How to Choose the Right Data for Your Computer Vision Project

For machine learning practitioners developing commercial applications, finding the best data for training their computer vision model is critical for achieving the required performance. But this kind of data-centric approach is only as good as your ability to get the right data to put into your model.
To help you get that data, this article will explore:
- The importance of finding the best training data
- How to prioritize what to label
- How to decide which subset of data to start training your model on
- How to use open-source tools to select data for your computer vision application
Why Focus on Data for Training Your Computer Vision Model?
There are several reasons why you should focus largely on building training data while working on your computer vision model. We will look briefly into three main aspects of your training data:
Data Quality
Firstly, the quality of the data used for training directly impacts the model's performance. An artificial intelligence model’s ability to learn and generalize to new, unseen data depends on the quality of the data it is trained on.
For your computer vision model, the data type can be images, videos, or DICOMs. No matter the type, the data quality can be considered good when it covers a wide range of possible scenarios and edge cases (i.e. it is representative of the problem space). If the data used for training is biased or unrepresentative, the model may perform poorly on real-world data that falls outside the training data range. This may be because the model is overfitting or underfitting the training data and not generalizing well to new data.
Secondly, the data used for training should be relevant to the task at hand. This means that the features used in the data should be meaningful and predictive of the target variable. If irrelevant or redundant features are included in the training data, the model may learn patterns that are not useful for making accurate predictions.
For example, let's say you want to check the quality of the dataset you have built for the classification task. In the case of classification, a good measure of the dataset's quality is how separable the data points are. If the data points can be grouped into separable clusters, then the model will learn to classify those clusters easily. If the datapoints aren’t separable, the model cannot learn to classify. To define the separability of the dataset, decomposition algorithms are used (Such as Principal Component Analysis, autoencoders, variational autoencoders, etc.)
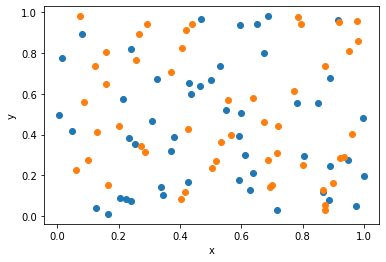
By plotting the features in 2D using a decomposition model, you can see in this dataset, the data points cannot be separated into clusters. Hence, data quality would be considered low for classification tasks.
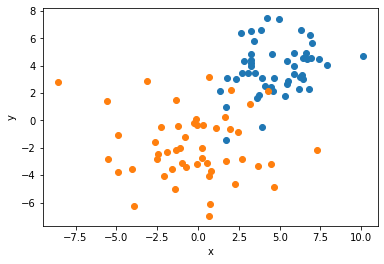
By plotting the features in 2D using a decomposition model, you can see in this dataset, the data points can easily be separated into clusters. Hence, data quality would be considered high for classification tasks.
Of course, different computer vision tasks would each need a different measure to define the overall quality of the data.
Data Quantity
Sufficient data is also important for computer vision models. The amount of data needed for training varies depending on the complexity of the task and the model used (e.g., complex deep learning model segmentation tasks have one requirement, whereas a simple classification task might have a different one).
For most use cases, a large amount of training data is better, as it allows the model to learn more robust representations of the computer vision task (read our blog on data augmentation to understand how to efficiently add more training images to your dataset). However, it bears repeating that data collection, data processing, and data annotation are time-consuming and resource intensive, so you have to find the right balance.
Label Quality
In addition to the quality of the data sources, the way the data is labeled also makes a huge difference.
Label quality refers to the accuracy and consistency of the annotations or labels assigned to the data in computer vision tasks. It is a crucial factor that determines the performance of machine learning algorithms in tasks such as object detection, image classification, and semantic segmentation.
High-quality labels provide the model with accurate information, allowing it to learn and generalize well to new data. In contrast, low-quality or inconsistent labels can lead to overfitting, poor performance, and incorrect predictions. Therefore, it is important to ensure that the labels used for training computer vision models are of high quality and accurately reflect the visual content of the images.
There are several ways you can mitigate label errors in your available datasets, such as:
- Clear label instructions: A clear set of guidelines that are shared amongst the team is essential before starting the annotation process. It will ensure uniformity among the labels tagged and also provide information about the labels to the machine learning engineer who would use these annotated data.
- Quality assurance system: The best practice while building a computer vision model is to have a quality assurance system in the pipeline. Here, you have an additional step to audit a subset of the labeled data. This is particularly helpful when you are dealing with a massive dataset. The addition of this step also makes your model more production friendly.
- Use trained models to detect label errors: There are tools available (such as Encord Active) that have features to help you detect label errors. By being able to easily find label errors you can ensure they get rectified before they start reducing the accuracy of your model.
To learn more about different label errors and how you can efficiently handle them, read our three-part guide Data errors in Computer Vision: Find and Fix Label Errors(part 1).
Once you’ve collected the image or video data you need and you’re confident with the quality of the dataset, you need to start labeling it. But labeling data is a time-consuming and labor-intensive process. So it is vital you’re first able to identify which data should be labeled, rather than trying to label all of it.
How do you decide what data you should label?
The decision of which data to label is usually guided by the specific task and the resources at your availability. Below are a few factors you should consider while selecting data for your next computer vision project:
- Problem definition: The problem you are trying to solve should guide the selection of data to label. For example, if you are building a binary classifier, you should label data that contains examples of both classes.
- Data quality: High-quality data is essential for building accurate machine learning models, so it’s important to prioritize labeling high-quality data. For example, if you are building an object detection model, you need the object of interest to be represented from a different point of view in the dataset. The annotations should also specify which is the object of interest and which isn’t (even if they “look” similar).
- Data diversity: To ensure that your model generalizes well, it’s important to label data that is diverse and representative of the problem you are trying to solve.
- Annotation cost: Video or image annotation can be time-consuming and expensive, so it’s important to prioritize the most important data to label based on the available resources.
- Model requirements: The data should be selected according to the machine learning algorithm you want to use. These algorithms are selected based on the problem you want to solve. Some algorithms require more labeled data than others, so it’s important to consider this when selecting data to label.
- Available resources: The amount of data that can be annotated is often limited by the available resources, such as time and budget. The selection of data to be annotated should take these constraints into account.
These factors help you to understand the properties of the data.
Understanding your data is essential to curate a training dataset that will help the computer vision algorithm solve the task at hand better. One approach is to start by labeling a small subset of the data to get a feel for the types of patterns that need to be learned.
This initial labeling phase can then be used to identify which data is particularly difficult to classify or identify data that is critical for the success of the application.
Such experimentation is easier when using a data curation and management tool. This can also provide valuable insights into the types of patterns that need to be learned.
Another approach is to leverage existing annotated data or use expert annotators or domain experts. This data can provide a starting point for labeling. This method can be more expensive but does require less experimentation.
How to Curate Data for Data Labeling
Curating data for labeling is a crucial step in preparing datasets for machine learning tasks. Here’s a guide on how to effectively curate data:
- Problem Definition: Define the specific task or problem your model aims to solve. This guides the selection of data that will be labeled to train your machine learning model.
- Data Collection: Gather a diverse range of data that represents different scenarios, variations, and conditions relevant to your problem statement. Ensure data quality and diversity to improve model robustness.
- Data Preprocessing: Clean and preprocess data to remove noise, correct errors, and standardize formats. This ensures that labeled data is consistent and of high quality.
- Data Annotation: Label the curated data with annotations that accurately describe the objects or features of interest. Use annotation tools and methodologies that align with your project requirements.
- Metadata Management: Organize and manage metadata to facilitate easy retrieval and understanding of dataset characteristics.
- Quality Assurance: Implement rigorous quality checks on annotated data to identify and correct labeling errors or inconsistencies. This step is critical to ensure the accuracy and reliability of the training dataset.
Using Encord Index for Data Curation and Management
Encord Index streamlines data curation and management by facilitating data versioning, ensuring quality assurance, managing metadata effectively, customizing workflows for efficient annotation, and providing powerful visualization tools. It optimizes the process of preparing datasets for machine learning tasks, ensuring they are well-organized, clean, and suitable for training high-performance AI models.
How to Decide Which Subset of Data for Model Training
Once you have labeled your data, the next step is to split the data into training, validation, and test subsets.
The training set is used to train the model, the validation set is used to tune the model's hyperparameters, and the test set is used to evaluate the model's performance on unseen data.
Now, when deciding which subset of data to start training your ML model on, the following factors can be considered:
- Size of the dataset: A smaller subset can be used initially to quickly train and evaluate your model, while larger subsets are used to build a robust and fine-tuned model.
- Representativeness of the data: It is important to choose a subset that is representative of the entire dataset, to avoid biases in the model’s predictions.
- Annotation quality: If the data has been manually annotated (with bounding boxes, polygons, or anything else), it is important to ensure that the annotations are of high quality to avoid training a model on incorrect or inconsistent information.
- Computational resources: The volume of computational resources available for training can influence the size of the subset that can be used.
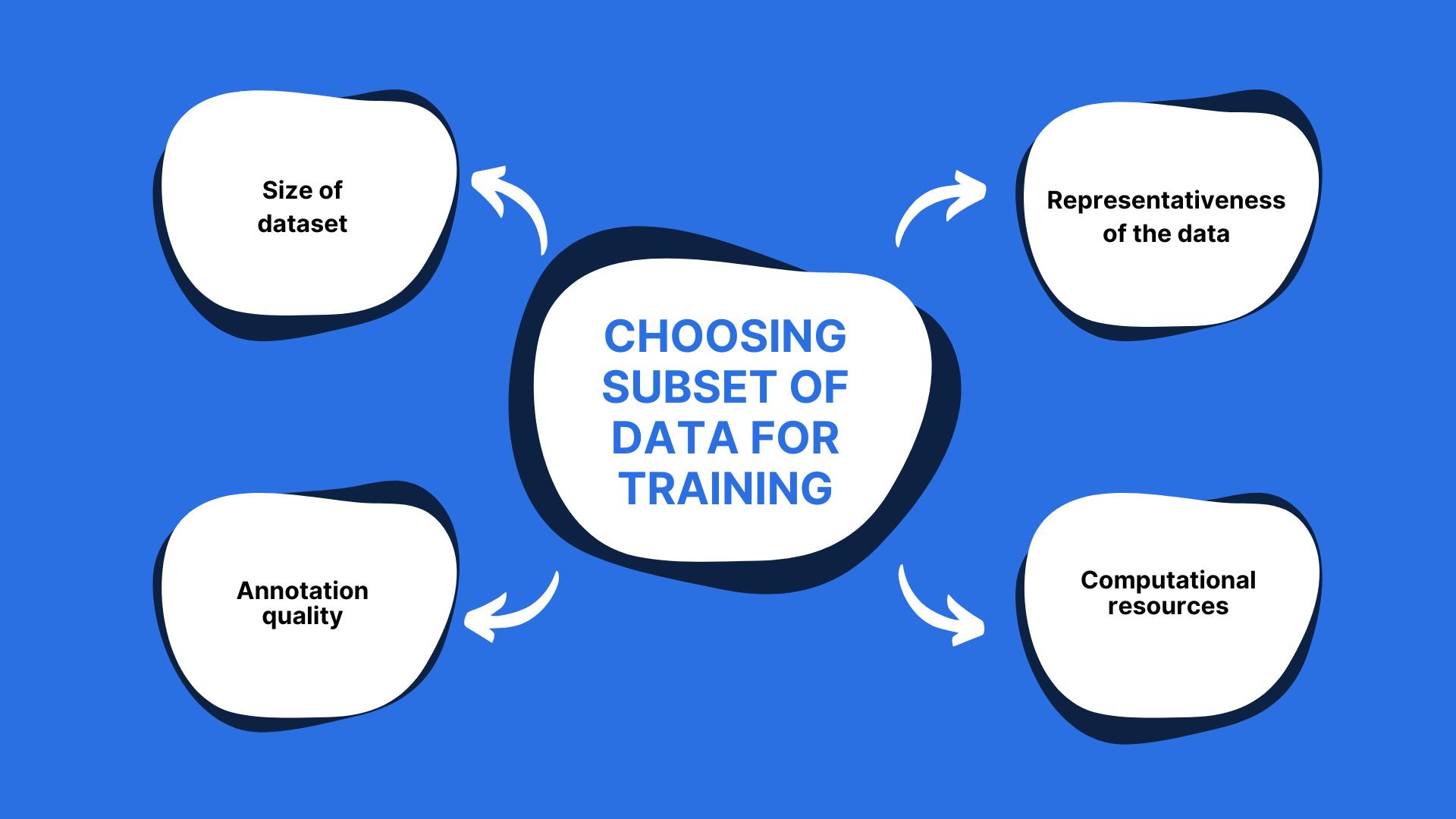
The ultimate objective is to select a subset that balances between being small enough to train quickly and being large enough to represent the entire dataset accurately.
There are data annotation tools that provide features that allow you to understand, annotate and analyze your data with ease. Let’s look at one such open-source tool and how to use it to understand your data.
Using Open-Source Tools to Select Data For Training
Here we will be using the open-source tool Encord Active on the RarePlanes dataset (which contains real and synthetically generated satellite imagery). For that, let’s download Encord Active in Python (or check out the Encord Active repository on GitHub):
python3.9 -m venv ea-venv source ea-venv/bin/activate # within venv pip install encord-active
RarePlanes is an open-source dataset that is available as a sandbox project on Encord Active and can be downloaded through the CLI itself. If you want to download it on your own, you need an AWS account and the AWS CLI installed and configured. Let’s download the RarePlanes image dataset:
# within venv encord-active download #select the rareplanes dataset #to visualize cd rareplanes encord-active visualize
Now you can see that the dataset has been imported to the platform, and you can visualize different properties of both the data and the labels.
First, let's discuss the data properties. Upon selecting Data Quality→Summary, you can visualize an overview of the data properties.
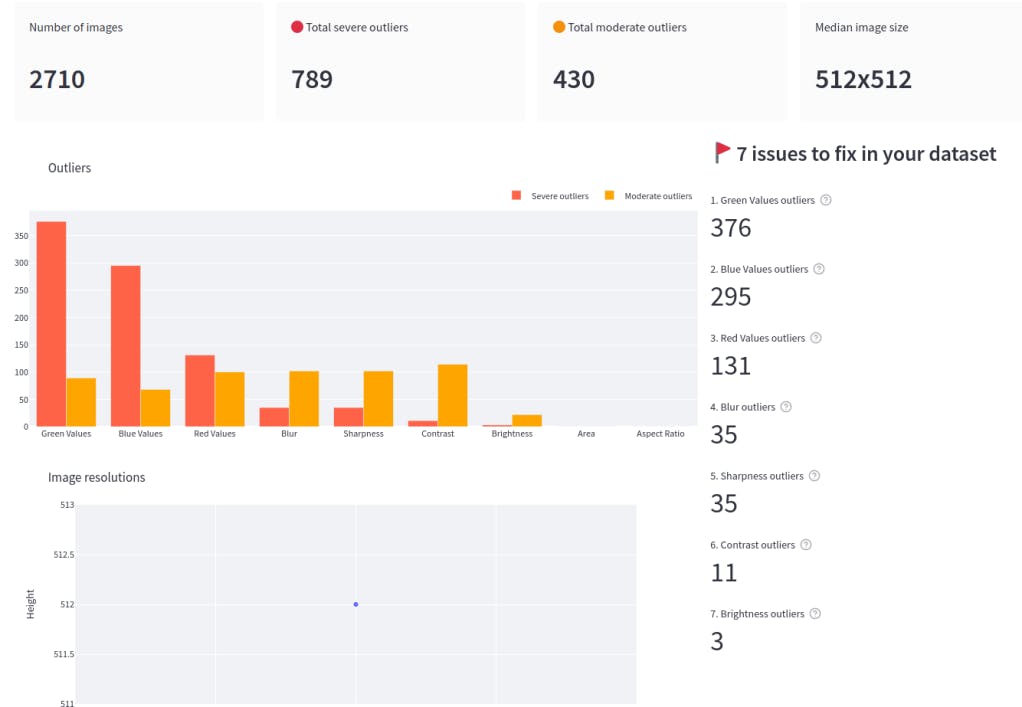
Data quality summary in Encord Active
From the summary, you can select the properties which show severe outliers, such as the green values. This allows you to analyze the quality of the dataset. They also provide features that allow you to either split the outliers evenly when splitting the data into training, validation, and test dataset or if you want to eliminate the outliers entirely.
For example, using the feature Action→Filter&Export, initially, we can see it has 9524 data points.
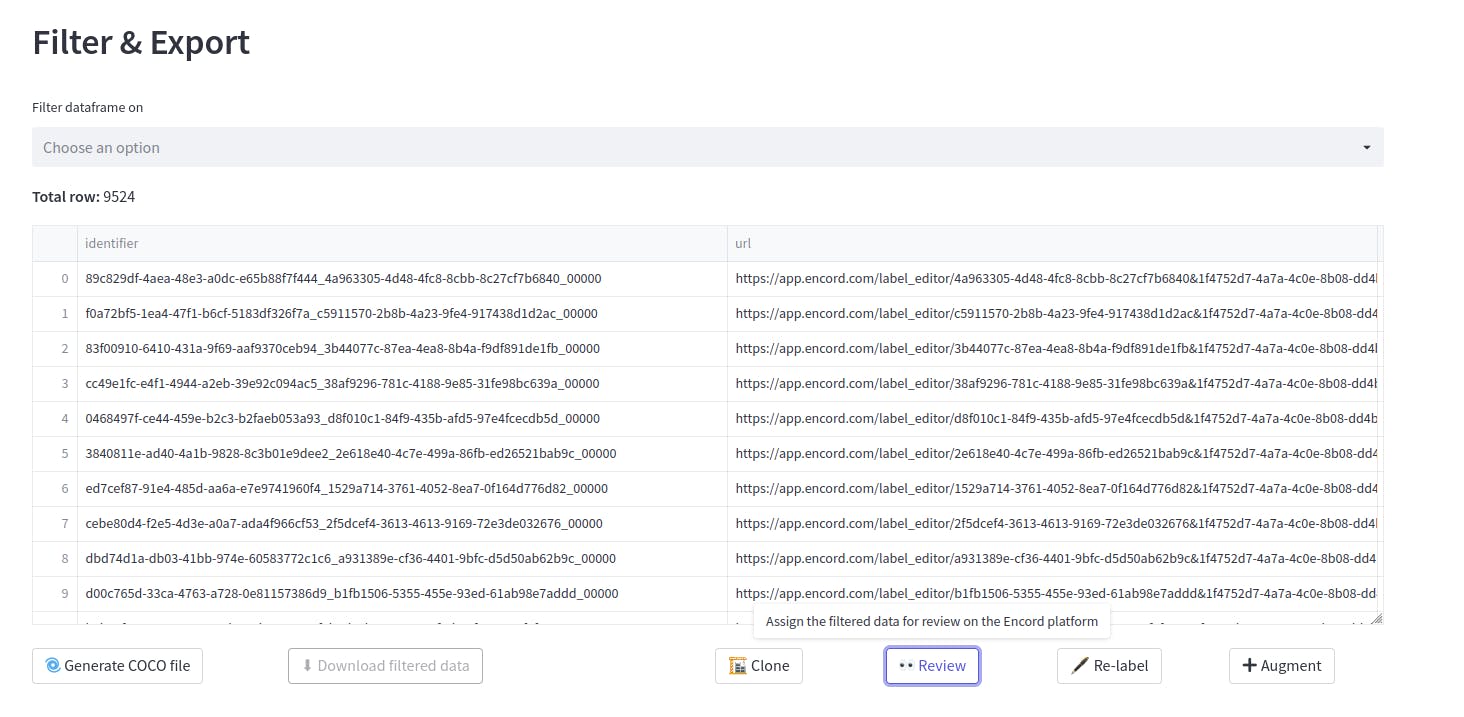
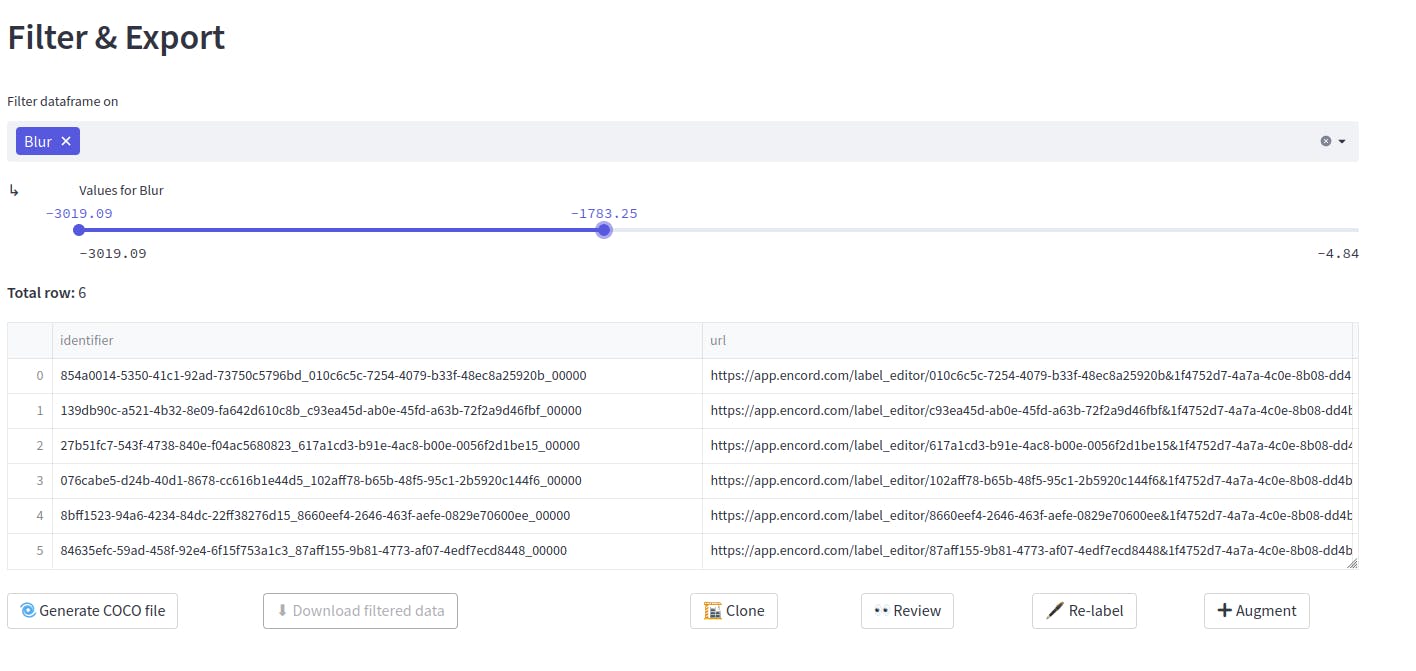
Now, previously we saw that the data contains 35 blur outliers. So after evaluation of those blur outliers, while creating the new dataset, we can easily eliminate these outliers by simply selecting from the drop-down menu. The threshold of the blur can also be varied.
Now let’s see how the tool can be helpful in checking the label quality. Select Label Quality→Summary, you will be able to visualize the different properties of the labels. This helps in checking how well the data has been labeled and if it is suitable for your machine learning project.
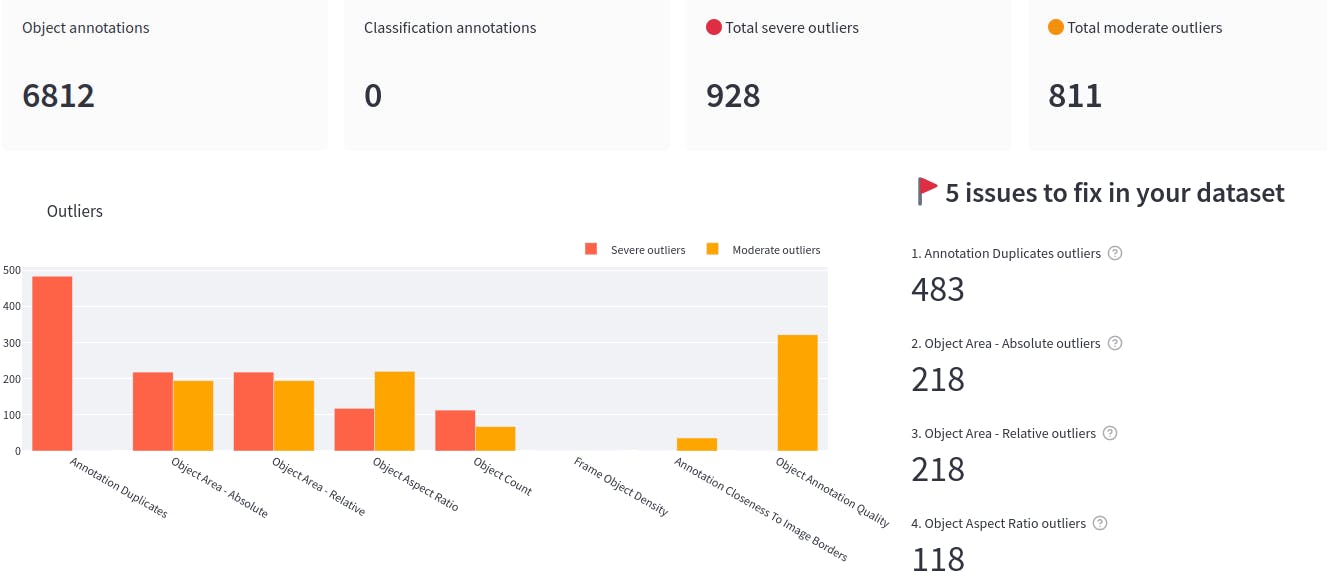
Label quality summary page in Encord Active
It allows you to see the major issues to fix in your dataset. So you can directly filter out the outliers and easily address these issues. For example, in the example above, you can see the RarePlanes dataset has 483 annotation duplicates.

Example of annotation duplicates
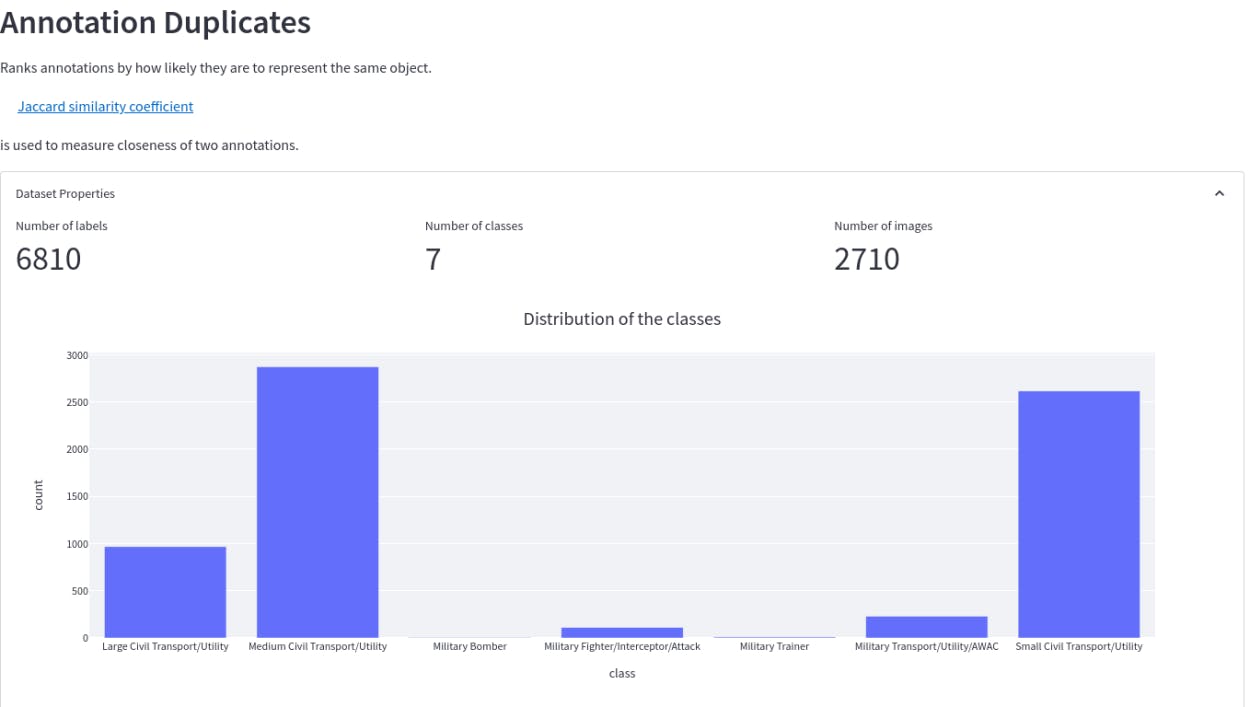
Encord Active’s explorer page showing the distribution of annotation duplicates
In Label Quality→Explore, upon selecting Annotation duplicates, you can analyze the outliers with ease. Now, these outliers can be dealt with differently depending on their quantity and type. The above dataset has almost 7% of duplicates. These images would not provide any additional information for the model to learn. So it would be better if these images are removed or merged.
Next Steps After Choosing Your Data
After data curation and annotation, the project workflow can head in different directions based on where you are in your ML model lifecycle.
If you have just finished curating your dataset, then checking if the amount of data is enough should be your next step.
If you are happy with your curated dataset, then building a baseline model would be a good start. This can help you judge if you need to make changes to the architecture of your machine learning algorithm or do feature extraction to improve the input to your algorithm.
Create a Baseline Model
It is a simple model built on the dataset curated without feature engineering. The goal of creating a baseline model is to create a starting point for evaluating model performance and to provide a standard to compare other, more complex models. It is important to keep in mind that the performance of a baseline model is often limited, but it provides a useful starting point for building more complex, trained models.
Check if the Amount of Data is Enough
The amount of data needed for a machine learning project depends on several factors, including the complexity of the model, the complexity of the learning algorithm, and the level of accuracy desired.
In general, more data can lead to more accurate models, but there is a point of diminishing returns where increasing the data size does not significantly improve performance.
As a rough rule of thumb, in computer vision, 1000 images per class is enough. This number can go down significantly if pre-trained models are used (Source). According to a study, the performance on vision tasks increases logarithmically based on the volume of training data size. So a large dataset is always desirable. But nowadays, it isn’t that common to build neural networks from scratch as there are many high-performance pre-trained models available. Using transfer learning on these pre-trained models, you can improve performance on many computer vision tasks with a significantly smaller dataset.
Feature Extraction
A feature in computer vision is a quantifiable aspect of your image that is specific to the object you are trying to recognize. It could be a standout hue in an image or a particular shape like a line, an edge, or a section of an image. Feature extraction is an important step as the input image has too much extra information which isn’t necessary for the model to learn. So, the first step after the preparation of the dataset is to simplify the images by extracting the important information and throwing away non-essential information.
By extracting important colors or image segments, we can transform complex and large image data into smaller sets of features. This allows the computer vision model to learn faster. Feature extraction can be done using traditional methods or deep neural networks.
In traditional machine learning problems, you spend a good amount of time in manual feature selection and engineering. In this process, we rely on our domain knowledge (or partnering with domain experts) to create features that make the machine learning algorithms work better. Some of the traditional methods used for feature extraction are:
- Harris Corner Detection: Uses a Gaussian window function to detect corners.
- Scale-Invariant Feature Transform (SIFT): Scale-invariant technique for corner detection.
- Features from Accelerated Segment Test (FAST): A faster version of SIFT for corner detection and mainly used in real-time applications.
In a deep learning model, we don’t need to extract features from the image manually. The network automatically extracts features and learns their importance on the output by applying weights to its connections. You feed the raw image to the network and, as it passes through the network layers, it identifies patterns within the image to create features. A few examples of neural networks that are used as feature extractors are:
- Superpoint: Self-Supervised Interest Point Detection and Description: Proposes a fully convolutional neural network that computes SIFT-like interest point locations and descriptors in a single forward pass.
- D2-Net: A Trainable CNN for Joint Description and Detection of Local Features: The paper proposes a single CNN that is both a dense feature descriptor and a feature detector.
- LF-Net: Learning Local Features from Images: The paper suggests using a sparse-matching deep architecture and uses an end-to-end training approach on image pairs having relative pose and depth maps. They run their detector on the first image, find the maxima and then optimize the weights so that when run on the second image, they produce a clean response map with sharp maxima at the right locations.
Conclusion
We went through the steps you can follow while curating your dataset. Our next focus was on choosing which data you should label and the subset of data you should use for training your computer vision model. We also looked at how you can use open-source tools to help us with data processing. Lastly, we discussed the next steps you can take once you’ve processed your data and what needs doing from there.
Take a look at the links below for some further ideas for what to do once you’ve created your training dataset!
Frequently asked questions
Encord offers robust tools for data labeling, model training, and feature detection, which are crucial for processing earth observation data. These features help simplify workflows, enhance accuracy in data interpretation, and ultimately support the automation of data verification processes in projects like Phantom.
Encord differentiates itself from competitors by offering native support for hyperspectral imaging, which is often lacking in other solutions. This focus allows for more efficient data handling and annotation processes, making it a suitable choice for organizations looking to leverage hyperspectral data effectively.
Encord enhances video data curation by streamlining the process from data collection to model training, offering a more scalable solution compared to traditional methods like manual curation using Jupyter notebooks or other open-source tools. This efficiency enables users to focus on high-impact training data.
Encord provides advanced annotation tools that streamline the data management process for teams working on computer vision and machine learning projects. With features like project management and integration with multiple data manipulation methods, Encord enhances the efficiency of the annotation process.
Encord includes features that allow users to interactively curate video data, utilizing custom metrics thresholds to identify key moments within videos. This capability is crucial for users looking to sift through large datasets and extract only the most important segments relevant to their projects.
Encord provides various approaches, including Z-core based methods and dataset core methods, to help users shortlist and prioritize images for annotation. This ensures that the most relevant and beneficial images are annotated first, enhancing the efficiency of the training process.
Encord's platform supports a wide range of data types, including images and videos, enabling users to annotate diverse datasets for various computer vision applications. This flexibility is essential for accurately training machine learning models across different sectors.
Encord utilizes various sensor data, including lidar and vision data, to enhance logistics operations. The platform focuses on modeling these data types to improve robot navigation and obstacle detection, thereby optimizing warehouse functionality and efficiency.
Encord supports a variety of data types, including both images and videos. This flexibility allows teams to work on diverse projects, ranging from robotics to biometrics, ensuring that all relevant data can be annotated and curated effectively.
Encord provides advanced capabilities for automated content collection using computer vision. This includes the ability to automatically gather and process data from various sports, facilitating efficient data management and analysis.