Contents
Micro-Models: Origin Story
What are micro-models exactly?
Added Benefits to using Micro-models in computer vision projects
Data-oriented Programming
Encord Blog
An Introduction to Micro-Models for Labeling Images and Videos




In this article, we are introducing the “micro-model” methodology used at Encord to automate data annotation. We have deployed this approach on computer vision labeling tasks across various domains, including medical imaging, agriculture, autonomous vehicles, and satellite imaging.
Let's cut to the chase:
- What are micro-models? Low-bias models are applied to a small group of images or videos within a dataset.
- How do micro-models work? Overfitting deep-learning models on a handful of examples of a narrowly defined task for this to be applied across the entire dataset once accuracy is high enough.
- Why use micro-models in computer vision? Saving hundreds of hours of manual labeling and annotation.
How much data do you need to build a micro-model that detects Batman?

Dark Knight vision
This of course, depends on your goal. Maybe you want a general-purpose model that can detect the Batmen of Adam West, Michael Keaton, and Batfleck all in one. Maybe you need it to include a Bruce Wayne detector that can also identify the man behind the mask.
But if you want a model that follows Christian Bale Batman in one movie, in one scene, the answer is…five labeled images. The model used to produce the snippet of model inference results above was trained with the five labels below:





The five labels used to train the micro-model
I hope that helps to answer the first question, and it might be surprising that all it takes are five images.
This model is only a partial Batman model. It doesn’t perform that well on the Val Kilmer or George Clooney Batmen, but it’s still functional for this specific use case. Thus, we won’t call it a Batman model but a Batman micro-model.
Micro-Models: Origin Story
Don’t worry; the origin story behind micro-models doesn’t start with a rich boy suddenly being made an orphan.
We started using micro-models in the early days of Encord when we focused purely on video datasets and computer vision models.
We stumbled upon the idea when trying out different modeling frameworks to automate the classification of gastroenterology videos (you can find more about that here).
Our initial strategy was to try a “classical” data science approach of sampling frames from a wide distribution of videos, training a model, and testing on out-of-sample images of a different set of videos. We would then use these models and measure our annotation efficiency improvement compared to human labeling.
During these experiments, we realized that a classification model trained on a small set of intelligently selected frames from only one video already produced strong results. We also noticed that as we increased the number of epochs, our annotation efficiencies increased.
This was contrary to what we knew about data science best practices (something the whole team has a lot of experience in). Inadvertently, we were grossly overfitting a model to this video. But it worked, especially if we broke it up such that each video had its model. We called them micro-models. While this was for video frame classification, we have since extended the practice to include object detection, segmentation, and human pose estimation tasks.

What are micro-models exactly?
Most succinctly, micro-models are annotation-specific models that are overtrained to a particular task or particular piece of data.
Micro-models purposefully overfit models such that they don’t perform well on general problems but are very effective in automating one aspect of your data annotation workflow. They are thus designed to only be good at one thing. To use micro-models in practice for image or video annotation and labeling, it’s more effective to assemble several together to automate a comprehensive annotation process.
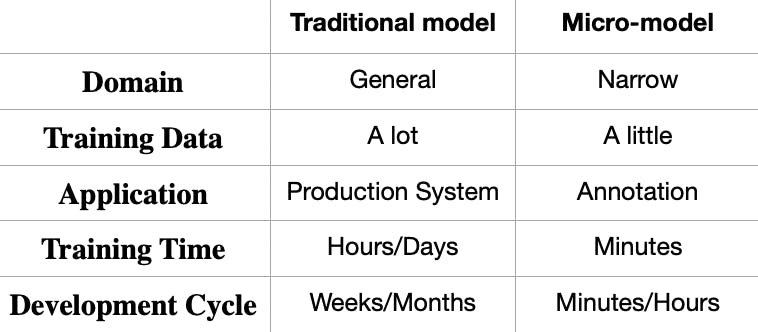
The distinction between a “traditional” model and a micro-model is not in their architecture or parameters but in their domain of application, the counter-intuitive data science practices that are used to produce them, and their eventual end uses.
Explaining Micro-models in more detail: 1-dimensional labeling
To cover how micro-models work, we will take a highly simplified toy model that can give a clearer insight into the underpinnings beneath them. Machine learning (ML) at its core is curve-fitting, just in a very high-dimensional space with many parameters. It’s useful to distill the essence of building a model to one of the simplest possible cases, one-dimensional labeling. The following is slightly more technical; feel free to skip ahead.
Imagine you are an AI company with the following problem:
- You need to build a model that fits the hypothetical curve below
- You don’t have the x-y coordinates of the curve and can’t actually see the curve as a whole; you can only manually sample values of x, and for each one, you have to look up the corresponding y value associated with it (the “label” for x).
- Due to this “labeling” operation, each sample comes with a cost.
You want to fit the whole curve with one model, but it’s too expensive to densly sample the right volume of points. What strategies can you use here?
One strategy is fitting a high-degree polynomial to an initial set of sampled points across the curve domain, re-sampling at random, evaluating the error, and updating the polynomial as necessary. The issue is that you must re-fit the whole curve each time new sample points are checked. Every point will affect every other. Your model will also have to be quite complex to handle all the different variations in the curve.
Another strategy, which resolves these problems, is to sample in a local region, fit a model that approximates just that region, and then stitch together many of these local regions over the entire domain. We can try to fit a model to just this curved piece below, for instance:
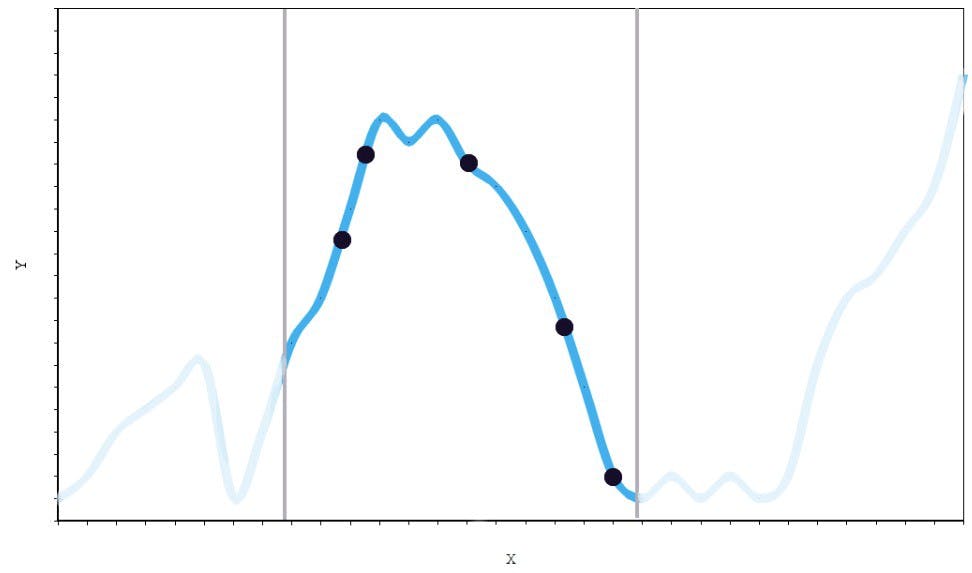
This is spline interpolation, a common technique for curve-fitting. Each spline is purposefully “overfit” to a local region. It will not extrapolate well beyond its domain, but it doesn’t have to. This is the conceptual basis for micro-models manifested in a low-dimensional space. These individual spline units are analogous to “micro-models” that we use to automate our x-value labeling.
A more general use case follows similar core logic with some additional subtleties (like utilizing transfer learning and optimizing sampling strategies). To automate a full computer vision annotation process, we also “stitch” micro-models together in a training data workflow, similar to an assembly line. Note assembling weak models together to achieve better inference results is an idea that has been around for a long time. This is a slightly different approach.
At Encord, we are not averaging micro-models together for a single prediction, we let each one handle predictions on their own. Micro-models are also not just “weak learners.” They just have limited coverage over a data distribution and exhibit very low bias over that coverage.
With micro-models, we are leveraging the fact that during the annotation workflow process, we have access to some form of human supervision to “point” the models to the correct domain. This guidance over the domain of the micro-model allows us to get away with using very few human labels to start automating a process.
Batman Efficiency
Models can be defined based on form (a quantifiable representation approximating some phenomena in the world) or on function (a tool that helps you do stuff). My view leans toward the latter. As the common quote goes:
All models are wrong, but some are useful.
Micro-models are no different. Their justification flows from using them in applications along a variety of domains.
To consider the practical considerations of micro-models with regard to annotation, let’s look at our Batman example. Taking fifteen hundred frames from the scene we trained our model on, we see that Batman is present in about half of them. Our micro-model in turn picks up about 70% of these instances. We thus get around five hundred Batman labels from only five manual annotations.
There are of course issues of correction. We have false positives for instance. Consider the inference result of one of the “faux” Batmen from the scene that our model picks up on.

I’m (not) Batman
We also have bounding boxes that are not as tight as they could be. This is all, however, with just the first pass of our micro-model. Like normal models, micro-models will go through a few rounds of iteration. For this, active learning is the best solution.
We only started with five labels, but now with some minimal correction and smart sampling, we have more than five hundred labels to work with to train the next generation of our micro-model. We then use this more powerful version to improve on our original inference results and produce higher-quality labels. After another loop of this process, when accounting for a number of human actions, including manual corrections, our Batman label efficiency with our micro-model gets to over 95%.
Added Benefits to using Micro-models in computer vision projects
There are some additional points to consider when evaluating micro-models:
- Time to get started: You can start using micro-models in inference within five minutes of a new project because they require so few labels to train.
- Iteration time: A corollary to the speed of getting started is the short iteration cycle. You can get into active learning loops that are minutes long rather than hours or days.
- Prototyping: Short iteration cycles facilitate rapid model experimentation. We have seen micro-models serve as very useful prototypes for the future production models people are building. They are quick checks if ideas are minimally feasible for an ML project.
Data-oriented Programming
While we have found success in using micro-models for data annotation, we think there’s also a realm of possibility beyond just data pipeline applications. As mentioned before, AI is curve fitting. But even more fundamentally, it’s getting a computer to do something you want it to do, which is simply programming. In essence, micro-models are a type of programming that is statistically rather than logically driven.
“Normal” programming works by establishing deterministic contingencies for the transformation of inputs to outputs via logical operations. Machine learning thrives in high-complexity domains where the difficulty in logically capturing these contingencies is supplanted by learning from examples. This statistical programming paradigm is still in its infancy and hasn’t developed the conceptual frameworks around it for robust practical use yet.
For example, the factorization of problems into smaller components is one of the key elements of most problem-solving frameworks. The object-oriented programming paradigm was an organizational shift in this direction that accelerated the development of software engineering and is still in practice today. We are still in the early days of AI, and perhaps instantiating a data-oriented programming paradigm is necessary for similar rapid progression.
In this context, micro-models might have a natural analog in the object paradigm. One lump in a complex data distribution is an “object equivalent” with the micro-model being an instantiation of that object. While these ideas are still early, they coincide well with the new emphasis on data-centric AI. Developing the tools to orchestrate these “data objects” is the burden for the next generation of AI infrastructure. We are only getting started, and still have a long way to go.

Explore our products
Index
Manage & curate your data
Understand and manage your visual data, prioritize data for labeling, and initiate active learning pipelines.
Annotate
Supporting your labeling needs
Super charge your data annotation with AI-powered labeling — including automated interpolation, object detection and ML-based quality control.
Active
Find & fix data issues with ease
Monitor, troubleshoot, and evaluate the data and labels impacting model performance.