GPT-4 Vision Alternatives

GPT-4 Vision by OpenAI integrates computer vision and language understanding to process text and visual inputs.
This multimodal approach enhances the model's interpretation and response to complex inputs, proving effective in tasks like Optical Character Recognition (OCR), Visual Question Answering (VQA), and Object Detection.
However, despite GPT-4 Vision's impressive capabilities, its limitations and closed-source nature have spurred interest in open-source alternatives.
These alternatives, known for their flexibility and adaptability, are pivotal for a diverse technological ecosystem.
They allow for broader application and customization, especially in fields requiring specific functionalities like OCR, VQA, and Object Detection.
This article explores:
- Four (4) open-source GPT-4V alternatives
- Features of the GPT-4V alternatives
- The potential applications and limitations
- Thorough comparison of performance across different attributes
Let’s jump right in!
GPT-4 Vision
The model supports various image formats, including PNG, JPEG, WEBP, and non-animated GIF files. Users can provide images in base64 encoded format to the GPT-4 Vision API for analysis. This flexibility makes GPT-4 Vision versatile in handling various visual inputs.
Key Capabilities
- Data analysis: GPT-4 Vision excels in analyzing data visualizations, interpreting the patterns underlying the data, and providing key insights based on the interpretation. However, accuracy may vary depending on the complexity of the data and the context provided.
- Creative applications: By combining GPT-4 Vision with DALL-E-3, users can create image prompts, generate visuals, and craft accompanying text, opening up new avenues for creative expression.
- Web development: GPT-4 Vision can convert visual designs into website source code. It can generate the corresponding HTML and CSS code by providing a visual image of the desired website layout, significantly reducing development time.
- Accessibility enhancement: The model has been tailored for applications like the "Be My Eyes" app, helping to make digital content more accessible to visually impaired users. By analyzing images and providing explanations, GPT-4 Vision improves the accessibility of visual information.
Potential Applications
- Educational and Academic Applications: It can transcribe and analyze mathematical concepts and handwritten content for students, researchers, and academics.
- Image Data Analysis for Geographical Exploration: It can analyze satellite photos and determine their geographical source for exploring different places in geography and travel.
- Interior Design and Architecture: GPT-4V can offer suggestions for room improvements based on an input image.
- Object Identification: The model can identify objects such as cables or medicines and explain relevant details that are beneficial for everyday use and shopping
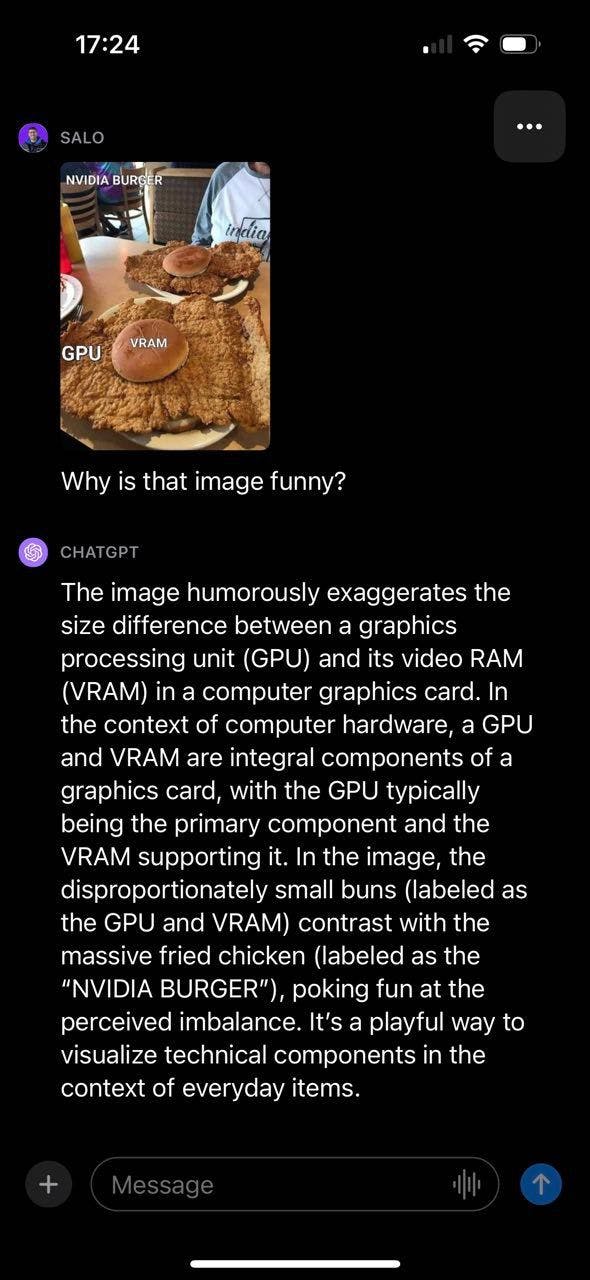
Limitations
GPT-4 Vision, while offering a range of capabilities, also comes with certain limitations that users should be aware of:
- Data Analysis Limitations: GPT-4 Vision's ability to analyze data visualizations and interpret patterns is not infallible. The model's accuracy in providing insights can vary with the complexity of the data and the context given. This means that the interpretations might only sometimes be accurate or comprehensive for highly complex or nuanced data.
- Creative Applications: While GPT-4 Vision, combined with DALL-E-3, opens creative avenues, the quality and relevance of generated visuals and text can vary. The interpretations and creations are based on the model's training data, which might only encompass some artistic styles or cultural contexts.
- Web Development: Though GPT-4 Vision can convert visual designs into website code, the generated HTML and CSS might only sometimes align with best coding practices or advanced web functionalities. It is a starting point but may require manual refinement for complex web projects.
- Cost: GPT-4 Vision can be cost-intensive, particularly for high-volume tokens. Costs can escalate quickly with increased API calls, which can be a limiting factor for small businesses or individuals.
- Data Privacy Concerns: GPT-4 Vision raises privacy concerns, especially in sensitive or personal data applications. Users must know how their data is stored, processed, and potentially shared, adhering to data protection regulations like GDPR.
When choosing alternatives to GPT-4 Vision, consider their accuracy in interpreting visual data and their ability to handle specialized, domain-specific tasks. Also, assess their integration capabilities and scalability to ensure they align with your project's needs and resources.
Alternatives to GPT-4 Vision
Open source alternatives to GPT-4 Vision perform well on multimodal tasks like OCR, VQA, and object detection that you can fine-tune to your specific needs and applications. We will discuss the four popular alternatives:
- LLaVa 1.5
- Qwen-VL
- CogVLM
- BakLLaVa
LLaVA 1.5
Research Paper | Github Repo | Model | Demo
LLaVA 1.5 is a novel end-to-end trained large multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding with state-of-the-art accuracy on Science QA.
Overview of Features
LLaVA 1.5, building upon its predecessor LLaVA, includes several enhancements:
- It integrates a CLIP-ViT-L-336px with a Multi-Layer Perceptron projection, adding academic-task-oriented VQA data.
- Simple modifications to the model architecture have led to state-of-the-art performance across 11 benchmarks using a relatively modest amount of public data (1.2 million data points).
- The model is designed for general-purpose visual and language understanding.
- LLaVA 1.5's simpler architecture requires significantly less training data than models like Qwen-VL and HuggingFace IDEFICS. This efficiency and its open-source nature, hosted on GitHub and HuggingFace, make LLaVA 1.5 accessible.
UPDATE: The researchers released LLaVA-NeXT with improved reasoning, OCR capabilities, and worldview over LLaVA-1.5. Along with the performance improvements, LLaVA-NeXT maintains the minimalist design and data efficiency of LLaVA-1.5. It re-uses the pre-trained connector of LLaVA-1.5 and still uses less than 1M visual instruction tuning samples. The largest 34B variant finishes training in ~1 day with 32 A100s. Learn more about these improvements on this page.
At Encord, we released an LLaVA-powered classification feature to automatically label your image based on nothing more than natural language comprehension of your labeling ontology. Give the tool an image and an arbitrarily complex ontology, and let it auto-label for you! Use LLaVA to annotate your images within Encord automatically. See how to get started in this blog post.
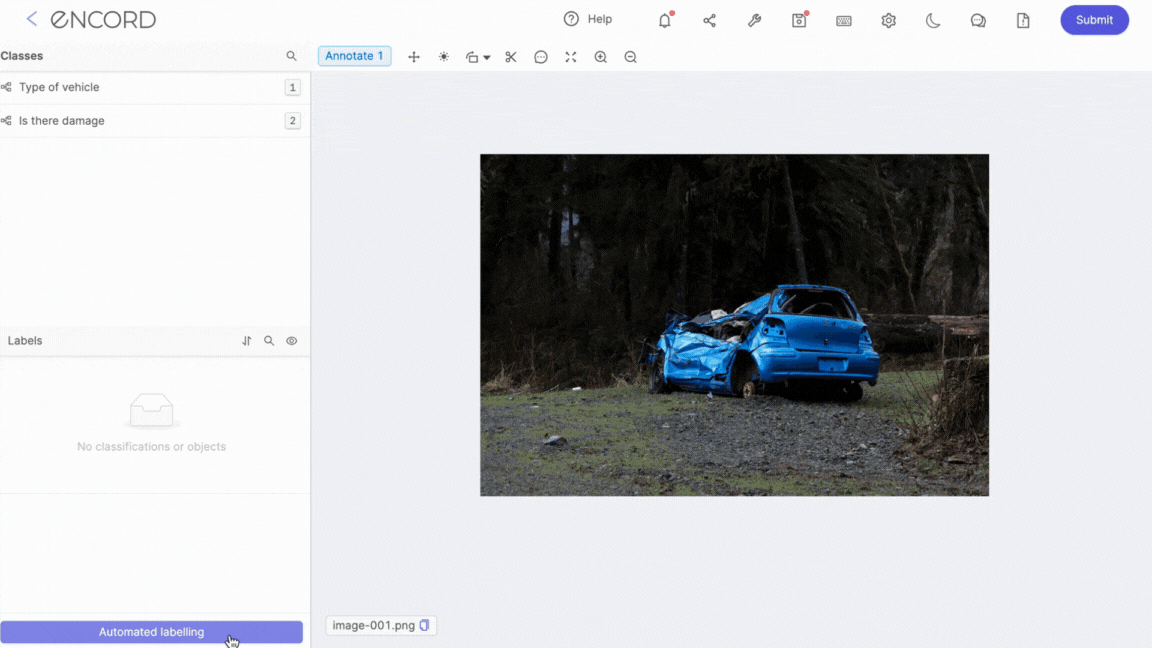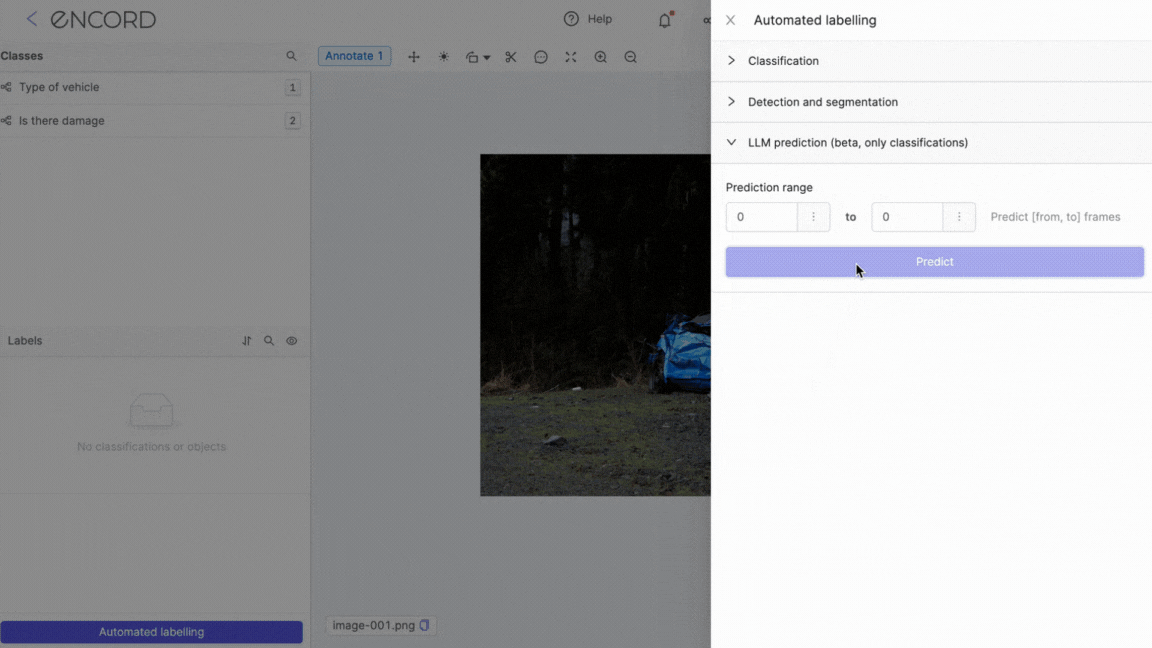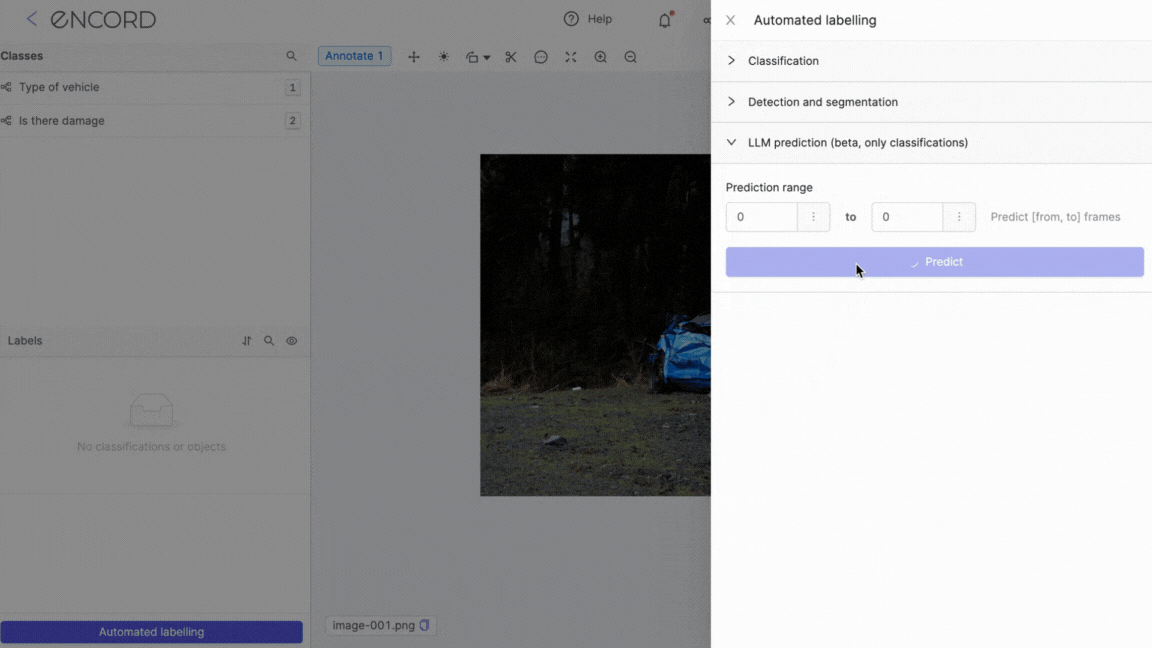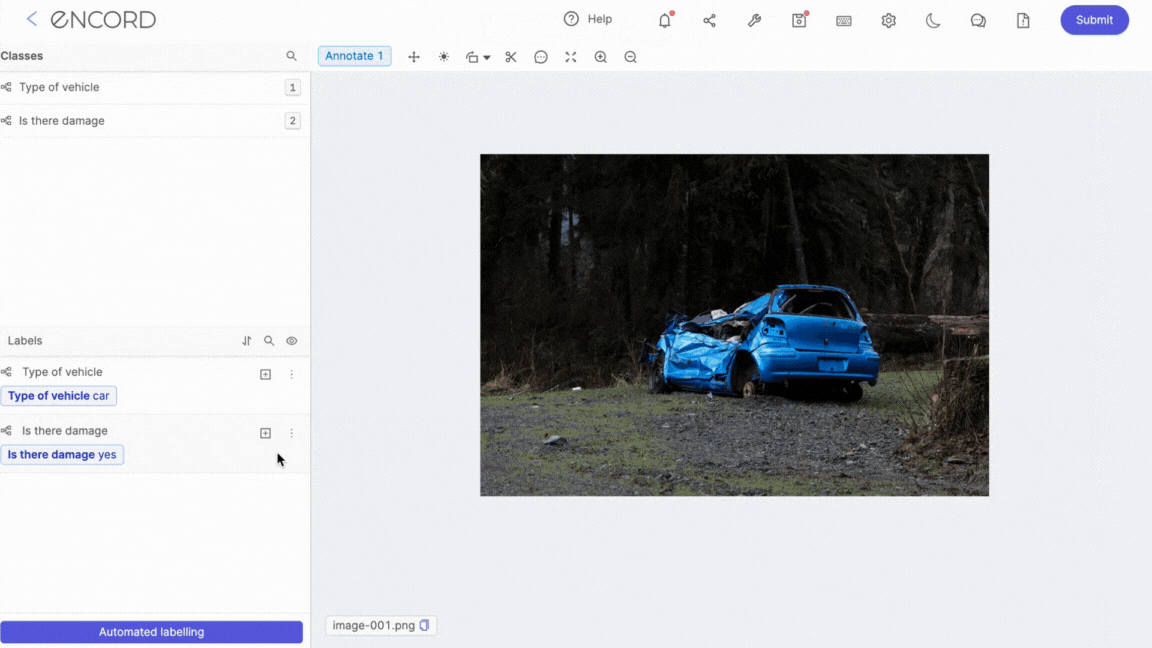
Capabilities in Zero-Shot Object Detection
Testing has shown that LLaVA 1.5 can detect objects and provide their coordinates in images. This highlights its efficacy in visual comprehension and object detection tasks.
Limitations and Training Efficiency
- Front-end code writing: While LLaVA 1.5 excels in many areas, it has limitations. For example, it needs to improve writing front-end code according to design, with relatively crude outputs.
- Language translation: Additionally, it struggles with translation tasks, indicating limitations in language translation tasks.

Qwen-VL
Research Paper | Github Repo | Model | Demo
This model is based on the Qwen-LM, enhanced with a visual receptor, an input-output interface, a 3-stage training pipeline, and a multilingual multimodal corpus.
The primary function of Qwen-VL is to align image-caption-box tuples, facilitating capabilities beyond conventional image description and question-answering.
Overview of Features: Qwen-VL
Qwen-VL, an advancement in Large Vision Language Models (LVLMs), showcases its strength in two key areas - multilingual support and Optical Character Recognition (OCR). Here are its notable features:
- Robust Multilingual Support: Qwen-VL excels in multilingual capabilities, particularly supporting English and Chinese. Its ability to perform end-to-end recognition of bilingual text in images is a significant feature. This functionality makes Qwen-VL highly adaptable for various international contexts, catering to a broader range of linguistic needs.
- Enhanced Optical Character Recognition: The model demonstrates strong performance in OCR and can fine-grained text recognition and understanding. This proficiency in OCR marks a notable improvement over other open-source LVLMs. Compared to its competitors' typical 224x224 resolution, Qwen-VL uses a higher resolution of 448x448. This increased resolution contributes to its enhanced capability in text recognition and document quality assurance.
Strengths in Multilingual Support and OCR
One of the standout features of Qwen-VL is its robust multilingual support in English and Chinese. This model facilitates end-to-end recognition of bilingual text (Chinese and English) in images, making it highly versatile in several international contexts.
Additionally, it exhibits strong performance in Optical Character Recognition (OCR) and can fine-grained text recognition and understanding.
This is a step up from other open-sourced LVLMs, which typically use a 224x224 resolution, as Qwen-VL employs a 448x448 resolution for improved text recognition and document QA.

Qualitative samples produced by Qwen-VL Chat
Use Cases and Potential Applications
Qwen-VL's versatility allows for applications like multi-image storytelling and spatial visual understanding. Its bilingual grounding ability and high-resolution OCR make it ideal for tasks requiring detailed text and image analysis.
Additionally, Qwen-VL sets new standards in image captioning, question answering, and visual grounding, outperforming existing models in real-world dialog and vision-language tasks.
The Qwen-VL-Chat variant, an instruction-tuned multimodal LLM-based AI assistant, also demonstrates superiority in real-world dialog benchmarks compared to existing vision-language chatbots.
CogVLM: Cognitive Visual Language Model
Research Paper | Github Repo | Model | Demo
CogVLM stands out as an innovative open-source visual language model, notable for its integration of diverse components and capabilities:
- CogVLM incorporates a Vision Transformer (ViT) Encoder designed to process image data, ensuring high-quality visual understanding. Adding a Multilayer Perceptron (MLP) Adapter enhances its capability to handle complex data transformations.
- Integration with a pre-trained Large Language Model (GPT) for text data, enabling sophisticated language processing. Including a Visual Expert Module contributes to its advanced visual and textual data interpretation, making the model highly versatile across various tasks.
Overview of Features and Improvements: CogVLM (Cognitive Visual Language Model)
- Visual Grounding and Image Description: The model excels in visual grounding, connecting textual descriptions with specific image regions. This skill is vital for tasks that require an in-depth understanding of the relationship between visual elements and textual information.
- Demonstrating state-of-the-art performance in picture captioning across several benchmarks, such as NoCaps and Flicker30k, CogVLM showcases its exceptional ability in image captioning. It can describe images with accuracy and contextual relevance, reinforcing its powerful text-image synthesis capabilities.
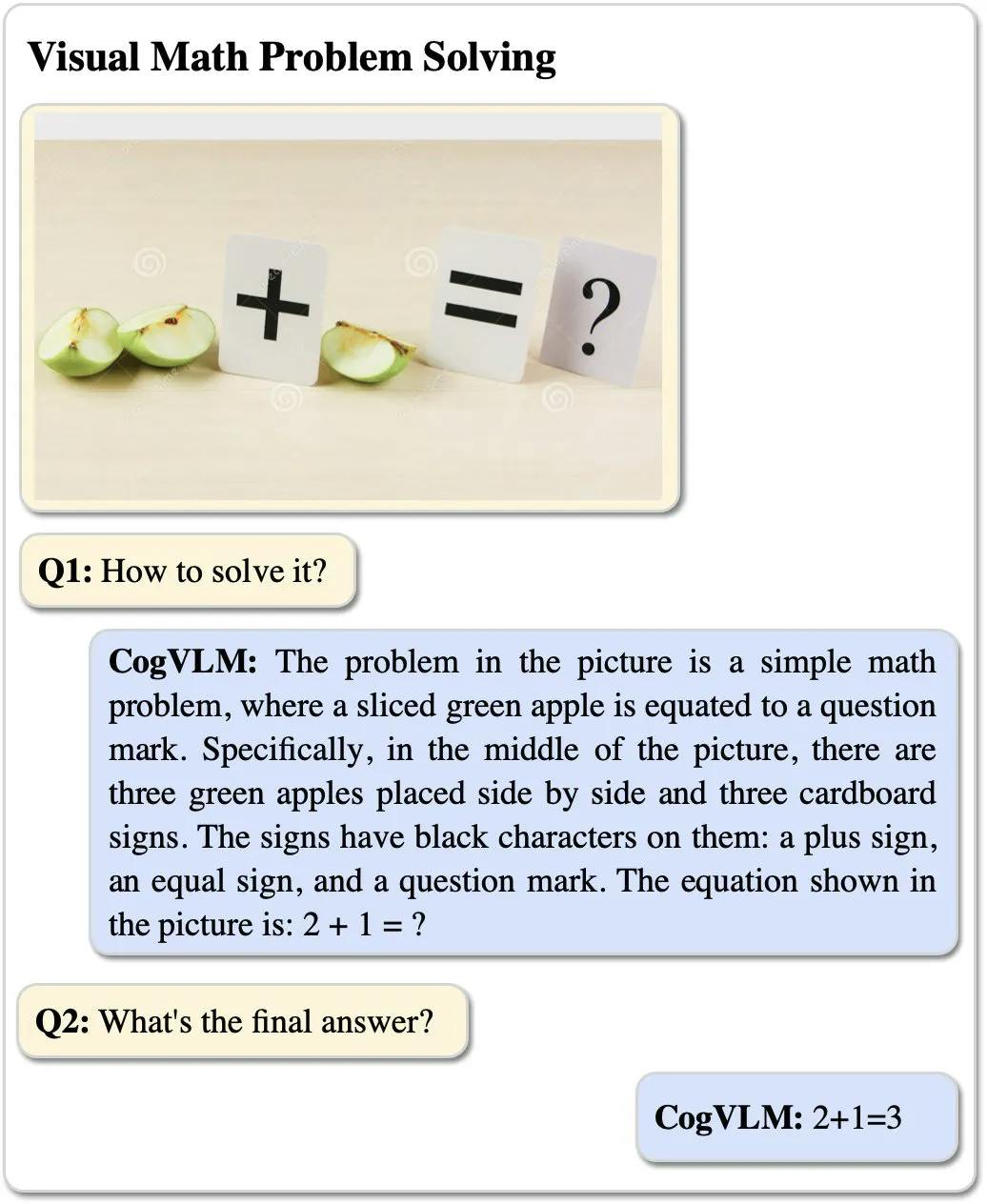
Chat examples by the CogVLM chat interface
Applications in Various Contexts
- Medical Imaging: CogVLM's detailed analysis and high accuracy make it ideal for medical imaging applications, where precise interpretation is critical.
- Security Surveillance: In security contexts, the model's ability to analyze and interpret text and image data can enhance surveillance capabilities.
- Internet Searches: Its proficiency in handling complex queries involving images and text makes it a valuable tool for enhancing search engine functionalities.
- Educational Materials: CogVLM can contribute significantly to developing educational resources, especially those integrating visual and textual content for a more comprehensive learning experience.
- Open-Source Accessibility: Being open-source, CogVLM is accessible to a broad range of users, including researchers, developers, and AI enthusiasts, fostering a collaborative environment for innovation in AI.
- Promoting Innovation and Growth: The model's open-source nature encourages innovation and growth in AI, allowing for continuous development and improvement.

BakLLaVA
Research Paper | Github Repo| Model | Demo
BakLLaVA is a multimodal model (LMM) developed collaboratively by LAION, Ontocord, and Skunkworks AI. Its design incorporates a Mistral 7B base, augmented with the LLaVA 1.5 architecture. This combination aims to leverage the strengths of both components, offering an advanced solution for multimodal AI tasks.
Overview of Features and Improvements: BakLLaVA
- Adaptability and Accessibility: Designed to run efficiently on laptops, BakLLaVA ensures accessibility to a broader range of users, provided they have adequate GPU resources. This feature makes it an attractive option for individual researchers, developers, and AI hobbyists needing access to high-end computing infrastructure.
- Enhanced Functionalities with Auxiliary Tools: BakLLaVA's functionality can be further expanded using tools like llama.cpp. This tool facilitates running the LLaMA model in C++, broadening BakLLaVA's scope and enhancing its applications in various AI-driven tasks.
Efficiency and Resource Management
- BakLLaVA's design emphasizes resource efficiency.
- Integrates Mistral 7B with LLaVA 1.5 for high performance with lower computational demand.
- Suitable for applications with limited GPU resources; operable on laptops.
- Appeals to a wider user and developer base due to its less resource-intensive nature.
Limitations and Fine-Tuning
- BakLLaVA faces challenges in writing refined front-end code.
- Achieves top results on benchmarks but requires fine-tuning for optimal performance.
- Necessity for customization to specific tasks or datasets.
- Less effective in language translation tasks.
How Do These Alternatives Compare with GPT-4 Vision
The Large Multimodal Models (LMMs) landscape is advancing with different alternatives to GPT-4 Vision, each exhibiting distinct strengths and weaknesses.
Here's a detailed analysis and comparison:
Performance Benchmarks
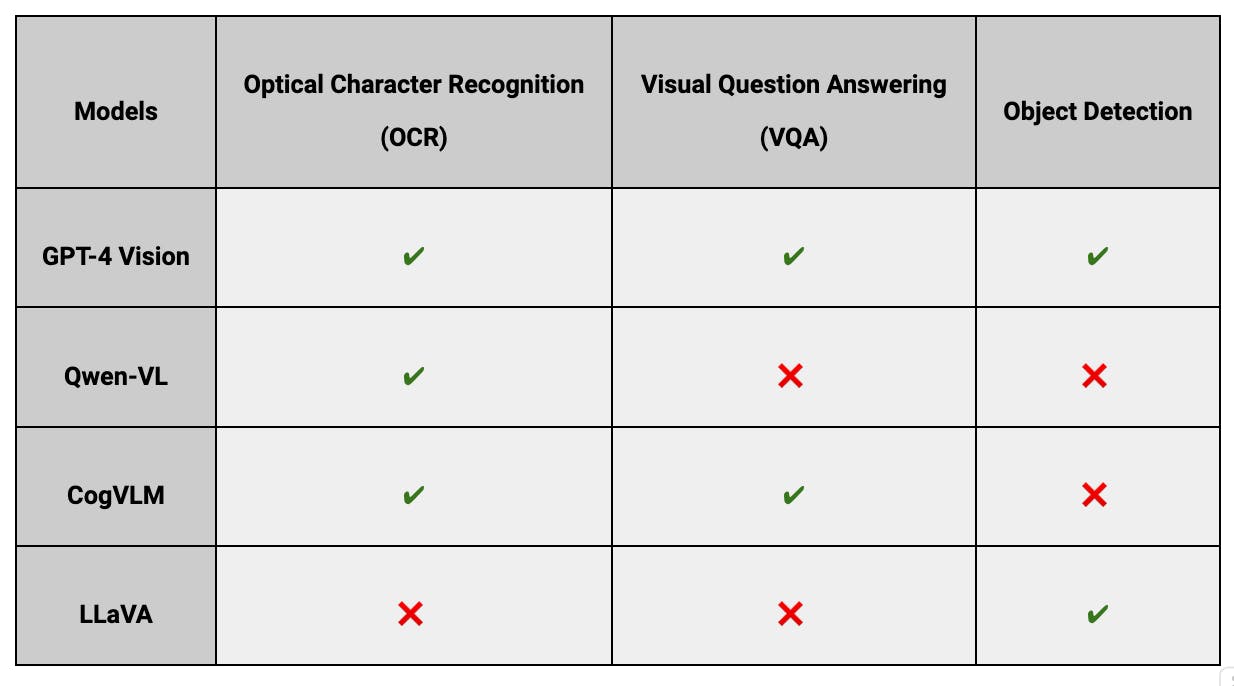
Model comparison - Performance benchmark
Open Source vs Proprietary Models
Open-source models like Qwen-VL, CogVLM, LLaVA, and BakLLaVA offer customization and flexibility, ideal for environments with specific needs or limitations. Proprietary models like GPT-4 Vision provide consistent updates and support but less deployment control and potential data privacy concerns.
Performance Comparison: GPT-4 Vision Vs. AI Models
The heatmap compares AI models against GPT-4 Vision across various attributes like OCR capabilities, object detection, etc. Each cell color intensity reflects the performance level (e.g., Strong, Moderate) for a specific attribute of a model. Darker shades indicate robust capabilities, facilitating an at-a-glance understanding of each model's strengths and weaknesses.
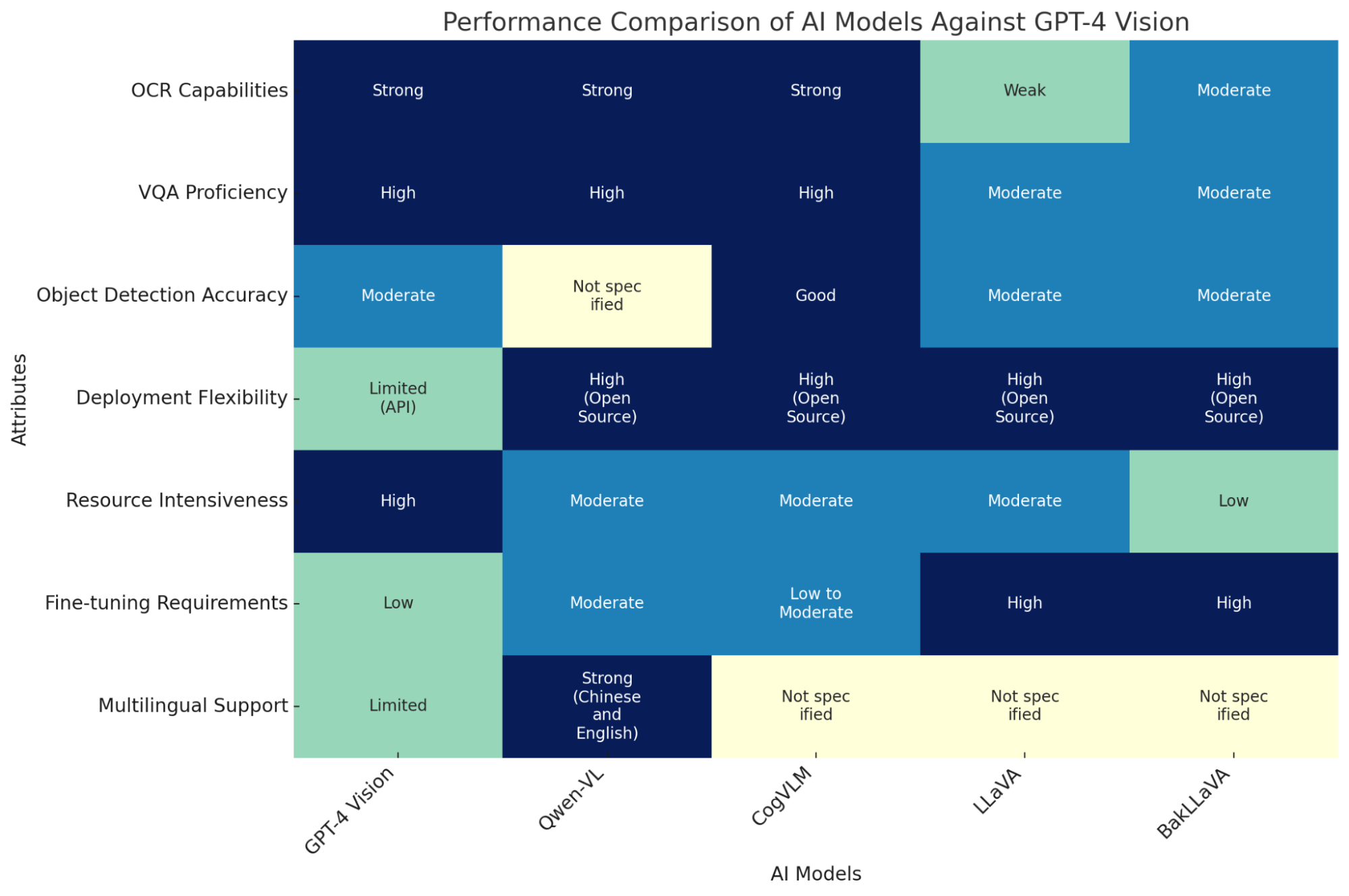
Reliability comparison between open source alternatives and GPT-4V
When comparing GPT-4 Vision with other AI models like Qwen-VL, CogVLM, LLaVA, and BakLLaVA, it's essential to consider their practical applications and limitations in various contexts.
Qwen-VL, developed by Alibaba Cloud, excels in handling images, text, and bounding boxes as inputs and can output text and bounding boxes. It supports English, Chinese, and multilingual conversation, making it useful in scenarios where Chinese and English are used.
Qwen-VL has successfully documented OCR, such as extracting text from web page screenshots and identifying serial numbers on objects like tires. This capability makes it a strong candidate for applications that require precise text extraction from images.
CogVLM is known for its ability to understand and answer a wide range of questions and has a version focused on visual grounding. This model can accurately describe images with minimal errors and is helpful for zero-shot object detection, as it returns coordinates of grounded objects. CogVLM can interpret infographics and documents with structured information, making it suitable for detailed image analysis and interpretation applications.
LLaVA is widely recognized as a reliable alternative to GPT-4 Vision in Visual Question Answering (VQA). While it has some capabilities in zero-shot object detection and OCR, it may need help with more complex scenarios, such as interpreting multiple coins in an image or accurately recognizing text from web page screenshots. LLaVA's strengths lie in its ability to process and analyze images for VQA, but it may need to improve for tasks requiring high precision in text recognition.
BakLLaVA, leveraging a Mistral 7B base with the LLaVA 1.5 architecture, offers a faster and less resource-intensive alternative to GPT-4 Vision. However, it requires more fine-tuning to achieve accurate results. BakLLaVA's strengths include its ability to detect objects and its versatility due to being less resource-intensive. However, it may only sometimes produce reliable results with substantial fine-tuning.
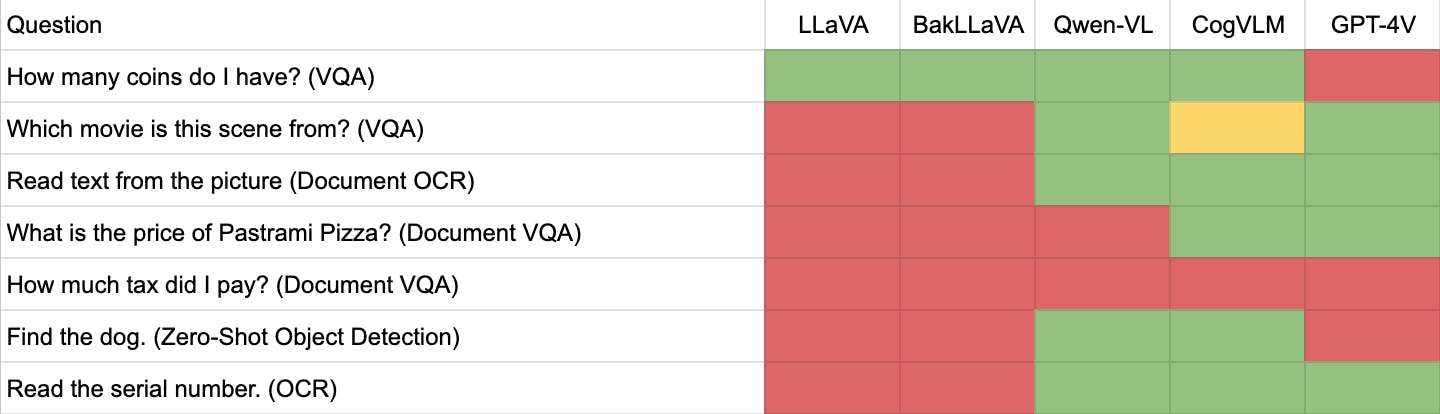
Accuracy comparison between open source alternatives and GPT-4V
Criteria for Choosing the Most Suitable Model
- For multilingual support, especially in Chinese and English, Qwen-VL is a strong option.
- For detailed image descriptions and zero-shot object detection, CogVLM is suitable.
- For applications requiring VQA with moderate complexity, LLaVA can be effective.
- For less resource-intensive tasks with the flexibility for fine-tuning, BakLLaVA is a viable choice.
- For diverse applications, including assistance for visually impaired users, GPT-4 Vision stands out, though its accuracy and limitations should be considered.
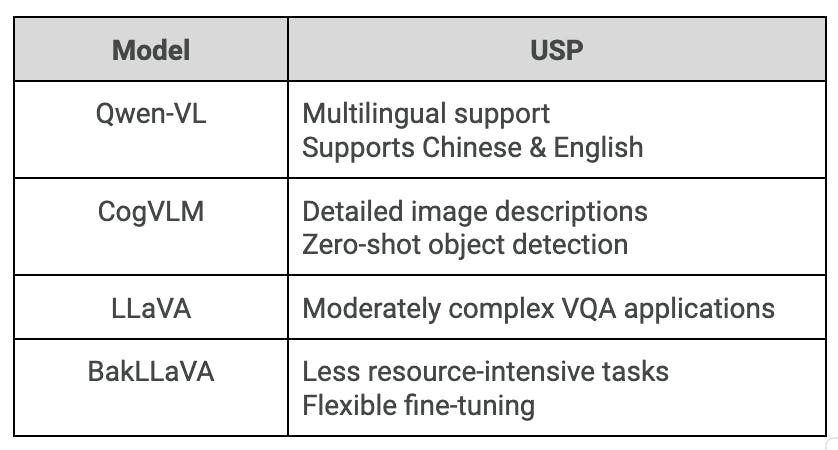
Future Outlook
The choice of multimodal AI model should be based on the specific requirements of the task, such as language support, the need for text extraction accuracy, and the level of detail required in image analysis.
In the context of multimodal models, open-source contributions shape AI's future significantly. These models, which integrate multiple data types such as text, images, and audio, are poised to offer a more nuanced and comprehensive understanding of human cognition.
GPT-4 Vision Alternatives: Key Takeaways
The significance of open-source large multimodal models (LMMs) is highly valuable. These models process diverse data types, including visual and natural language inputs, enhancing AI accuracy and comprehension. Their open-source nature not only enables accessibility and innovation but also promises a more human-like understanding of complex queries.
Adding visual encoders, transformers, and the ability to follow instructions to models like GPT-4 Vision (GPT-4V) and its alternatives shows how multimodal AI could change fields like computer vision and machine learning.
As research in AI continues to incorporate ethical considerations and leverage platforms like Hugging Face for open-source collaborations, the future of Large Multimodal Models (LMMs), including models outperforming existing benchmarks, looks promising.
Frequently asked questions
Large Multimodal Models, like GPT-4 Vision, are AI models capable of processing and understanding multiple data types, such as images and text. They are designed to interpret and respond to complex inputs by integrating AI technologies like computer vision and natural language processing.
Open-source alternatives provide flexibility, customization, and adaptability, crucial for specific applications and technological innovation. They offer broader accessibility to developers and researchers, fostering a diverse technological ecosystem and encouraging continuous improvement and community-driven innovation.
LMMs analyze images to identify objects and their characteristics. In visual question answering, they interpret the content of an image in the context of a question, providing accurate and relevant answers based on both textual and visual inputs.
Closed-source models like GPT-4 Vision often have established data privacy policies and comply with GDPR regulations. However, open-source models can be more transparent in handling data, but ensuring compliance and security might require additional effort.
These models offer unique features like multilingual support, detailed image description, zero-shot object detection, and efficiency in resource usage. Each model has specific strengths, making them suitable for different tasks and applications, whereas GPT-4 vision is a closed-source model generalized over different tasks.
Encord offers a comprehensive solution for managing video data in Advanced Driver Assistance Systems (ADAS) by utilizing a vector database that allows for efficient querying and retrieval of relevant video segments. This capability is essential for addressing long tail scenarios and helps teams visualize and analyze complex driving behaviors more effectively.
Encord provides functionality to identify and analyze edge cases, which are critical for improving the robustness of autonomous driving models. This includes detecting challenging scenarios such as urban environments or varying weather conditions, ensuring that models trained in one setting can perform effectively in diverse real-world situations.
Yes, Encord’s platform is designed to support deployment across heterogeneous device environments, ensuring that computer vision solutions can be implemented seamlessly on various devices, including iOS. This flexibility allows organizations to adapt to different field conditions and operational requirements.
Yes, Encord's platform is designed to support the integration of multiple sensor data types, including thermal cameras and LIDAR. This capability allows developers to create robust detection systems that leverage diverse data inputs for improved accuracy in object detection and distance measurement.
Encord provides a unified platform that allows users to annotate both images and LiDAR data seamlessly. This integration simplifies workflows by enabling the combination of various sensor data types, making it easier to handle complex use cases in machine learning and perception tasks.
Absolutely. Encord is focused on providing an easy-to-use system that empowers non-technical users to work effectively with lidar data. The platform's intuitive interface simplifies the annotation process, making it accessible for users who may not have a deep technical background.
Encord provides support for integrating with Google Cloud Platform (GCP) environments, ensuring that users can access their projects and utilize features like video playback directly from GCP. Guidance is available for setting up access and managing project data.
Yes, Encord supports Lidar annotation. The platform helps consolidate fragmented annotation processes by providing a unified solution for both image and Lidar data, allowing teams to streamline their workflows and manage their annotation needs in one place.
Yes, Encord can facilitate real-time data processing by allowing users to annotate and prepare data for models that operate on edge devices, leveraging GPU capabilities for tasks such as detection and classification.