Lessons Learned: Employing ChatGPT as an ML Engineer for a Day

Co-Founder & CEO at Encord
TLDR; Among the proliferation of recent use cases using the AI application ChatGPT, we ask whether it can be used to make improvements in other AI systems. We test it on a practical problem in a modality of AI in which it was not trained, computer vision, and report the results. The average over ChatGPT suggestions, achieves on average 10.1% improvement in precision and 34.4% improvement in recall over our random sample, using a purely data-centric metric driven approach. Code for the post is here.

Introduction
Few technological developments have captured the public imagination as quickly and as starkly as the release of ChatGPT by OpenAI.
Within two months of launch, it had garnered over 100 million users, the fastest public application to do so in history. While many see ChatGPT as a leap forward technologically, its true spark wasn’t based on a dramatic technological step change (GPT3, the model it is based on has been around for almost 3 years), but instead on the fact that it was an AI application perfectly calibrated towards individual human interactions.
It was its ostentatiousness as an AI system that could demonstrate real-world value that so thoroughly awed the public. Forms of AI are present in various aspects of modern life but are mostly hidden away (Google searches, Youtube recommendations, spam filters, identity recognition) in the background.
ChatGPT is one of the few that is blatantly artificial, but also intelligent. AI being in the limelight has spawned a deluge of thought pieces, articles, videos, blog posts, and podcasts.
Amid this content rush have been renewed questions and concerns around the more provocative implications of AI advancement, progression towards AI consciousness, artificial general intelligence(AGI), and a technological singularity. In the most speculative scenarios, the fear (or hope depending on who you ask) is that the sophistication, power, and complexity of our models will eventually breach an event horizon of breakaway intelligence, where the system develops the capability to iteratively self-improve both it’s core functionality and it’s own ability to self-improve. This can create an exponentially growing positive reinforcement cycle spurring an unknowable and irreversible transition of society and human existence as we know it.

Not yet, ChatGPT
To be clear…that’s not where we are.
ChatGPT is not the dawn of the Terminator. Prognosticating on the direction of a technology still in rapid development is often a folly, and on its broader implications even more so. However, in the presence of a large looming and unanswerable question, we can still develop insights and intuition by asking smaller, more palatable ones.
In that vein, we look for a simpler question we can pose and subsequently test on the topic of AI self-improvement:
Can we find an avenue by which we can examine if one AI system can iteratively improve another AI system?
We observe that the main agents at the moment for AI progression are people working in machine learning as engineers and researchers. A sensible proxy sub-question might then be:
Can ChatGPT function as a competent machine learning engineer?
The Set Up
If ChatGPT is to function as an ML engineer, it is best to run an inventory of the tasks that the role entails. The daily life of an ML engineer includes among others:
- Manual inspection and exploration of data
- Training models and evaluating model results
- Managing model deployments and model monitoring processes.
- Writing custom algorithms and scripts.
The thread tying together the role is the fact that machine learning engineers have to be versatile technical problem solvers. Thus, rather than running through the full gamut of ML tasks for ChatGPT, we can focus on the more abstract and creative problem-solving elements of the role.
We will narrow the scope in a few ways by having ChatGPT:
- Work specifically in the modality of computer vision: We chose computer vision both as it is our expertise and because as a large language model, ChatGPT, did not (as far as we know) have direct access to any visual media in its training process. It thus approaches this field from a purely conceptual point of view.
- Reason over one concrete toy problem: In honour of both the Python library we all know and love and the endangered animal we also all know and love, we pick our toy problem to be building a robust object detector of pandas. We will use data from the open source YouTube-VOS dataset which we have relabelled independently and with deliberate mistakes.
- Take an explicitly data-centric approach: We choose a data-centric methodology as it is often what we find has the highest leverage for practical model development. We can strip out much of the complication of model and parameter selection so that we can focus more on improving the data and labels being input into the model for training. Taking a more model-centric approach of running through hyper parameters and model architectures, while important, will push less on testing abstract reasoning abilities from ChatGPT.
- Use existing tools: To further simplify the task, we remove any dependence on internal tools ML engineers often build for themselves. ChatGPT (un)fortunately can’t spend time in a Jupyter Notebook. We will leverage the Encord platform to simplify the model training/inference by using Encord’s micro-models and running data, label, and model evaluation through the open source tool Encord Active. Code for running the model training is presented below.

With this narrowed scope in mind, our approach will be to use ChatGPT to write custom quality metrics through Encord Active that we can run over the data, labels, and model predictions to filter and clean data in our panda problem.
Quality metrics are additional parametrizations over your data, labels, and models; they are methods of indexing training data and predictions in semantically interesting and relevant ways. Examples can include everything from more general attributes like the blurriness of an image to arbitrarily specific ones like the number of average distance between pedestrians in an image.
ChatGPT’s job as our ML engineer will be to come up with ideas to break down and curate our labels and data for the purpose of improving the downstream model performance, mediated through tangible quality metrics that it can program on its own accord.
The code for an example quality metric is below:
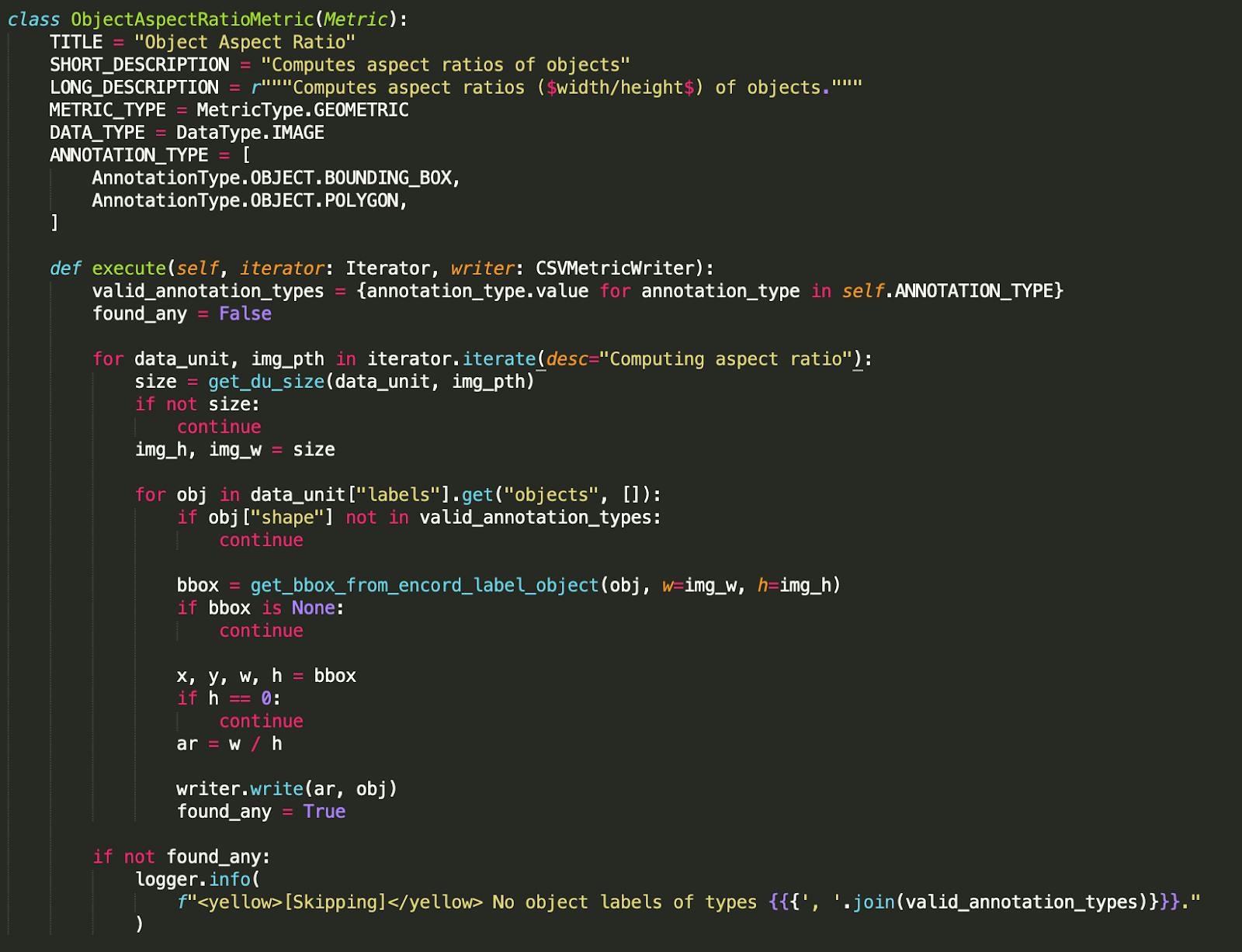
This simple metric calculates the aspect ratio of bounding boxes within the data set. Using this metric to traverse the dataset we see one way to break down the data:
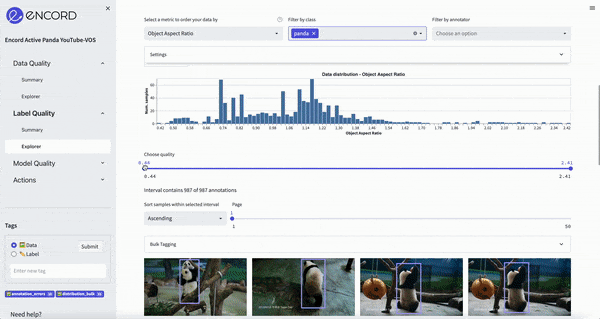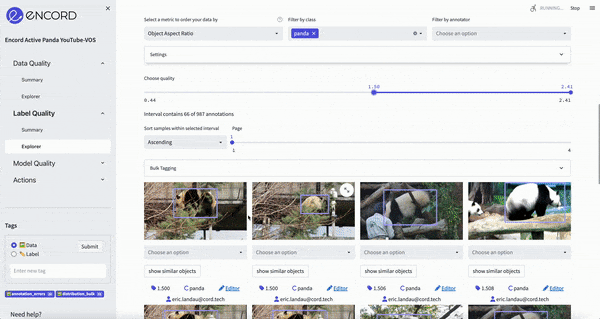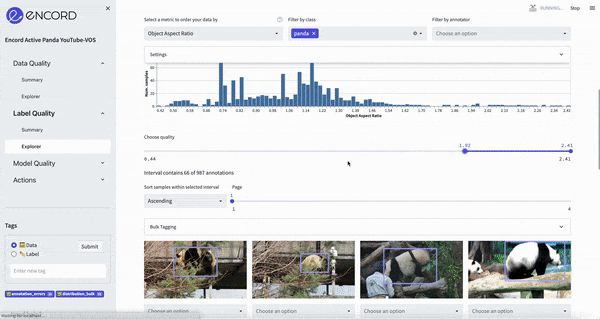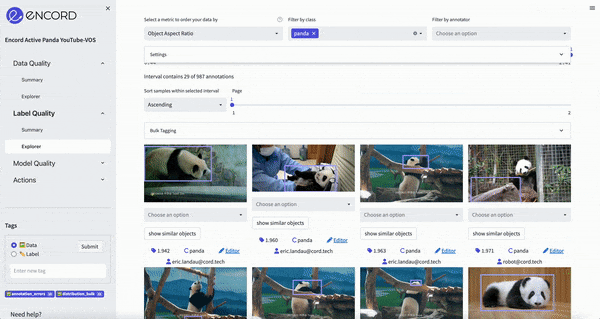
ChatGPT’s goal will be to find other relevant metrics which we can use to improve the data.
One final point we must also consider is that ChatGPT is at a great disadvantage as an ML engineer. It can’t directly see the data it’s dealing with. Its implementation capabilities are also limited. Finally, ChatGPT, as a victim of its own success, has frequent bouts of outages and non-responses. ChatGPT is an ML engineer at your company that lives on a desert island with very bad wifi where the only software they can run is Slack. We thus require a human-in-the-loop approach for practical reasons. We will serve as the eyes, ears, and fingers of ChatGPT as well as its probing colleagues in this project.
The Process
With the constraints set above, our strategy will be as follows:
- Run an initial benchmark model on randomly sampled data
- Ask ChatGPT for ideas to improve the data and label selection process
- Have it write custom quality metrics to instantiate those ideas
- Train new models on improved data
- Evaluate the models and compare
With a data-centric approach, we will limit the variables with which ChatGPT has to experiment to just quality metrics. All models and hyper parameters will remain fixed. To summarise:

One of the luxuries we have as humans versus a neural network trapped on OpenAI servers (for now), is we can directly look at the data. Through some light visual inspection, it is not too difficult to quickly notice label errors (that we deliberately introduced). Through the process, we will do our best to communicate as much as what we see to ChatGPT to give it sufficient context for its solutions. Some (incontrovertibly cute) data examples include:



With some clear labeling errors:


Not exactly pandas
Benchmarking
With all this established, we can start by running an initial model to benchmark ChatGPT’s efforts. For our benchmark we take a random sample of 25% of the training data set and run it through the model training loop described above. Our initial results come to a mean average precision (mAP) of 0.595 and mean average recall of 0.629.
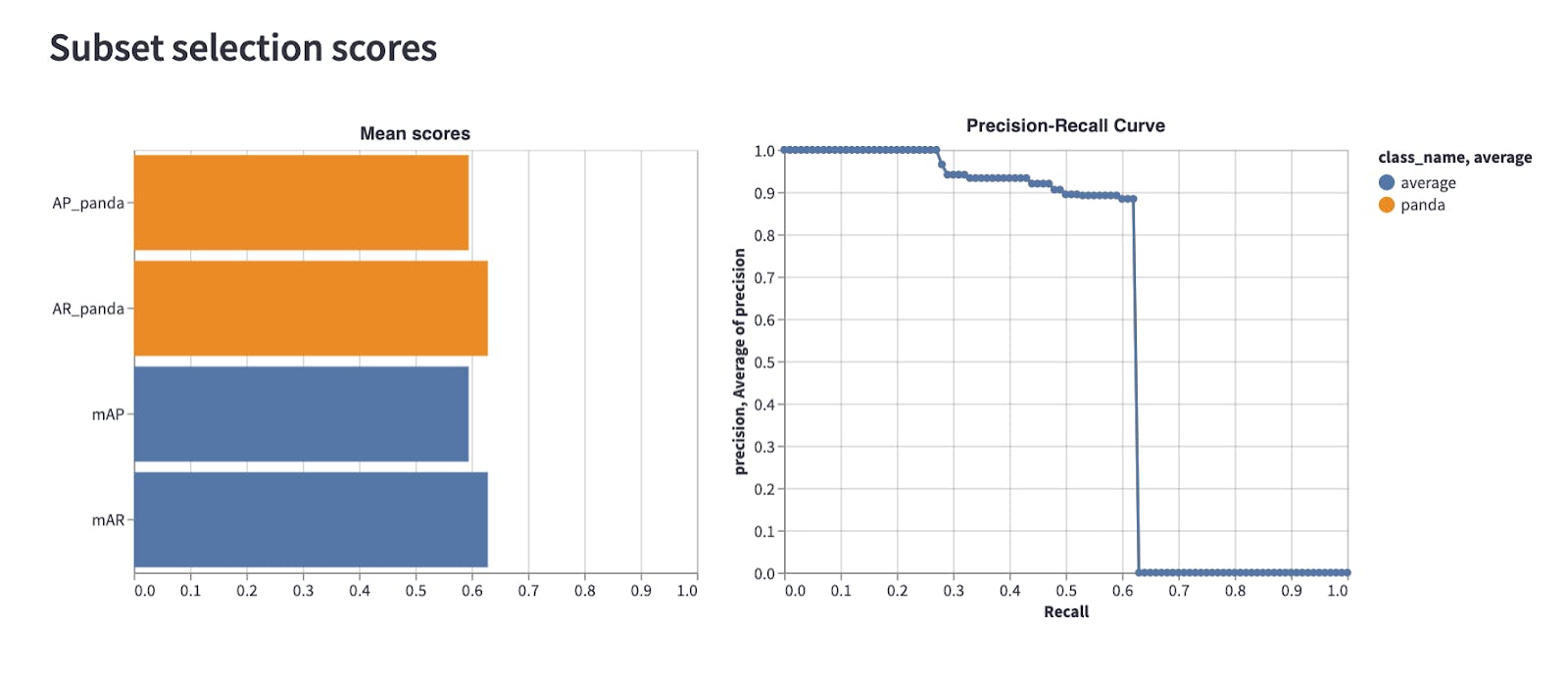
We can now try out ChatGPT for where to go next.
ChatGPT Does Machine Learning
With our benchmark set, we engage with ChatGPT on ideas for ways to improve our dataset with quality metrics. Our first approach is to set up a high-level description of the problem and elicit initial suggestions.


A series of back and forths yields a rather productive brainstorming session:
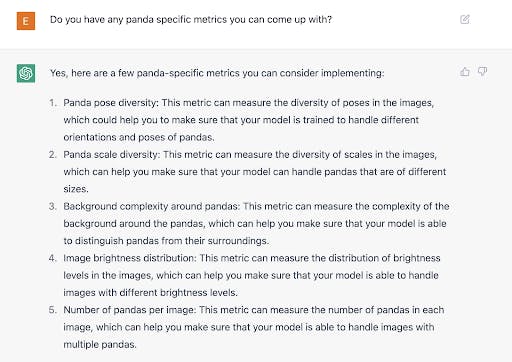
Already, we have some interesting ideas for metrics. To continue to pull ideas, we chat over a series of multiple long conversations, including an ill fated attempt to play Wordle during a break.
After our many interactions(and a solid rapport having been built) we can go over some of the sample metric suggestions ChatGPT came up with:
- Object Proximity: parametrizing the average distance between panda bounding boxes in the frame. This can be useful if pandas are very close to each other, which might confuse an object detection model.
- Object Confidence Score: this is a standard approach of using an existing model to rank the confidence level of a label with the initial model itself.
- Object Count: a simple metric, relevant for the cases where the number of pandas in the frame affects the model accuracy.
- Bounding Box Tightness: calculates the deviation of the aspect ratio of contours within the bounding box from the aspect ratio of the box itself to gauge whether the box is tightly fitted around the object of interest
Besides ideas for metrics, we also want its suggestions for how to use these metrics in practice.
Data selection:
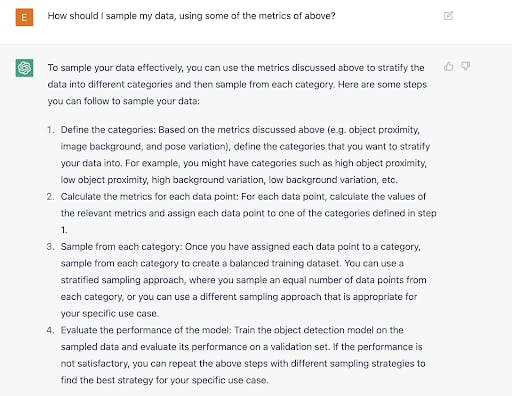
Let’s ask ChatGPT what it thinks about using metrics to improve data quality.
Label errors
We can also inquire about what to do when metrics find potential label errors.

To summarise, a few concrete strategies for improving our model according to ChatGPT are:
- Data Stratification: using metrics to stratify our dataset for balance
- Error Removal: filtering potential errors indicated by our metrics from the training data
- Relabeling: sending potential label errors back to get re-annotated
We have now compiled a number of actionable metrics and strategies through ChatGPT ideation. The next question is:
Can ChatGPT actually implement these solutions?
The next step will be for it to instantiate its ideas as its own custom metrics. Let’s try it out by inputting some sample metric code and instructions from Encord Active’s documentation on an example metric:

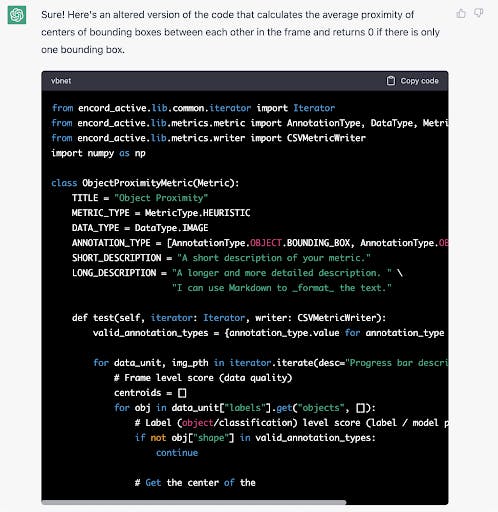
From the surface, it looks good. We run through various other metrics ChatGPT suggested and find similar plausible looking code snippets we can try via copy/paste. Plugging these metric into Encord Active to see how well it runs we get:

Looks like some improvement is needed here. Let’s ask ChatGPT what it can do about this.
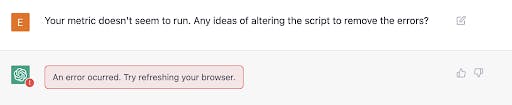
Uh-oh. Despite multiple refreshes, we find a stonewalled response. Like an unreliable colleague, ChatGPT has written buggy code and then logged out for the day, unresponsive.
Seems like human input is still required to get things running. After a healthy amount of manual debugging, we do finally get ChatGPT’s metrics to run. We can now go back and implement its suggestions.
As with any data science initiative, the key is trying many iterations over candidate ideas. We will run through multiple ChatGPT metrics and average the results, but for purposes of brevity we will only try the filtering strategy it suggested. We spare ChatGPT from running these experiments, letting it rest after the work it has done so far. We share sample code for some of our experiments and ChatGPT metrics in the Colab notebook here.
The Results
We run multiple experiments using ChatGPT’s metrics and strategies. Looking over metrics we can see ChatGPT’s model performance below.
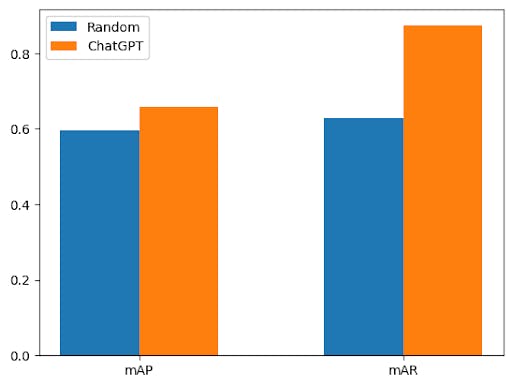
The average over ChatGPT metric suggestions, achieves on average 10.1% improvement in precision and 34.4% improvement in recall over our random sample, using a purely data-centric metric driven approach.
While not a perfect colleague, ChatGPT did a commendable job in ideating plausible metrics. Its ideas made a significant improvement in our panda detector. So is ChatGPT the next Geofrey Hinton?
Not exactly. For one, its code required heavy human intervention to run. We also would be remiss to omit the observation that in the background of the entire conversation process, there was a healthy dose of human judgement implicitly injected. Our most successful metric in fact, the one that had the most significant impact in reducing label error, and improving model performance was heavily influenced by human suggestion:
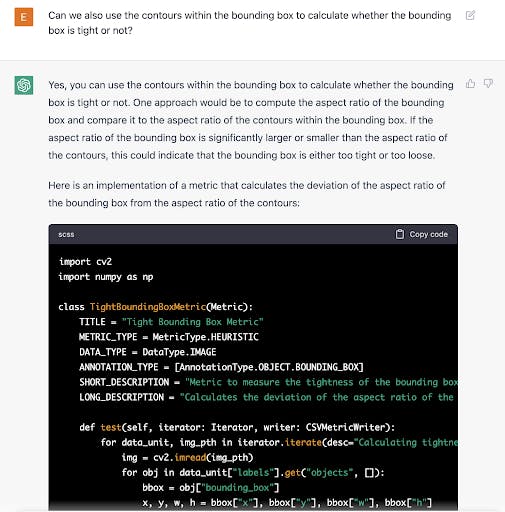
This “Bounding Box Tightness” metric, defined early, was arrived at over a series of prompts and responses. The path to the metric was not carved by ChatGPT, but instead by human hand.
ChatGPT also missed the opportunity for some simple problem-specific metrics. An obvious human observation about pandas is their black and white colour. A straightforward metric to have tried for label error would have been taking the number of white and black bounding box pixels divided by the total number of pixels in the box. A low number for this metric would indicate that the bounding box potentially did not tightly encapsulate a panda. While obvious to us, we could not coax an idea like this despite our best efforts.
Conclusion
Overall, it does seem ChatGPT has a formidable understanding of computer vision. It was able to generate useful suggestions and initial template code snippets for a problem and framework for which it was unfamiliar with. With its help, we were able to measurably improve our panda detector.The ability to create code templates rather than having to write everything from scratch can also significantly speed up the iteration cycle of a (human) ML engineer.
Where it lacked, however, was in its ability to build off its own previous ideas and conclusions without guidance. It never delved deeper into the specificity of the problem through focused reasoning.
For humans, important insights are not easily won, they come from building on top of experience and other previously hard-fought insights. ChatGPT doesn’t seem to have yet developed this capability, still relying on the direction of a “prompt engineer.” While it can be a strong starting point for machine learning ideas and strategies, it does not yet have the depth of cognitive capacity for independent ML engineering.
Can ChatGPT be used to improve an AI system? Yes.
Would we hire it as our next standalone ML engineer? No.
Let’s wait until GPT4.
In the meantime, if you’d like to try out Encord Active yourself you can find the open source repository on GitHub and if you have questions on how to use ChatGPT to improve your own datasets ask us on our Slack channel.

Frequently asked questions
Encord's managed workforce includes annotators with varying levels of expertise, capable of handling specialized tasks such as sentiment analysis or complex audio labeling. This flexibility allows teams to choose the right level of expertise to match their project's requirements.
Domain expertise is essential in the annotation process, especially for complex fields like medical imaging. While some data can be annotated with general labor, tasks like identifying hemorrhages in the brain require specialized knowledge to ensure accuracy and reliability.
Encord works closely with partners to help identify client needs and provide suitable technology solutions. By leveraging Encord's knowledge of the industry, partners can confidently recommend the right tools to their clients.