Improving Training Data with Outlier Detection

In machine learning, training data plays a vital role in the accuracy and effectiveness of models. However, not all data is created equal, and the presence of outliers can significantly impact the performance of these models.
In this blog post, we will explore the concept of outlier detection and how it can be leveraged to improve training data with Encord Active.
What is Outlier Detection?
Outlier detection refers to identifying data points that deviate significantly from the normal distribution of a dataset. Outliers can arise due to various factors such as measurement errors, data corruption, or anomalies in the data. Detecting and handling outliers is crucial as they can distort statistical analysis and affect the performance of your ML models.

In data analysis and machine learning, you can encounter two types of outliers:
- Data outliers
- Label outliers
Data Outliers
Data outliers refer to observations or instances in a dataset that significantly deviate from the expected or typical values. These outliers arise due to measurement errors, data corruption, or anomalies.
Data outliers can distort statistical analysis, affect the performance of machine learning models, and lead to inaccurate predictions. Detecting and addressing data outliers is crucial to ensure a high-quality dataset.
Label Outliers
Label outliers pertain to mislabeled or incorrectly assigned labels in a dataset. These outliers can occur due to human error during the labeling process or ambiguous instances that are challenging to classify accurately.
Label outliers can substantially impact the performance of supervised learning algorithms by introducing noise and misguiding the training process. Identifying and rectifying label outliers is essential for training models with accurate ground truth and improving their predictive capabilities.
Both data outliers and label outliers require careful analysis and handling to ensure the quality and reliability of data for your machine learning tasks. You must employ robust outlier detection techniques and quality assurance procedures to identify and address these outliers for more accurate and dependable models.
Outlier Detection in Encord Active
Encord Active offers a robust solution to identify and label outliers for pre-defined metrics, custom metrics, and label classes using precomputed interquartile ranges
With this feature, you can easily spot data points that deviate significantly from the norm, enabling you to take appropriate actions and ensure data quality. By leveraging Interquartile ranges, Encord Active streamlines your outlier detection workflow, helping to debug your data.
Setup
To install Encord Active, follow these simple commands in your favorite Python environment:
python3.9 -m venv ea-venv source ea-venv/bin/activate pip install encord-active
 💡 Check out the documentation for installation for more information.
💡 Check out the documentation for installation for more information. Let's explore the steps in improving training data with outlier detection in Encord Active. Here we will be using the BDD dataset.
Data Outliers
Finding the Data Outliers
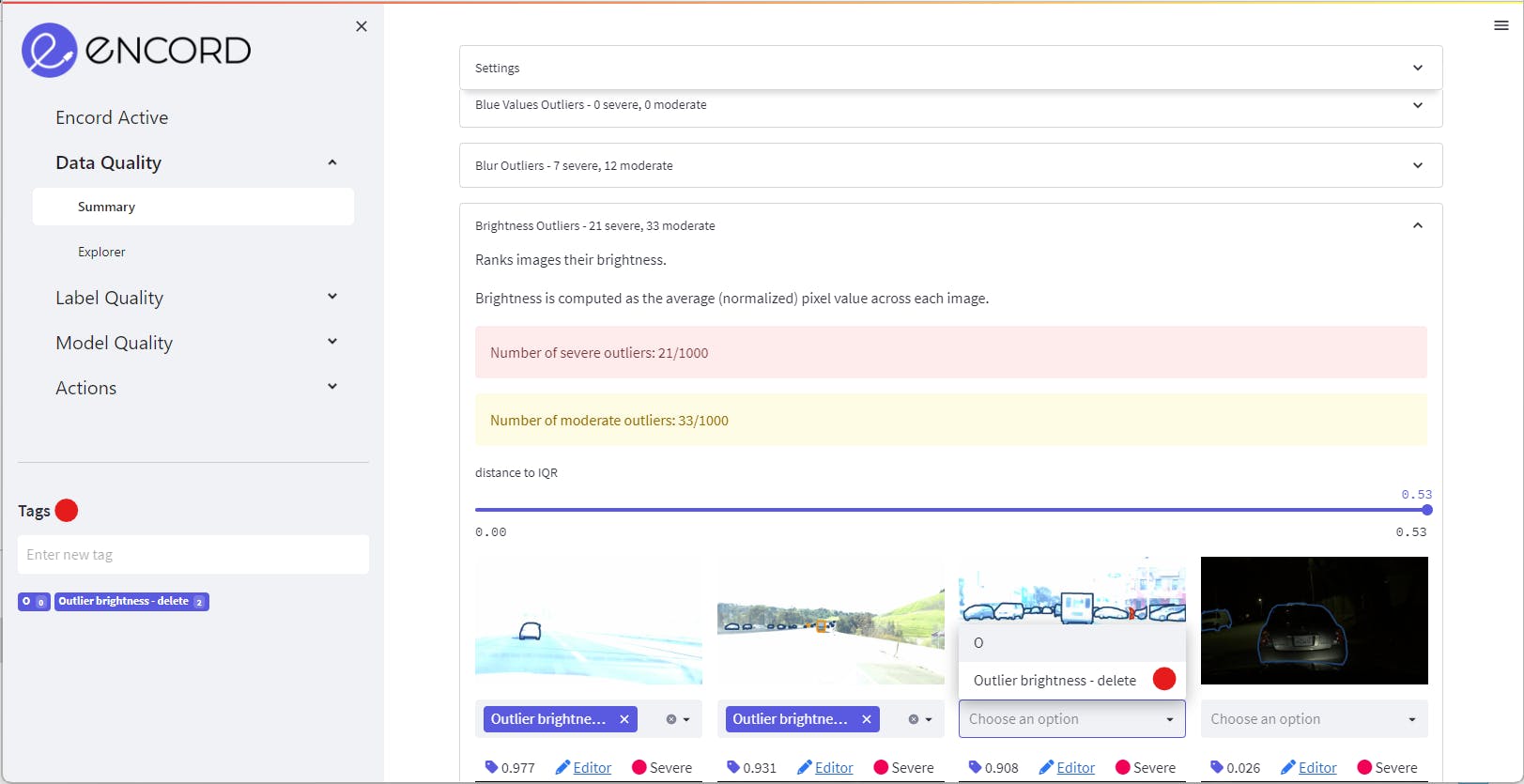
Encord Active provides an intuitive interface to locate outliers in your dataset. Navigate to the Data Quality > Summary tab and access the Quality Metrics, which are presented as expandable panes.
Click on a specific metric to reveal moderate to severe outliers, with the most severe ones displayed first, and use the slider to navigate through

Tagging the Data Outliers
Once you identify outliers of interest, Encord Active allows you to tag them individually or in bulk, to easily manage and work with them for further analysis.
Acting on the Data Outliers
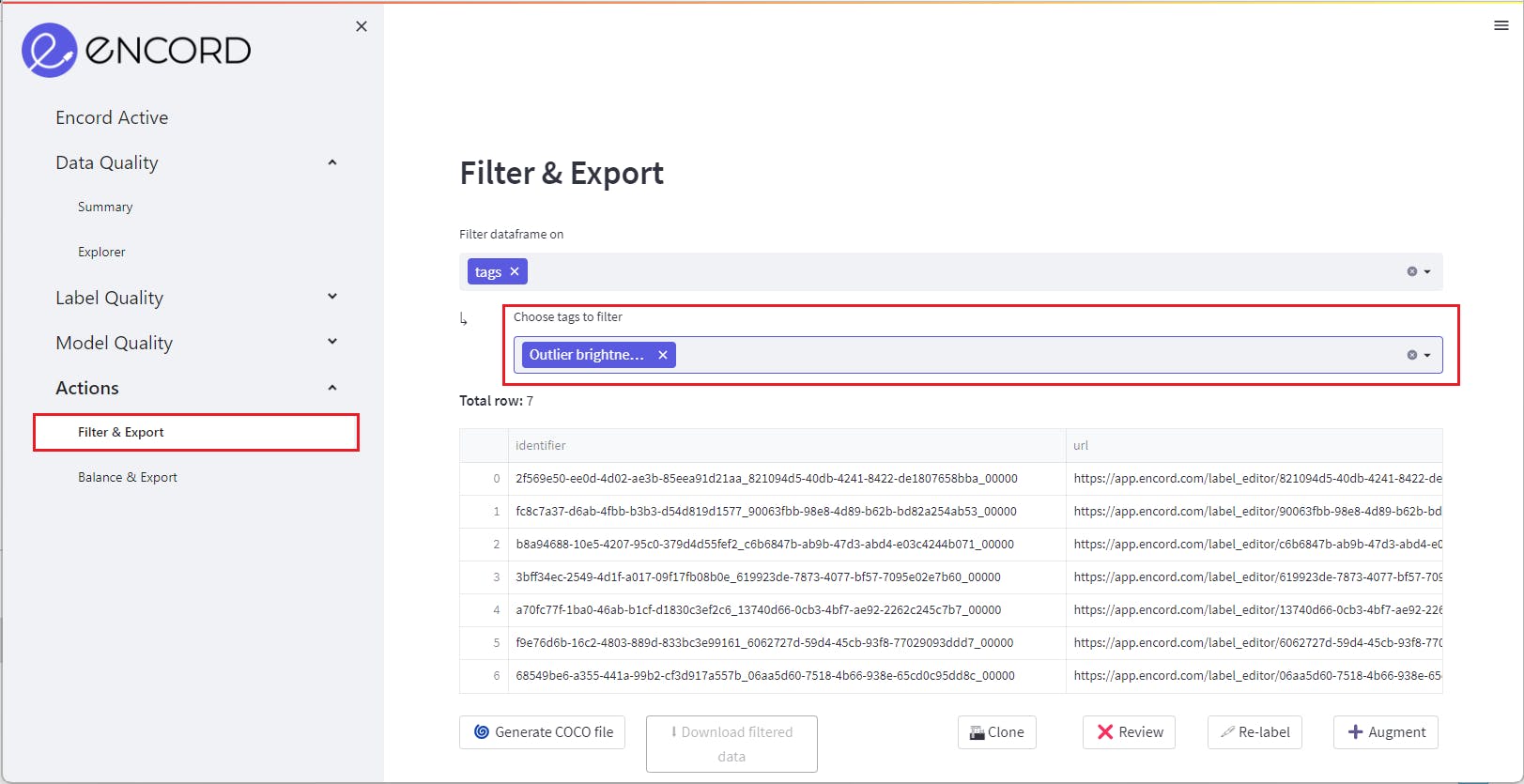
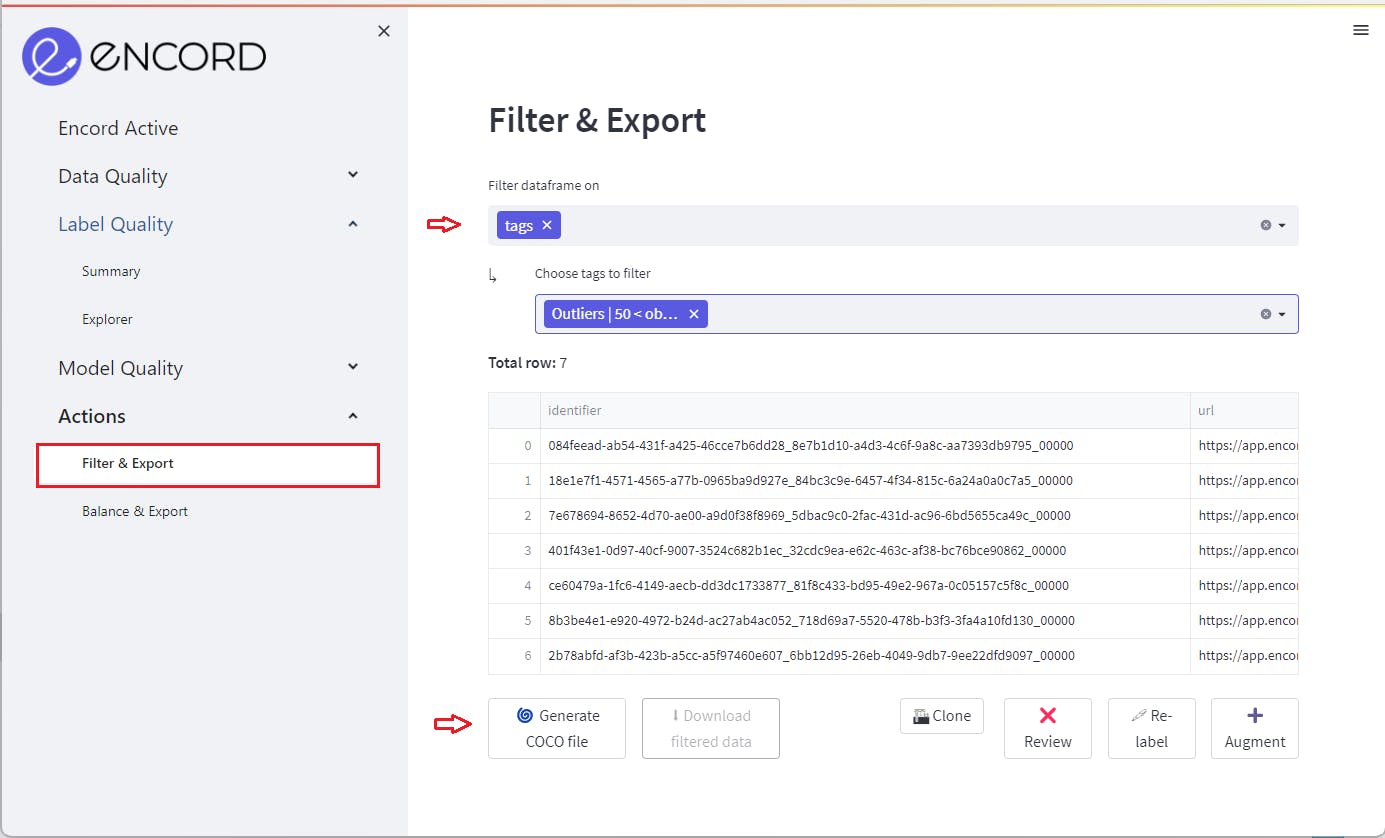
After creating the tagged image group, access it conveniently in the Actions tab at the bottom of the left sidebar, with a range of actions at your disposal.
Select "Filter data frame on" and choose the "tags" option to focus on the tagged outliers. You can then export the outliers, relabel them, augment the data, review them in detail, or even delete them from your dataset.
Label Outliers
Find Label Outliers
To begin, navigate to the Label Quality > Summary tab in Encord Active. Here, you will find each Quality Metric presented as expandable panes, providing an overview of label quality.
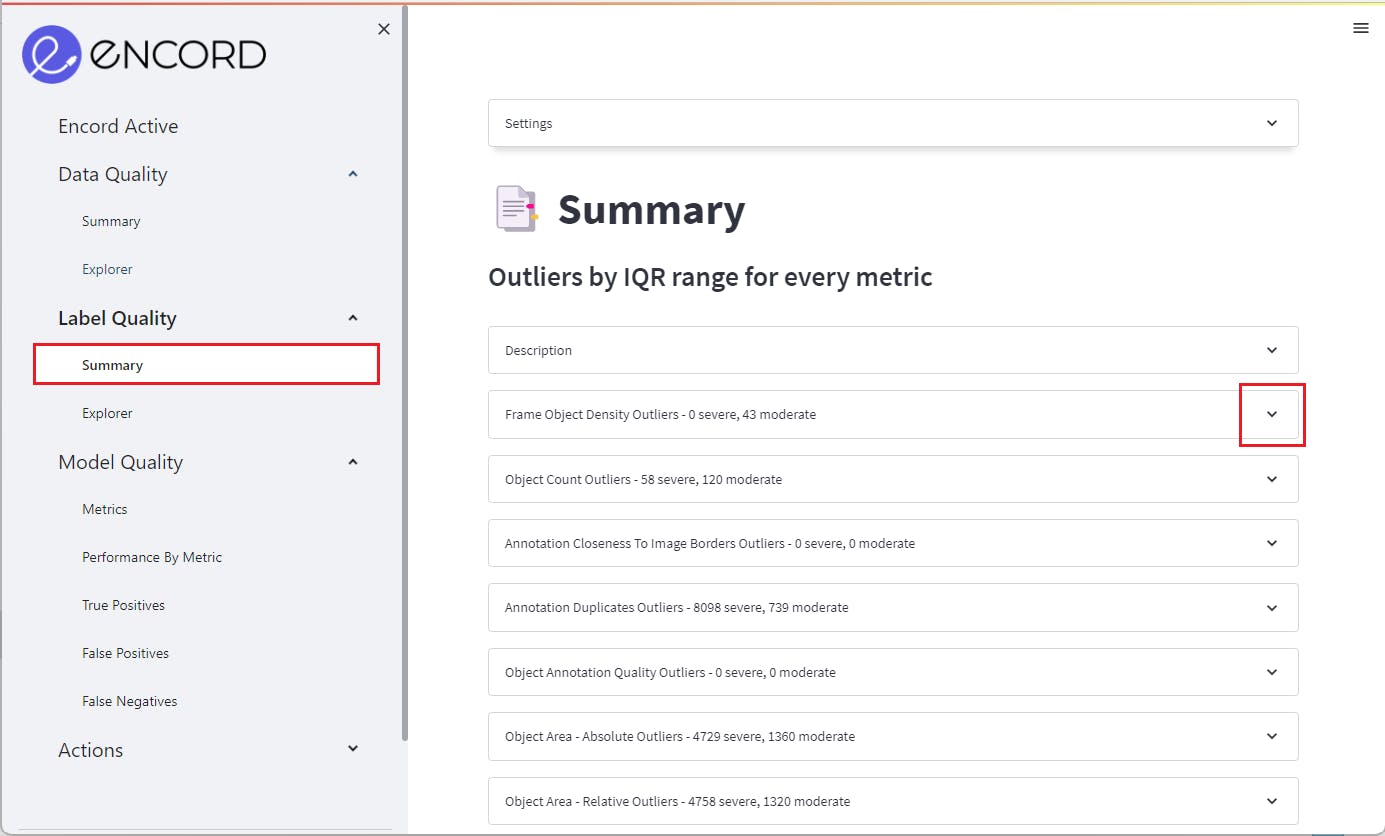
Click on a specific metric to gain deeper insights into moderate and severe label outliers. Like data outliers, the pane will prioritize presenting the severe outliers first, allowing you to focus on the most critical issues.
Tag Label Outliers
Once you have identified label outliers of interest, you can utilize individual and bulk tagging features to select and group the corresponding images. You can conveniently organize and manipulate these outliers for subsequent analysis and actions by tagging them.
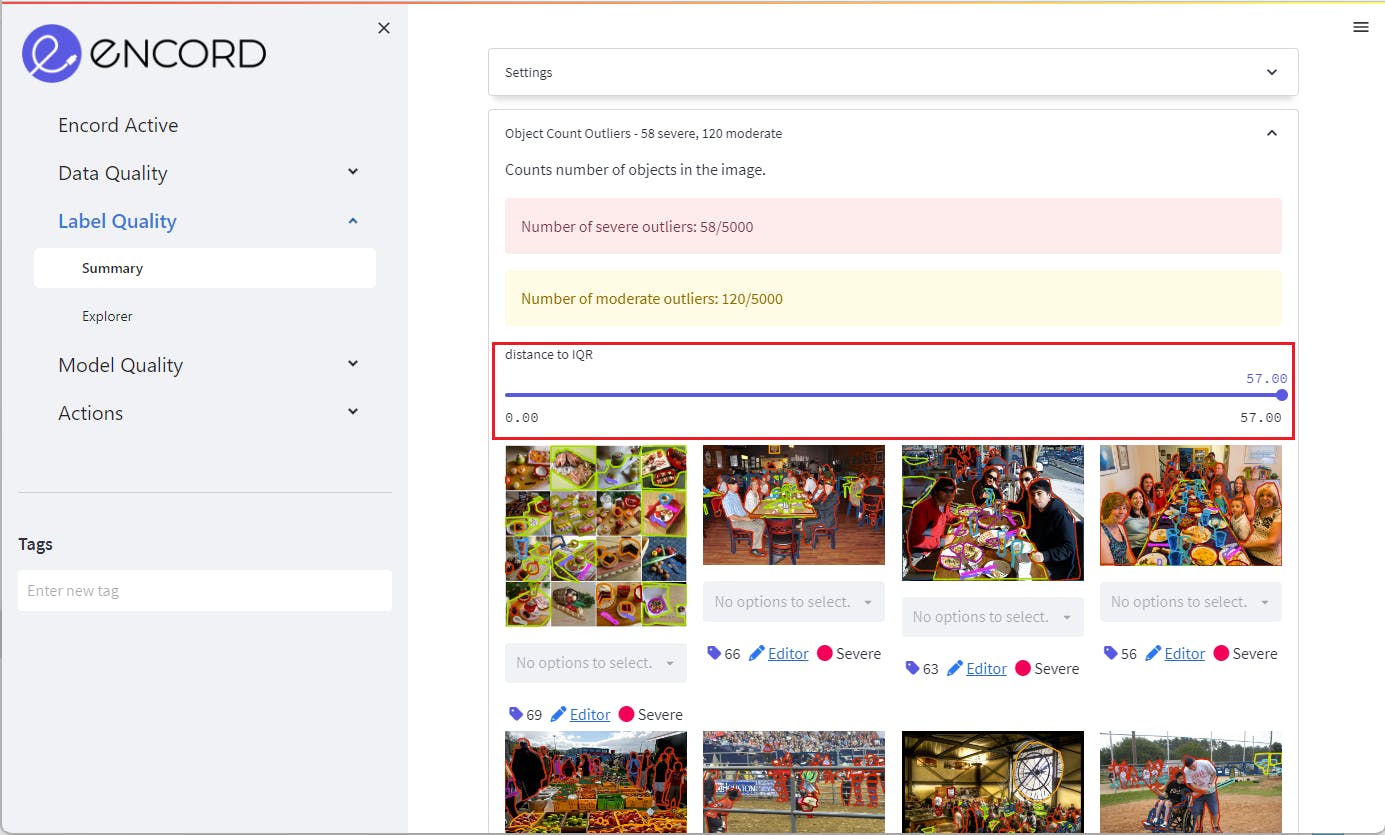
Access the tagged image group at the bottom of the left sidebar in the Actions tab.
Act on Label Outliers
Within the Actions tab, click "Filter data frame on" and select the "tags" option, allowing you to narrow the data frame to focus solely on the tagged label outliers.
You can choose the desired actions from here, such as exporting the outliers, relabeling them, augmenting the dataset, reviewing them in detail, or even deleting them when necessary.
How to Improve Training Data in Encord
After reviewing the outlier detection procedure using Encord, let's examine its advantages for enhancing training data.
Data Cleaning
With its comprehensive set of tools for outlier detection, data visualization, and data quality assessment, Encord Active empowers users to identify problematic data points easily.
You can efficiently detect and address problematic data points early in your machine learning pipeline by leveraging these features. This proactive approach ensures that you can identify and mitigate potential issues early on, leading to improved data quality and more reliable machine learning models.
💡Encord allows you to filter data in 3 ways: Standard filter feature, embeddings plot, and natural language search. Balancing Data Distribution
The Actions tab in Encord Active offers two valuable options for refining your dataset:
- Filtering and creating a new dataset
- Balancing your existing dataset
These options are accompanied by visualization capabilities, enabling you to make informed decisions about dataset quality without resorting to data augmentation or solely relying on the original dataset.
By creating a small, balanced dataset through filtering, you can conduct thorough tests on your machine learning model. This approach helps you finalize your model in the pipeline, assess its performance, and determine if they require any further adjustments or augmentations. It also helps you evaluate different machine learning models. That enables you to make informed decisions about the most effective approach for your specific task.
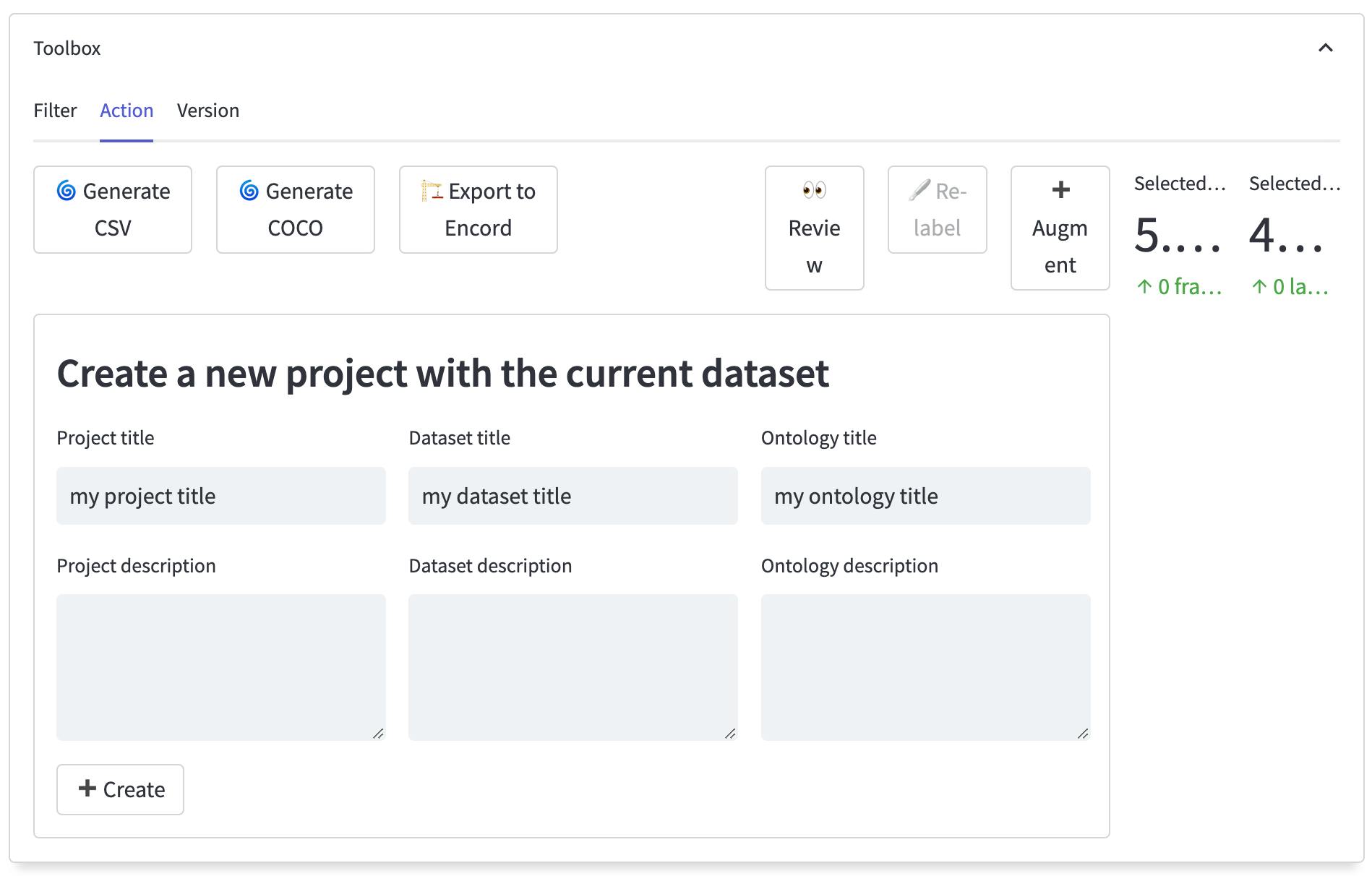
By leveraging the flexibility of the Actions tab in Encord Active and utilizing visualizations effectively, you can make data-driven choices regarding dataset balancing, augmentation, and model selection. This iterative process ensures that your training data is refined and optimized for the best possible model performance.
💡To know more about data balancing, read the blog Introduction to Balanced and Imbalanced Datasets in Machine Learning. Data Management
By utilizing Encord Index, a product of Encord, for data curation and management, teams can ensure datasets are clean, well-organized, and relevant to the training task.
This includes maintaining data versioning to track changes over time, implementing quality assurance measures to validate data integrity, and optimizing metadata management for efficient dataset retrieval and understanding.
Such practices not only streamline the preparation of high-quality training datasets but also contribute to improved model performance by reducing noise, ensuring data consistency, and enhancing the overall reliability of the training process.
Continuous Iteration and Feedback
Continuous iteration and refinement of training data based on model performance and feedback are crucial for achieving optimal results. Regularly evaluating the model's accuracy, identifying areas for improvement, and updating the training data accordingly are essential steps in this process.
Encord Active offers a range of tools to monitor model performance and assess the impact of data modifications, enabling informed decision-making. Model quality metrics provide a valuable means to evaluate data and labels using a trained model and imported predictions.
By leveraging these metrics, you can gain insights into the strengths and weaknesses of your dataset, enabling targeted improvements. Encord Active also helps with data versioning, allowing you to compare and assess the model's performance on each version. This iterative approach helps identify the best version of the dataset that yields optimal model performance.
By leveraging the feedback loop between model evaluation, dataset refinement, and performance assessment in Encord Active, you can continuously optimize your training data to improve model quality.
Conclusion
Improving training data quality is crucial for boosting the accuracy and effectiveness of machine learning models. Outlier detection, as explored in this blog post, plays a vital role in identifying and managing data outliers and label outliers. Encord Active offers robust outlier detection features that enable users to easily spot significant deviations in data. Encord Active streamlines the workflow by tagging and organizing outliers and ensuring data quality through its intuitive interface and comprehensive toolset.
However, the benefits of Encord Active extend beyond outlier detection. The platform empowers users to perform data cleaning, balance data distribution, and iterate on the dataset based on model performance and feedback. With data visualization, dataset filtering, and model quality metrics, users can make data-driven decisions and continually optimize their training data.
By proactively addressing problematic data points, balancing data distribution, and iterating on the dataset, users can enhance the quality and reliability of their machine learning models. Encord Active serves as a powerful platform for these tasks, enabling users to refine and optimize their training data to achieve optimal model performance.
Are you ready to improve your training data with Encord Active?
Sign-up for a free trial of Encord: The Data Engine for AI Model Development, used by the world’s pioneering computer vision teams.
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Frequently asked questions
Encord provides advanced annotation tools that can enhance the data annotation process by allowing users to specify different types of defects, rather than just identifying valid and invalid parts. This capability is particularly beneficial for automating quality control in manufacturing, as it helps to create more detailed datasets for training machine learning models.
Encord focuses on providing high-quality data annotation services that include a robust quality assurance process. This helps mitigate issues with inaccurate annotations, ensuring that the data used for training models is reliable and specific to the needs of projects such as corrosion detection.
Encord provides comprehensive solutions for building robust training pipelines, including automated and semi-automated annotation features. These capabilities allow teams to efficiently manage data preprocessing, annotation, and model training to streamline the overall machine learning workflow.
Encord facilitates similarity search by identifying and analyzing model outliers, allowing users to find analogous data points. This feature helps prioritize labeling efforts on edge cases, ensuring that new data is effectively utilized in training and refining models.
Encord helps teams analyze operational data by providing robust annotation tools that enable detailed tracking of processes. This analysis can lead to insights that drive efficiency improvements, compliance, and better decision-making in industrial environments.
Yes, Encord is designed to handle situations where the classes to be detected are not predefined. The platform provides tools for data annotation that can adapt to evolving project needs, allowing teams to identify and label new classes during the analysis.
Encord supports the enrichment of training data quality by enabling teams to collect varied types of data, including images from different origins. This diversity helps in building a more robust database for model training.
Encord aids in the collection and annotation of difficult samples that are crucial for training AI models. By focusing on these challenging cases, clients can improve their models' performance in real-world scenarios.
Encord uses advanced techniques to detect abnormal annotations by comparing model predictions with existing annotations. This process helps flag outliers and enhances the overall reliability of the annotated data.