Grounding-DINO + Segment Anything Model (SAM) vs Mask-RCNN: A comparison

Are you looking to improve your object segmentation pipeline with cutting-edge techniques?
Look no further!
In this tutorial, we will explore zero-shot object segmentation using Grounding-DINO and Segment Anything Model (SAM) and compare its performance to a standard Mask-RCNN model.
We will delve into what Grounding-DINO and SAM are and how they work together to achieve great segmentation results.
Plus, stay tuned for a bonus on DINO-v2, a groundbreaking self-supervised computer vision model that excels in various tasks, including segmentation.

What is Zero-Shot Object Segmentation?
Zero-shot object segmentation offers numerous benefits in computer vision applications. It enables models to identify and segment objects within images, even if they have never encountered examples of these objects during training.
This capability is particularly valuable in real-world scenarios where the variety of objects is vast, and it is impractical to collect labeled data for every possible object class.
By leveraging zero-shot object segmentation, researchers and developers can create more efficient and versatile models that can adapt to new, unseen objects without the need for retraining or obtaining additional labeled data.
Furthermore, zero-shot approaches can significantly reduce the time and resources required for data annotation, which is often a major bottleneck in developing effective computer vision systems.
In this tutorial, we will show you how you can implement a zero-shot object segmentation pipeline using Grounding-DINO and Segment Anything Model (SAM), a SOTA visual foundation model from Meta. In the end, we will compare its segmentation performance to a standard Mask-RCNN model.
First, let’s investigate separately what these foundational models are about.

What is Grounding DINO?
In the paper "Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection" the authors propose a method for improving open-set object detection.
So, what is this open-set object detection?
Open-set object detection is a subtask of object detection in computer vision, where the goal is to identify and localize objects within images. However, unlike traditional object detection, open-set object detection recognizes that the model may encounter objects from classes it has not seen during training. In other words, it acknowledges that there might be "unknown" or "unseen" object classes present in real-world scenarios.
The challenge in open-set object detection is to develop models that can not only detect known objects (those seen during training) but also differentiate between known and unknown objects and potentially detect and localize the unknown objects as well. This is particularly important in real-world applications where the variety of object classes is immense, and it is infeasible to collect labeled training data for every possible object type.
To address this challenge, researchers often employ various techniques, such as zero-shot learning, few-shot learning, or self-supervised learning, to build models capable of adapting to novel object classes without requiring exhaustive labeled data.
So, what is Grounding-DINO?
In the Grounding-DINO paper, the authors combine DINO, a self-supervised learning algorithm, with grounded pre-training, which leverages both visual and textual information. This hybrid approach enhances the model's ability to detect and recognize previously unseen objects in real-world scenarios. By integrating these techniques, the authors demonstrate improved performance on open-set object detection tasks compared to existing methods.
Basically, Grounding-DINO accepts a pair of images and text as input and outputs 900 object boxes along with their objectness confidence. Each box has similarity scores for each word in the input text. At this point, there are two selection processes:
- Algorithm chooses the boxes that are above the box_threshold.
- For each box, the model extracts the words whose similarity scores are higher than the defined text_threshold.
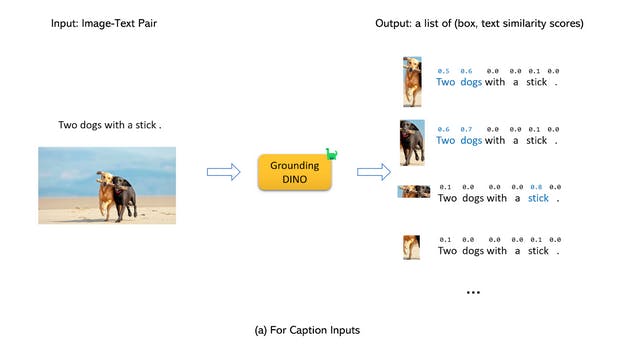
So, with Grounding-DINO we can get the bounding boxes; however, this only solves half of the puzzle.
We also want to get the objects segmented, so we will employ another foundation model called the Segment Anything Model (SAM) to use the bounding box information to segment the objects.
What is Segment Anything Model (SAM)?
Last week Meta released the Segment Anything Model (SAM), a state-of-the-art image segmentation model that will change the field of computer vision.

SAM is based on foundation models. It focuses on promptable segmentation tasks, using prompt engineering to adapt to diverse downstream segmentation problems.
SAM’s design hinges on three main components:
- The promptable segmentation task to enable zero-shot generalization.
- The model architecture.
- The dataset that powers the task and model.
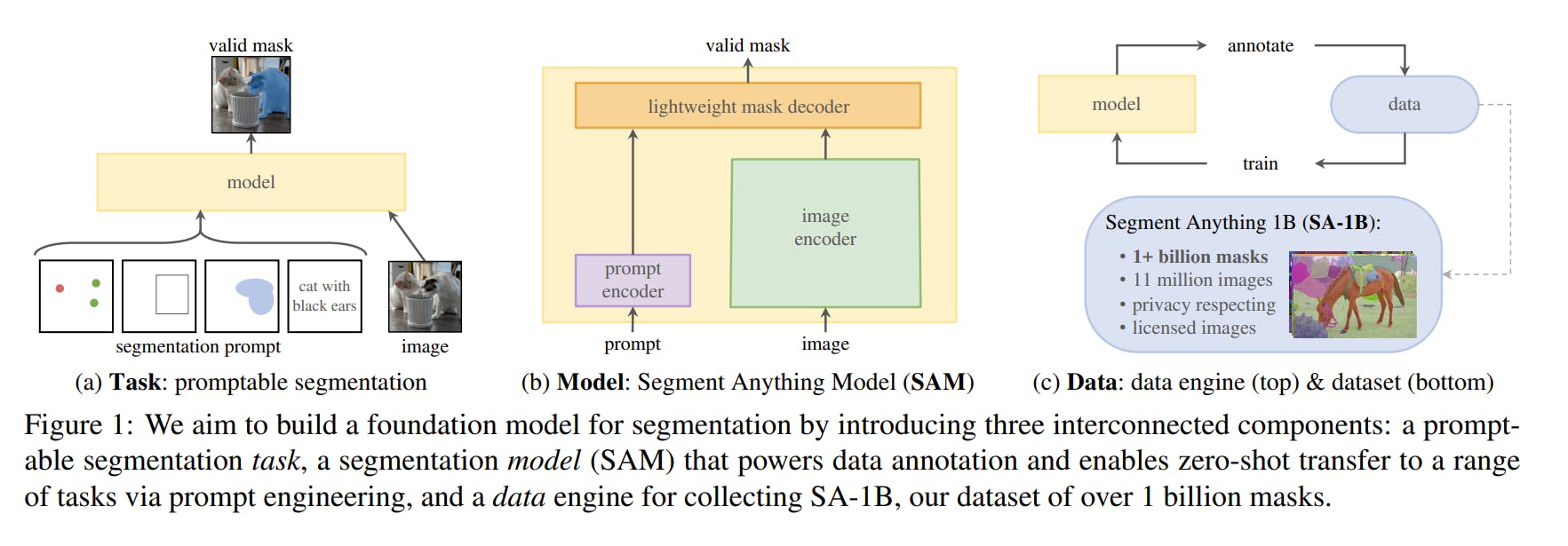
 Learn about all the details of SAM in the full explainer.
Learn about all the details of SAM in the full explainer.Merging Grounding DINO and SAM
Now we know that given a text prompt and an image, Grounding-DINO can return the most relevant bounding boxes for the given prompt. We also know that given a bounding box and an image, SAM can return the segmented mask inside the bounding box. Now we will stack these two pieces together and given an image and text prompt (which will include our classes) we will get the segmentation results!
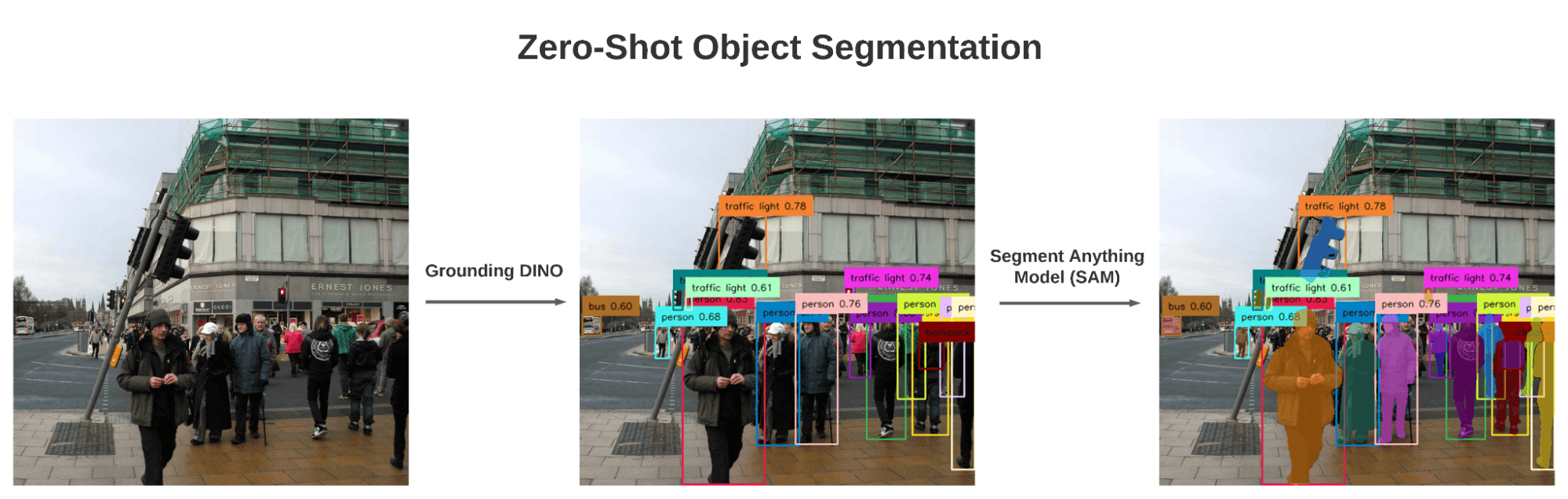
Baseline Results
In Encord Active, we already have predictions for some well-known datasets (COCO, Berkeley Deep Drive, Caltech101, Covid-19 etc.). So for the baseline result, we already know the result in advance. These model performances were obtained by training a Mask-RCNN model on these datasets and inference on the test sets. Then we imported model predictions into Encord-Active to visualize the model performance. In this post, we will oenly cover two datasets: EA-quickstart (200-image subset of COCO) and Berkely DeepDrive (BDD):
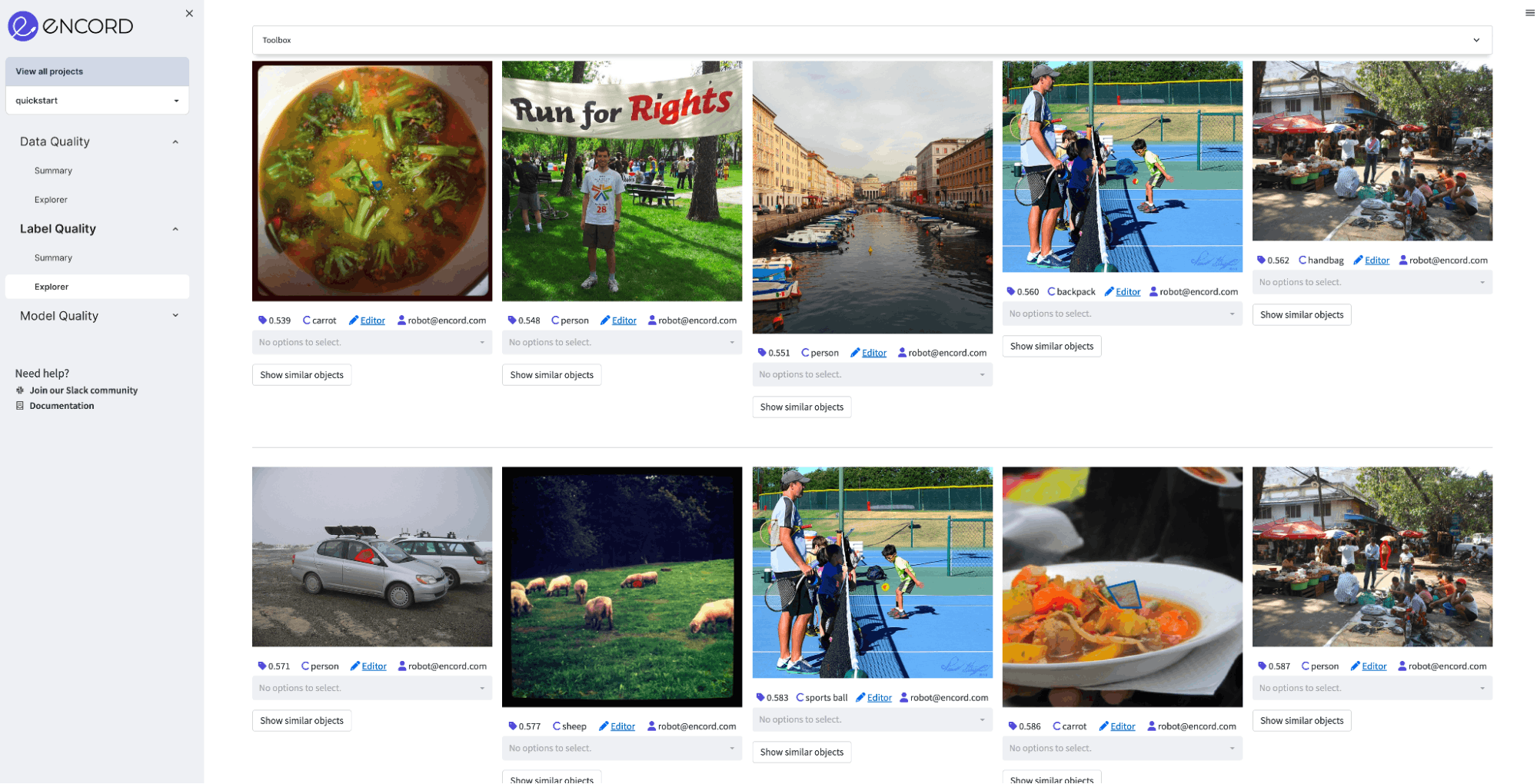
Exploring quickstart project in Encord Active
Exploring BDD project in Encord Active
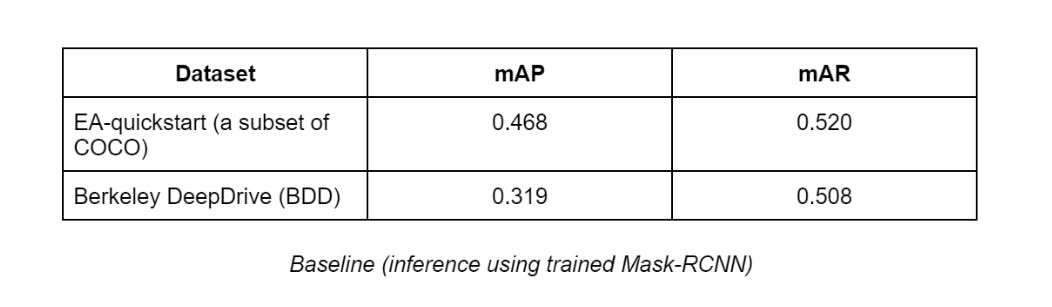
Baseline (inference using trained Mask-RCNN)
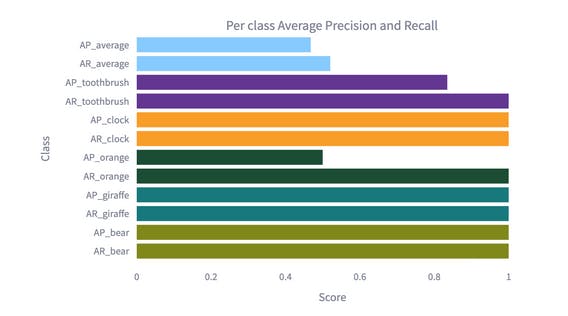
The top 5 best performing classes ranked according to the Average-Recall (quickstart)
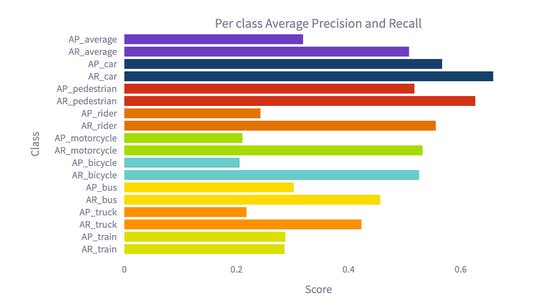
The top 5 best performing classes ranked according to the Average-Recall (BDD)
Grounding DINO + SAM result
We first convert Encord ontology to a text prompt by getting the name of the classes and concatenating them with a period. So, our text prompt for the Grounding-DINO will follow the following pattern:
“Class-1 . Class-2 . Class-3 . … . Class-N”
When the Grounding-DINO is prompted with the above text, it assigns the given classes into a bounding box if they are above a certain threshold. Then we feed the image and predicted bounding box to SAM to get the segmentation result.
Once we do this for all images in the dataset and get the prediction results, we import these predictions into Encord-Active to visualize the model performance. Here are the performance results for the Grounding-DINO+SAM.

Grounding DINO + SAM
The top 5 best performing classes ranked according to the Average-Recall (EA-quickstart)
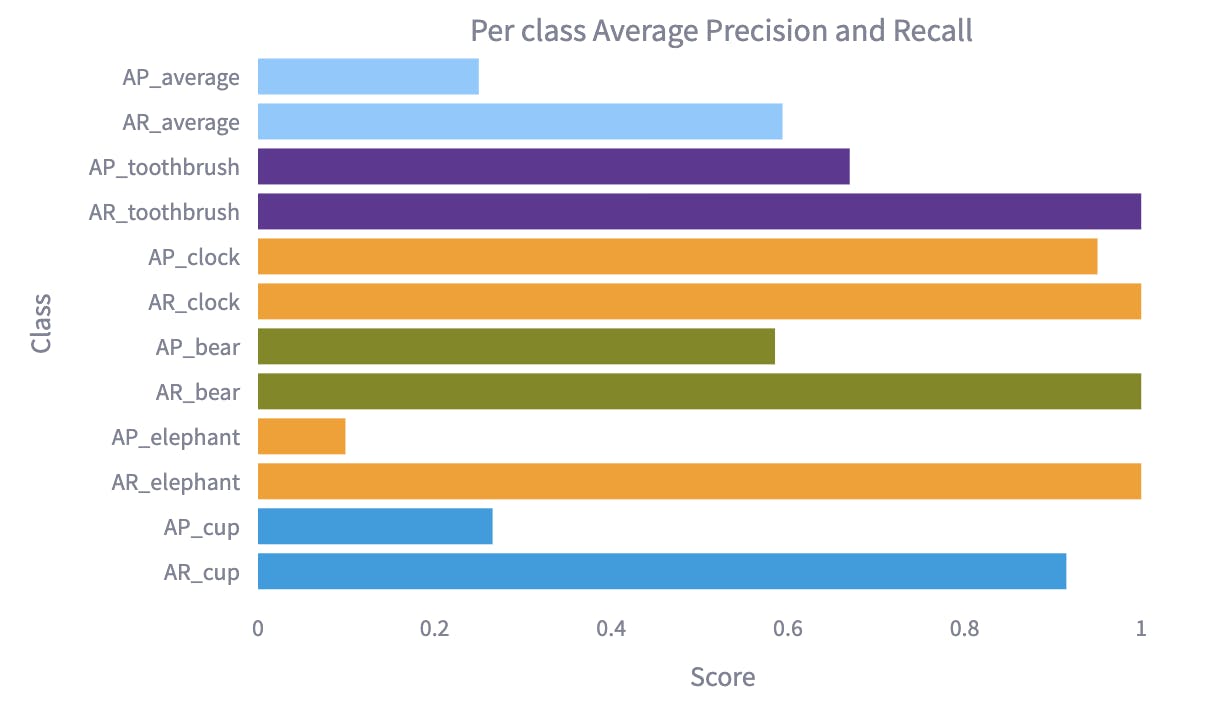
The top 5 best-performing classes ranked according to the Average-Recall (BDD)
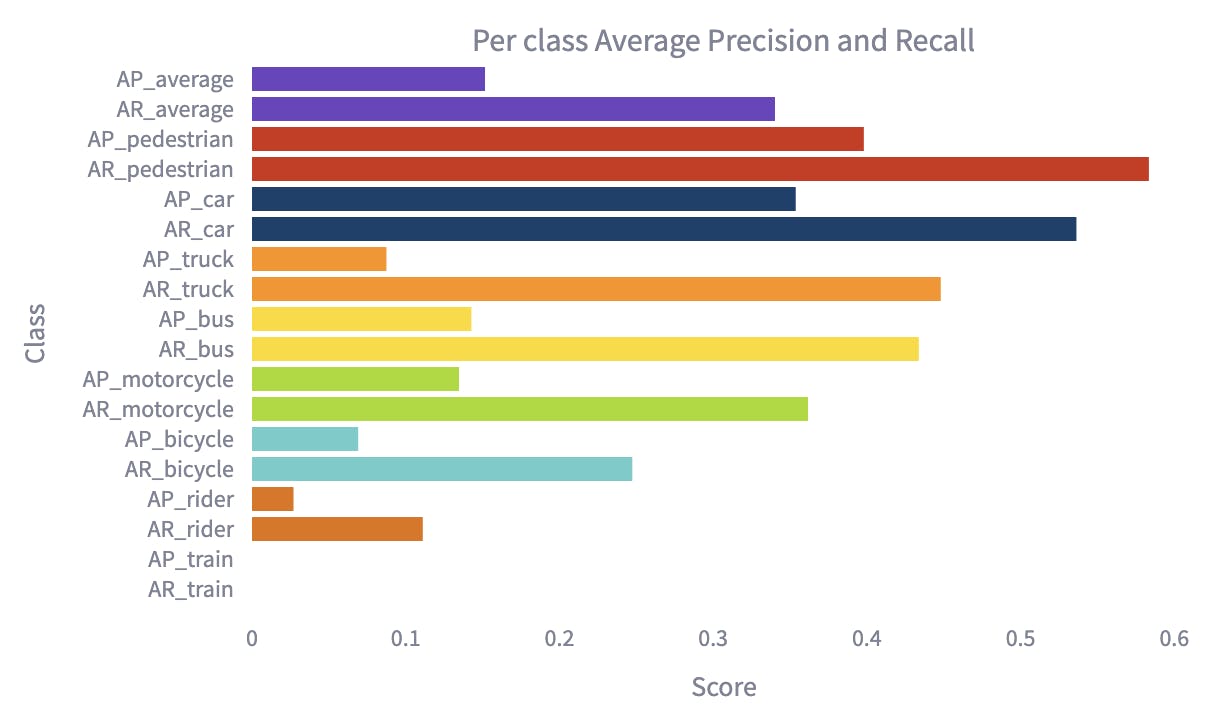
Discussion
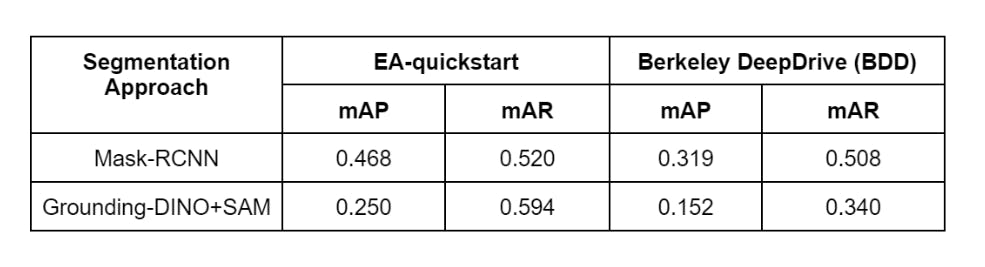
Although Grounding DINO + SAM is behind the Mask RCNN in terms of performance, remember that it is not trained on this dataset at all. So, its zero-shot capabilities are very strong in that sense. Moreover, we have not tuned any of its parameters, so there is probably room for improvement.
Now, let’s investigate the performance of Grounding-DINO+SAM in Encord Active and get insights on prediction results. First, let’s check what are the most important metrics for the model performance of BDD:
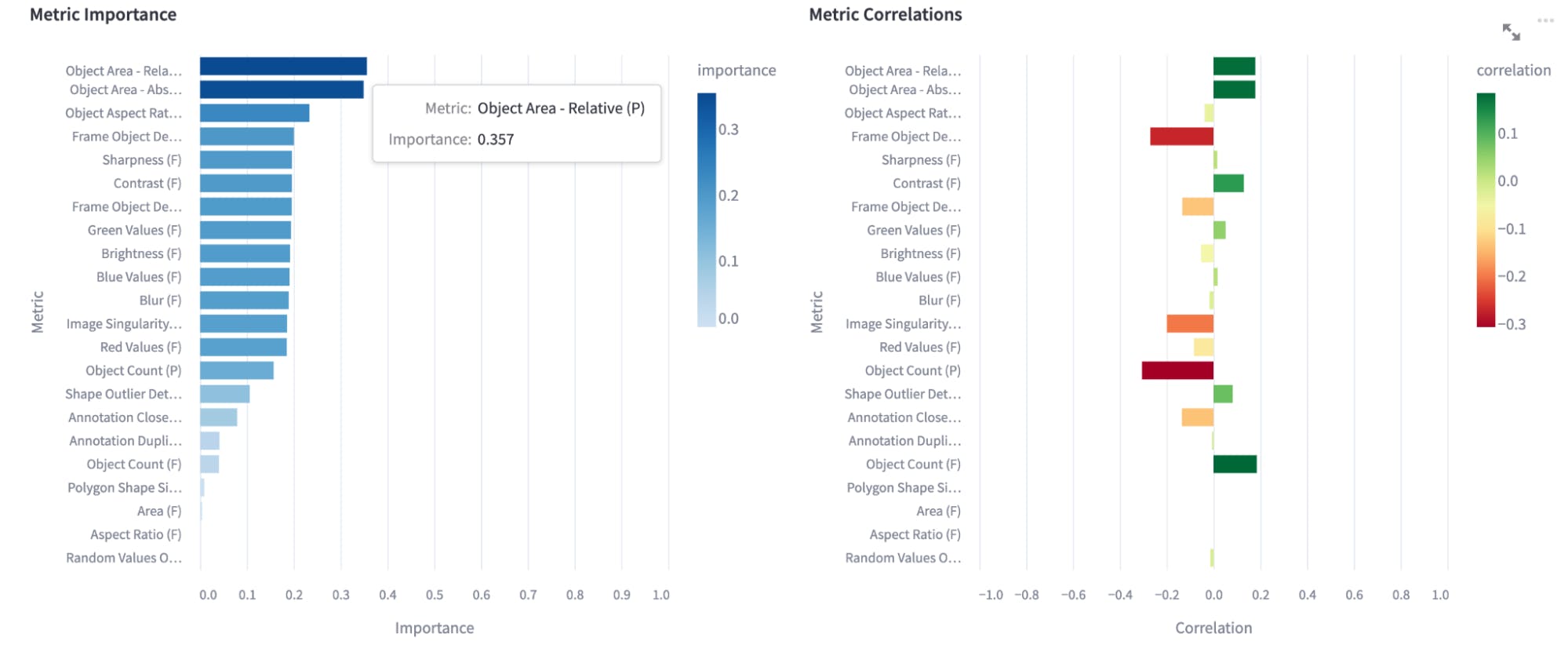
Encord Active demonstrates that the most important metrics for the model performance are related to the predicted bounding box size. As the graph on the right-hand side shows, the size has a positive correlation with the performance.
Let’s investigate this metric more by examining performance by the Object Area - Relative plot.
To do that using Encord Active, go to the Performance by Metric tab under the Model Quality and choose Object Area - Relative (P) metric under the Filter tab.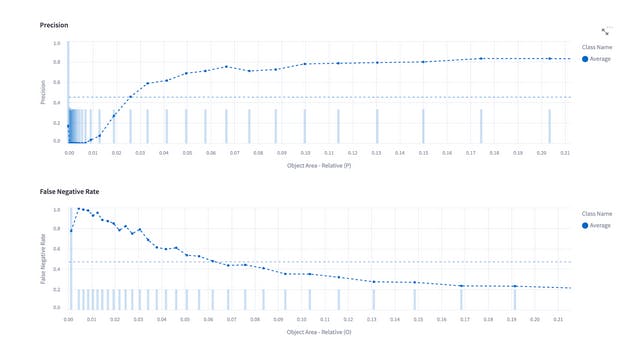
As the above graph demonstrates, there are certainly some problems with the small objects.
The upper plot shows the precision (TP/TP+FP) with respect to the predicted object size. So when the predictions are small, the ratio of false positives to true positives is higher which leads to low precision. In other words, the model must generate many small bounding boxes, which is wrong. The conclusion we need to draw from this graph is that we need to check our small predictions and investigate the patterns among them.
The lower plot shows the False Negative Rate (FN\FN+TP) with respect to the object size. It is clear that model cannot detect small objects. So we need to review the small objects and try to understand what could be the possible reason.
To review the small objects, go to the Explorer page under the Model Quality tab and filter the False Positive and False Negative samples according to the Object Area - Relative (P) metric.
An example of a very small segmented region, which is a false positive

An example of a (very problematic) false negative
As seen from the examples above, Encord Active can clearly outline the issues in the Grounding-DINO+SAM method. As a next step, our zero-shot object segmentation pipeline can be fine-tuned to improve its performance. Possible actions to improve performance based on the above insights are:
- Very small bounding box predictions obtained from Grounding-DINO can be eliminated by a size threshold.
- Confidence value for the boxness_threshold can be reduced to obtain more candidate bounding boxes to increase the probability of catching the ground truths.
Bonus: DINO-v2
Meta AI introduced DINO-v2, a groundbreaking self-supervised computer vision model, delivering unmatched performance without the need for fine-tuning. This versatile backbone is suitable for various computer vision tasks, excelling in classification, segmentation, image retrieval, and depth estimation.
Built upon a vast and diverse dataset of 142 million images, this cutting-edge model overcomes the limitations of traditional image-text pretraining methods. With efficient implementation techniques, DINOv2 delivers twice the speed and uses only a third of the memory compared to its predecessor, enabling seamless scalability and stability. The next blog post will incorporate DINO-v2 into Grounding-SAM for better object detection.
Conclusion
We have explored the powerful zero-shot object segmentation pipeline using Grounding-DINO and Segment Anything Model (SAM) and compared its performance to a standard Mask-RCNN model.
Grounding-DINO leverages grounded pre-training and self-supervised learning to improve open-set object detection, while SAM focuses on promptable segmentation tasks using prompt engineering.
Although Grounding DINO + SAM is currently behind Mask-RCNN in terms of performance, its zero-shot capabilities are impressive, and there is potential for improvement with parameter tuning. Additionally, with DINO-v2 just out, it looks promising. We will run that experiment next and post the results here when finished.
Frequently asked questions
Encord supports a variety of data types, including 2D, 3D, LiDAR, and radar, which can be generated from different sensor stacks. The platform is adaptable to the specific requirements of each use case, allowing for tailored solutions based on the type of data and the problem statement at hand.