Inter-rater Reliability: Definition, Examples, Calculation

Inter-rater reliability measures the agreement between two or more raters or observers when assessing subjects. This metric ensures that the data collected is consistent and reliable, regardless of who is collects or analyzes it. The significance of inter-rater reliability cannot be overstated, especially when the consistency between observers, raters, or coders is paramount to the validity of the study or assessment.
Inter-rater reliability refers to the extent to which different raters or observers give consistent estimates of the same phenomenon. It is a measure of consistency or agreement between two or more raters. On the other hand, intra-rater reliability measures the consistency of ratings given by a single rater over different instances or over time.
In research, inter-rater reliability is pivotal in ensuring the validity and reliability of study results. In qualitative research, where subjective judgments are often required, having a high degree of inter-rater reliability ensures that the findings are not merely the result of one individual's perspective or bias. Instead, it confirms that multiple experts view the data or results similarly, adding credibility to the findings.1
Moreover, in studies where multiple observers are involved, inter-rater reliability helps standardize the observations, ensuring that the study's outcomes are not skewed due to the variability in observations.
Methods to Measure Inter-rater Reliability
Inter-rater reliability, often called IRR, is a crucial statistical measure in research, especially when multiple raters or observers are involved. It assesses the degree of agreement among raters, ensuring consistency and reliability in the data collected. Various statistical methods have been developed to measure it, each with unique advantages and applications.1
Cohen's Kappa
Cohen's Kappa is a widely recognized statistical method used to measure the agreement between two raters. It considers the possibility of the agreement occurring by chance, providing a more accurate measure than a simple percentage agreement. The Kappa statistic ranges from -1 to 1, where 1 indicates perfect agreement, 0 suggests no better agreement than chance, and -1 indicates complete disagreement.2
The formula for calculating Cohen's Kappa is:
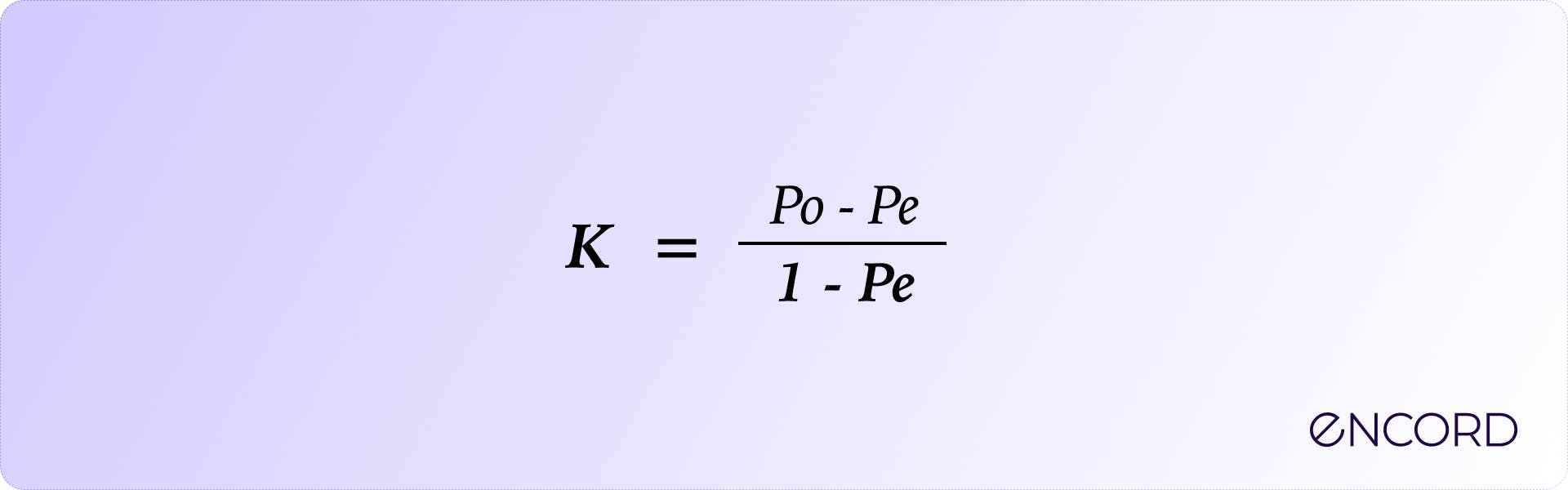
Where:
- \( p_o \) is the observed proportion of agreement
- \( p_e \) is the expected proportion of agreement
Using Cohen's Kappa is essential when the data is categorical, and raters may agree by chance. It provides a more nuanced understanding of the reliability of raters.
Intraclass Correlation Coefficient (ICC)
The Intraclass Correlation Coefficient, commonly known as ICC, is another method used to measure the reliability of measurements made by different raters. It's beneficial when the measurements are continuous rather than categorical. ICC values range between 0 and 1, with values closer to 1 indicating higher reliability.
One of the main differences between ICC and Cohen's Kappa is their application. While Cohen's Kappa is best suited for categorical data, ICC is ideal for continuous data. Additionally, ICC can be used for more than two raters, making it versatile in various research settings.
Percentage Agreement
Percentage agreement is the simplest method to measure inter-rater reliability. It calculates the proportion of times the raters agree without considering the possibility of chance agreement. While it's straightforward to compute, it doesn't provide as nuanced a picture as methods like Cohen's Kappa or ICC.
For instance, if two raters agree 85% of the time, the percentage agreement is 85%. However, this method doesn't account for agreements that might have occurred by chance, making it less robust than other methods.
Despite its simplicity, it is essential to be cautious when using percentage agreement, especially when the stakes are high, as it might provide an inflated sense of reliability.
Factors Affecting Inter-rater Reliability
Inter-rater reliability (IRR) is a crucial metric in research methodologies, especially when data collection involves multiple raters. It quantifies the degree of agreement among raters, ensuring that the data set remains consistent across different individuals. However, achieving a high IRR, such as a perfect agreement, is difficult. Several factors can influence the consistency between raters, and comprehending these can aid in enhancing the reliability measures of the data.
Rater Training
One of the most important factors affecting IRR is the training of raters. Proper training can significantly reduce variability and increase the coefficient of inter-rater agreement. For instance, in Krippendorff's study (2011) study, raters trained using a specific methodology exhibited a Cohen’s Kappa value of 0.85, indicating a high level of agreement, compared to untrained raters with a kappa value of just 0.5.4
Training ensures that all raters understand the rating scale and the criteria they are evaluating against. For example, in clinical diagnoses, raters can be trained using mock sessions where they are presented with sample patient data. Feedback sessions after these mock ratings can pinpoint areas of disagreement, offering a chance to elucidate and refine the methodology.
Clarity of Definitions
The clarity of definitions in the rating process is pivotal. Providing raters with unambiguous definitions, such as elucidating the difference between intra-rater and inter-rater reliability or explaining terms like "percent agreement" versus "chance agreement," ensures consistency. For example, in a research method involving the assessment of academic papers, if "originality" isn't clearly defined, raters might have divergent interpretations. A clear definition of terms in a study involving Krippendorff’s alpha as a reliability measure increased the alpha value from 0.6 to 0.9, indicating a higher degree of agreement.5 Defining the time frame between tests can lead to more consistent results in test-retest reliability assessments.
Subjectivity in Ratings
Subjectivity, especially in ordinal data, can significantly impede achieving a high IRR. For instance, in a data collection process involving movie reviews, two raters might have different thresholds for what constitutes a "good" film, leading to varied ratings. A Pearson correlation study found that when raters were given a clear guideline, the coefficient increased by 20%.6
To curtail subjectivity, it's imperative to have explicit guidelines. Tools like Excel for data analysis can help visualize areas of high variability. Moreover, employing reliability estimates like Fleiss Kappa or Cronbach's alpha can provide a clearer picture of the degree of agreement. For instance, a Fleiss Kappa value closer to 1 indicates high inter-rater reliability.
While tools like the kappa statistic, intra-class correlation coefficient, and observed agreement offer quantifiable metrics, the foundation of high IRR lies in rigorous training, precise definitions, and minimizing subjectivity.
Practical Applications and Examples of Inter-rater Reliability
Inter-rater reliability (IRR) is used in various research methods to ensure that multiple raters or observers maintain consistency in their assessments. This measure often quantified using metrics such as Cohen’s Kappa or the intra-class correlation coefficient, is paramount when subjective judgments are involved. Let's explore the tangible applications of inter-rater reliability across diverse domains.
Clinical Settings
In clinical research, IRR is indispensable. Consider a scenario where a large-scale clinical trial is underway. Multiple clinicians collect data, assessing patient responses to a new drug. Here, the level of agreement among raters becomes critical. The trial's integrity is compromised if one clinician records a side effect while another overlooks it. In such settings, metrics like Fleiss Kappa or Pearson's correlation can quantify the degree of agreement among raters, ensuring that the data set remains consistent.7
Furthermore, in diagnoses, the stakes are even higher. A study revealed that when two radiologists interpreted the same X-rays without a standardized rating scale, their diagnoses had a variability of 15%. However, clear guidelines and training reduced the variability to just 3%, showcasing the power of high inter-rater reliability in clinical settings.
Social Sciences
Social sciences, with their inherent subjectivity, lean heavily on IRR. Multiple researchers conducted observational studies in a study exploring workplace dynamics in English corporate culture. Using tools like Excel for data analysis, the researchers found that the observed agreement among raters was a mere 60% without established guidelines. However, post-training and with clear definitions, the agreement soared to 90%, as measured by Krippendorff’s alpha.9
Education
Education, a sector shaping future generations, cannot afford inconsistencies. Consider grading, a process fraught with subjectivity. In a study involving multiple teachers grading the same set of papers, the initial score variability was 20%. However, after a rigorous training session and with a standardized rating scale, the variability plummeted to just 5%.10
Standardized tests are the gateways to numerous opportunities, especially relying on IRR. A disparity in grading can alter a student's future. For instance, a test-retest reliability study found that scores varied by as much as 15 points on a 100-point scale without ensuring inter-rater agreement. Such inconsistencies can differentiate between a student getting their dream opportunity or missing out.10
Inter-rater reliability, quantified using metrics like the kappa statistic, Cronbach's alpha, or the intra-rater reliability measure, is non-negotiable across domains. Whether it's clinical trials, anthropological studies, or educational assessments, ensuring consistency among raters is not just a statistical necessity; it's an ethical one.
Inter-rater Reliability: Key Takeaways
Inter-rater reliability (IRR) is a cornerstone in various research domains, ensuring that evaluations, whether from clinical diagnoses, academic assessments, or qualitative studies, are consistent across different raters. Its significance cannot be overstated, as it safeguards the integrity of research findings and ensures that subjective judgments don't skew results. IRR is a litmus test for data reliability, especially when multiple observers or raters are involved.
The call to action for researchers is clear: rigorous training and comprehensive guidelines for raters are non-negotiable. Ensuring that raters are well-equipped, both in terms of knowledge and tools, is paramount. It's not just about achieving consistent results; it's about upholding the sanctity of the research process and ensuring that findings are valid and reliable.
Future Directions
As we look ahead, the landscape of inter-rater reliability is poised for evolution. With technological advancements, there's potential for more sophisticated methods to measure and ensure IRR. Software solutions equipped with artificial intelligence and machine learning capabilities might soon offer tools that can assist in training raters, providing real-time feedback, and even predicting areas of potential disagreement.
Moreover, as research methodologies become more intricate, the role of technology in aiding the process of ensuring IRR will undoubtedly grow. The future holds promise, from virtual reality-based training modules for raters to advanced statistical tools that can analyze inter-rater discrepancies in real time. For researchers and professionals alike, staying abreast of these advancements will ensure their work remains at the forefront of reliability and validity.
In conclusion, while the principles of inter-rater reliability remain steadfast, the tools and methods to achieve it are ever-evolving, promising a future where consistency in evaluations is not just hoped for but assured.
Frequently asked questions
Inter-rater Reliability (IRR) is a metric used in research to measure the consistency or agreement between two or more raters or observers when assessing subjects. It ensures that the data collected remains consistent regardless of who is collecting or analyzing it.
While IRR measures the consistency between different raters or observers, Intra-rater Reliability measures the consistency of ratings given by a single rater over different instances or over time.
Some standard methods to measure IRR include Cohen's Kappa, Intraclass Correlation Coefficient (ICC), and Percentage Agreement. Each method has its unique advantages and applications.
IRR is pivotal in ensuring the validity and reliability of study results. Especially in qualitative research, a high degree of IRR ensures that findings are not influenced by one individual's perspective or bias, adding credibility to the results.
Improving IRR involves rigorous rater training, providing unambiguous definitions, and minimizing subjectivity in ratings. Proper training ensures raters understand the criteria they are evaluating against, leading to more consistent results.
Encord is committed to reliability and performance, with a dedicated engineering team focused on maintaining high standards. This includes optimizing loading speeds and processing times, ensuring that users can depend on the platform for their data annotation and analysis needs.
Encord maintains real-time connections with most customer solutions, allowing for seamless integration and ingestion of documents. This ensures that the data being processed is always the most up-to-date, facilitating effective information delivery to field workers.