The Advantages and Disadvantages of Synthetic Training Data

ML Lead at Encord
In another article, we introduced you to synthetic training data. Now let’s look more closely at the advantages and disadvantages of using synthetic data in computer vision and machine learning models.
The most obvious advantage of synthetic training data is that it can supplement image and video-based datasets that otherwise would lack sufficient examples to train a model. As a general rule, having a larger volume of higher-quality training data improves the performance and accuracy of a model, so synthetic data can play a crucial role for data scientists working in fields and on use cases that suffer from a scarcity of data.
However, using synthetic data comes with pros and cons. Let’s examine some advantages and disadvantages of using synthetic training data to train machine learning algorithms.
Advantages of synthetic data for computer vision models
There are several advantages to investing in synthetic data for computer vision models.
Helps solve the problems of edge cases and outliers, and reduces data bias
When high-stakes computer vision and machine learning models, such as those used to run autonomous vehicles/self-driving cars or diagnose patients, run in the real world, they need to be able to deal with edge cases. Because edge cases are outliers, finding enough real-world examples to create a large enough dataset and train a model can sometimes feel like searching for a needle in a haystack.
With a synthetic dataset, that problem is solved. Theoretically, you can create as much data as you need without worrying about running out of the right number of images and videos that cover enough variables.
For instance, think of data science professionals training a model to diagnose a rare genetic condition. Because the condition is rare, the real-world sample of patients to collect data is likely too small to train a model effectively. There won’t be enough images or datasets containing those images to make a viable training dataset. Generating synthetic data can circumvent the challenge of creating and labeling large enough data from a small sample size.
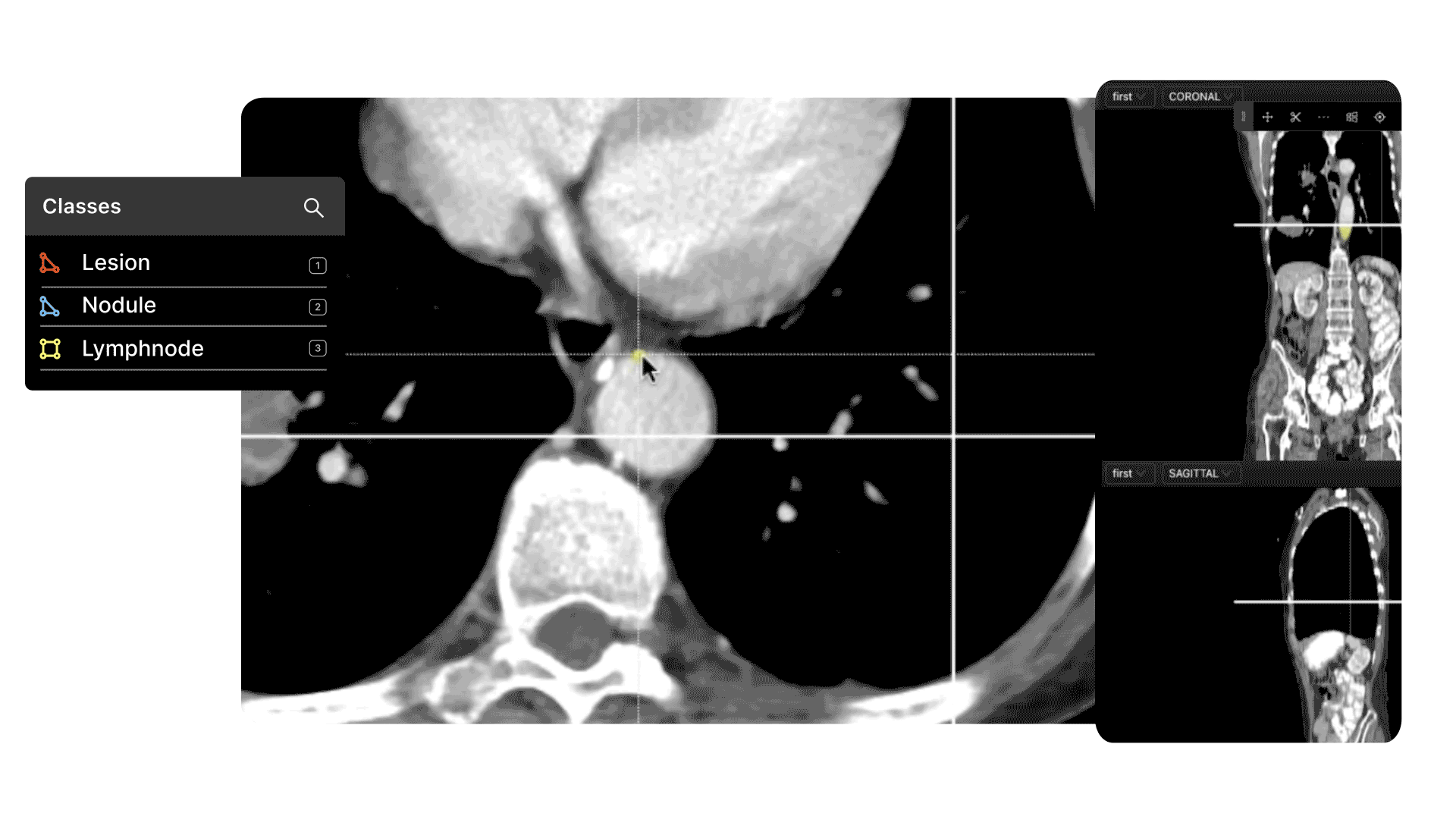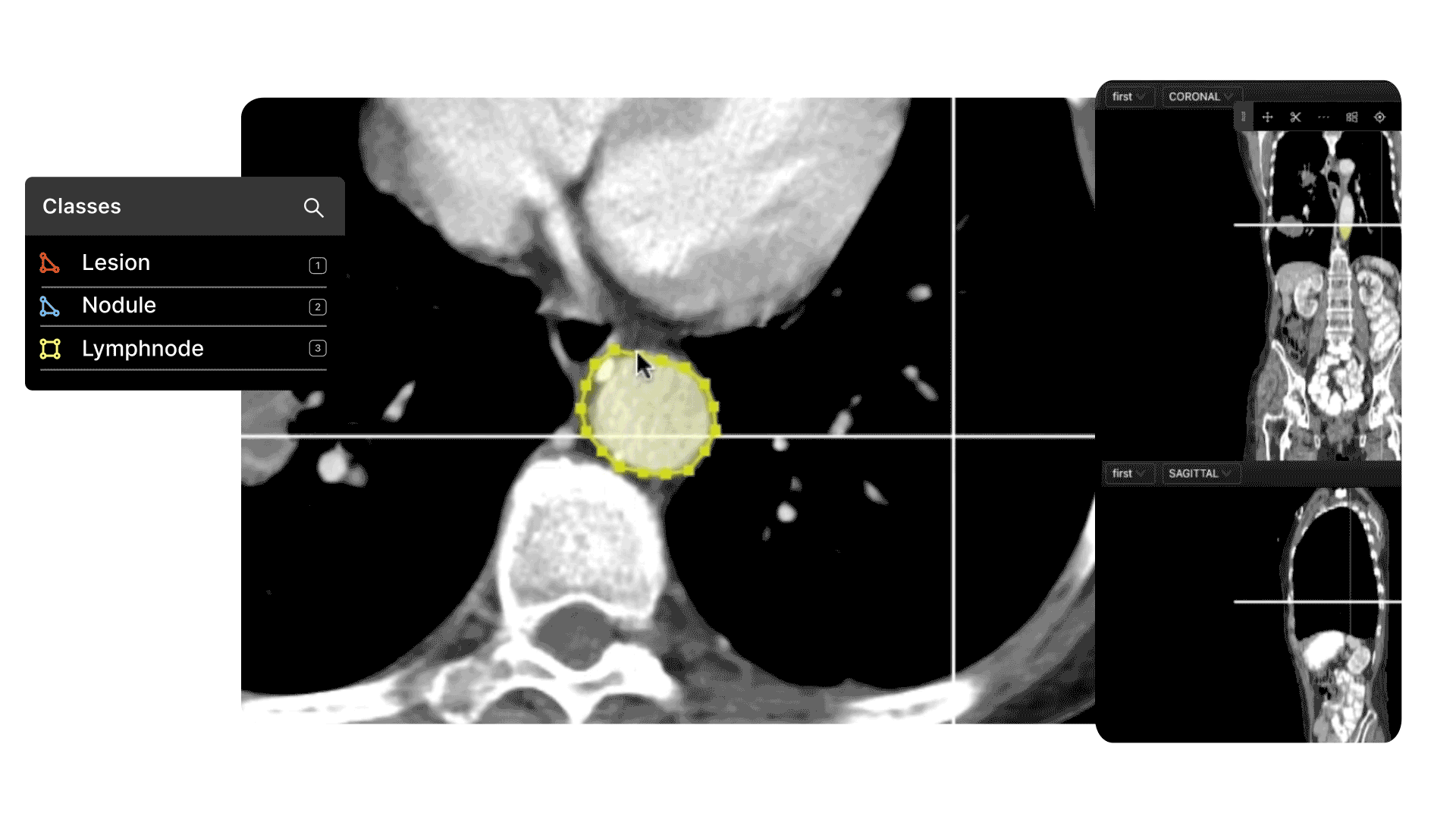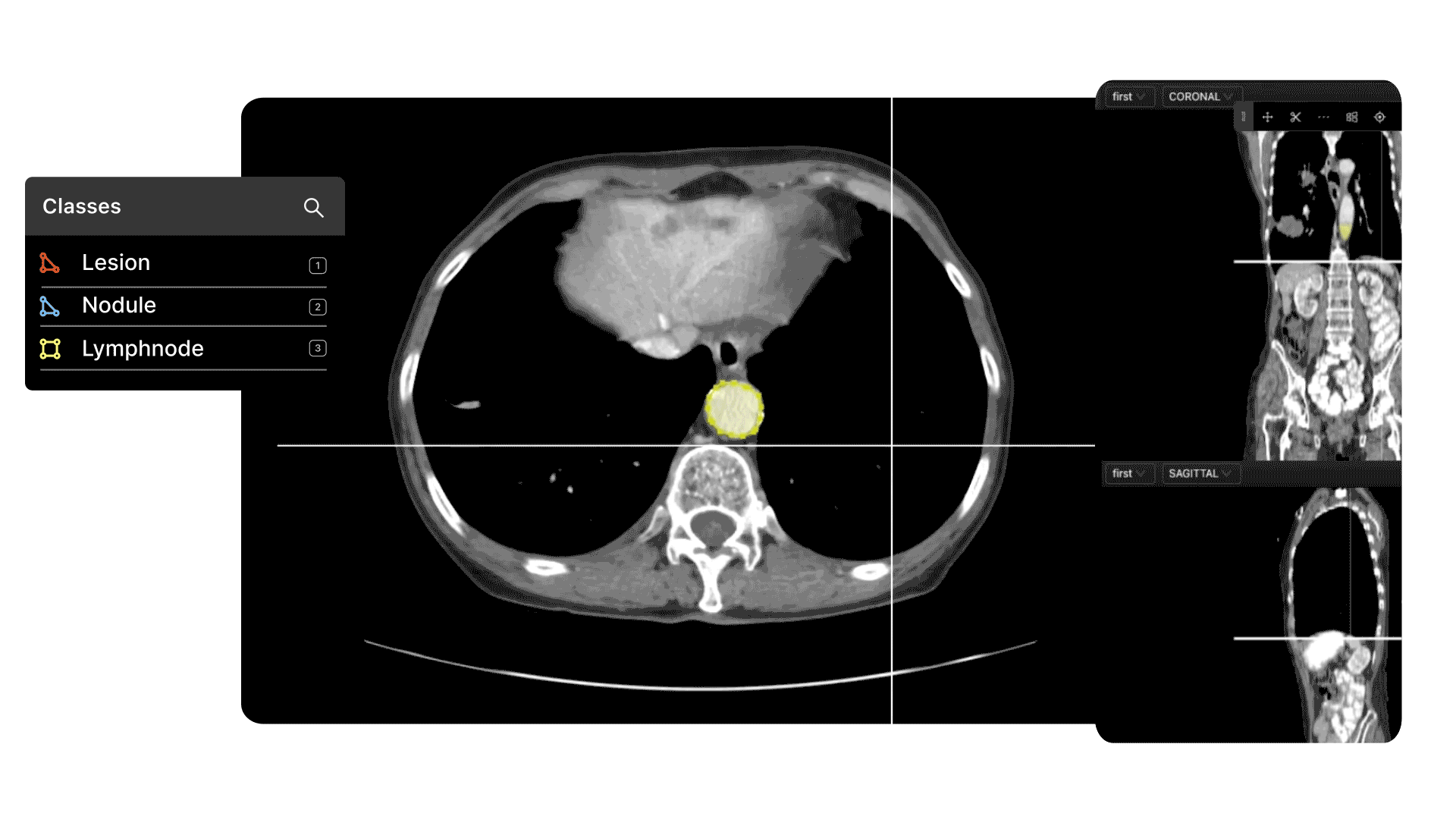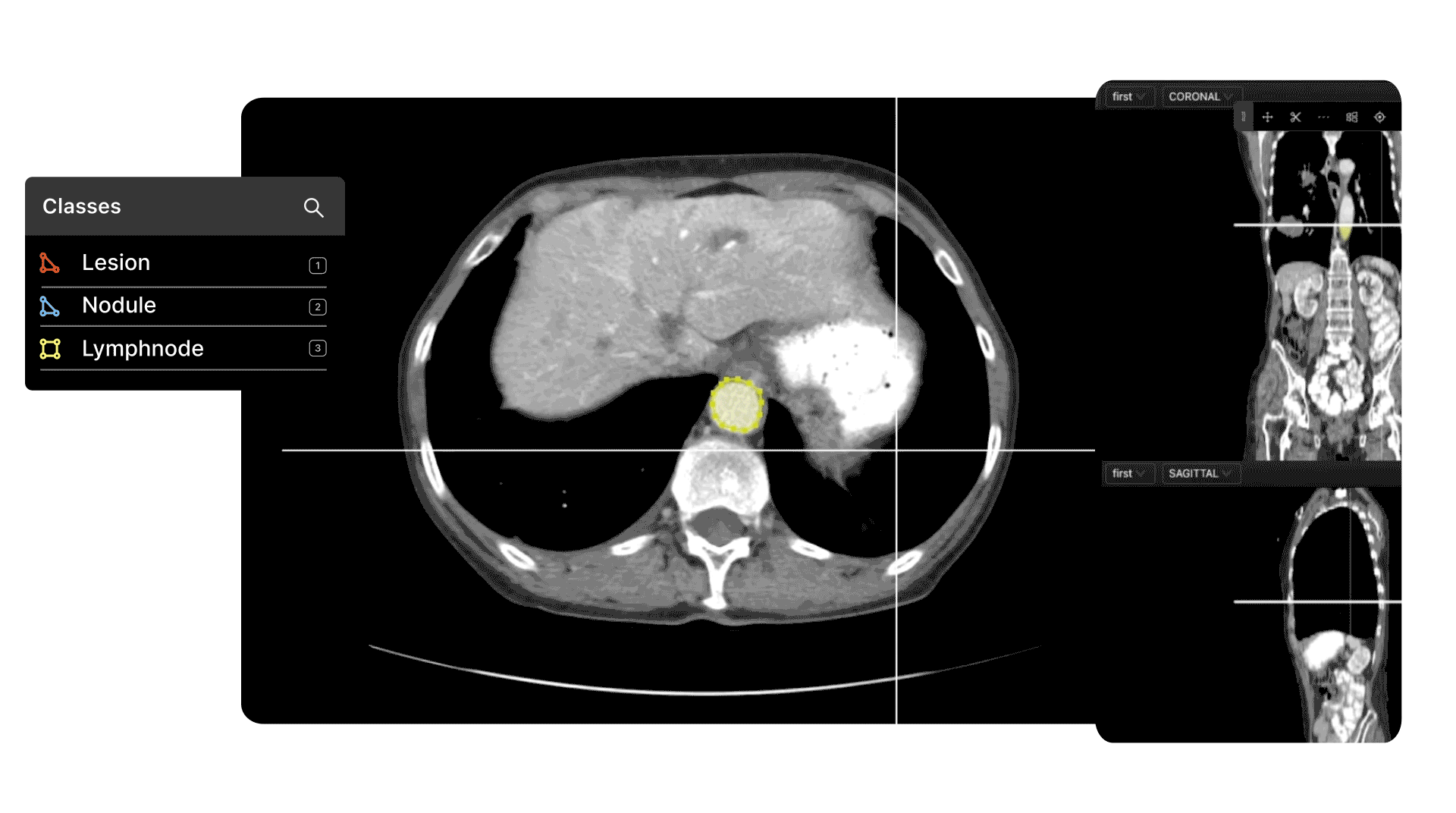
It's not a problem when there are millions of images to choose from, but what about outliers, especially for medical computer vision models?
In the same way that synthetic data is useful for augmenting datasets that suffer from systemic data bias. For instance, historically, much of medical research has been based on studies of white men, resulting in racial and gender bias in medicine and medical artificial intelligence.
Additionally, an overreliance on major research institutions for datasets has perpetuated racial bias. It’s also known that an overreliance on existing open-source datasets that compound societal inequities has resulted in facial recognition software performing more accurately on white faces.
To avoid perpetuating these biases, machine learning engineers must train models on data containing underrepresented groups. Augmenting existing datasets with synthetic data that represent these groups can accelerate the correction of these biases.

Saves time and money with synthetic data augmentation
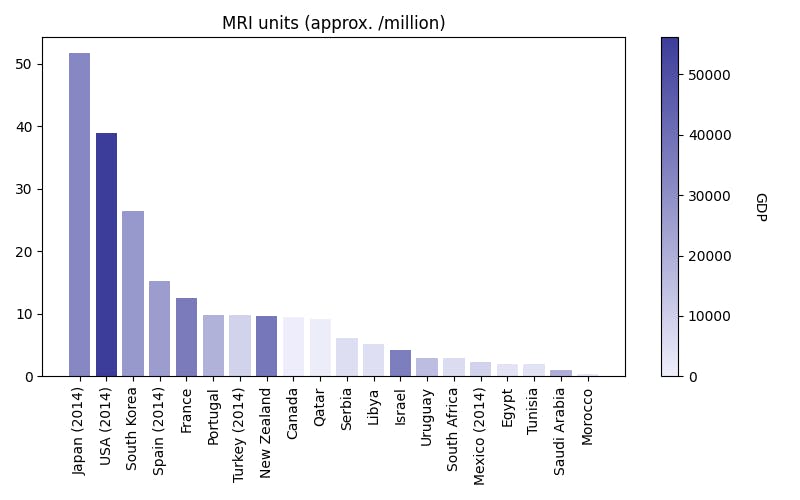
For research areas where data is hard to come by, using synthetic data to augment training datasets can be an effective solution that saves a computer vision project valuable time and money. Researchers and clinicians working with MRI face many challenges when collecting diverse datasets. For starters, MRI machines are costly, with a typical machine costing $1 million and cutting-edge models running up to $3 million.
In addition to the hardware, MRI machines require sterile rooms that eliminate outside interference and offer protection to those outside the room. Because of these installation costs, a hospital usually spends between $3 to $5 million on a suite with one machine. As of 2016, only about 36,000 machines existed globally, with 2,500 being produced annually. Operating these machines safely and effectively also requires specific technical expertise.

An example of a synthetic image generated by a GAN
Given these constraints, it’s no wonder these machines are in demand, and hospitals have long waiting lists full of patients needing them for diagnosis. At the same time, researchers and machine learning engineers might need additional MRI data on rare diseases before they can train a model to diagnose patients accurately. Supplementing these datasets with synthetic data means they don't have to book as much expensive MRI time or wait for the machines to become available, ultimately lowering the cost and timeline for putting a model into production.
Synthetic data generation can also save costs and time in other ways. For rare or regionally specific diseases, synthetic data can eliminate the challenges associated with locating enough patients worldwide and having to depend on their participation in the time-consuming process of getting an MRI.
The ability to augment datasets can help level the playing field in accelerating the development of medical computer vision and artificial intelligence (AI) models for treating patients in developing nations with limited medical access and resources. All of this creates additional challenges for training, finding a large enough volume of data to train a model on. For context, in 2022, the entire West Africa region had only 84 MRI machines to serve a population of more than 350 million.
Navigates data privacy regulatory requirements and increases scientific collaboration.
In an ideal world, researchers would collaborate to build larger, shared datasets, but for the fields in which data scarcity is most prevalent, privacy regulations and data protection laws (such as GDPR) often make collaboration difficult. Open-source datasets make this easier, but for rare edge and use cases, there aren’t enough images or videos in these datasets to train computational models.
Because synthetic data isn’t real, it doesn’t include any real patient information, so it doesn’t contain sensitive data, which opens up the possibility for the sharing of datasets among researchers to enhance and accelerate scientific discovery. For example, in 2022, King's College London (KCL) released 100,000 artificially generated brain images to researchers to help accelerate dementia research. Collaboration on this level in medical science is only possible through synthetic data.
Unfortunately, at the moment, using synthetic data comes with a tradeoff between achieving differential privacy– the standard for ensuring that individuals within a dataset cannot be identified from personally identifiable information– and the accuracy of the synthetic data generated. However, in the future, sharing artificial images publicly without breaching privacy may become increasingly possible.
{{training_data_CTA}}
Disadvantages of synthetic data for computer vision models
At the same time, there are also some disadvantages to using synthetic data for computer vision models.
Remains cost-prohibitive for smaller organizations and startups
While synthetic data enables researchers to avoid the expense of building datasets solely from real-world data, generating synthetic data comes with its own costs. The computing time and financial cost of training a Generative Adversarial Network (GAN) - or any other deep learning-based generative model - to generate realistic artificial data varies with the complexity of the data in question. Training a GAN to produce realistic medical imaging data could take weeks of training, even on expensive specialist hardware and under the supervision of a team of data science engineers.
Even for those organizations that have access to the required hardware and know-how, synthetic data may not always be the solution for their dataset difficulties. GANs are relatively recent, so predicting whether a GAN will produce useful synthetic data is difficult to do except through trial and error. To pursue a trial-and-error strategy, organizations need to have time and money to spare, and operational leaders need to expect a higher-than-average failure rate.
As a result, generating synthetic data is somewhat limited to institutions and companies that have access to capital, large amounts of computing power, and highly skilled machine-learning engineers. In the short term, synthetic data could inhibit the democratization of AI by separating those who have the resources to generate artificial data from those who don’t.

Since this article was first published, AI-generated images have progressed, thanks to Visual Foundation Models. This is an example of an award-winning AI-generated image.
Overtraining risk
Even when a GAN is working properly, ML engineers need to remain vigilant that it isn’t “over-trained.” As strange as it sounds, synthetic data can help researchers navigate privacy concerns and place them at risk of committing unexpected privacy violations if a GAN overtrains.
If training continues for too long, the generative model will eventually start reproducing data from its original data pool. Not only is this result counterproductive, but it also has the potential to undermine the privacy of people whose data was during its training by recreating their information in what is supposed to be an artificial dataset.
Is this a real image of Drake?

No, it’s not. It’s a synthetic image from this paper where a deep-learning model increases the size of Drake’s nose. So does this image preserve Drake’s privacy or not? It’s technically not Drake, but it is still clearly Drake, right?
With new generative AI tools emerging, we are going to see an explosion of artificially generated images and videos, and this will impact the use of synthetic data in computer vision models.
Verifying the truth of the data produced
Because artificial data is often used in areas where real-world data is scarce, there’s a chance that the data generated might not accurately reflect real-world populations or scenarios. Researchers must create more data ⏤ because there wasn’t enough data to train a model to begin with ⏤ , but then they must find a way to trust that the data they’re creating is reflective of what’s happening in the real world.
Data and ML engineers must perform an important layer of quality control after the data is produced to test whether the new artificial data accurately reflect the sample of real-world data that it aims to mimic.
A note of optimism for creating and using synthetic data in computer vision models
While synthetic training brings its own difficulties and disadvantages, its development is promising, and it has the potential to revolutionize fields where the scarcity of real-world datasets has slowed the application of machine learning models. As with any new technology, generating synthetic data will have its growing pains, but its promise for accelerating technology and positively impacting the lives of many people far outweighs its current disadvantages.
Encord has developed our medical imaging dataset annotation software in synthetic training data science teams, giving you a powerful automated image annotation suite, fully auditable data, and powerful labeling protocols.
Ready to automate and improve the quality of your data labeling?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Join our Discord channel to chat and connect.
Frequently asked questions
Encord provides robust data preparation capabilities that streamline the process of converting raw data, such as ROS bags, into formats suitable for training and evaluating machine learning models. This includes features for annotation, scene description, and quality grading of data captures, ensuring that the datasets are ready for effective model training.
Using Encord for machine learning annotation can provide cost efficiency by reducing the need for full-time employees while offering dedicated annotators familiar with your tasks. This model allows for scalable and flexible annotation capabilities, which can lead to improved speed and quality in your projects.
Organizations using Encord should focus on the representativeness of their training datasets and the implications of data security. By leveraging Encord's capabilities, users can ensure their AI models are trained effectively while adhering to best practices in data management and ethical considerations.
Using synthetic data alongside real-world data can enhance model performance by filling in gaps in training datasets, especially for rare or edge cases. Encord's platform helps streamline this process, allowing teams to balance the strengths of both data types for better training outcomes.
Encord provides a robust solution for data curation, allowing organizations to efficiently clean and organize unstructured data. This includes removing unwanted data and creating curated collections tailored to specific annotation tasks, ultimately enhancing the annotator's efficiency.
Encord helps teams evaluate their machine learning models by providing a platform to track and analyze the performance of models in production. This includes assessing the accuracy of labels and facilitating the iterative improvement of models based on real-world data.
Once data is processed in Encord, users can generate training datasets that can be used to train models externally. After training, predictions can be brought back into Encord for comparison against ground truth, allowing for model evaluation and refinement.
Yes, Encord facilitates the evaluation of model predictions by comparing them against ground truth annotations. This process helps identify data or model-related issues, ensuring that users can refine their models based on accurate performance metrics.
Yes, Encord has capabilities that allow teams to create and utilize synthetic data for training machine learning models. This feature can help accelerate the data wrangling process and improve model performance by diversifying the training datasets.
While Encord does not generate synthetic data, it collaborates with partners who utilize its indexing tools to identify areas where data augmentation is needed. This enhances the overall effectiveness of using synthetic data in AI model training.