Meta AI's CoTracker: It is Better to Track Together for Video Motion Prediction

In deep learning, establishing point correspondences in videos is a fundamental challenge with broad applications. Accurate video motion prediction is crucial for various downstream machine learning tasks, such as object tracking, action recognition, and scene understanding. To address the complexities associated with this task, Meta AI introduces "CoTracker," a cutting-edge architecture designed to revolutionize video motion estimation.

CoTracker: It is Better to Track Together
Video Motion Estimation
Video motion estimation involves predicting the movement of points across frames in a video sequence. Traditionally, two main approaches have been used: optical flow and tracking algorithm.
Optical flow estimates the velocity of points within a video frame, while the tracking method focuses on estimating the motion of individual points over an extended period. While both approaches have their strengths, they often overlook the strong correlations between points, particularly when points belong to the same physical object. These correlations are crucial for accurate motion prediction, especially when dealing with occlusions and complex scene dynamics.
Video motion estimation has many practical applications in artificial intelligence, enabling enhanced visual understanding and interaction. In surveillance, it aids in object detection and anomaly detection. In filmmaking and entertainment, it drives special effects and scene transitions. In robotics and automation, it enhances robotic movement and task execution. Autonomous vehicles utilize it for environment perception and navigation. Medical imaging can benefit from motion-compensated diagnostics. Virtual reality benefits from realistic movement portrayal. Video compression and streaming utilize motion estimation for efficient data transmission.
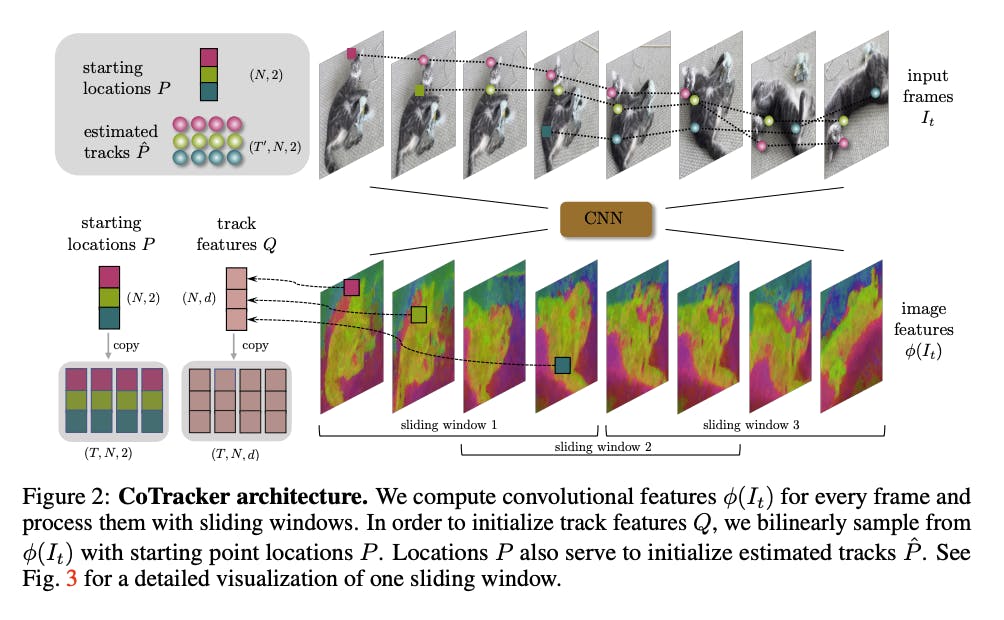
Co-Tracker: Architecture
Meta AI has introduced "CoTracker," an innovative architecture that enhances video motion prediction by jointly tracking multiple points throughout an entire video sequence. CoTracker is built on the foundation of the transformer network, a powerful and flexible neural architecture that has demonstrated success in various natural language processing and computer vision tasks.
The key innovation of CoTracker is its ability to leverage both time and group attention blocks within the transformer architecture. By interleaving these attention blocks, CoTracker achieves a more comprehensive understanding of motion dynamics and correlations between points. This design enables CoTracker to overcome the limitations of traditional methods that focus on tracking points independently, thus unlocking a new era of accuracy and performance in video motion prediction.
CoTracker: It is Better to Track Together
Transformer Formulation
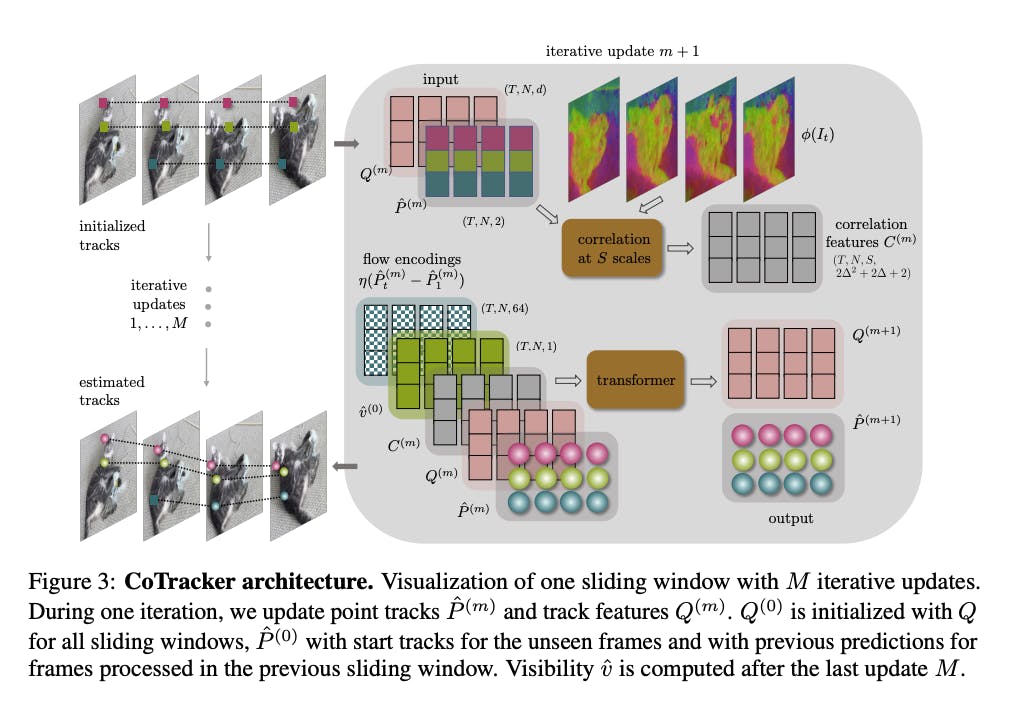
The Co-Tracker architecture utilizes a transformer network with a CNN-based foundation, a versatile and powerful neural network architecture. This network denoted as Ψ : G → O, is tailored to enhance the accuracy of track estimates. Tracks are represented as input tokens Gi, encoding essential information like image features, visibility, appearance, correlation vectors, and positional encodings. The transformer processes these tokens iteratively to refine track predictions, ensuring context assimilation. The optimization of visibility is achieved through learned weights and strategically initialized quantities
Windowed Inference
Co-Tracker has the ability to support windowed applications, allowing it to efficiently handle long videos. In scenarios where the video length T' exceeds the maximum window size supported by the architecture, the video is split into windows with an overlap. The transformer is then applied iteratively across these windows, allowing the model to process extended video sequences while preserving accuracy.
Unrolled Learning
Unrolled learning is a vital component of Co-Tracker's training process. This mechanism enables the model to handle semi-overlapping windows, which is essential for maintaining accuracy across longer videos. During training, the model is trained using an unrolled fashion, effectively preparing it to handle videos of varying lengths during evaluation.
Transformer Operation and Components
Co-Tracker's transformer operates using interleaved time and group attention blocks. This unique approach allows the model to consider temporal and correlated group-based information simultaneously. Time attention captures the evolution of individual tracks over time, while group attention captures correlations between different tracks. This enhances the model's ability to reason about complex motion patterns and occlusions.
Point Selection
A crucial aspect of Co-Tracker's success lies in its approach to point selection. To ensure a fair comparison with existing methods and to maintain robustness in performance, the model is evaluated using two-point selection strategies: global and local. In the global strategy, points are selected on a regular grid across the entire image. In the local strategy, points are chosen in proximity to the target point. Point selection enhances the model's ability to focus on relevant points and regions, contributing to its accuracy in motion prediction.
CoTracker: It is Better to Track Together
Co-Tracker: Implementation
Co-Tracker's implementation involves rendering 11,000 pre-generated 24-frame sequences from TAP-Vid-Kubric, each annotated with 2,000 tracked points. These points are preferentially sampled on objects.
During training, 256 points are randomly selected per sequence, visible either in the first or middle frames. Co-Tracker is trained as a baseline on TAP-Vid-Kubric sequences of size 24 frames using sliding windows of size 8 frames, iterated 50,000 times on 32 NVIDIA TESLA Volta V100 32GB GPUs. This scalable approach ensures efficient learning and flexibility to adapt the batch size according to available GPU memory, resulting in high-quality tracking performance and achieving a stable frame rate (fps).
Ground truth annotations enhance the training process, contributing to the model's robustness and accuracy in capturing complex motion patterns.
Co-Tracker: Experiments and Benchmarks
The Co-Tracker efficacy in video motion prediction and point tracking was evaluated on a series of experiments and benchmark assessments. The performance of the architecture was rigorously tested using a combination of synthetic and real-world datasets, each carefully chosen to represent a spectrum of challenges. The synthetic dataset, TAP-Vid-Kubric, played a pivotal role in training the architecture and simulating dynamic scenarios with object interactions. Benchmark datasets like TAP-Vid-DAVIS, TAP-Vid-Kinetics, BADJA, and FastCapture provided real-world videos with annotated trajectories to facilitate the assessment of Co-Tracker's predictive prowess.
These evaluations adhered to predefined protocols tailored to the intricacies of each dataset. The "queried strided" protocol was adopted, requiring precise tracking in both forward and backward directions to address varying motion complexities. Evaluation metrics such as Occlusion Accuracy (OA), Average Jaccard (AJ), and Average Positional Accuracy (< δx avg) were used to gauge the architecture's performance.
Co-Tracker: Results

CoTracker: It is Better to Track Together
The paper explores the impact of joint tracking and support grids, an essential element of Co-Tracker's design. By evaluating different support grids and employing the "uncorrelated single target point" protocol, it demonstrated that the architecture's ability to collectively reason about tracks and their trajectories (group attention and time attention) led to improved outcomes. The best results were achieved when the correct contextual points were considered, highlighting the effectiveness of combining local and global grids. The potential for even better performance was seen when using the "all target points" protocol, indicating that correlated points are indeed influential. Although this protocol was not directly compared to prior work for fairness, it aligns with real-world scenarios where segmentation models could automatically select correlated points.
When compared to prior state-of-the-art AI models like RAFT and PIPs, Co-Tracker exhibited remarkable accuracy in tracking points and their visibility across various benchmark datasets. The architecture's capacity for long-term tracking of points in groups was especially beneficial. This approach was different from traditional single-point models and short-term optical flow methods that often grapple with accumulated drift issues. The meticulous evaluation protocol further solidified Co-Tracker's superior predictive capabilities.

CoTracker: It is Better to Track Together
During the exploration of the importance of training data, TAP-Vid-Kubric emerged as the superior choice vs. FlyingThings++. The latter's short sequences clashed with Co-Tracker's reliance on sliding windows for training. On the other hand, Kubric's realistic scenes and occluded objects aligned seamlessly with the architecture's design. The significance of unrolled learning in the sliding window scheme was demonstrated through evaluations. Given that evaluation sequences often exceeded training video lengths, Co-Tracker's ability to propagate information between windows emerged as a crucial factor in its exceptional performance.
Co-Tracker: Key Takeaways

CoTracker: It is Better to Track Together
- Group Tracking Boosts Accuracy: Co-Tracker's simultaneous tracking of multiple points improves accuracy by considering correlations between them, surpassing single-point models.
- Contextual Points Matter: Co-Tracker's success depends on choosing contextual points effectively within support grids, highlighting the importance of context in accurate tracking.
- Long-Term Group Tracking Prevails: Co-Tracker's long-term group tracking surpasses single-point models and short-term optical flow methods, ensuring better predictive accuracy and mitigating drift issues.
- Training Data's Influence: TAP-Vid-Kubric's training data is superior, aligning well with Co-Tracker's approach and offering more realistic scenes than FlyingThings++.
- Efficient Unrolled Learning: Co-Tracker's unrolled learning for sliding windows efficiently propagates information, proving vital for maintaining accuracy on longer sequences.
- Co-Tracker's success hinges on correlation utilization, context consideration, and real-world adaptability, solidifying its role as a transformative solution for video motion prediction and point tracking.