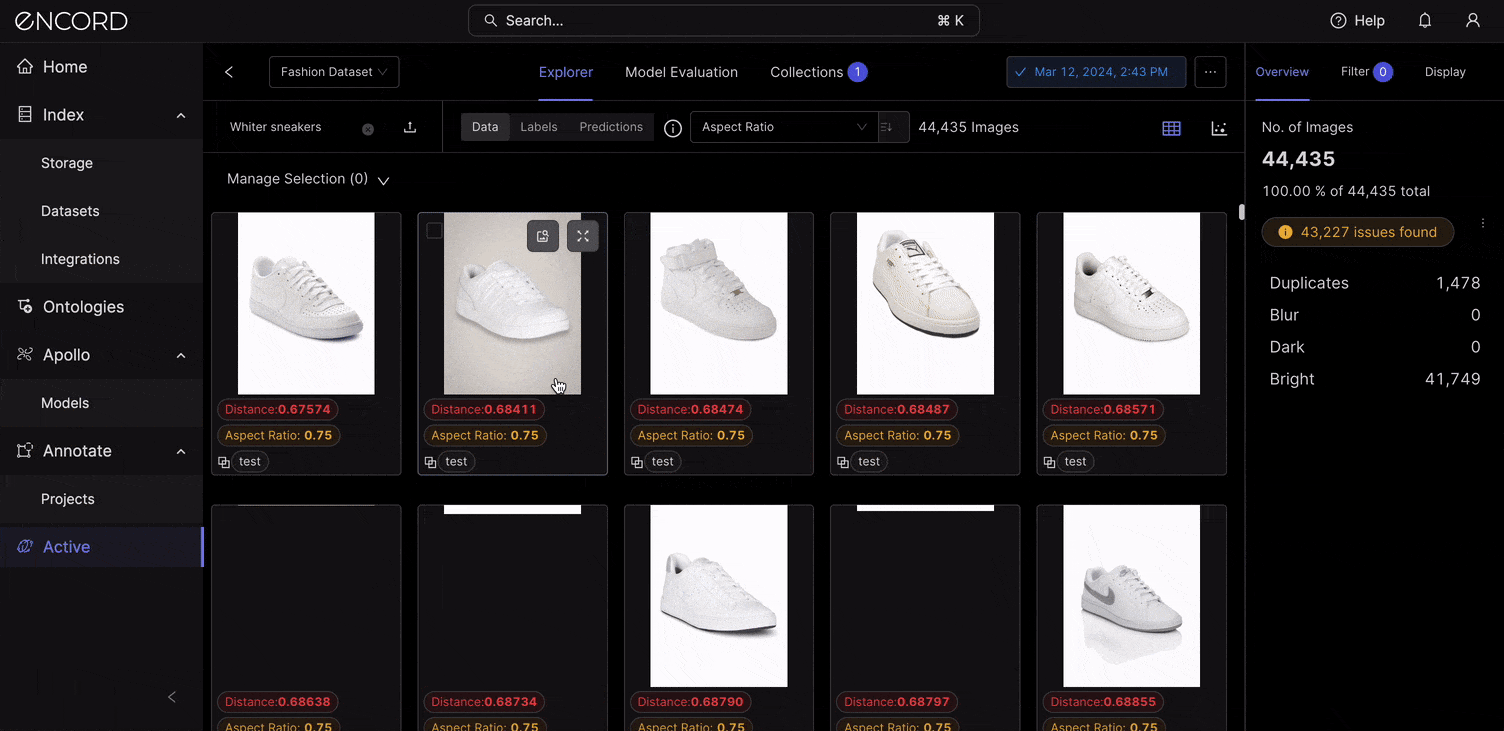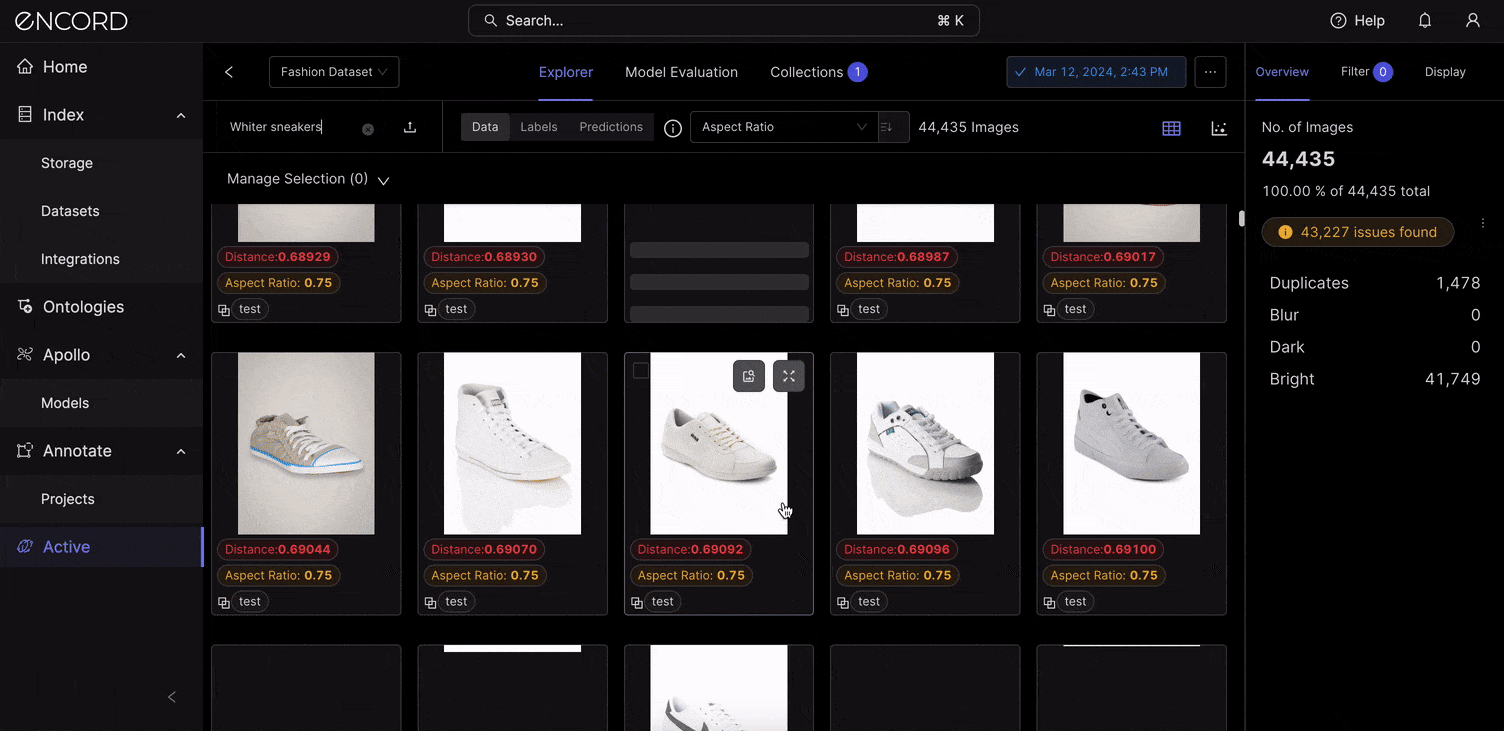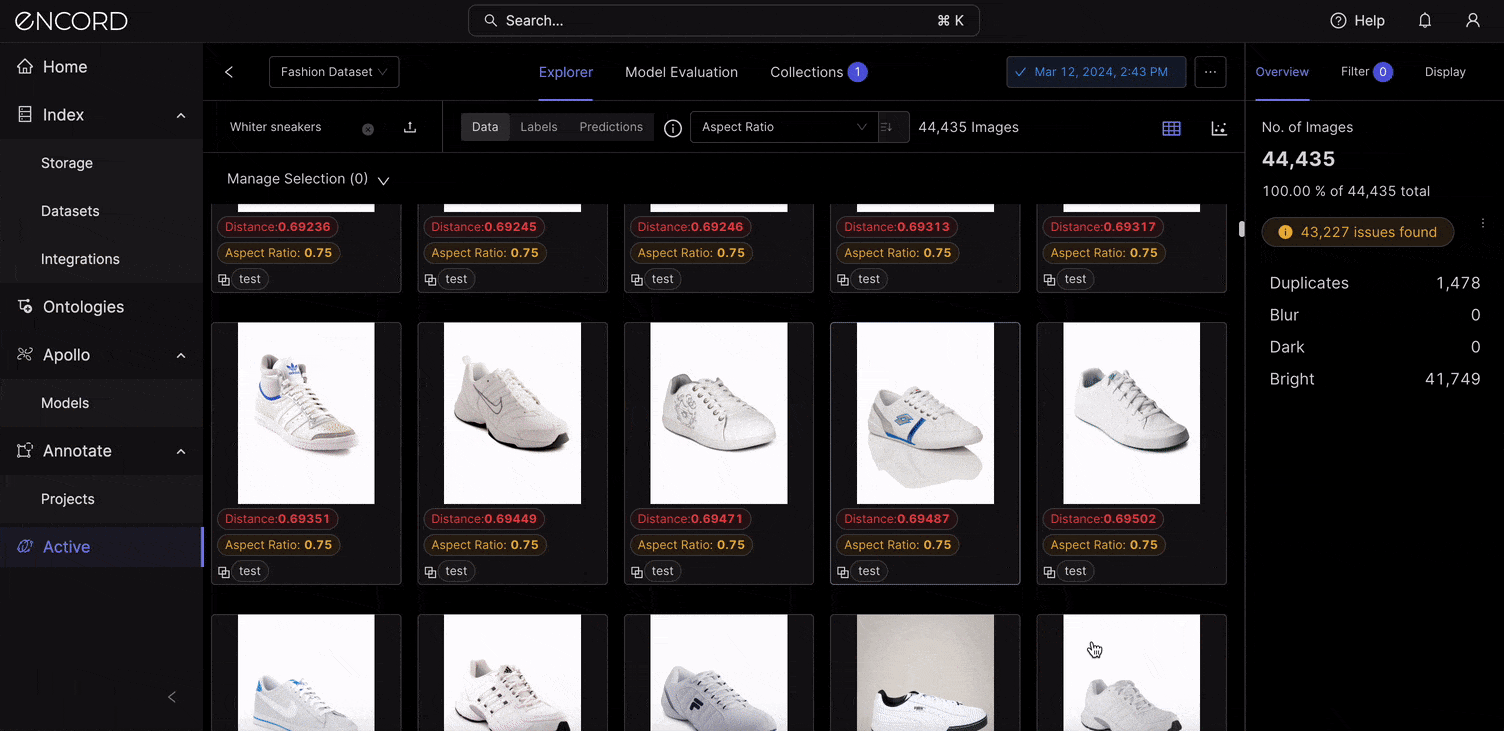
VLMs like CLIP power the semantic search feature within Encord Active. When you log into Encord → Active → Choose a Project → Use the Natural Language search to find items in your dataset with a text description. Here is a way to search with natural language using “White sneakers” as the query term:
ALIGN is another example that uses image and textual encoders to minimize the distance between similar embeddings using a contrastive loss function.
PrefixLM
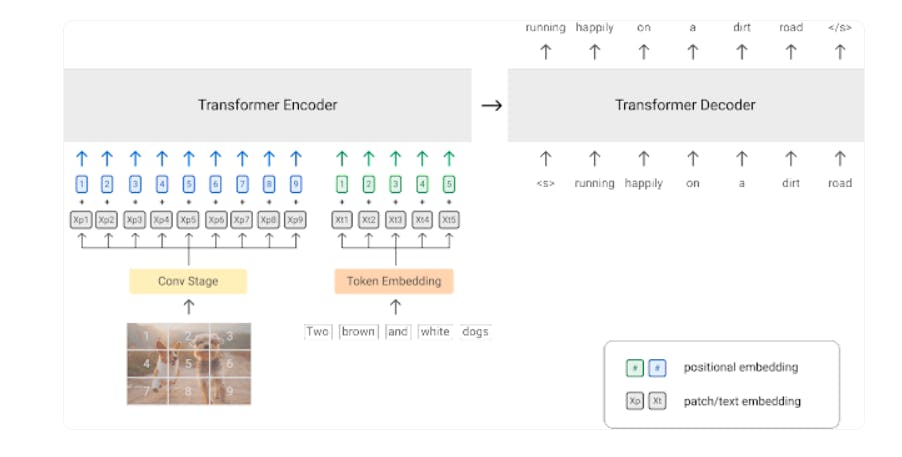
PrefixLM is an NLP learning technique mostly used for model pre-training. It inputs a part of the text (a prefix) and learns to predict the next word in the sequence. In Visual Language Models, PrefixLM enables the model to predict the next sequence of words based on an image and its respective prefix text. It leverages a Vision Transformer (ViT) that divides an image into a one-dimensional patch sequence, each representing a local image region.
Then, the model applies convolution or linear projection over the processed patches to generate contextualized visual embeddings. For text modality, the model converts the text prefix relative to the patch into a token embedding. The transformer's encoder-decoder blocks receive both visual and token embeddings. It is there that the model learns the relationships between the embeddings.
SimVLM is a popular architecture utilizing the PrefixLM learning methodology. It has a simpler Transformer architecture than its predecessors, surpassing their results in various benchmarks.
It uses a transformer encoder to learn image-prefix pairs and a transformer decoder to generate an output sequence. The model also demonstrates good generalization and zero-shot learning capabilities.
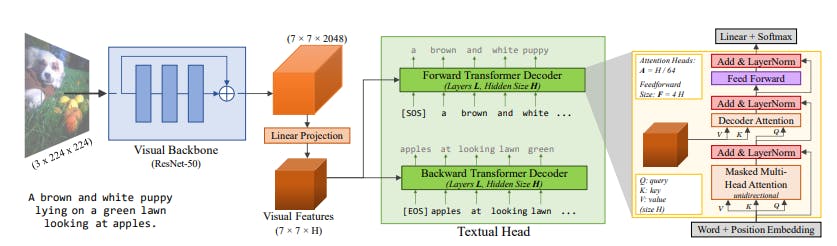
Similarly, VirTex uses a convolutional neural network to extract image features and a textual head with transformers to manage text prefixes. You can train the model end-to-end to predict the correct image captions by feeding image-text pairs to the textual head.
Frozen PrefixLM
While PrefixLM techniques require training visual and textual encoders from scratch, Frozen PrefixLM allows you to use pre-trained networks and only update the parameters of the image encoders.
For instance, the architecture below shows how Frozen works using a pre-trained language model and visual encoder. The text encoder can belong to any large language model (LLM), and the visual encoder can also be a pre-trained visual foundation model.
You can fine-tune the image encoder so its image representations align with textual embeddings, allowing the model to make better predictions.
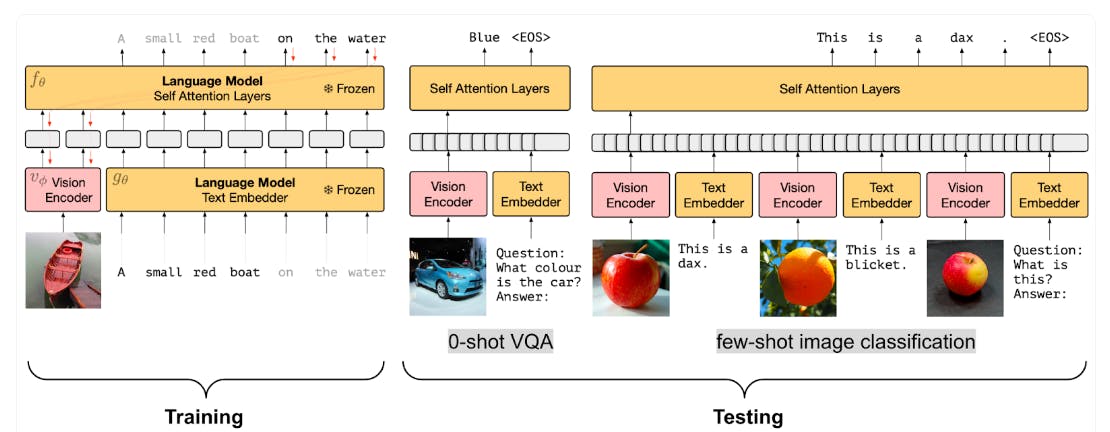
Flamingo's architecture uses a more state-of-the-art (SOTA) approach. It uses a CLIP-like vision encoder and an LLM called Chinchilla. Keeping the LLM fixed lets you train the visual encoder on images interleaved between texts.
The visual encoders process the image through a Perceiver Sampler. The technique results in faster inference and makes Flamingo ideal for few-shot learning.
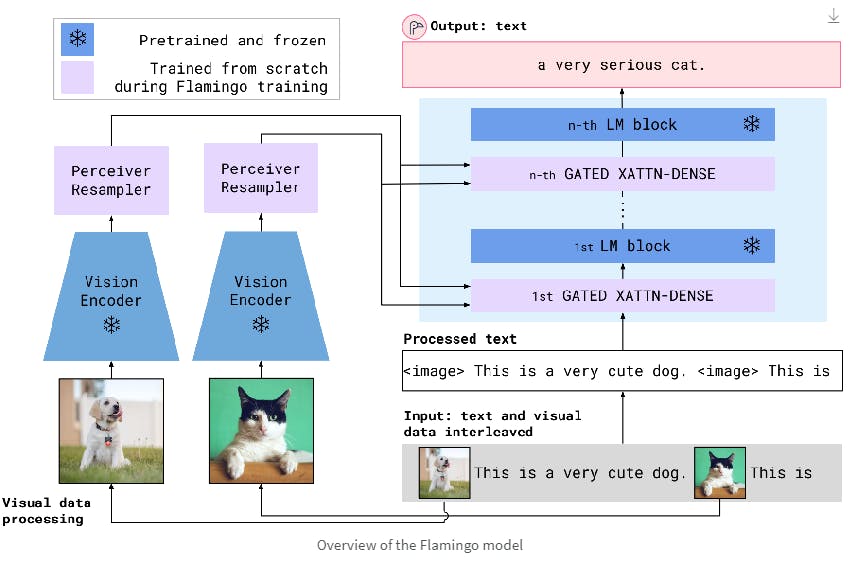
Multimodal Fusing with Cross-Attention
This method utilizes the encoders of a pre-trained LLM for visual representation learning by adding cross-attention layers. VisualGPT is a primary example that allows quick adaptation of an LLM’s pre-trained encoder weights for visual tasks.
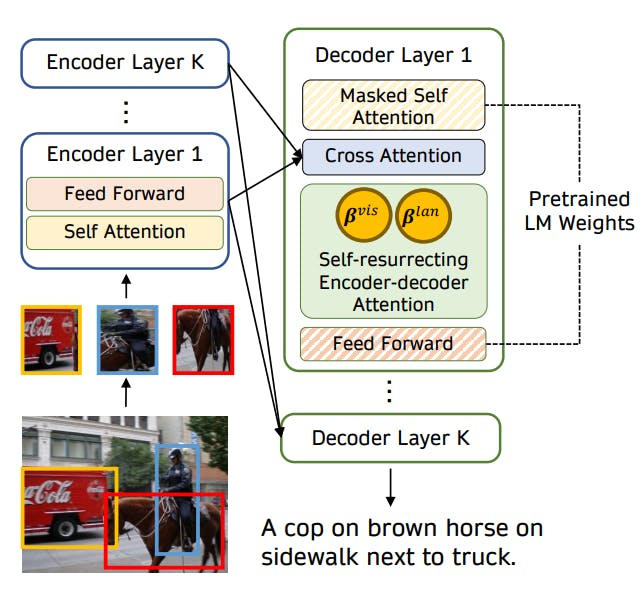
Practitioners extract relevant objects from an image input and feed them to a visual encoder. The resulting visual representations are then fed to a decoder and initialized with weights according to pre-trained LLM. The decoder module balances the visual and textual information through a self-resurrecting activation unit (SRAU).
The SRAU method avoids the issue of vanishing gradients, a common problem in deep learning where model weights fail to update due to small gradients. As such, VisualGPT outperforms several baseline models, such as the plain transformer, the Attention-on-Attention (AoA) transformer, and the X-transformer.
Masked-language Modeling (MLM) & Image-Text Matching (ITM)
MLM works in language models like BERT by masking or hiding a portion of a textual sequence and training the model to predict the missing text. ITM involves predicting whether sentence Y follows sentence X.
You can adapt the MLM and ITM techniques for visual tasks. The diagram below illustrates VisualBERT's architecture, trained on the COCO dataset.
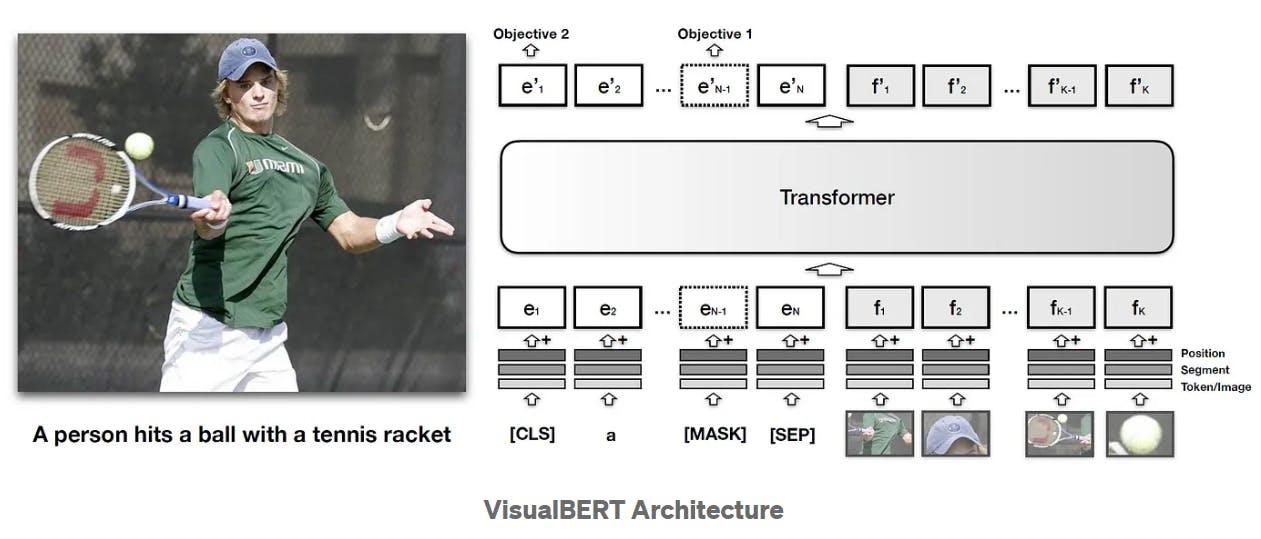
It augments the MLM procedure by introducing image sequences and a masked textual description. Based on visual embeddings, the objective is to predict the missing text. Similarly, ITM predicts whether or not a caption matches the image.
No Training
You can directly use large-scale, pre-trained vision-language models without any fine-tuning. For example, MAGIC and ASIF are training-free frameworks that aim to predict text descriptions that align closely with the input image.
MAGIC uses a specialized score based on CLIP-generated image embeddings to guide language models' output. Using this score, an LLM generates textual embeddings that align closely with the image semantics, enabling the model to perform multimodal tasks in a zero-shot manner.
ASIF uses the idea that similar images have similar captions. The model computes the similarities between the training dataset's query and candidate images. Next, it compares the query image embeddings with the text embeddings of the corresponding candidate images.
Then, it predicts a description whose embeddings are the most similar to those of the query image, resulting in comparable zero-shot performance to models like CLIP and LiT.
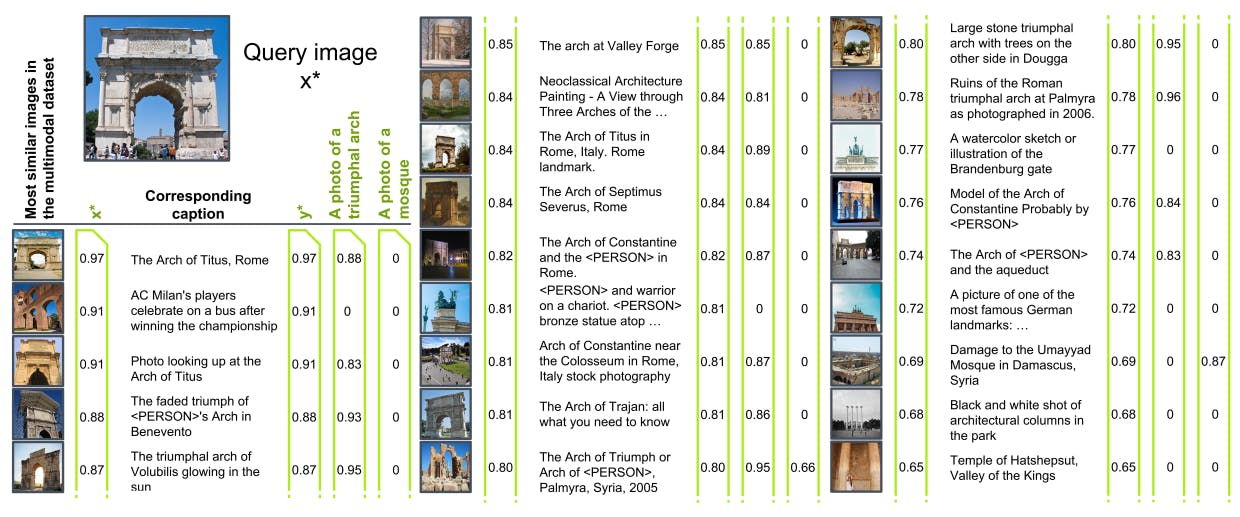
Knowledge Distillation
This technique involves transferring knowledge from a large, well-trained teacher model to a lighter student model with few parameters. This methodology allows researchers to train VLMs from larger, pre-trained models.
For instance, ViLD is a popular VLM developed using the knowledge distillation methodology. The model uses a pre-trained open-vocabulary image classification model as the teacher to train a two-stage detector (student).
The model matches textual embeddings from a textual encoder with image embeddings.
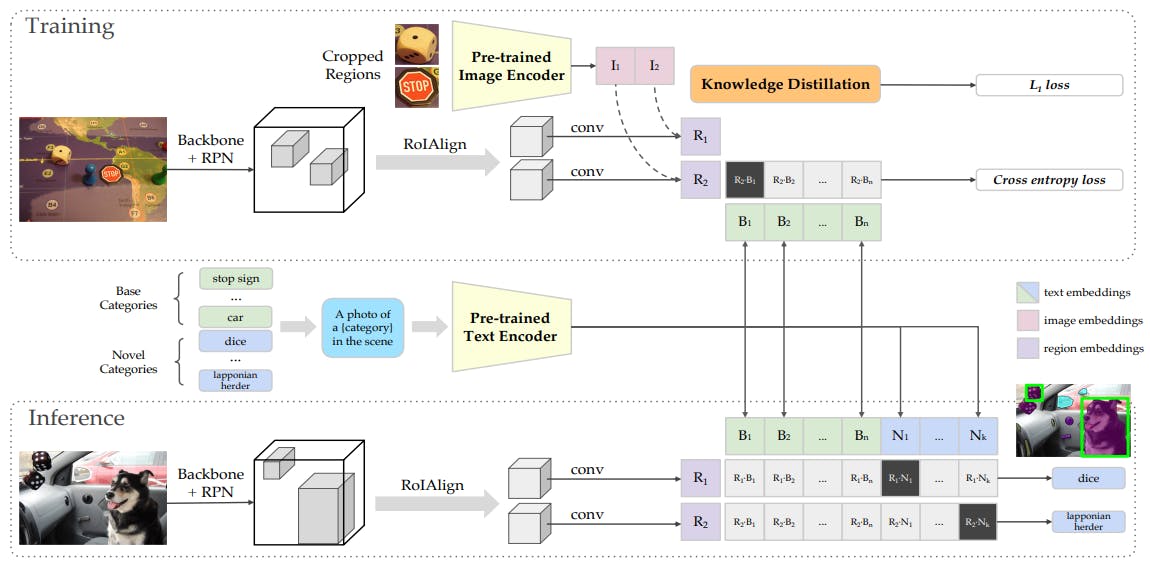
Knowledge distillation transfers knowledge from the image encoder to the backbone model to generate regional embeddings automatically. Only the backbone model generates regional embeddings during inference, and it matches them with unseen textual embeddings.
The objective is to draw correct bounding boxes around objects in an image based on textual descriptions.
Evaluating Vision Language Models
VLM validation involves assessing the quality of the relationships between the image and text data. For an image captioning model, this would mean comparing the generated captions to the ground-truth description.
You can use various automated n-gram-based evaluation strategies to compare the predicted labels in terms of accuracy, semantics, and information precision. Below are a few key VLM evaluation metrics.
- BLEU: The Bilingual Evaluation Understudy (BLEU) metric was originally proposed to evaluate machine translation tasks. It computes the precision of the target text compared to a reference (ground truth) by considering how many words in the candidate sentence appear in the reference.
- ROUGE: Recall-Oriented Understudy for Gisting Evaluation (ROUGE) computes recall by considering how many words in the reference sentence appear in the candidate.
- METEOR: Metric for Evaluation of Translation with Explicit Ordering (METEOR) computes the harmonic mean of precision and recall, giving more weight to recall and multiplying it with a penalty term. The metric is an improvement over others that work with either Precision or Recall, as it combines information from both to give a better evaluation.
- CIDEr: Consensus-based Image Description Evaluation (CIDEr) compares a target sentence to a set of human sentences by computing the average similarity between reference and target sentences using TF-IDF scores.
Now that you have learned evaluation metrics pertinent to Vision-Language Models (VLMs), knowing how to curate datasets for these models is essential. A suitable dataset provides fertile ground for training and validating VLMs and is pivotal in determining the models' performance across diverse tasks.
Datasets for Vision Language Models
Collecting training data for VLMs is more challenging than traditional AI models since it involves the collection and quality assurance of multiple data modalities. Encord Index streamlines this process by providing comprehensive data management and curation solutions. Below is a list of several datasets combining image and text data for multimodal training.
- LAION-5B: Practitioners use the LAION-5B dataset to build large, pre-trained VLMs. The dataset contains over five billion image-text pairs generated from CLIP, with descriptions in English and foreign languages, catering to a multilingual domain.
- PMD: The Public Model Dataset (PMD) originally appeared in the FLAVA paper and contains 70 billion image-text pairs. It is a collection of data from other large-scale datasets, such as COCO, Conceptual Captions (CC), RedCaps, etc. This dataset is a reservoir of multimodal data that fosters robust model training.
- VQA: Experts use the VQA dataset to fine-tune pre-trained VLMs for downstream VQA and visual reasoning tasks. The dataset contains over 200,000 images, with five questions per image, ten ground-truth answers, and three incorrect answers per question.
- ImageNet: ImageNet contains over 14 million images with annotations categorized according to the WordNet hierarchy. It’s helpful in building models for simple downstream tasks, such as image classification and object recognition.
Training a strong vision-language model depends on well-aligned image-text pairs. See how Data curation for multimodal data keeps captions and images accurate after cleaning.
Despite the availability of high-quality multimodal datasets, VLMs can face significant challenges during the model development process. Let’s discuss them below.

Limitations of Vision Language Models
Although VLMs are powerful in understanding visual and textual modalities to process information, they face three primary challenges:
- Model complexity.
- Dataset bias.
- Evaluation difficulties.
Model Complexity
Language and vision models are quite complex on their own, and combining the two only worsens the problem. Their complexity raises additional challenges in acquiring powerful computing resources for training, collecting large datasets, and deploying on weak hardware such as IoT devices.
Dataset Bias
Dataset biases occur when VLMs memorize deep patterns within training and test sets without solving anything. For instance, training a VLM on images curated from the internet can cause the model to memorize specific patterns and not learn the conceptual differences between various images.
Evaluation Strategies
The evaluation strategies discussed above only compare a candidate sentence with reference sentences. The approach assumes that the reference sentences are the only ground truths. However, a particular image can have several ground-truth descriptions.
Although consensus-based metrics like CIDEr account for the issue, using them becomes challenging when consensus is low for particular images. Another challenge is when a generic description applies to several images.

As the illustration shows, a VLM can annotate or retrieve several relevant images that match the generic caption. However, in reality, the model is nothing more than a bag-of-words. All it’s doing is considering words, such as ‘city,’ ‘bus,’ ‘lights,’ etc., to describe the image instead of actually understanding the caption's sequential order and true contextual meaning.
Furthermore, VLMs used for VQA can generate highly confident answers to nonsensical questions. For instance, asking a VLM, “What color is the car?” for an image that contains a white horse will generate the answer as “white” instead of pointing out that there isn’t a car in the picture.
Lastly, VLMs lack compositional generalization. This means that their performance decreases when they process novel concepts. For example, a VLM can fail to recognize a yellow horse as a category since it’s rare to associate the color yellow with horses.
Despite many development and deployment challenges, researchers and practitioners have made significant progress in adopting VLMs to solve real problems. Let’s discuss them briefly below.
Applications of Vision Language Models
While most VLMs discussed earlier are helpful in captioning images, their utility extends to various domains that leverage the capability to bridge visual and linguistic modalities. Here are some additional applications:
- Image Retrieval: Models such as FLAVA help users navigate through image repositories by helping them find relevant photos based on linguistic queries. An e-commerce site is a relevant example. Visitors can describe what they’re looking for in a search bar, and a VLM will show the suitable options on the screen. This application is also popular on smartphones, where users can type in keywords (landscapes, buildings, etc.) to retrieve associated images from the gallery.
- Generative AI: Image generation through textual prompts is a growing domain where models like DALL-E allow users to create art or photos based on their descriptions. The application is practical in businesses where designers and inventors want to visualize different product ideas. It also helps create content for websites and blogs and aids in storytelling.
- Segmentation: VLMs like SegGPT help with segmentation tasks such as instance, panoptic, semantic, and others. SegGPT segments an image by understanding user prompts and exploiting a distinct coloring scheme to segment objects in context. For instance, users can ask SegGPT to segment a rainbow from several images, and SegGPT will efficiently annotate all rainbows.
Future Research
The following are a few crucial future research directions in the VLM domain:
Better Datasets
The research community is working on building better training and test datasets to help VLMs with compositional understanding. CLEVR is one example of this effort.

As the illustration shows, it contains images of novel shapes, colors, and corresponding questions that allow experts to test a VLM’s visual reasoning capacity.
Better Evaluation Methods
Evaluation challenges warrant in-depth research into better evaluation methods for building more robust VLMs. One alternative is to test VLMs for individual skills through the ARO benchmark.
Attribute identification, relational reasoning, and word-order sensitivity (ARO) are three skills that VLMs must master.

The illustration above explains what ARO entails in different contexts. Using such a dataset, experts can analyze what VLMs learn and how to improve the outcomes.
Robotics
Researchers are also using VLMs to build purpose-specific robots. Such robots can help navigate environments, improve warehouse operations in manufacturing by monitoring items, and enhance human-machine interaction by allowing robots to understand human gestures, such as facial expressions, body language, voice tones, etc.
Medical VQA
VLMs’ ability to annotate images and recognize complex objects can help healthcare professionals with medical diagnoses. For example, they can ask VLMs critical questions about X-rays or MRI scans to determine potential problems early.
Vision-Language Models: Key Takeaways
Visual language modeling is an evolving field with great promise for the AI industry. Below are a few critical points regarding VLMs:
- Vision-language models are a multimodal architecture that simultaneously comprehends image and text data modalities.
- They use CV and NLP models to correlate information (embeddings) from the two modalities.
- Several VLM architectures exist that aim to relate visual semantics to textual representations.
- Although users can evaluate VLMs using automated scores, better evaluation strategies are crucial to building more reliable models.
- VLMs have many industrial use cases, such as robotics, medical diagnoses, chatbots, etc.
Frequently asked questions
Vision Language Models (VLMs) combine computer vision (CV) and natural language processing (NLP) capabilities to perform tasks such as image captioning, image retrieval, generative AI, visual reasoning, etc.
VisualBERT, Visual ChatGPT, Flamingo, and CLIP are all examples of popular vision-language models (VLMs).
Vision-language models mainly transform images and text into embeddings and attempt to minimize loss by matching similar embeddings in the semantic space.
Language models are good at processing natural language. They’re helpful for language tasks, such as sentiment analysis, text classification, topic categorization, and text generation.
Several methods exist to train VLMs. Contrastive learning, masked language modeling, PrefixLM, and knowledge distillation are popular methods.
State-of-the-art pre-trained vision-language models learn primitive concepts such as colors, shapes, attributes, etc. However, the models have low interpretability, so it isn’t easy to understand how they learn these concepts.
Fundamentally, a language model is a probabilistic model that tries to predict the following words or sentences in a given sequence.
A traditional language model cannot process visual inputs. A vision-language model can simultaneously handle visual and textual modalities for several downstream tasks.
Depending on how you train a VLM, outputs can include image captions, descriptions, summaries, bounding boxes, segmentations, and answers to questions related to an image.
Encord facilitates the integration of DICOM images with natural language processing capabilities to handle the complexity of image reports. By addressing the challenges of unlabeled data and varying report accuracy, Encord enables teams to effectively correlate images with their corresponding textual reports, enhancing the overall data analysis process.
Encord supports the development of vision-language models by providing tools for annotating video and image data, which are essential for training models on complex tasks such as pick and place. The platform's capabilities enable users to collect and annotate data efficiently, facilitating the rapid development and deployment of machine learning models.
Encord supports the training of various models, including those for object detection tasks, where users can draw bounding boxes around objects, and video captioning tasks, which involve annotating key moments in video footage. This flexibility allows users to tailor their model training to specific project requirements.
Yes, Encord is designed to be adaptable and can support the integration of different AI models, including those based on vision-language models (VLM) and vision-language architectures (VLA). This flexibility allows teams to experiment with and implement the latest AI innovations in their robotics projects.
Encord facilitates multi-modal training by providing robust annotation tools that support both image and text data. This allows users to annotate images alongside textual descriptions, which is essential for training complex models that understand both visual and linguistic information.
Encord provides advanced vision reasoning capabilities that help clients understand and validate robotic actions. This includes scene understanding, where the platform analyzes whether a robotic arm has successfully picked up an object and identifies anomalies in the process.
Encord allows users to integrate various models into the annotation workflow seamlessly. Users can orchestrate model stages for post-processing, decision-making, and routing, enabling a more dynamic and efficient annotation experience that leverages existing infrastructure.
Yes, Encord has the capability to automate annotation through the use of vision libraries. This feature streamlines the identification of objects within datasets, facilitating a human-in-the-loop approach to refine and validate automated annotations for improved accuracy.
Encord provides tools to help evaluate various vision-language models (VLMs) and supports the stacking of custom object detectors. This allows users to select images, assign them to specific models, and fine-tune or retrain the VLMs as needed for their unique use cases.
Encord provides robust annotation capabilities for vision tasks, including frame classification and defect detection. The platform supports semantic understanding to enrich binary classifications with explanations, enhancing the overall utility of the annotations.