Improving Data Quality Using End-to-End Data Pre-Processing Techniques in Encord Active

In computer vision, you cannot overstate the importance of data quality. It directly affects how accurate and reliable your models are.
This guide is about understanding why high-quality data matters in computer vision and how to improve your data quality. We will explore the essential aspects of data quality and its role in model accuracy and reliability. We will discuss the key steps for improving quality, from selecting the right data to detecting outliers.
We will also see how Encord Active helps us do all this to improve our computer vision models. This is an in-depth guide; feel free to use the table of contents on the left to navigate each section and find one that interests you.
By the end, you’ll have a solid understanding of the essence of data quality for computer vision projects and how to improve it to produce high-quality models.
Let’s dive right into it!
Introduction to Data Quality in Computer Vision
Defining the Attributes of High-Quality Data
High-quality data includes several attributes that collectively strengthen the robustness of computer vision models:
- Accuracy: Precision in reflecting real-world objects is vital; inaccuracies can lead to biases and diminished performance.
- Consistency: Uniformity in data, achieved through standardization, prevents conflicts and aids effective generalization.
- Data Diversity: By incorporating diverse data, such as different perspectives, lighting conditions, and backgrounds, you enhance the model's adaptability, making it resilient to potential biases and more adept at handling unforeseen challenges.
- Relevance: Data curation should filter irrelevant data, ensuring the model focuses on features relevant to its goals.
- Ethical Considerations: Data collected and labeled ethically, without biases, contributes to responsible and fair computer vision models.
By prioritizing these data attributes, you can establish a strong foundation for collecting and preparing quality data for your computer vision projects.
Next, let's discuss the impact of these attributes on model performance.
Impact of Data Quality on Model Performance
Here are a few aspects of high-quality data that impact the model's performance:
- Accuracy Improvement: Curated and relevant datasets could significantly improve model accuracy.
- Generalization Capabilities: High-quality data enables models to apply learned knowledge to new, unseen scenarios.
- Increased Model Robustness: Robust models are resilient to variations in input conditions, which is perfect for production applications.
As we explore enhancing data quality for training computer vision models, it's essential to underscore that investing in data quality goes beyond mere accuracy. It's about constructing a robust and dependable system.
By prioritizing clean, complete, diverse, and representative data, you establish the foundation for effective models.
Considerations for Training Computer Vision Models
Training a robust computer vision model hinges significantly on the training data's quality, quantity, and labeling. Here, we explore the key considerations for training CV models:
Data Quality
The foundation of a robust computer vision model rests on the quality of its training data. Data quality encompasses the accuracy, completeness, reliability, and relevance of the information within the dataset. Addressing missing values, outliers, and noise is crucial to ensuring the data accurately reflects real-world scenarios. Ethical considerations, like unbiased representation, are also paramount in curating a high-quality dataset.
Data Diversity
Data diversity ensures that the model encounters many scenarios. Without diversity, models risk being overly specialized and may struggle to perform effectively in new or varied environments. By ensuring a diverse dataset, models can better generalize and accurately interpret real-world situations, improving their robustness and reliability.
Data Quantity
While quality takes precedence, an adequate volume of data is equally vital for comprehensive model training. Sufficient data quantity contributes to the model's ability to learn patterns, generalize effectively, and adapt to diverse situations. The balance of quality and quantity ensures a holistic learning experience for the model, enabling it to navigate various scenarios.
It's also important to balance the volume of data with the model's capacity and computational efficiency to avoid issues like overfitting and unnecessary computational load.
Label Quality
The quality of its labels greatly influences the precision of a computer vision model. Consistent and accurate labeling with sophisticated annotation tools is essential for effective training. Poorly labeled data can lead to biases and inaccuracies, undermining the model's predictive capabilities.
Data Curation and Management Tool
A robust data curation and management tool is crucial for maintaining high-quality datasets. These tools support the organization, cleaning, and integration of data, enhancing its overall reliability. By offering intuitive interfaces, efficient data workflows, and comprehensive management options, these tools simplify the process of refining and maintaining valuable datasets.
Well-curated data ensures that the model is trained on clean, relevant, and well-organized datasets, greatly enhancing its learning process and overall performance.
Data Annotation Tool
A reliable data annotation tool is equally essential to ensuring high-quality data. These tools facilitate the labeling of images, improving the quality of the data. By providing a user-friendly interface, efficient workflows, and diverse annotation options, these tools streamline the process of adding valuable insights to the data.
Properly annotated data ensures the model receives accurate ground truth labels, significantly contributing to its learning process and overall performance.
Selecting the Right Data for Your Computer Vision Projects
The first step in improving data quality is data curation.
Data Curation is the process that involves defining criteria for data quality and establishing mechanisms for sourcing reliable datasets. Here are a few key steps to follow when selecting the data for your computer vision project:
Criteria for Selecting Quality Data
The key criteria for selecting high-quality data include:
- Accuracy: Data should precisely reflect real-world scenarios to avoid biases and inaccuracies.
- Completeness: Comprehensive datasets covering diverse situations are crucial for generalization.
- Consistency: Uniformity in data format and preprocessing ensures reliable model performance.
- Timeliness: Regular updates maintain relevance, especially in dynamic or evolving environments.
Evaluating and Sourcing Reliable Data
The process of evaluating and selecting reliable data involves:
- Quality Metrics: Validating data integrity through comprehensive quality metrics, ensuring accuracy, completeness, and consistency in the dataset.
- Ethical Considerations: Ensuring data is collected and labeled ethically without introducing biases.
- Source Reliability: Assessing and selecting trustworthy data sources to mitigate potential biases.
Case Studies: Improving Data Quality Improved Model Performance by 20%
When faced with challenges managing and converting vast amounts of images into labeled training data, Automotus turned to Encord. The flexible ontology structure, quality control capabilities, and automated labeling features of Encord were instrumental in overcoming labeling obstacles. The result was twofold: improved model performance and economic efficiency.
With Encord, Autonomous efficiently curated and reduced the dataset by getting rid of data that was not useful. This led to a 20% improvement in mAP (mean Average Precision), a key metric for measuring the accuracy of object detection models.
This was not only effective in addressing the accuracy of the model but also in reducing labeling costs. Efficient data curation helped prioritize which data to label, resulting in a 33% reduction in labeling costs. Thus, improving the accuracy of the models enhanced the quality of the data that Autonomous delivered to its customers.
Exploring Data Curation and Management using Encord
Encord is designed to streamline data curation and management for machine learning and AI applications. It offers a range of features that help organizations effectively manage their datasets, ensuring data quality and integrity throughout the machine learning lifecycle.
Key Features
- Data Versioning: Encord Index tracks different versions of your datasets, allowing you to monitor changes and compare data distributions over time. This feature helps in identifying data drift and ensures that your models are trained on the most current and relevant data.
- Quality Assurance: Encord Index includes robust quality assurance tools that detect and rectify data quality issues. By identifying labeling errors, missing values, and inconsistencies, it ensures that your datasets are of the highest quality, which is critical for training accurate models.
- Metadata Management: Effective metadata management is crucial for organizing and retrieving datasets. Encord Index allows you to create and manage metadata, making it easier to search, filter, and understand your data.
- Visualization and Analysis: The platform provides powerful visualization tools that help you analyze your data, identify patterns, and make informed decisions. Visualizing data distributions and anomalies can significantly enhance the data curation process.

Following data curation, the next step involves inspecting the quality of the data. Let's learn how to explore data quality with Encord Active.
Exploring Data Quality using Encord
Encord provides a comprehensive set of tools to curate, maintain, evaluate, and improve the quality of your data. It uses quality metrics to assess the quality of your data, labels, and model predictions.
Data Quality Metrics analyzes your images, sequences, or videos. These metrics are label-agnostic and depend only on the image content. Examples include image uniqueness, diversity, area, brightness, sharpness, etc.
Label Quality Metrics operates on image labels like bounding boxes, polygons, and polylines. These metrics can help you sort data, filter it, find duplicate labels, and understand the quality of your annotations. Examples include border proximity, broken object tracks, classification quality, label duplicates, object classification quality, etc.
In addition to the metrics that ship with Encord Active, you can define custom quality metrics for indexing your data. This allows you to customize the evaluation of your data according to your specific needs.
Here's a step-by-step guide to exploring data quality through Encord Active:
Create an Encord Project
Initiating your journey with Encord begins with creating a project in Index and then Annotate, setting the foundation for an efficient and streamlined data annotation process. Follow these steps for a curation workflow from Index to Annotate to Active:
- Create a Project in Index.
- Add an existing dataset or create your own dataset.
- To label the curated dataset, create a project in Annotate.
- Set up the ontology of the annotation project.
- Customize the workflow design to assign tasks to annotators and for expert review.
- Start the annotation process!
Import Encord Active Project
Once you label a project in Annotate, transition to Active by clicking Import Annotate Project.
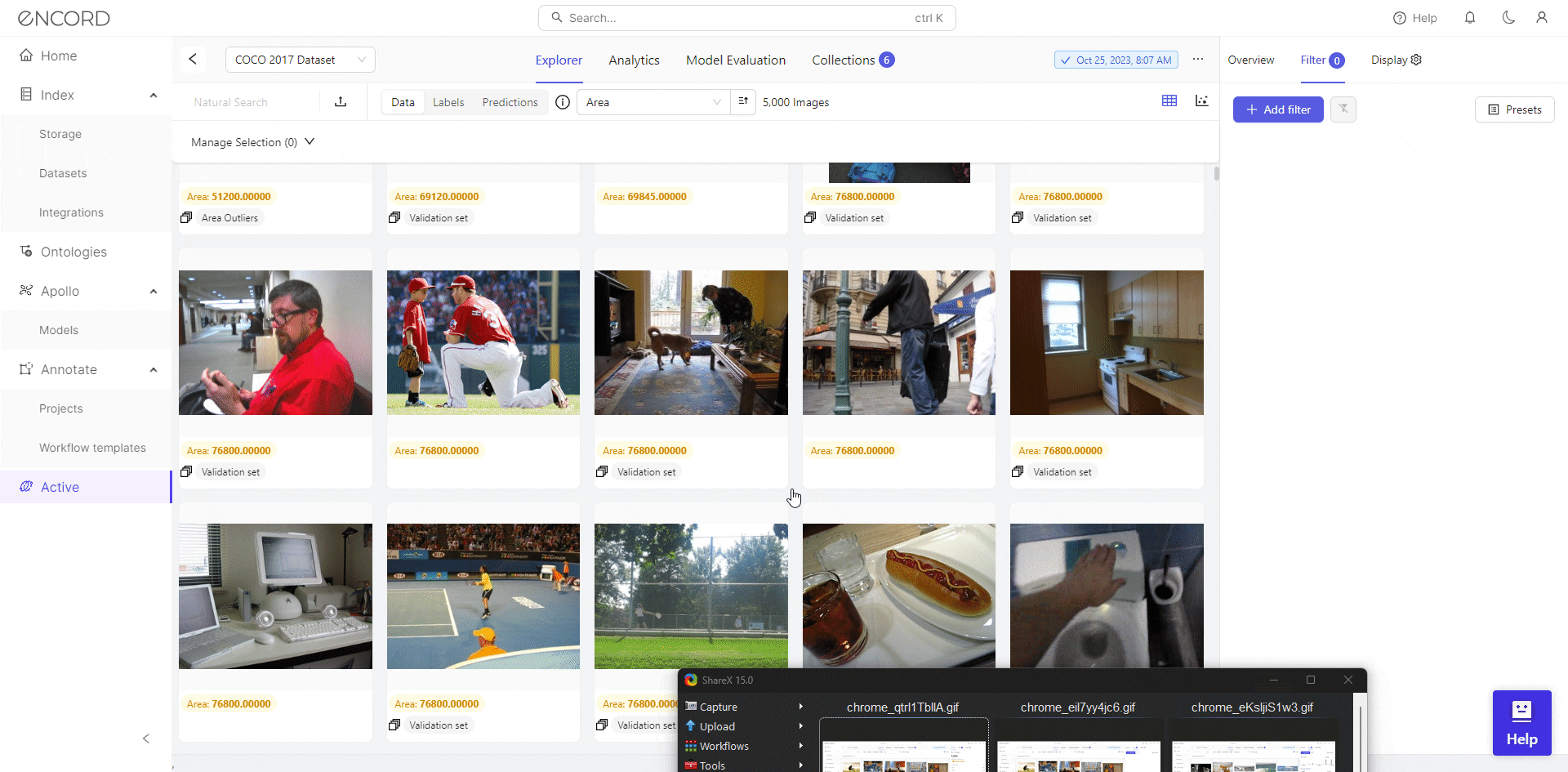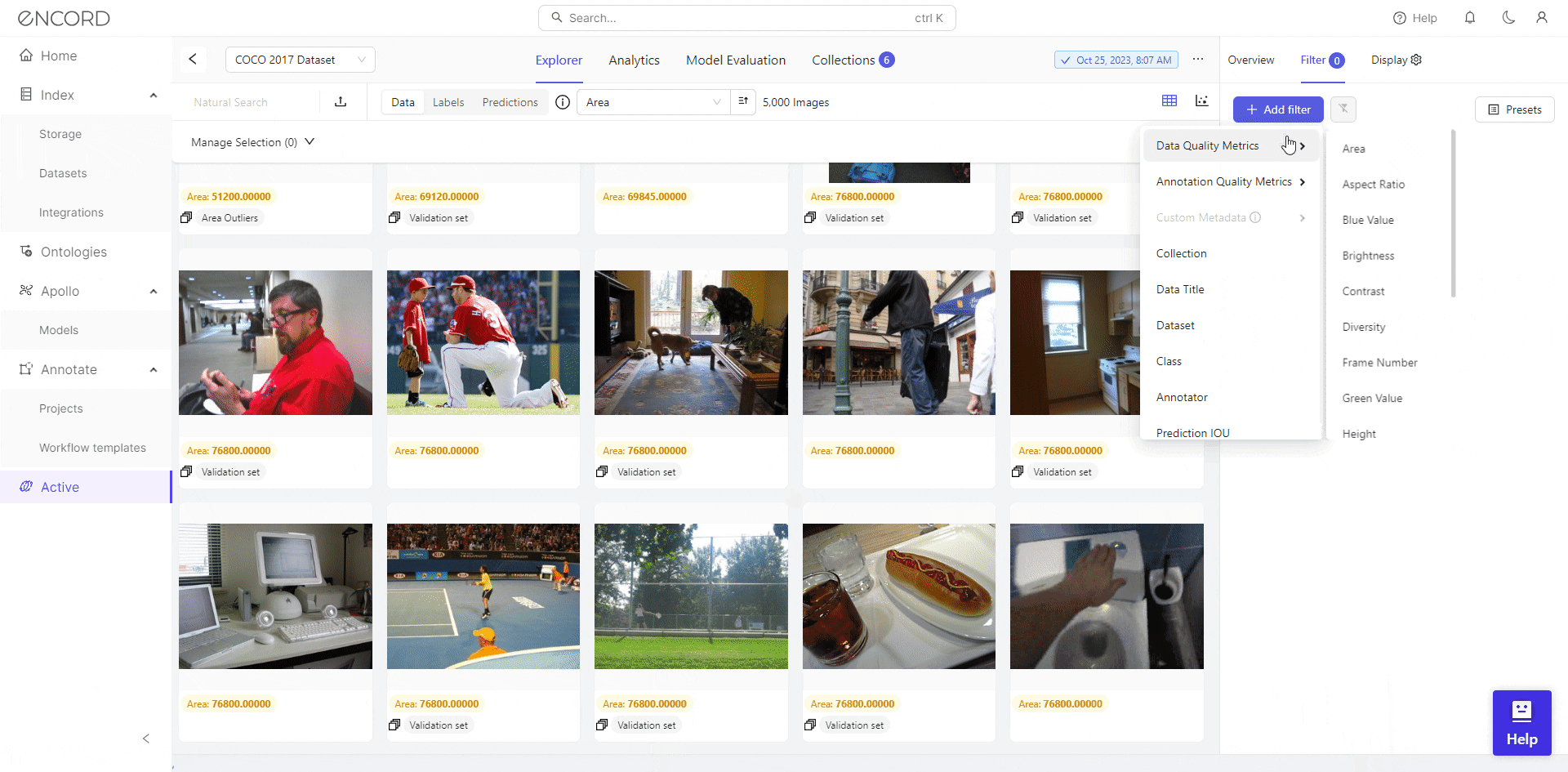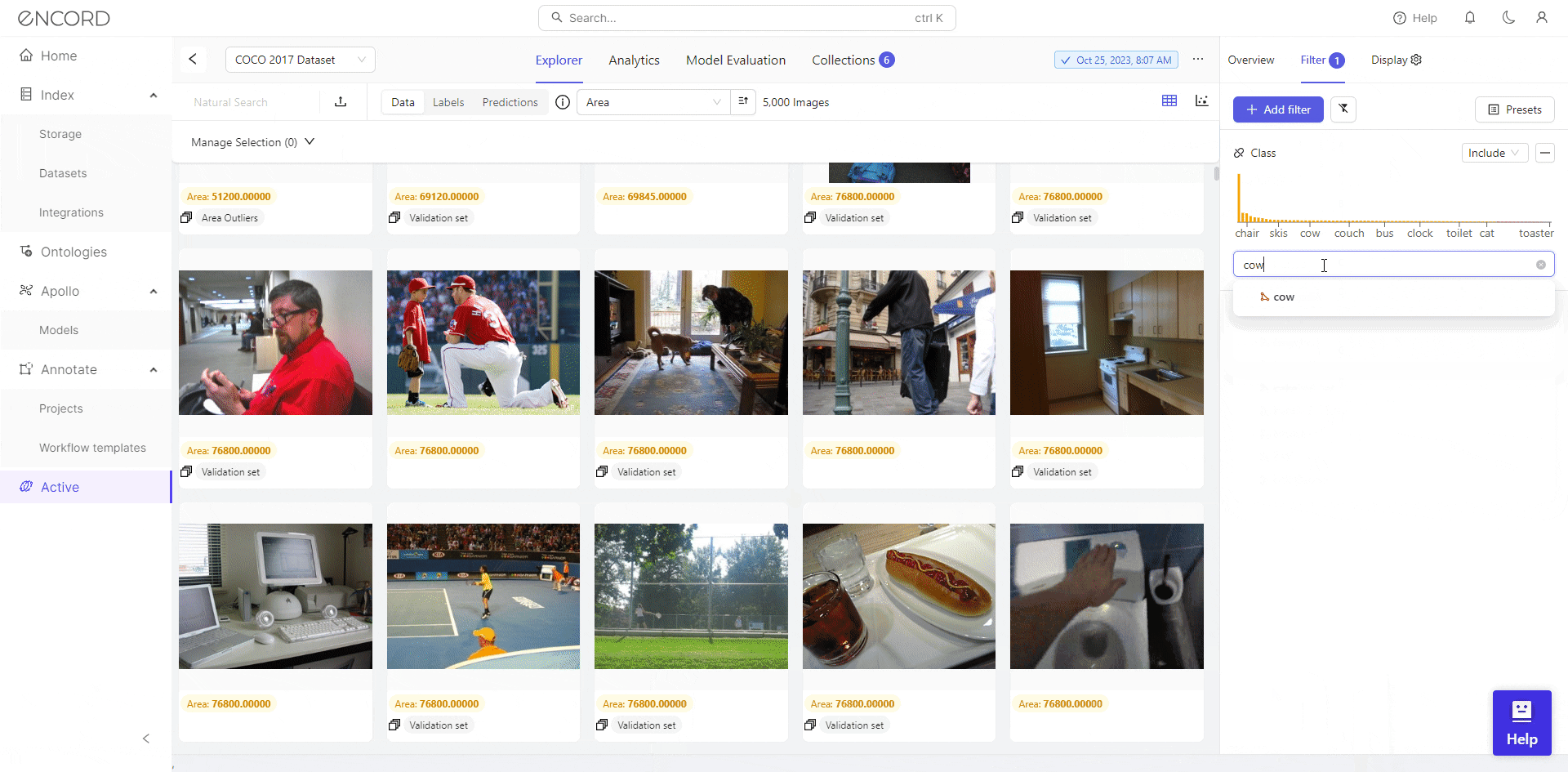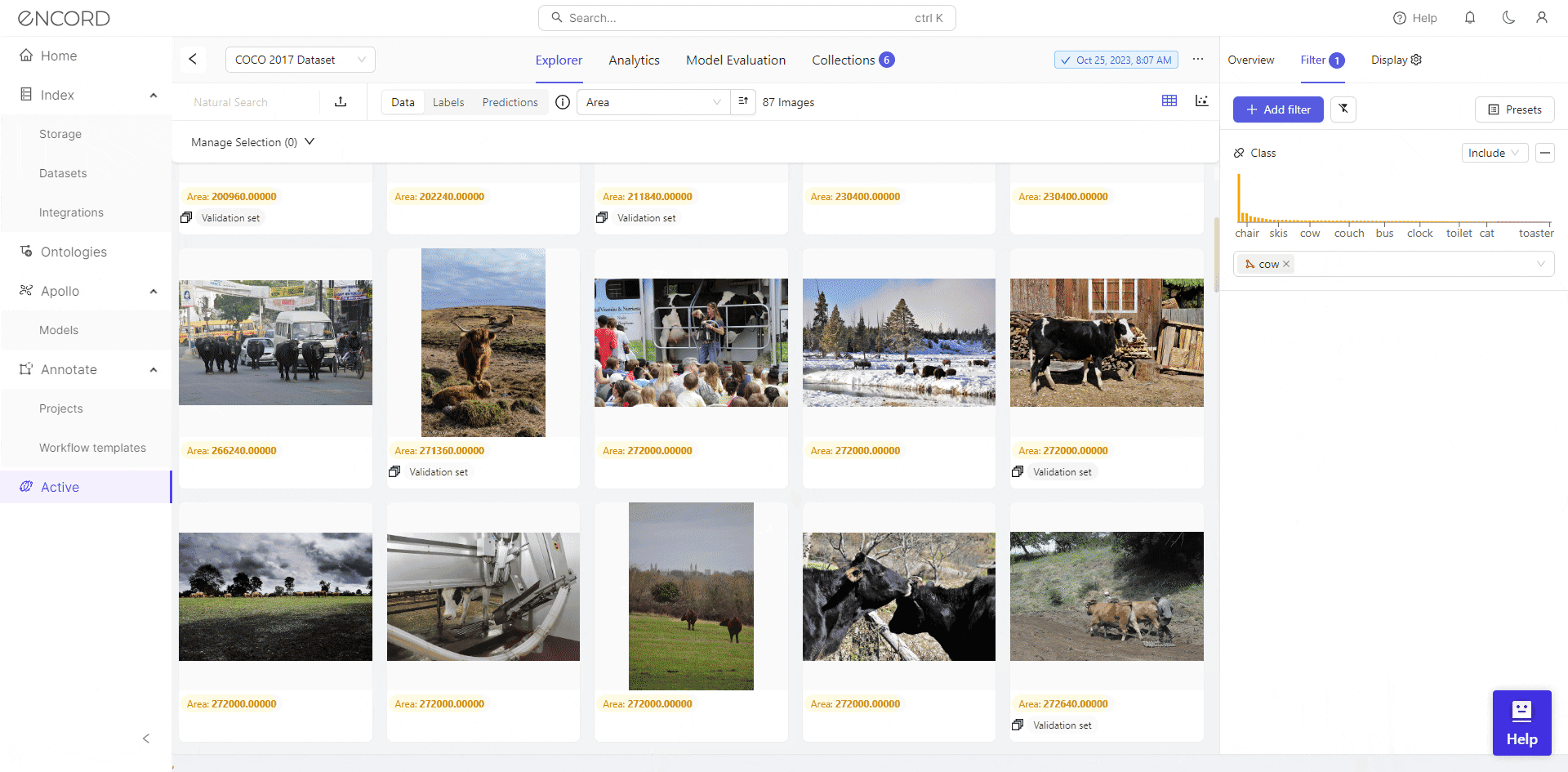
Using Quality Metrics
After choosing your project, navigate to Filter on the Explorer page >> Choose a Metric from the selection of data quality metrics to visually analyze the quality of your dataset.
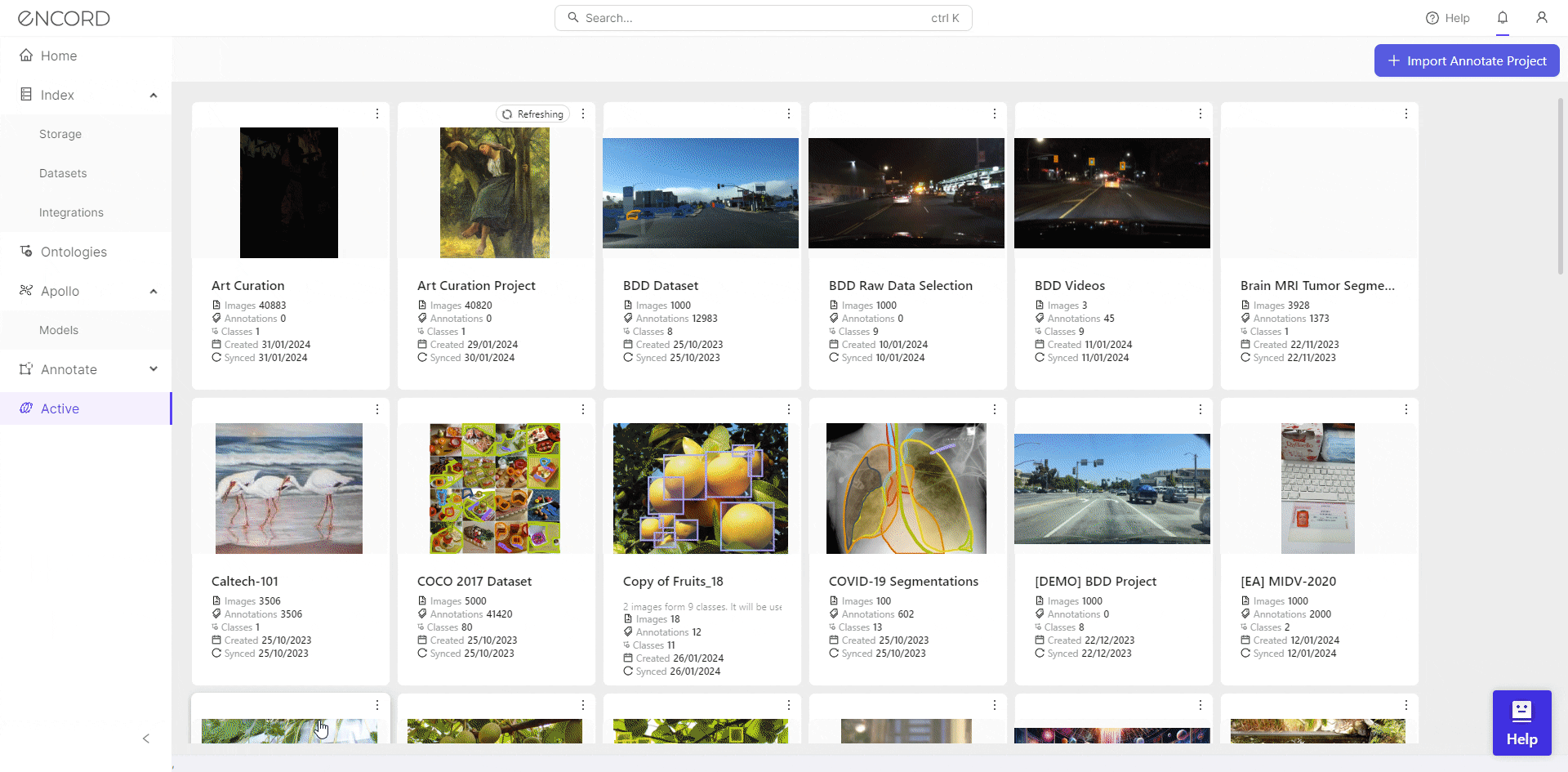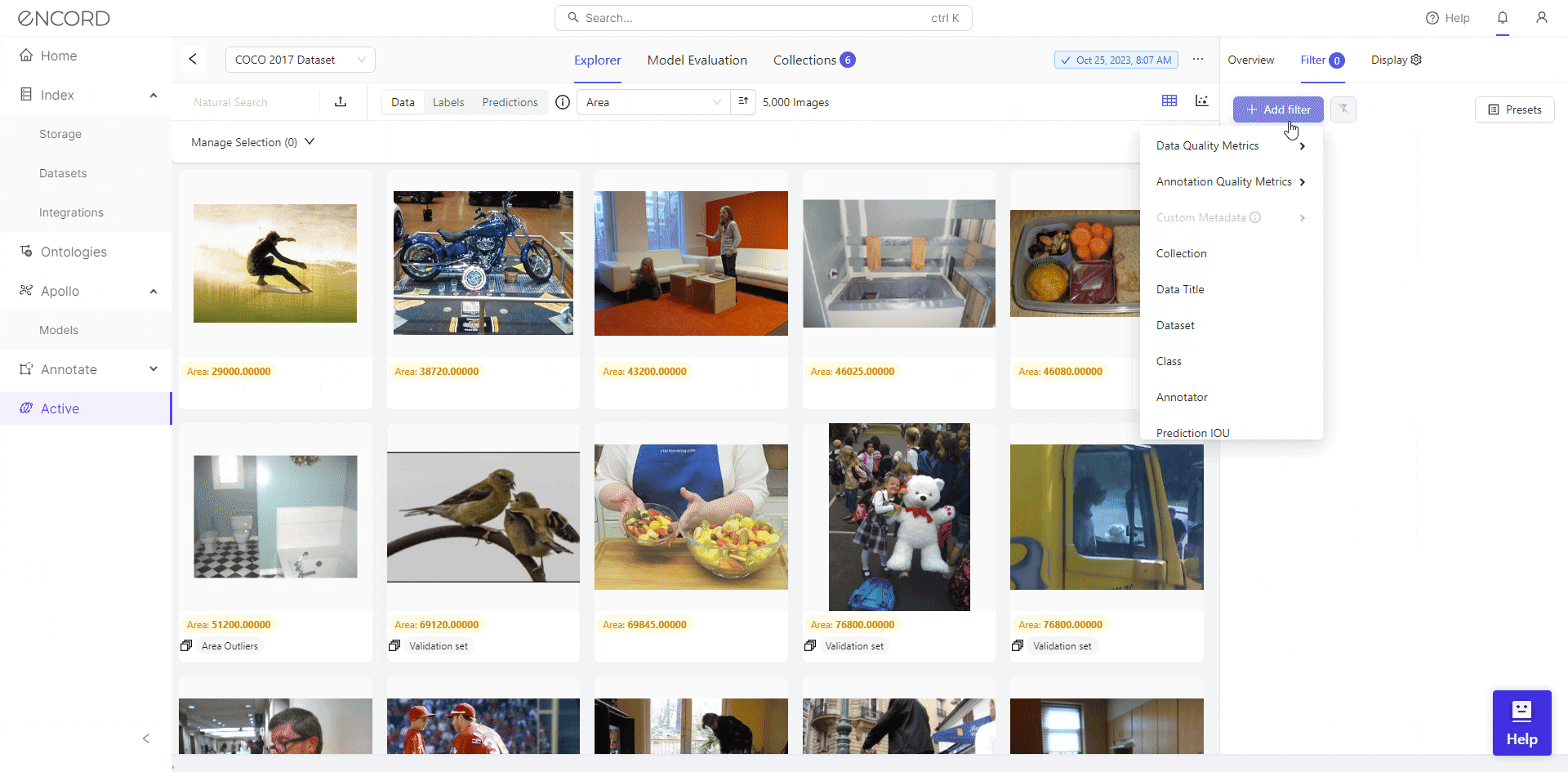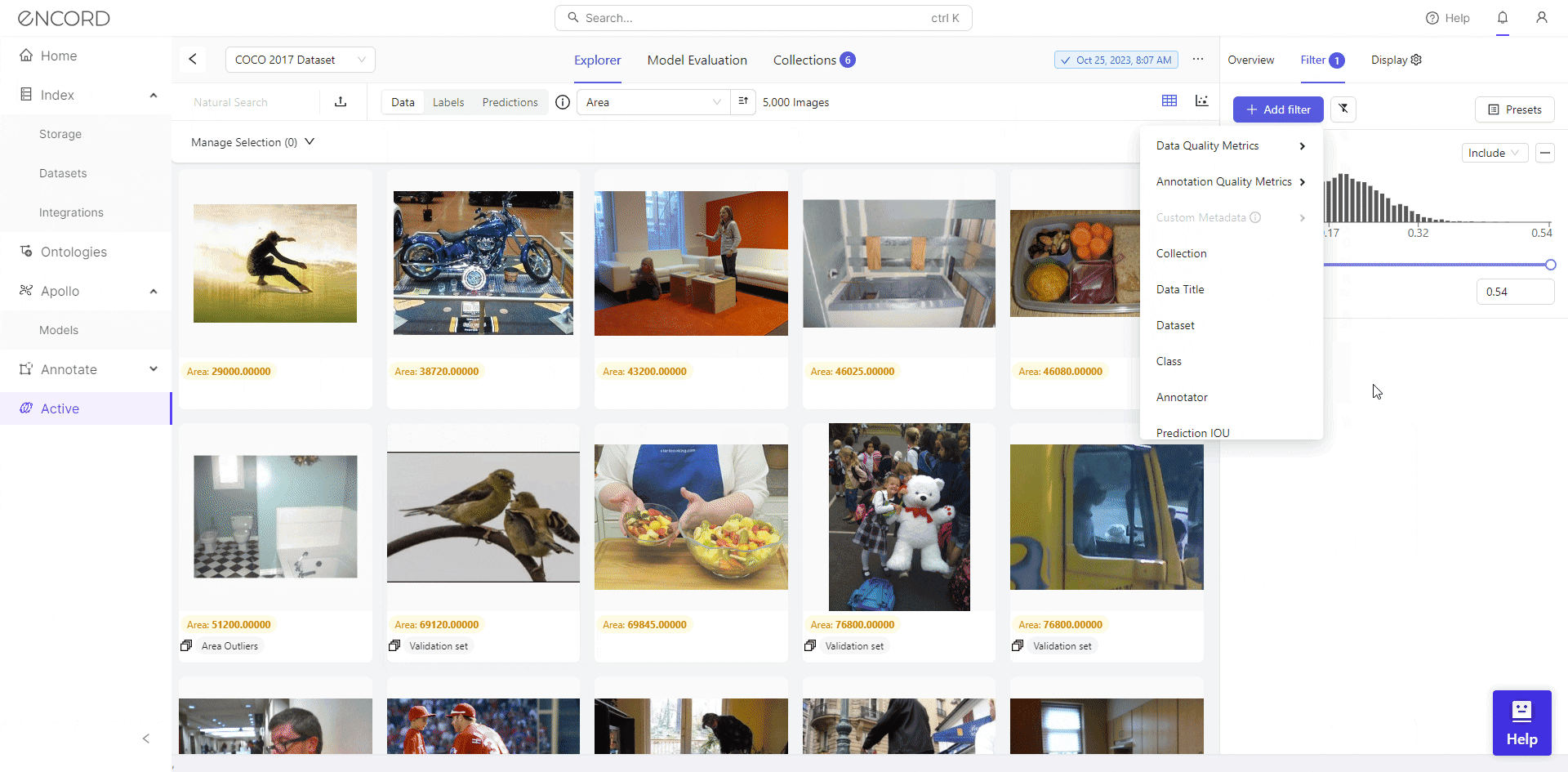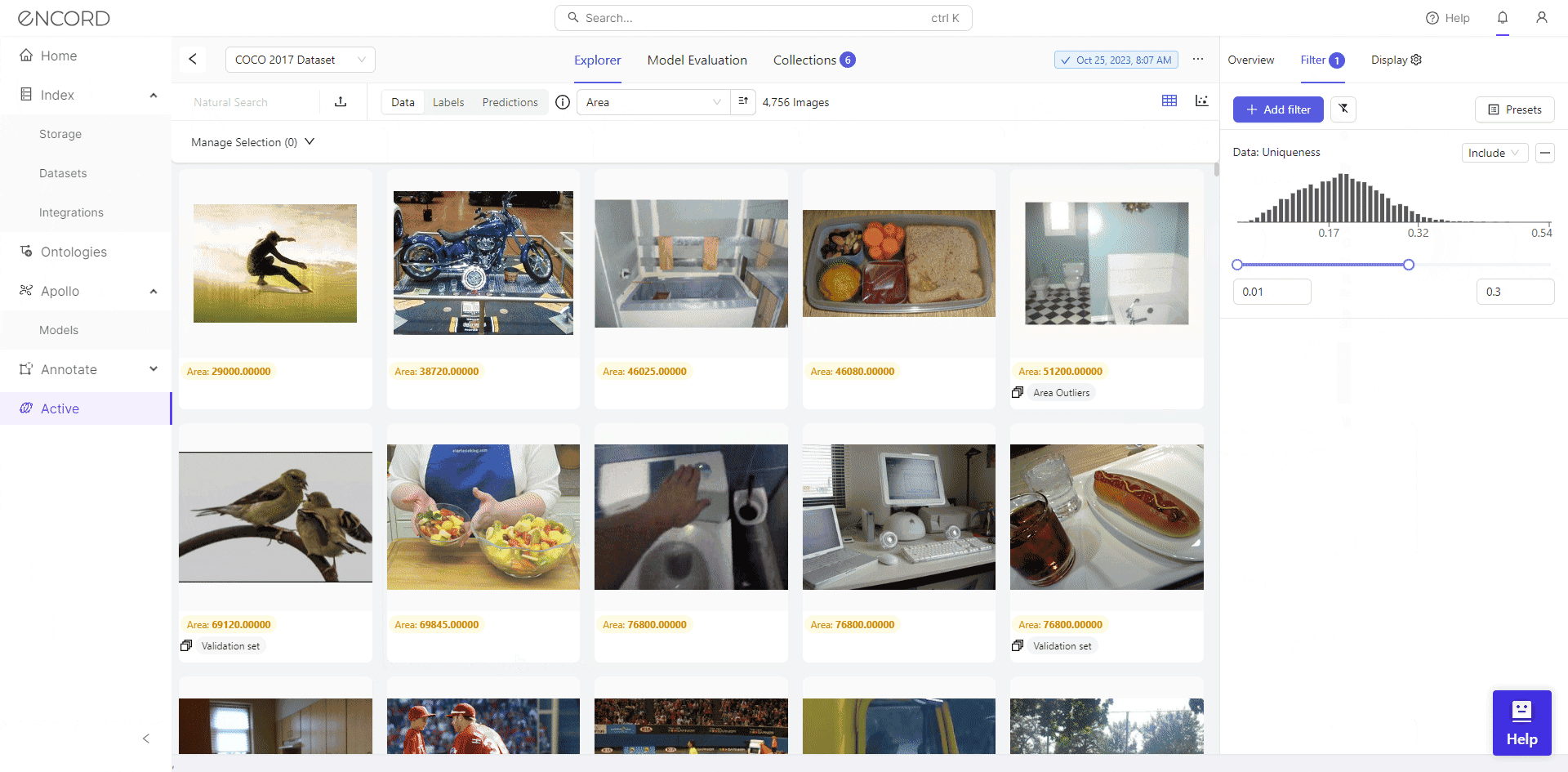
Great! That helps you identify potential issues such as inconsistencies, outliers, etc., which helps make informed decisions regarding data cleaning.
Guide to Data Cleaning
Data cleaning involves identifying and rectifying errors, inconsistencies, and inaccuracies in datasets. This critical phase ensures that the data used for computer vision projects is reliable, accurate, and conducive to optimal model performance.
Understanding Data Cleaning and Its Benefits
Data cleaning involves identifying and rectifying data errors, inconsistencies, and inaccuracies. The benefits include:
- Improved Data Accuracy: By eliminating errors and inconsistencies, data cleaning ensures that the dataset accurately represents real-world phenomena, leading to more reliable model outcomes.
- Increased Confidence in Model Results: A cleaned dataset instills confidence in the reliability of model predictions and outputs.
- Better Decision-Making Based on Reliable Data: Organizations can make better-informed decisions to build more reliable AI.
Selecting the right tool is essential for data cleaning tasks. In the next section, you will see criteria for selecting data cleaning tools to automate repetitive tasks and ensure thorough and efficient data cleansing.
Selecting a Data Cleaning Tool
Some criteria for selecting the right tools for data cleaning involve considering the following:
- Diversity in Functionality: Assess whether the tool specializes in handling specific data issues such as missing values or outlier detections. Understanding the strengths and weaknesses of each tool enables you to align them with the specific requirements of their datasets.
- Scalability and Performance: Analyzing the performance of tools in terms of processing speed and resource utilization helps in selecting tools that can handle the scale of the data at hand efficiently.
- User-Interface and Accessibility: Tools with intuitive interfaces and clear documentation streamline the process, reducing the learning curve.
- Compatibility and Integration: Compatibility with existing data processing pipelines and integration capabilities with popular programming languages and platforms are crucial. Seamless integration ensures a smooth workflow, minimizing disruptions during the data cleaning process.
Once a suitable data cleaning tool is selected, understanding and implementing best practices for effective data cleaning becomes imperative. These practices ensure you can optimally leverage the tool you choose to achieve desired outcomes.
Best Practices for Effective Data Cleaning
Adhering to best practices is essential for ensuring the success of the data cleaning process. Some key practices include:
- Data Profiling: Understand the characteristics and structure of the data before initiating the cleaning process.
- Remove Duplicate and Irrelevant Data: Identify and eliminate duplicate or irrelevant images/videos to ensure data consistency and improve model training efficiency.
- Anomaly Detection: Utilize anomaly detection techniques to identify outliers or anomalies in image/video data, which may indicate data collection or processing errors.
- Documentation: Maintain detailed documentation of the cleaning process, including the steps taken and the rationale behind each decision.
- Iterative Process: Treat data cleaning as an iterative process, revisiting and refining as needed to achieve the desired data quality.
Overcoming Challenges in Image and Video Data Cleaning
Cleaning image and video data presents unique challenges compared to tabular data. Issues such as noise, artifacts, and varying resolutions require specialized techniques. These challenges need to be addressed using specialized tools and methodologies to ensure the accuracy and reliability of the analyses.
- Visual Inspection Tools: Visual data often contains artifacts, noise, and anomalies that may not be immediately apparent in raw datasets. Utilizing tools that enable visual inspection is essential. Platforms allowing users to view images or video frames alongside metadata provide a holistic understanding of the data.
- Metric-Based Cleaning: Implementing quantitative metrics is equally vital for effective data cleaning. You can use metrics such as image sharpness, color distribution, blur, changing your image backdrop, and object recognition accuracy to identify and address issues. Tools that integrate these metrics into the cleaning process automate the identification of outliers and abnormalities, facilitating a more objective approach to data cleaning.
Using tools and libraries streamlines the cleaning process and contributes to improved insights and decision-making based on high-quality visual data.
Using Encord Active to Clean the Data
Let’s take an example of the COCO 2017 dataset imported to Encord Active.
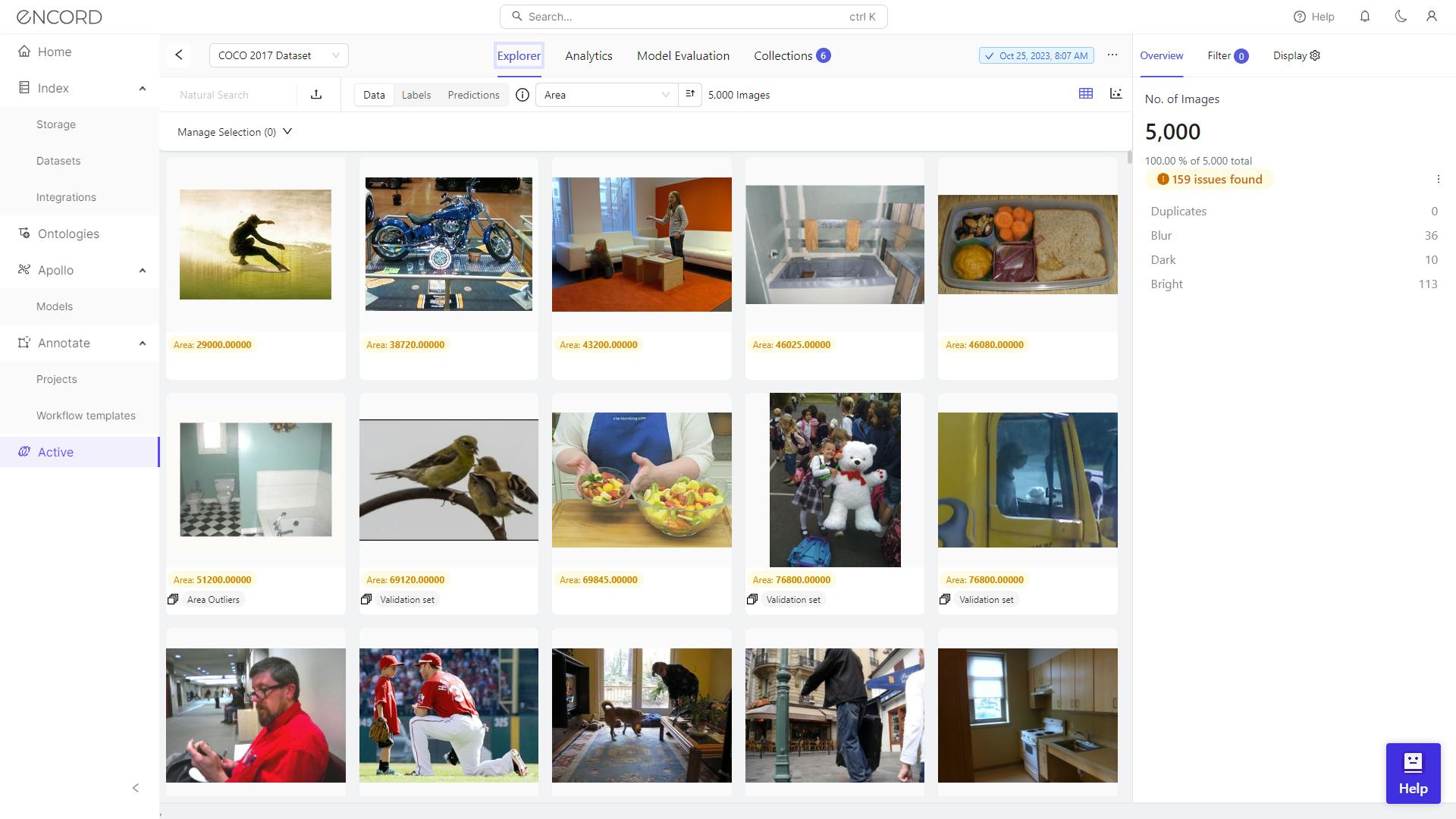
Upon analyzing the dataset, Encord Active highlights both severe and moderate outliers. While outliers bear significance, maintaining a balance is crucial.
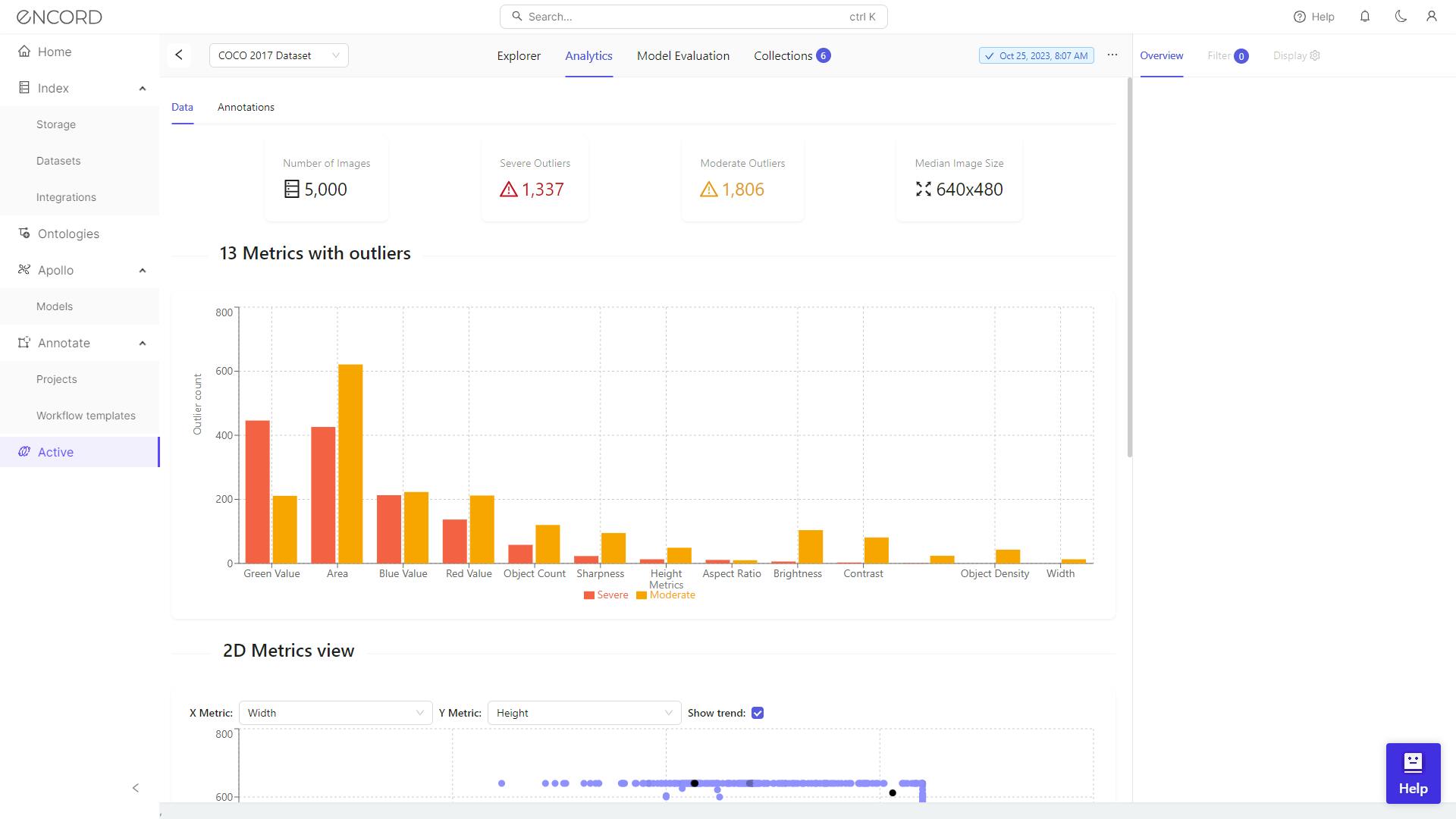
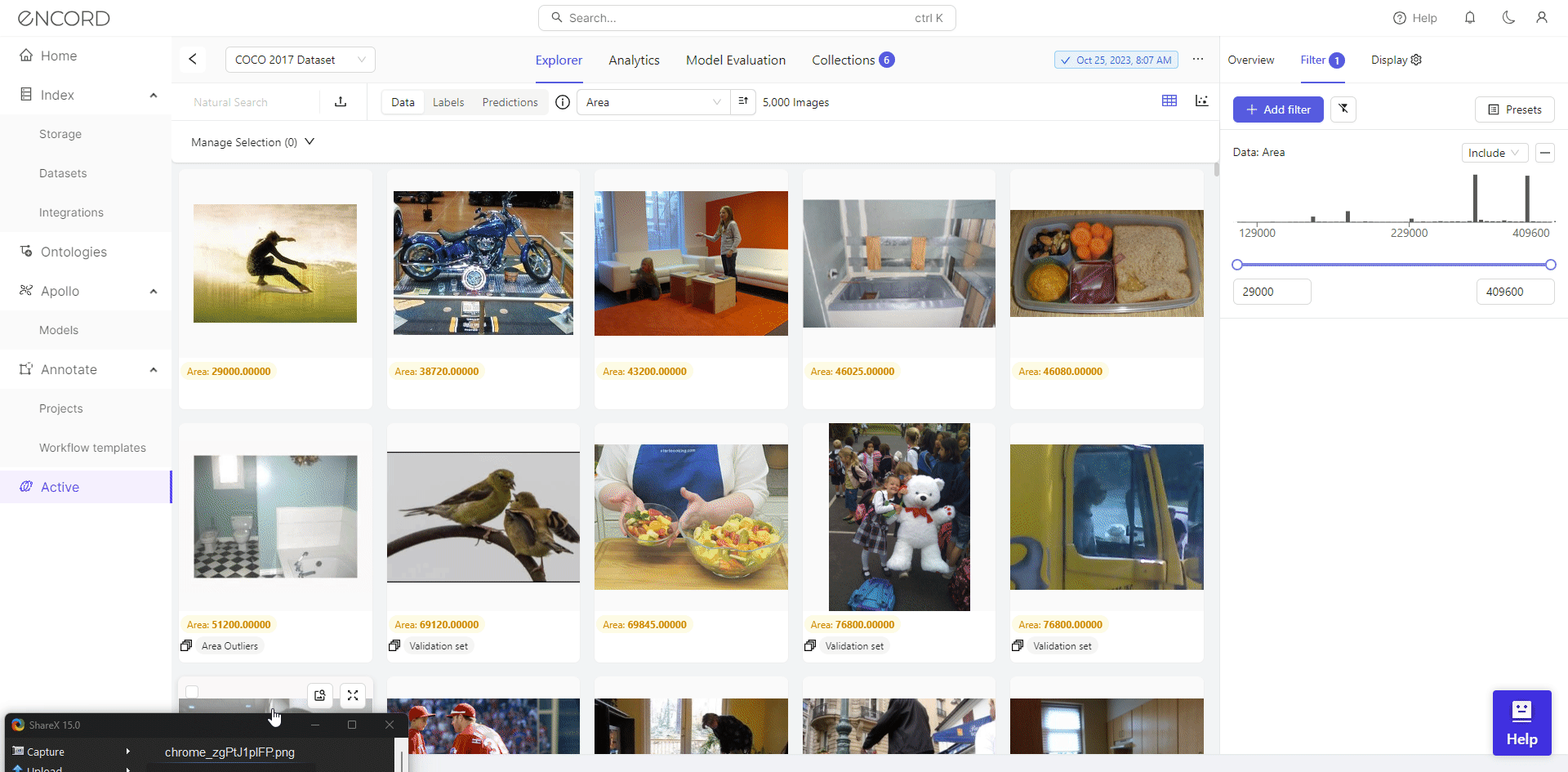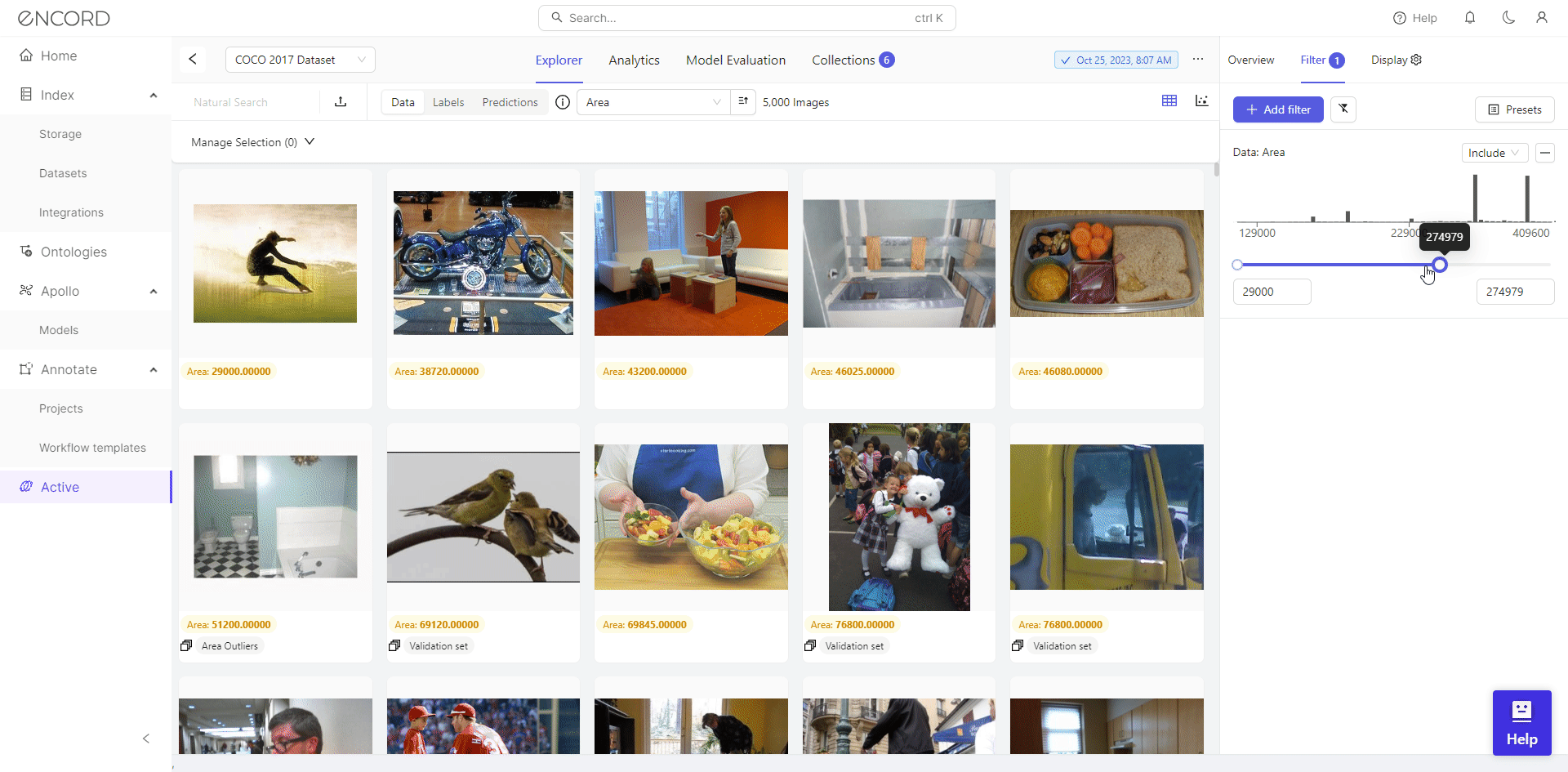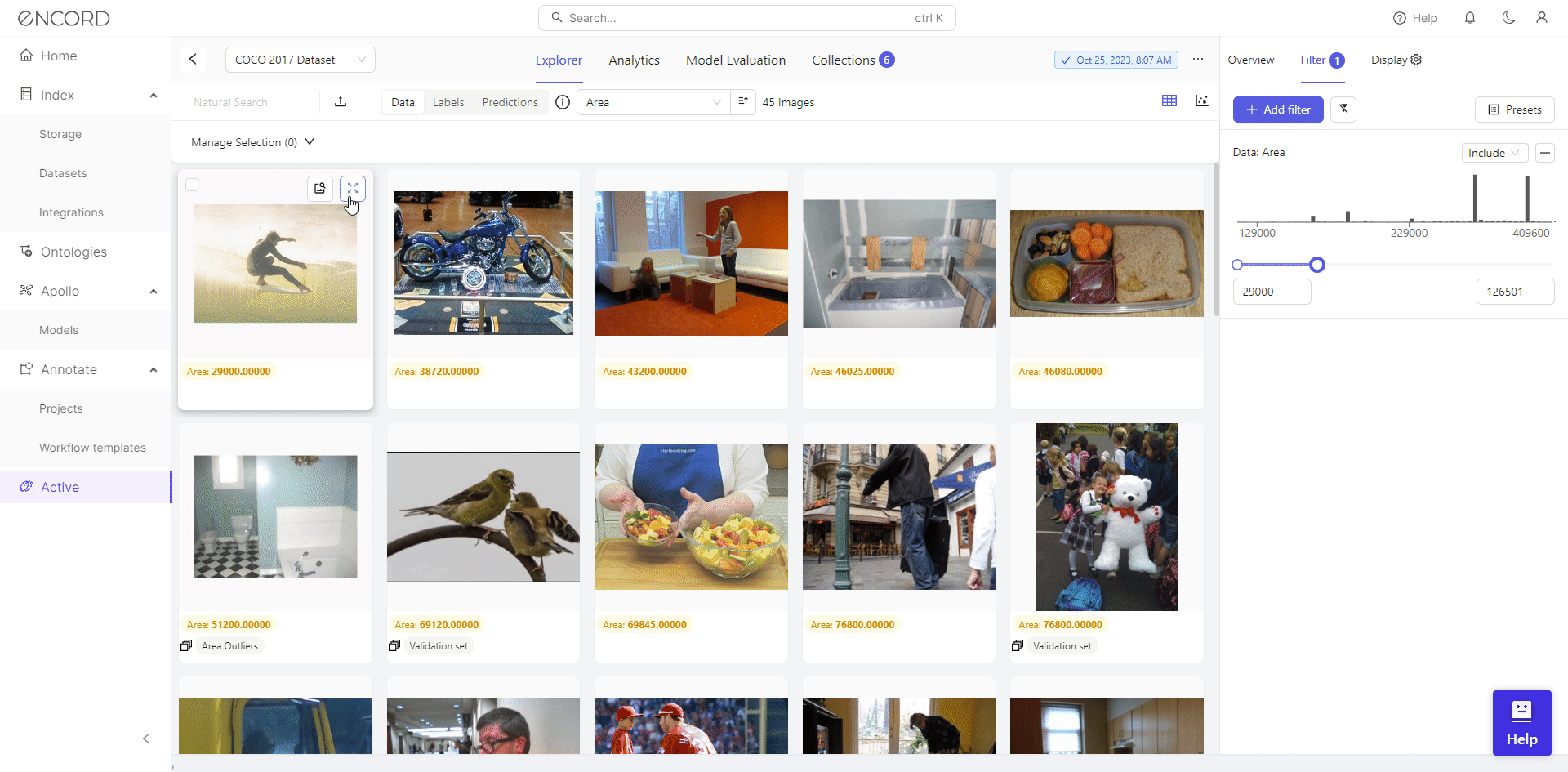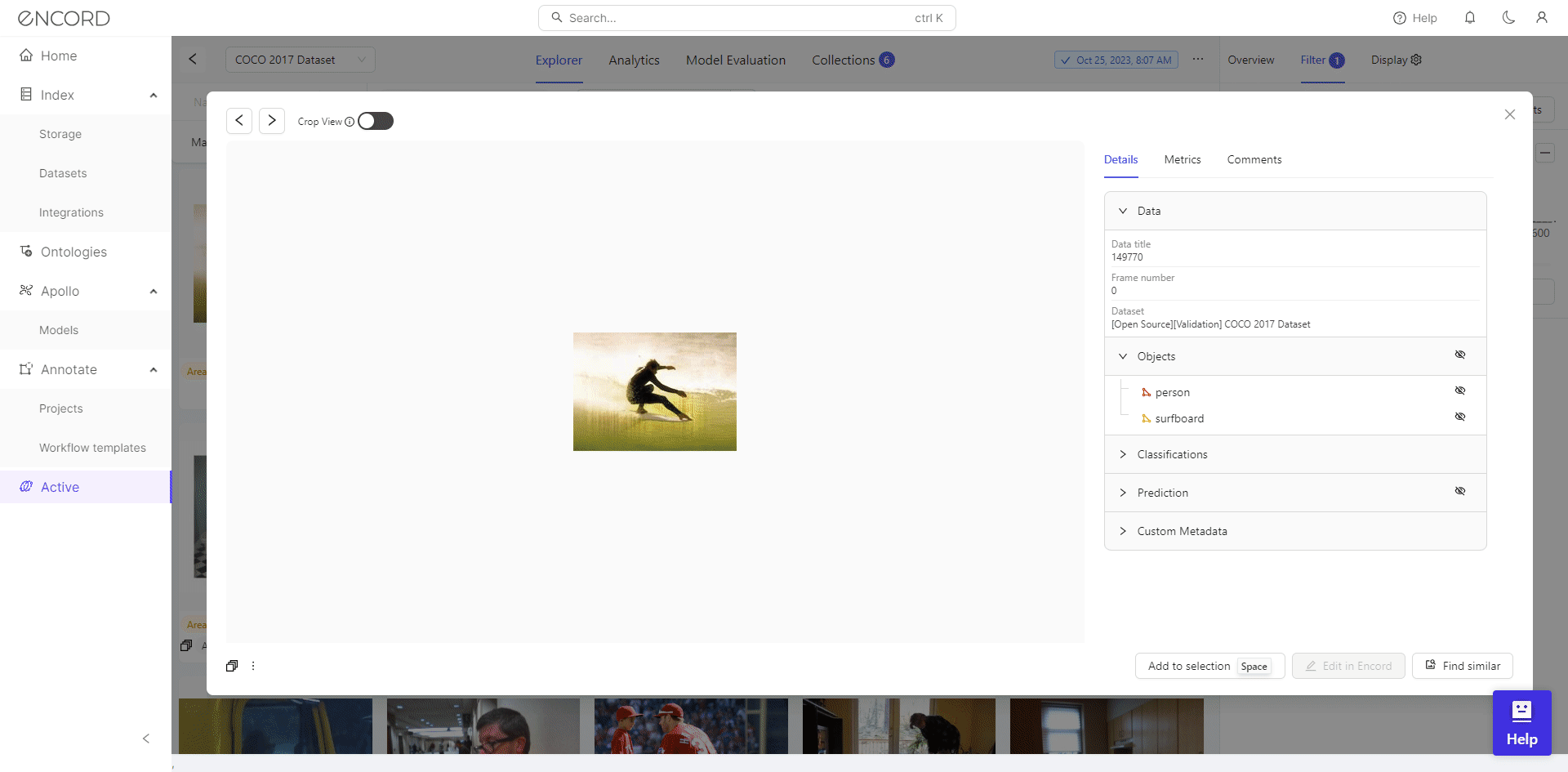
Using Filter, Encord Active empowers users to visually inspect outliers and make informed decisions regarding their inclusion in the dataset. Taking the Area metric as an example, it reveals numerous severe outliers.
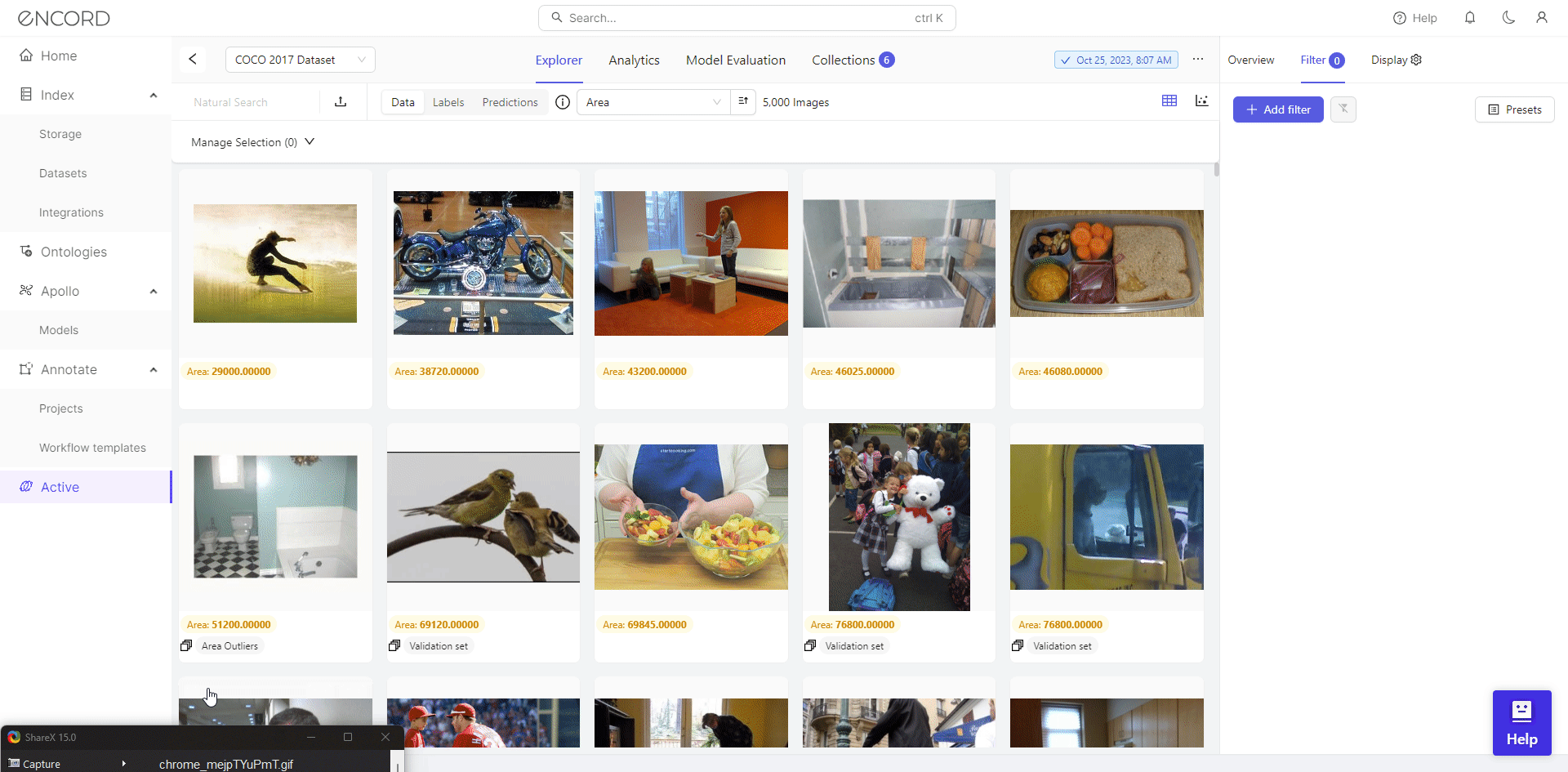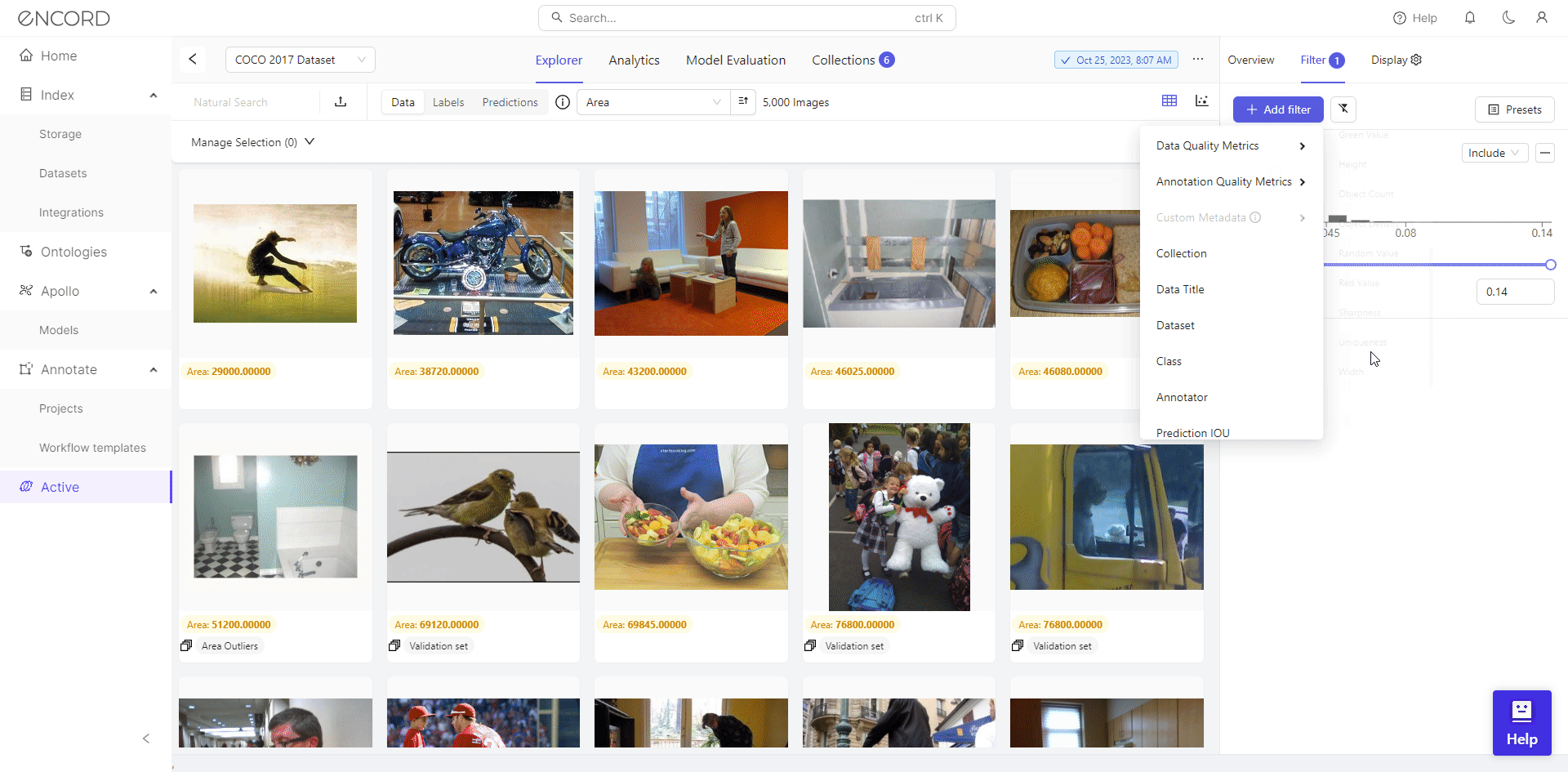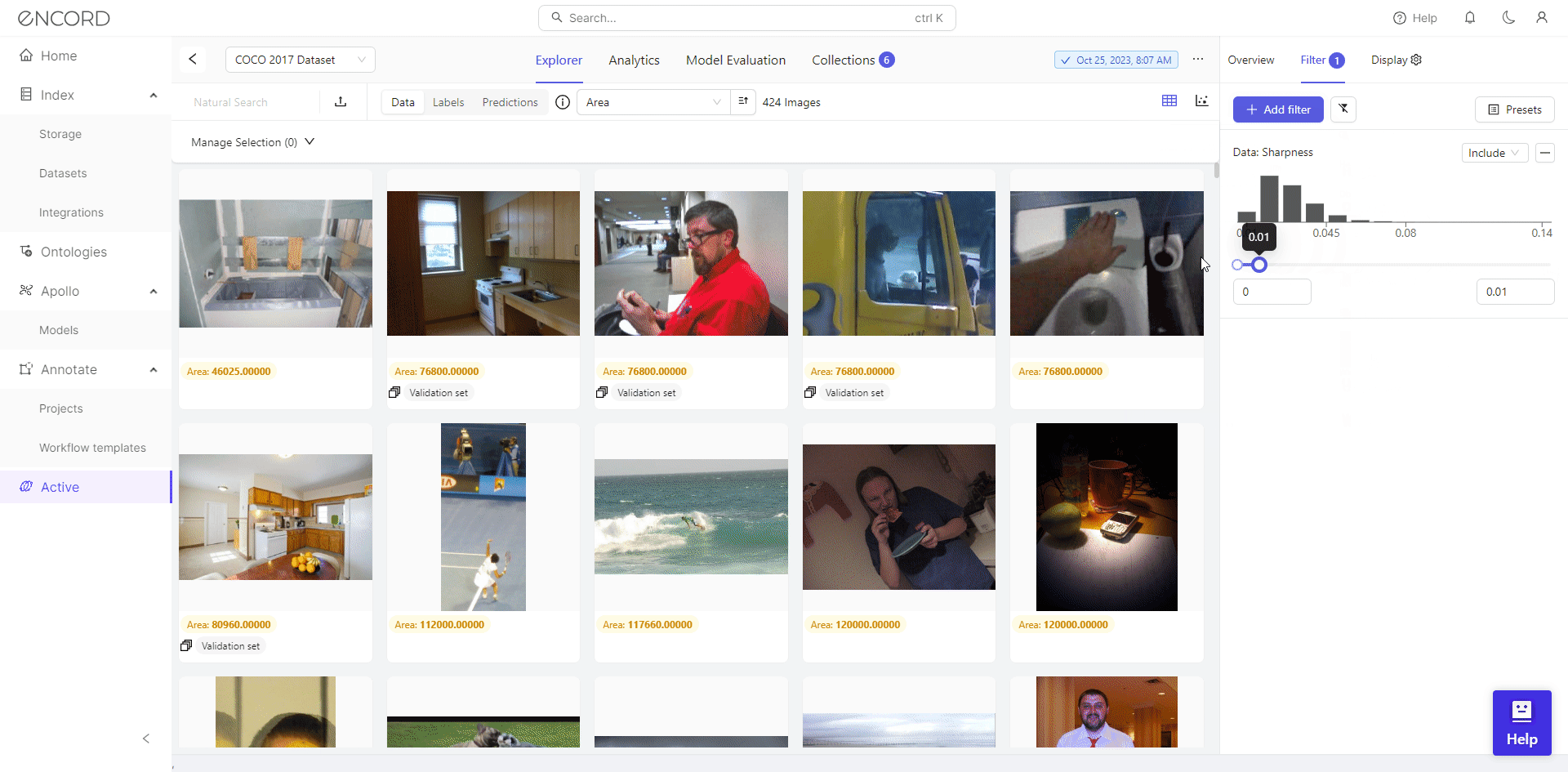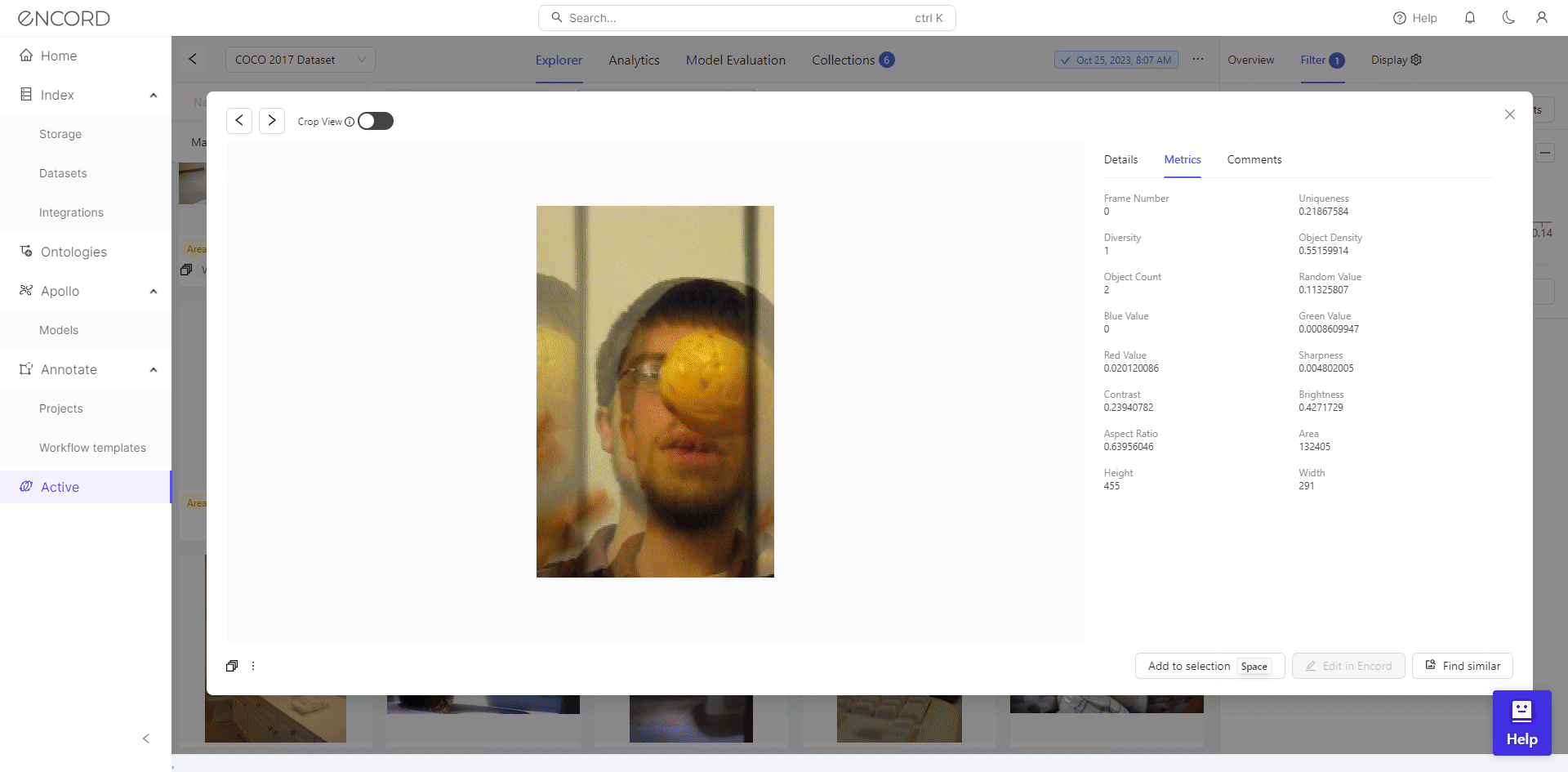
We identify 46 low-resolution images with filtering, potentially hindering effective training for object detection. Consequently, we can select the dataset, click Add to Collection, remove these images from the dataset, or export them for cleaning with a data preprocessing tool.
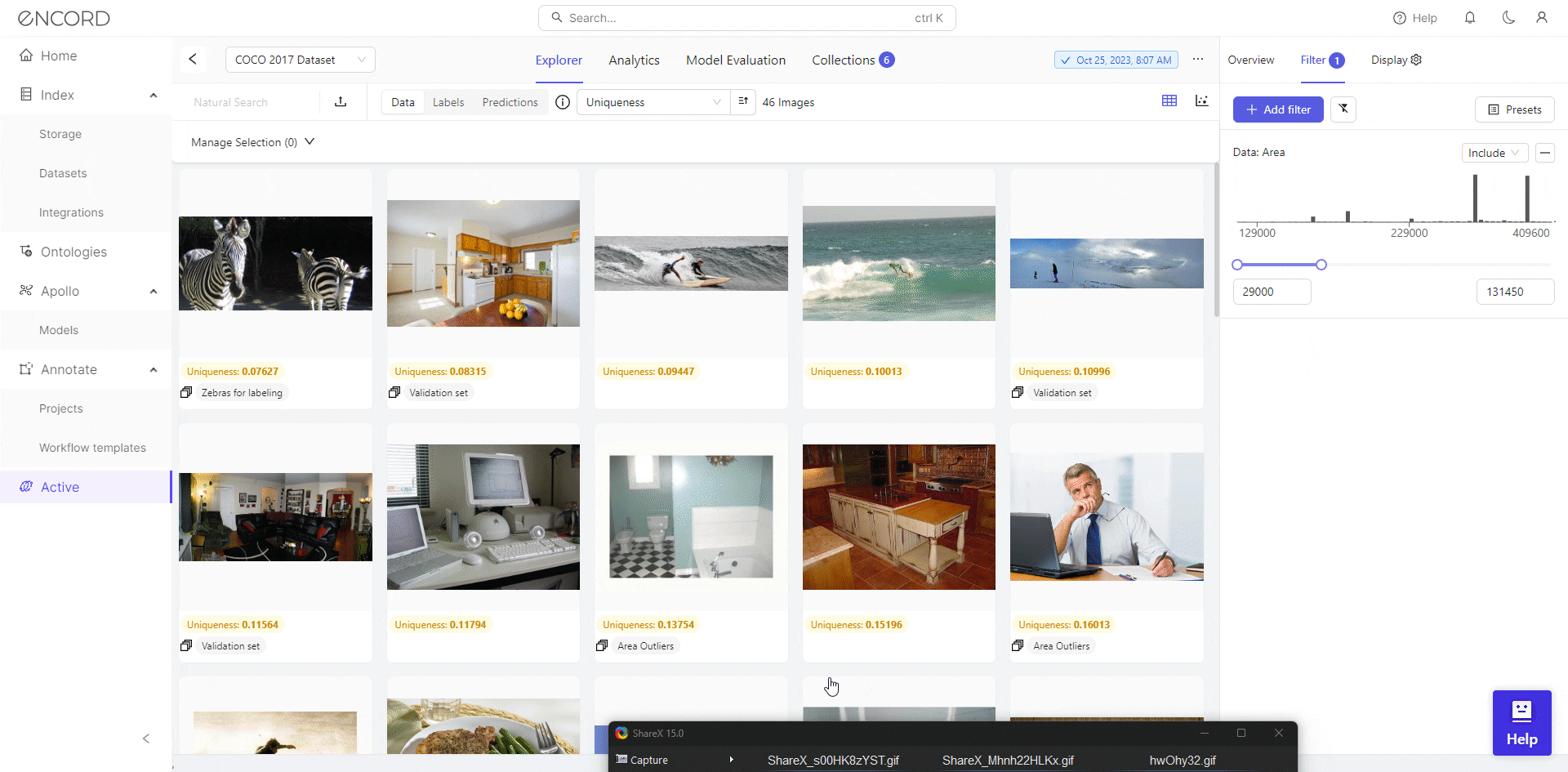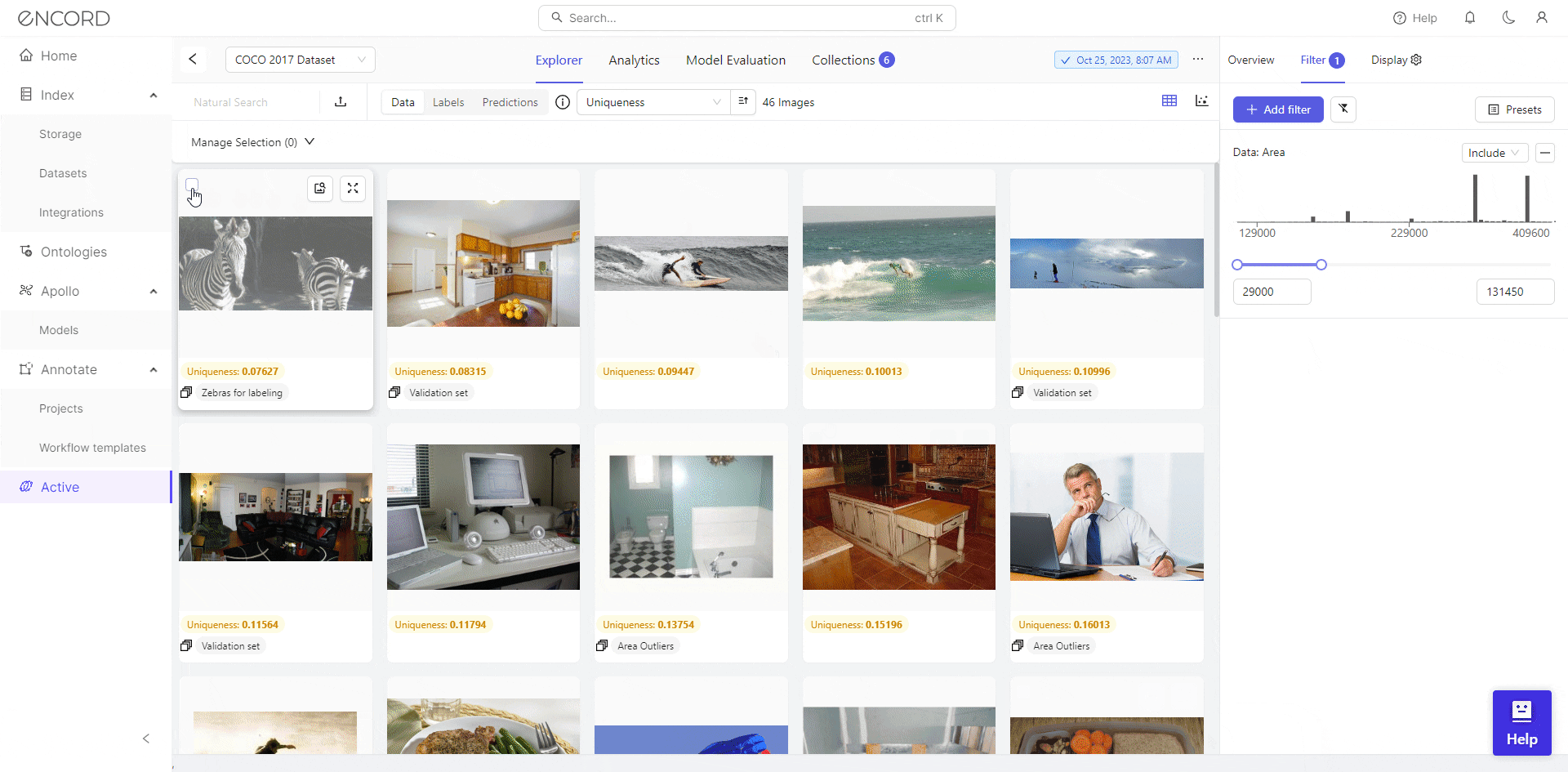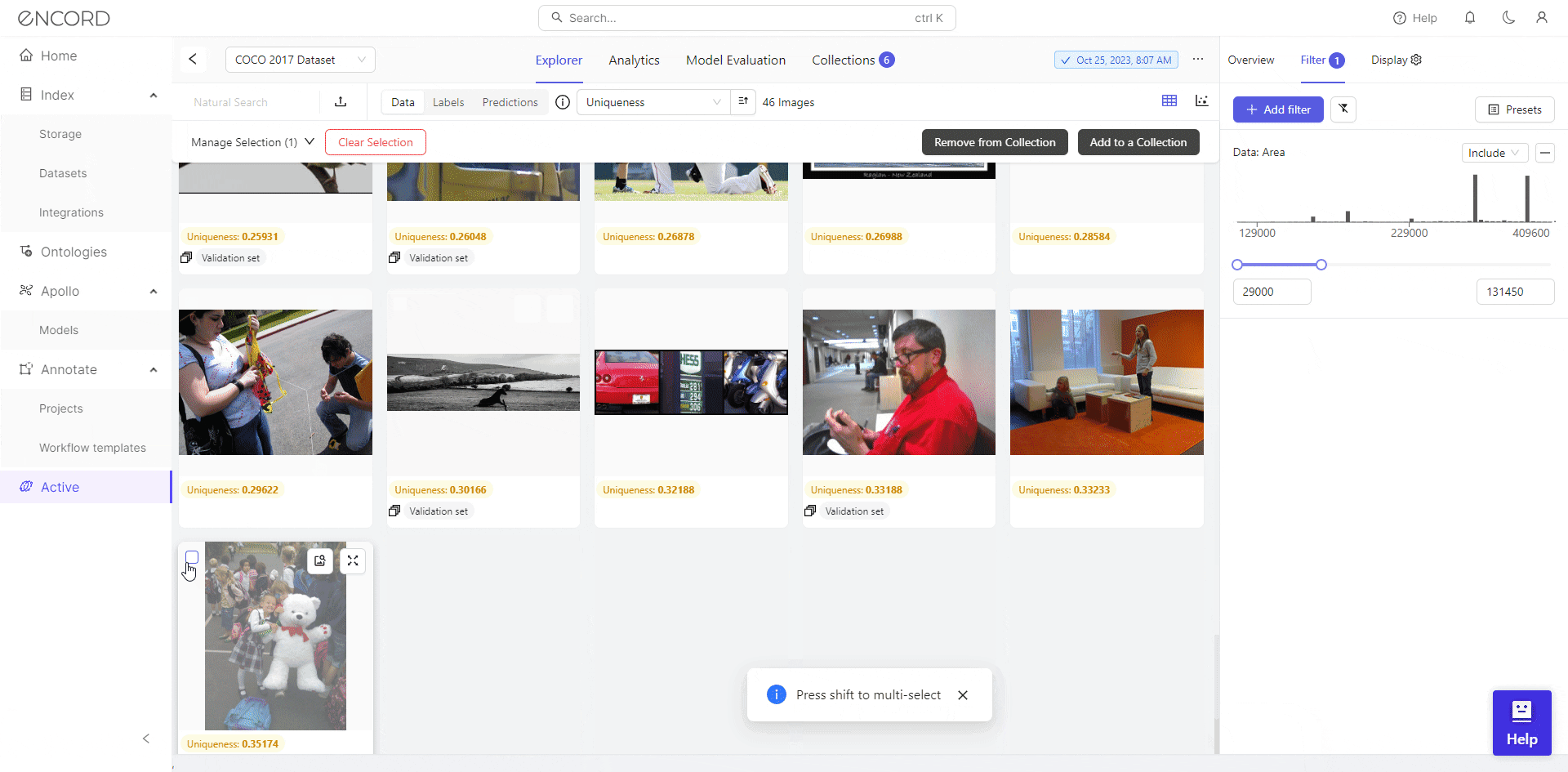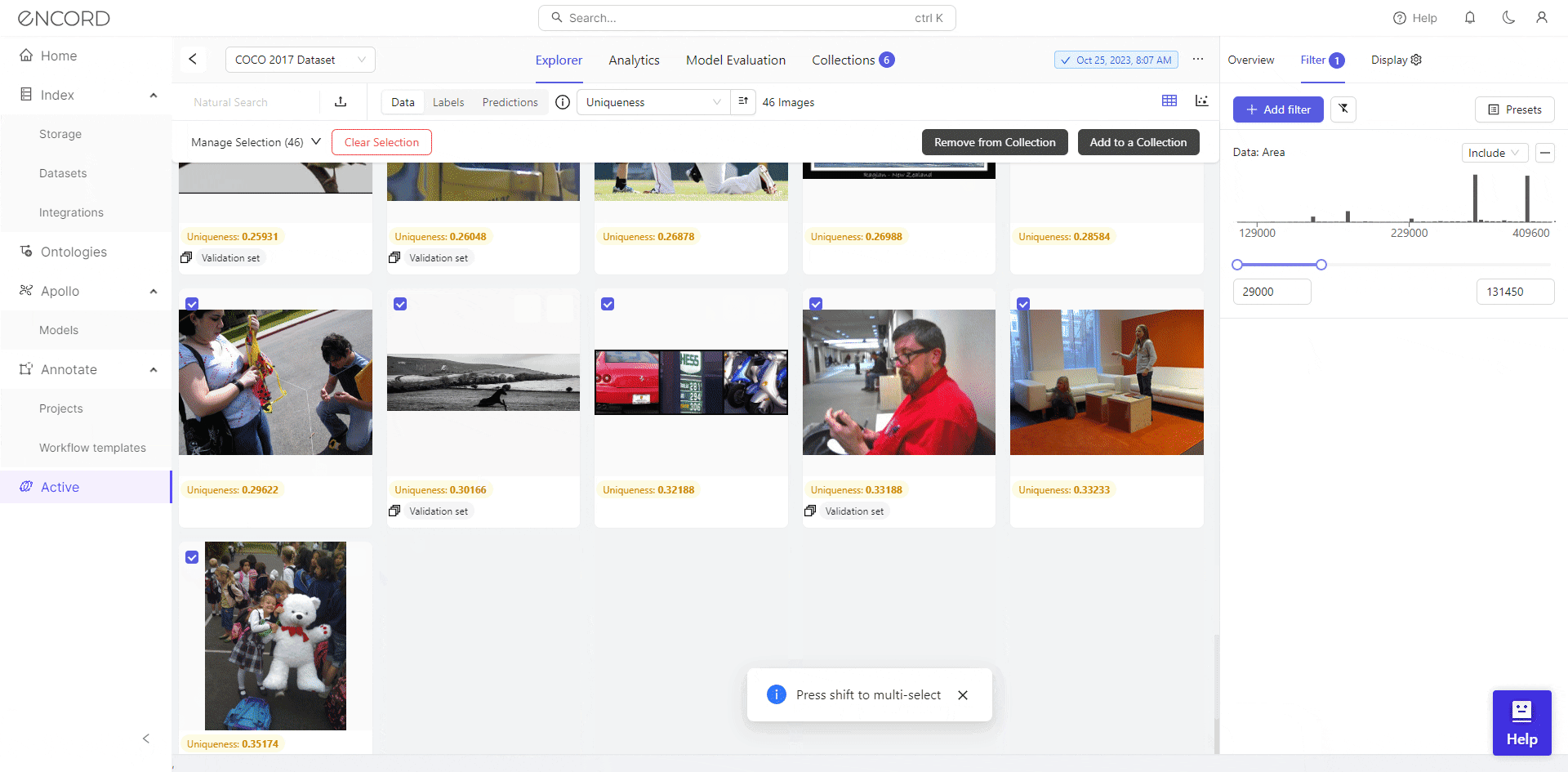
Encord Active facilitates visual and analytical inspection, allowing users to detect datasets for optimal preprocessing. This iterative process ensures the data is of good quality for the model training stage and improves performance on computer vision tasks.
Case Studies: Optimizing Data Cleaning for Self-Driving Cars with Encord Active
Encord Active (EA) streamlines the data cleaning process for computer vision projects by providing quality metrics and visual inspection capabilities.
In a practical use case involving managing and curating data for self-driving cars, Alex, a DataOps manager at self-dr-AI-ving, uses Encord Active's features, such as bulk classification, to identify and curate low-quality annotations. These functionalities significantly improve the data curation process.
The initial setup involves importing images into Active, where the magic begins.
- Alex organizes data into collections, an example being the "RoadSigns" Collection, designed explicitly for annotating road signs.
- Alex then bulk-finds traffic sign images using the embeddings and similarity search. Alex then clicks Add to a Collection, then Existing Collection, and adds the images to the RoadSigns Collection.
- Alex categorizes the annotations for road signs into good and bad quality, anticipating future actions like labeling or augmentation.
- Alex sends the Collection of low-quality images to a new project in Encord Annotate to re-label the images.
- After completing the annotation, Alex syncs the Project data with Active. He heads back to the dashboard and uses the model prediction analytics to gain insights into the quality of annotations.
Encord Active's integration and efficient workflows empower Alex to focus on strategic tasks, providing the self-driving team with a streamlined and improved data cleaning process that ensures the highest data quality standards.
Data Preprocessing
What is Data Preprocessing?
Data preprocessing transforms raw data into a format suitable for analysis. In computer vision, this process involves cleaning, organizing, and using feature engineering to extract meaningful information or features.
Feature engineering helps algorithms better understand and represent the underlying patterns in visual data. Data preprocessing addresses missing values, outliers, and inconsistencies, ensuring that the image or video data is conducive to accurate analyses and optimal model training.
Data Cleaning Vs. Data Preprocessing: The Difference
- Data cleaning involves identifying and addressing issues in the raw visual data, such as removing noise, handling corrupt images, or correcting image errors. This step ensures the data is accurate and suitable for further processing.
- Data preprocessing includes a broader set of tasks beyond cleaning, encompassing operations like resizing images, normalizing pixel values, and augmenting data (e.g., rotating or flipping images). The goal is to prepare the data for the specific requirements of a computer vision model.
Techniques for Robust Data Preprocessing
- Image Standardization: Adjusting images to a standardized size facilitates uniform processing. Cropping focuses on relevant regions of interest, eliminating unnecessary background noise.
- Normalization: Scaling pixel values to a consistent range (normalization) and ensuring a standardized distribution enhances model convergence during training.
- Data Augmentation: Introduces variations in training data, such as rotations, flips, and zooms, and enhances model robustness. Data augmentation helps prevent overfitting and improves the model's generalization to unseen data.
- Dealing with Missing Data: Addressing missing values in image datasets involves strategies like interpolating or generating synthetic data to maintain data integrity.
- Noise Reduction: Applying filters or algorithms to reduce image noise, such as blurring or denoising techniques, enhances the clarity of relevant information.
- Color Space Conversion: Converting images to different color spaces (e.g., RGB to grayscale) can simplify data representation and reduce computational complexity.
Now that we've laid the groundwork with data preprocessing, let's explore how to further elevate model performance through data refinement.
Enhancing Models with Data Refinement
Unlike traditional model-centric approaches, data refinement represents a paradigm shift, emphasizing nuanced and effective data-centric strategies. This approach empowers practitioners to leverage the full potential of their models through informed data selection and precise labeling, fostering a continuous cycle of improvement.
By emphasizing input data refinement, you can develop a dataset that optimally aligns with the model's capabilities and enhances its overall performance.
Model-centric vs Data-centric Approaches
- Model-Centric Approach: Emphasizes refining algorithms and optimizing model architectures. This approach is advantageous in scenarios where computational enhancements can significantly boost performance.
- Data-Centric Approach: Prioritizes the quality and relevance of training data. It’s often more effective when data quality is the primary bottleneck in achieving higher model accuracy.
The choice between these approaches often hinges on the specific challenges of a given task and the available resources for model development.
Data Refinement Techniques: Active Learning and Semi-Supervised Learning
- Active Learning: It is a dynamic approach that involves iteratively selecting the most informative data points for labeling. For example, image recognition might prioritize images where the model's predictions are most uncertain. This method optimizes labeling efforts and enhances the model's learning efficiency.
- Semi-Supervised Learning: It tackles scenarios where acquiring labeled data is challenging. This technique combines labeled and unlabeled data for training, effectively harnessing the potential of a broader dataset. For instance, in a facial recognition task, a model can learn general features from a large pool of unlabeled faces and fine-tune its understanding with a smaller set of labeled data.
With our focus on refining data for optimal model performance, let's now turn our attention to the task of identifying and addressing outliers to improve the quality of our training data.
Improving Training Data with Outlier Detection
Outlier detection is an important step in refining machine learning models. Outliers, or abnormal data points, have the potential to distort model performance, making their identification and management essential for accurate training.
Understanding Outlier Detection
Outliers, or anomalous data points, can significantly impact the performance and reliability of machine learning models. Identifying and handling outliers is crucial to ensuring the training data is representative and conducive to accurate model training.
Outlier detection involves identifying data points that deviate significantly from the expected patterns within a dataset. These anomalies can arise due to errors in data collection, measurement inaccuracies, or genuine rare occurrences.
For example, consider a scenario where an image dataset for facial recognition contains rare instances with extreme lighting conditions or highly distorted faces. Detecting and appropriately addressing these outliers becomes essential to maintaining the model's robustness and generalization capabilities.
Implementing Outlier Detection with Encord Active
The outlier detection feature in Encord Active is robust. It can find and label outliers using predefined metrics, custom metrics, label classes, and pre-calculated interquartile ranges. It’s a systematic approach to debugging your data. This feature identifies data points that deviate significantly from established norms.
In a few easy steps, you can efficiently detect outliers:
Accessing Data Quality Metrics: Navigate to the Analytics > Data tab within Encord Active. Quality metrics offer a comprehensive overview of your dataset.
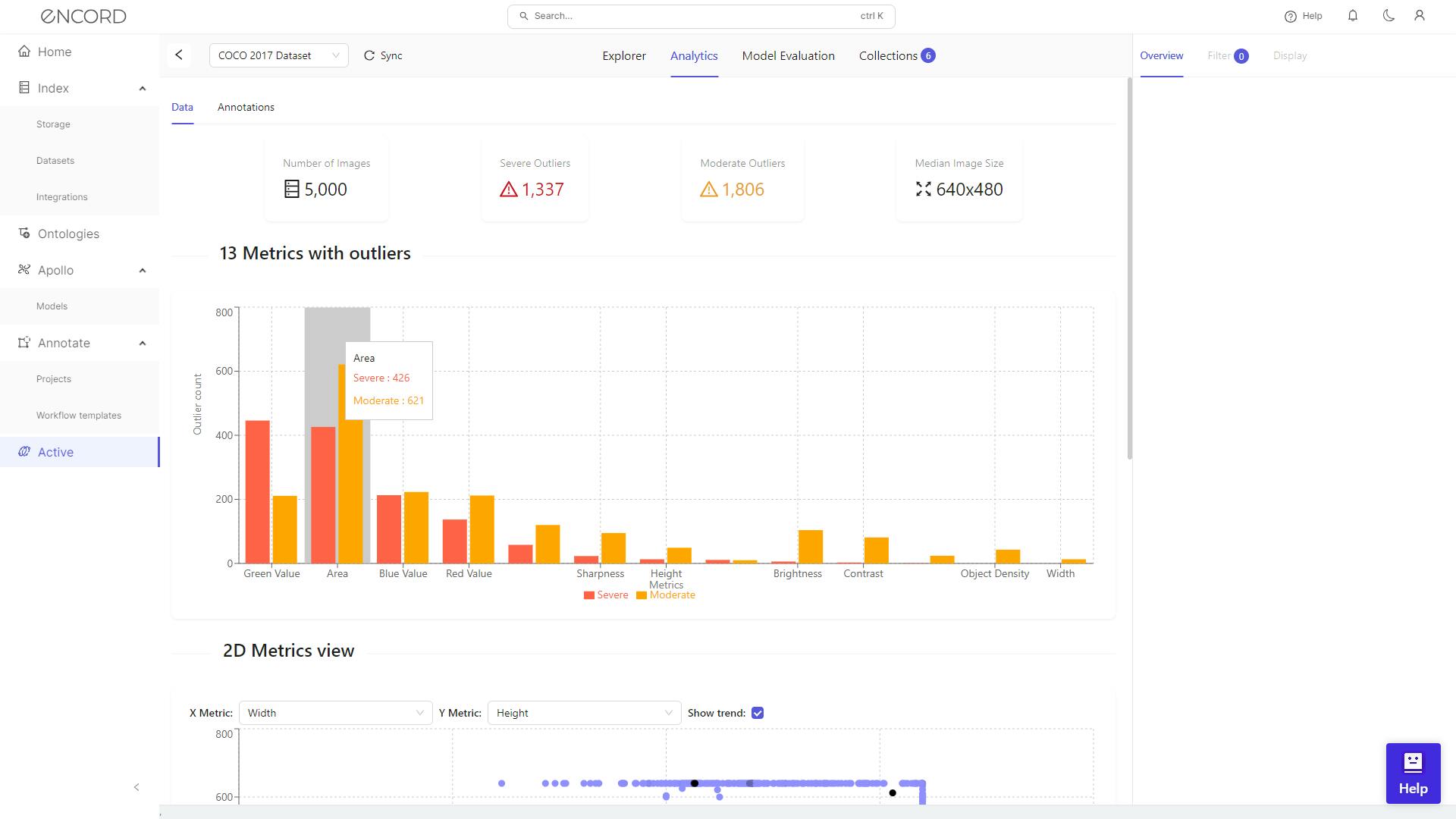
In a practical scenario, a data scientist working on traffic image analysis might use Encord Active to identify and examine atypical images, such as those with unusual lighting conditions or unexpected objects, ensuring these don’t skew the model’s understanding of standard traffic scenes.
Understanding and Identifying Imbalanced Data
Addressing imbalanced data is crucial for developing accurate and unbiased machine learning models. An imbalance in class distribution can lead to models that are skewed towards the majority class, resulting in poor performance in minority classes.
Strategies for Achieving Balanced Datasets
- Resampling Techniques: Techniques like SMOTE for oversampling minority classes or Tomek Links for undersampling majority classes can help achieve balance.
- Synthetic Data Generation: Using data augmentation or synthetic data generation (e.g., GANs, generative models) to create additional examples for minority classes.
- Ensemble Methods: Implement ensemble methods that assign different class weights, enabling the model to focus on minority classes during training.
- Cost-Sensitive Learning: Adjust the misclassification cost associated with minority and majority classes to emphasize the significance of correct predictions for the minority class.
When thoughtfully applied, these strategies create balanced datasets, mitigate bias, and ensure models generalize well across all classes.
Balancing Datasets Using Encord Active
Encord Active can address imbalanced datasets for a fair representation of classes. Its features facilitate an intuitive exploration of class distributions to identify and rectify imbalances. Its functionalities enable class distribution analysis. Automated analysis of class distributions helps you quickly identify imbalance issues based on pre-defined or custom data quality metrics.
For instance, in a facial recognition project, you could use Encord Active to analyze the distribution of different demographic groups within the dataset (custom metric). Based on this analysis, apply appropriate resampling or synthetic data generation techniques to ensure a fair representation of all groups.

Understanding Data Drift in Machine Learning Models
What is Data Drift?
Data drift is the change in statistical properties of the data over time, which can degrade a machine learning model's performance. Data drift includes changes in user behavior, environmental changes, or alterations in data collection processes. Detecting and addressing data drift is essential to maintaining a model's accuracy and reliability.
Strategies for Detecting and Addressing Data Drift
- Monitoring Key Metrics: Regularly monitor key performance metrics of your machine learning model. Sudden changes or degradation in metrics such as accuracy, precision, or recall may indicate potential data drift.
- Using Drift Detection Tools: Tools that utilize statistical methods or ML algorithms to compare current data with training data effectively identify drifts.
- Retraining Models: Implement a proactive retraining strategy. Periodically update your model using recent and relevant data to ensure it adapts to evolving patterns and maintains accuracy.
- Continuous Monitoring and Data Feedback: Establish a continuous monitoring and adaptation system. Regularly validate the model against new data and adjust its parameters or retrain it as needed to counteract the effects of data drift.
Practical Implementation and Challenges
Imagine an e-commerce platform that utilizes a computer vision-based recommendation system to suggest products based on visual attributes. This system relies on constantly evolving image data for products and user interaction patterns.
Identifying and addressing data drift
- Monitoring User Interaction with Image Data: Regularly analyzing how users interact with product images can indicate shifts in preferences, such as changes in popular colors, styles, or features.
- Using Computer Vision Drift Detection Tools: Tools that analyze changes in image data distributions are employed. For example, a noticeable shift in the popularity of particular styles or colors in product images could signal a drift.
Retraining the recommendation model
- Once a drift is detected, you must update the model to reflect current trends. This might involve retraining the model with recent images of products that have gained popularity or adjusting the weighting of visual features the model considers important.
- For instance, if users start showing a preference for brighter colors, the recommendation system is retrained to prioritize such products in its suggestions.
The key is to establish a balance between responsiveness to drift and the practicalities of model maintenance.
Next, let's delve into a practical approach to inspecting problematic images to identify and address potential data quality issues.
Inspect the Problematic Images
Encord Active provides a visual dataset overview, indicating duplicate, blurry, dark, and bright images. This accelerates identifying and inspecting problematic images for efficient data quality enhancement decisions. Use visual representations for quick identification and targeted resolution of issues within the dataset.
Severe and Moderate Outliers
In the Analytics section, you can distinguish between severe and moderate outliers in your image set, understand the degree of deviation from expected patterns, and address potential data quality concerns.
For example, below is the dataset analysis of the COCO 2017 dataset. It shows the data outliers in each metric and their severity.
Blurry Images in the Image Set
The blurry images in the image set represent instances where the visual content lacks sharpness or clarity. These images may exhibit visual distortions or unfocused elements, potentially impacting the overall quality of the dataset.
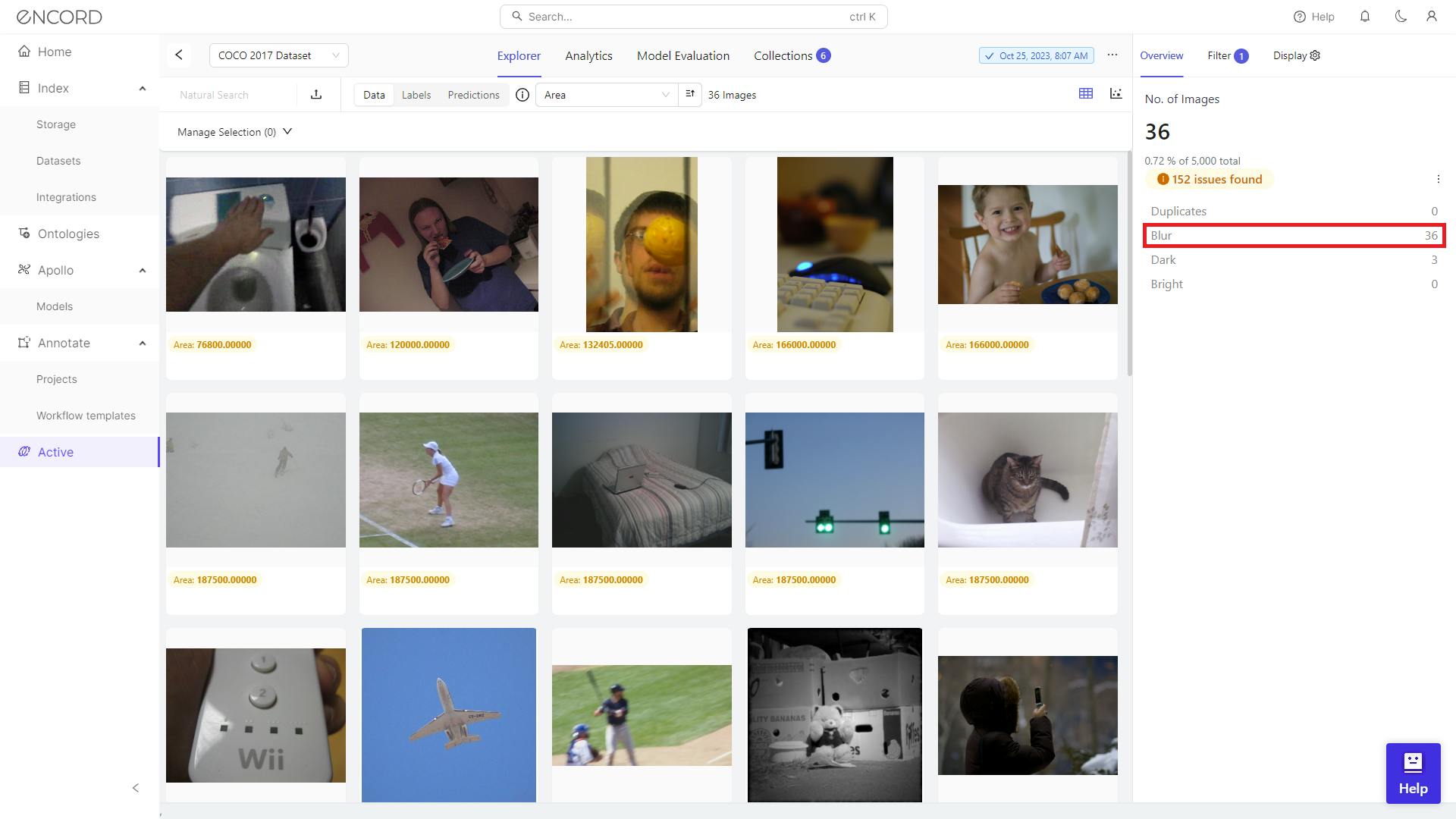
You can also use the filter to exclude blurry images and control the quantity of retained high-quality images in the dataset.
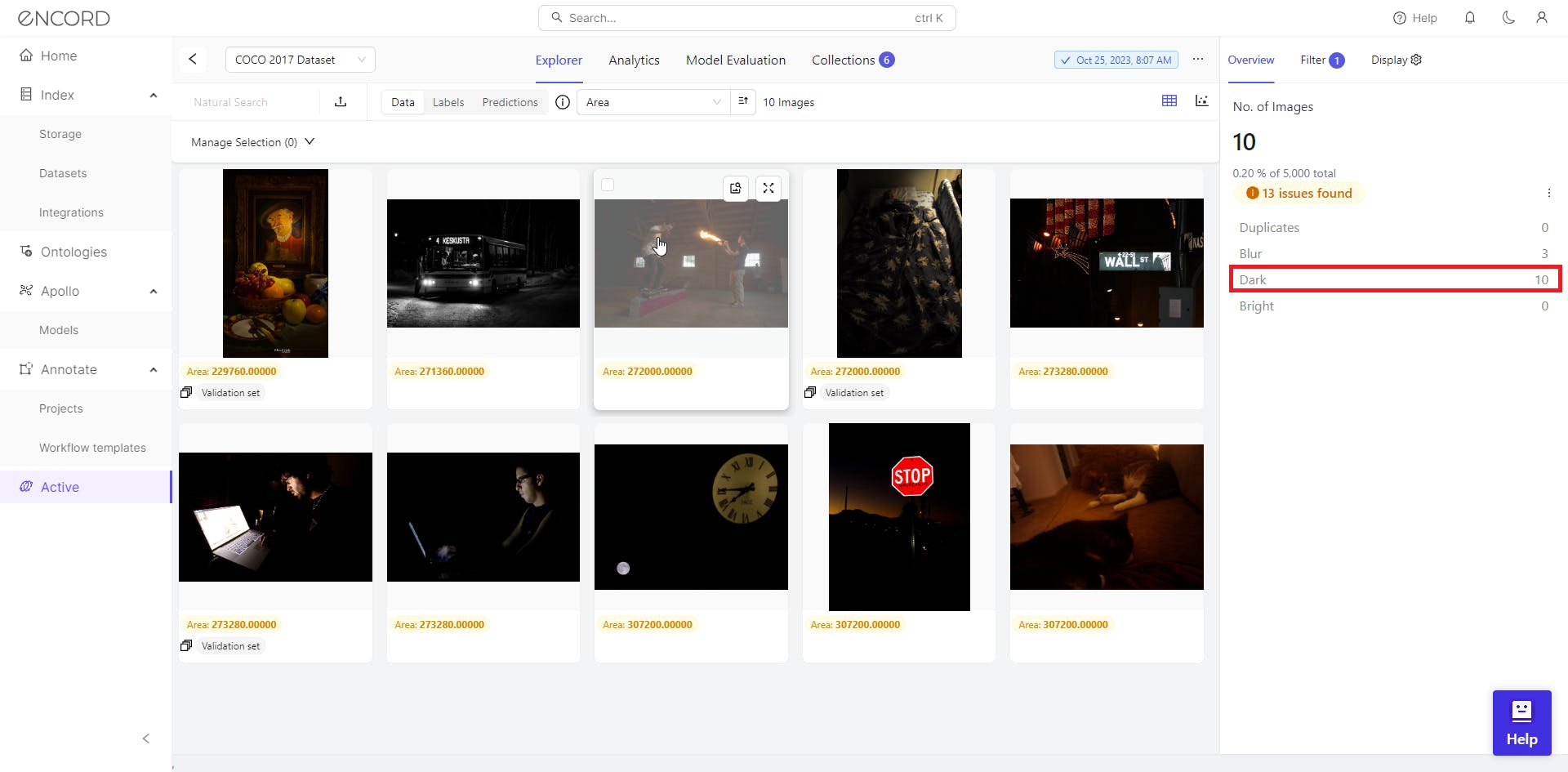
Darkest Images in the Image Set
The darkest images in the image set are those with the lowest overall brightness levels. Identifying and managing these images is essential to ensure optimal visibility and clarity within the dataset, particularly in scenarios where image brightness impacts the effectiveness of model training and performance analysis.
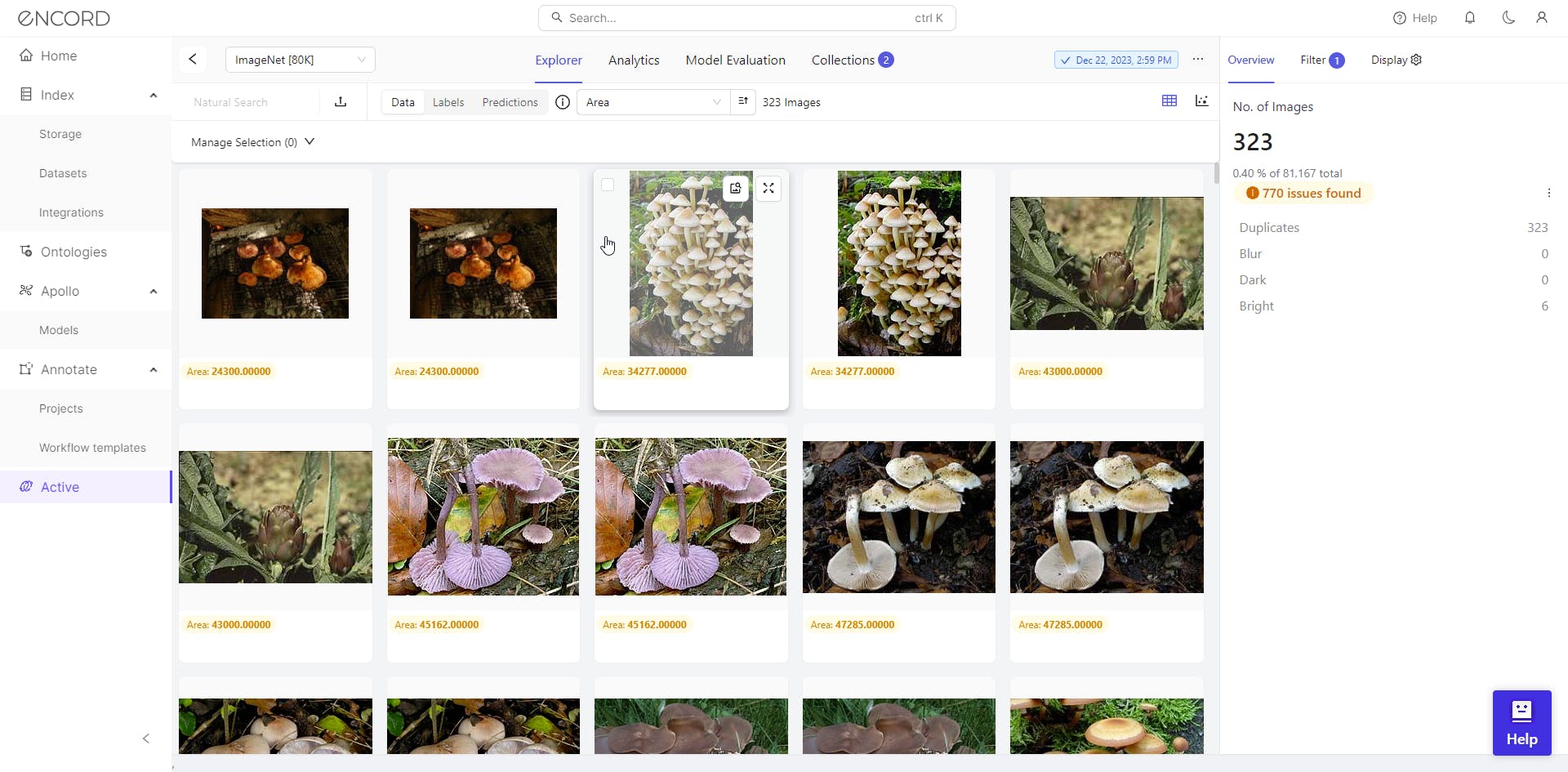
Duplicate or Nearly Similar Images in the Set
Duplicate or nearly similar images in the set are instances where multiple images exhibit substantial visual resemblance or share identical content. Identifying and managing these duplicates is important for maintaining dataset integrity, eliminating redundancy, and ensuring that the model is trained on diverse and representative data.
Next Steps: Fixing Data Quality Issues
Once you identify problematic images, the next steps involve strategic methods to enhance data quality. Encord Active provides versatile tools for targeted improvements:
Re-Labeling
Addressing labeling discrepancies is imperative for dataset accuracy. Use re-labeling to rectify errors and inconsistencies in low-quality annotation. Encord Active simplifies this process with its Collection feature, selecting images for easy organization and transfer back for re-labeling. This streamlined workflow enhances efficiency and accuracy in the data refinement process.
Active Learning
Leveraging active learning workflows to address data quality issues is a strategic move toward improving machine learning models. Active learning involves iteratively training a model on a subset of data it finds challenging or uncertain. This approach improves the model's understanding of complex patterns and improves predictions over time. In data quality, active learning allows the model to focus on areas where it exhibits uncertainty or potential errors, facilitating targeted adjustments and continuous improvement.
Quality Assurance
Integrate quality assurance into the data annotation workflow, whether manual or automated. Finding and fixing mistakes and inconsistencies in annotations is possible by using systematic validation procedures and automated checks. This ensures that the labeled datasets are high quality, which is important for training robust machine learning models.
Frequently asked questions
Data pre-processing involves transforming raw data into a suitable format for analysis. It includes cleaning, organizing, and enhancing data to ensure accuracy in machine learning models.
Data cleaning is important for removing errors and inconsistencies, ensuring accurate analyses, and preventing skewed results in machine learning models.
For computer vision, prepare data by resizing images, normalizing pixel values, and creating labeled datasets to facilitate model training and evaluation.
Common data quality issues in computer vision include noise from data curation, inconsistent labeling or annotations, missing data points, and dataset bias stemming from demographic or environmental factors. These challenges can significantly impact model performance and require careful consideration and mitigation strategies during dataset preparation.
Outliers are extreme data points that deviate significantly from the norm. Treating outliers is essential to prevent them from skewing model predictions and ensuring model accuracy.
Feature scaling involves normalizing the range of features in a dataset. It is used in the data preprocessing stage because the machine learning model converges faster. Using feature scaling if regularization is part of the loss function is also important to penalize coefficients efficiently.
To assess video data quality in computer vision, utilize visual inspection to identify artifacts, sample frames for analysis, assess resolution consistency across frames, and evaluate motion smoothness. These methods help ensure that video data meets quality standards for accurate and reliable computer vision model training and evaluation.
Data curation involves organizing, managing, and maintaining datasets to ensure their quality and relevance. Data cleaning, a subset of curation, specifically focuses on identifying and correcting errors, inconsistencies, and inaccuracies within the data. While curation is a broader, ongoing process, cleaning addresses immediate issues to improve data integrity.
Encord specializes in generating high-quality images that meet the demands of e-commerce clients who require photographic quality at a lower cost. The platform allows for the creation of realistic images and 3D models that help clients present their products effectively, even in challenging scenarios where traditional models are unavailable.
Encord can generate domain-specific quality metrics for images, such as assessing the consistency of room dimensions before and after home staging. By utilizing depth maps and other analytical tools, Encord helps in establishing semi-automated methods for attributing quality to generated images, ensuring they meet specific criteria.
Encord actively addresses issues related to image quality, such as blurry or low-resolution images, by ensuring that DICOM files are natively handled. This capability helps maintain the integrity of the image data throughout the annotation process, ensuring high-quality outcomes for machine learning models.
High-quality input data is crucial for Encord's image generation capabilities. The platform ensures that the images produced meet the expectations of clients in the e-commerce sector, enabling the creation of realistic product representations that enhance customer engagement and satisfaction.
Yes, Encord includes functionalities that help identify and exclude images that do not meet certain quality standards, such as blurred or low-resolution images. This ensures that only optimal images are used for training, which is crucial for building effective machine learning models.
Encord aims to develop solutions that can handle variations in depth image quality produced by different cameras. This involves adapting models to work effectively with both high-quality and lower-quality depth images, ensuring robust performance across diverse environments.
Yes, Encord is designed to accommodate both high-quality and low-quality images. This flexibility allows research teams to experiment with a diverse range of data, facilitating the exploration of what works best for their specific machine learning applications.
Encord includes advanced preprocessing features that help to reduce noise in images before they are sent for annotation. This ensures that only high-quality data is used, improving the overall accuracy and effectiveness of the machine learning models.
Encord focuses on subpixel-level measurements and employs specialized annotation techniques to handle the challenges presented by noisy images. This approach ensures that even with low signal-to-noise ratios, accurate annotations can be achieved.
Encord focuses on high-resolution rendering of ECG signals, allowing users to zoom in on details while maintaining clarity. This is achieved through advanced visualization techniques that separate distinct signals for easy comparison.