How to Use OpenCV With Tesseract for Real-Time Text Detection

Product Manager at Encord
Real-time text detection is vital for text extraction and Natural Language Processing (NLP). Recent advances in deep learning have ushered in a new age for natural scene text identification. Apart from formats, natural texts show different fonts, colors, sizes, orientations, and languages (English being the most popular). It often overwhelms readers, especially those with visual impairments. Natural texts also include complex backgrounds, multiple photographic angles, and illumination intensities, creating text recognition and detection barriers. Text detection simplifies decoding videos, images, and even handwriting for a machine.
In this article, you will work on a project to equip a system to perform real-time text detection from a webcam feed. But, for that, your machine must include a real-timeOCR processing feature. The same OCR powers your applications to perform real-time text detection from the input images or videos.
Ready? Let’s start by understanding the problem and project scope.
Problem Statement and Scope
In this section, you will learn about the use case of text recognition in video streams, its challenges, and, more specifically, how to overcome them.
Real-time Text Detection from Webcam Feed
The requirement for real-time text detection from camera-based documents is growing rapidly due to its different applications in robotics, image retrieval, intelligent transport systems, and more. The best part is that you can install real-time text detection using the webcam on your computer. OCR-based tools like Tesseract and OpenCV are there to help you out in this regard.
Displaying the Detected Text on the Screen
There is no denying the fact that detecting oriented text in natural images is quite challenging, especially for low-grade digital cameras and mobile cameras. The common challenges include blurring effects, sensor noise, viewing angles, resolutions, etc.
Real-world text detection isn't without hurdles. Blurring effects, sensor noise, and varying viewing angles can pose significant challenges, especially for low-grade digital cameras. Overcoming these obstacles requires advanced techniques and tools.
Real-Time Text Detection Using Tesseract OCR and OpenCV
Text detection methods using Tesseract is simple, quick, and effective. The Tesseract OCR helps extract text specifically from images and documents. Moreover, it generates the output in a PDF, text file, or other popular format. It's open-source Optical Character Recognition (OCR) software that supports multiple programming languages and frameworks. The Tesseract 3x is even more competent as it performs scene text detection using three methods: word finding, line finding, and character classification to produce state-of-the-art results.
Firstly, the tool finds words by organizing the text lines into bubbles. These lines and regions are analyzed as proportional text or fixed pitch. Then, these lines are arranged by word spacing to make word extraction easier. The next step comprises filtering out words through a two-pass process. The first pass checks only if each word is understandable. If the words are recognizable, they will proceed with the second pass. This time, the words use an adaptive classifier where they are recognized more accurately. On the other hand, the Tesseract 4 adopts a neural network subsystem for recognizing text lines. This neural subsystem originated from OCRopus' Python-based LSTM implementation.
OpenCV (Open Source Computer Vision Library) is open-source for computer vision, image processing, and machine learning. Computer vision is a branch of artificial intelligence that focuses on extracting and analyzing useful information from images. This library allows you to perform real-time scene text detection and image and video processing with the scene text detector. This library has more than 2500 in-built algorithms. The function of these algorithms is to identify objects, recognize images, text lines, and more.
So, let’s learn how Tesseract OCR and OpenCV help with real-time text detection in this tutorial.
Data Collection and Preprocessing
The preprocessing of a video or image consists of noise removal, binarization, rescaling, and more. Thus, preprocessing is necessary for acquiring an accurate output from the OCR.
The OCR software imposes several techniques to pre-process the images and videos:
- Binarization is a technique that converts a colorful or grayscale image into a binary or black-and-white image, enhancing the quality of character recognition. It separates text or image components from the background, making identifying and analyzing text characters easier.
- De-skewing is a technique that ensures proper alignment of text lines during scanning. Despeckling is used for noise reduction, reducing noise from multiple resources. Word and line detection generate a baseline for shaping characters and words. Script recognition is essential for handling multilingual scripts, as they change at the level of the words.
- Character segmentation or isolation is crucial for proper character isolation and reconnection of single characters due to image artifacts. Techniques for fixed-pitch font segmentation require aligning the image to a standard grid base, which includes fewer intersections in black areas. Techniques for proportional fonts are necessary to address issues like greater whitespace between letters and vertically intersecting more than one character.
Two basic OCR algorithms for text recognition through computer vision techniques are matrix matching and feature extraction.
- Matrix matching compares an image to a glyph pixel-by-pixel, known as image correlation or pattern recognition. The output glyph is in the same scale and a similar font.
- The feature extraction algorithm breaks glyphs into features such as lines, line intersections, and line directions, making the recognition process more efficient and reducing the dimensionality of the texts. Again, the k-nearest neighbors algorithm compares the image features with the stored glyphs to choose the nearest match. The glyphs are symbolic characters or figures recognized as text after an OCR is conducted over an image.
Capturing Video From the Webcam Using OpenCV
OpenCV can detect text in different languages using your computer’s webcam. The video streaming process in OpenCV runs on a dedicated thread. It reads live frames from the webcam and caches the new videos in memory as a class attribute.
The video script ingests real-time OCR effects by multi-threading. When the OCR runs in the background, the multi-threading improves the processing by enabling real-time video streaming. The OCR thread updates the detected texts and the boxes, giving them prominent visibility.

🎥 Interested in video annotation? Read our full guide to video annotation in computer vision.
Set Up Tesseract OCR and Specify its Executable Path
There are several reasons to install Python-tesseract to proceed with your real-time text detection. Its OCR feature easily recognizes and encodes texts from your video. Moreover, it can read many images, such as PNG, GIF, and JPEG. Thus, it can be used as an individual script.
To integrate Tesseract into your Python code, you should use Tesseract’s API. It supports real concurrent execution when you use it with Python’s threading module. Tesseract releases GIL (Generic Image Library) while processing an image.
First of all, install the Tesseract OCR in your environment:
pip install pytesseract
Then, start importing the required libraries
import cv2 import pytesseract import numpy as np from PIL import ImageGrab
Set up the executable path for Tesseract OCR
# Set the path to the Tesseract executable for Windows OS pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
Function to Capture the Screen
The `capture_screen` function captures the screen content using `ImageGrab.grab` from the Pillow library. This function captures a specific screen region defined by the `bbox` parameter. It converts the captured image from RGB to BGR format, which is suitable for OpenCV.
# Function to capture the screen
def capture_screen(bbox=(300, 300, 1500, 1000)):
cap_scr = np.array(ImageGrab.grab(bbox))
cap_scr = cv2.cvtColor(cap_scr, cv2.COLOR_RGB2BGR)
return cap_scrWebcam Initialization
The code initializes the webcam (if available) by creating a VideoCapture object and setting its resolution to 640x480.
# Initialize the webcam
cap = cv2.VideoCapture(0)
cap.set(3, 640)
cap.set(4, 480)
while True:
# Read a frame from the webcam
ret, frame = cap.read()Text Detection and Processing
The output stream for real-time text detection can be a file of characters or a plain text stream. However a sophisticated OCR stores the original layout of a page. The accuracy of an OCR can be boosted when there is a lexicon constraint in the output. Lexicons are lists of words that can be presented in a document. However, it becomes problematic for an OCR to improve detection accuracy when the quantity of non-lexical words increases. It is, however, possible to assume that a few optimizations will speed up OCR in many scenarios, like data extraction from a screen.
Additionally, the k-nearest-neighbor analysis (KNN) corrects the error from the words that can be used together. For example, it can differentiate between 'United States of America' and 'United States'.
Now, you will learn about automated text extraction after detecting it with Tesseract OCR.
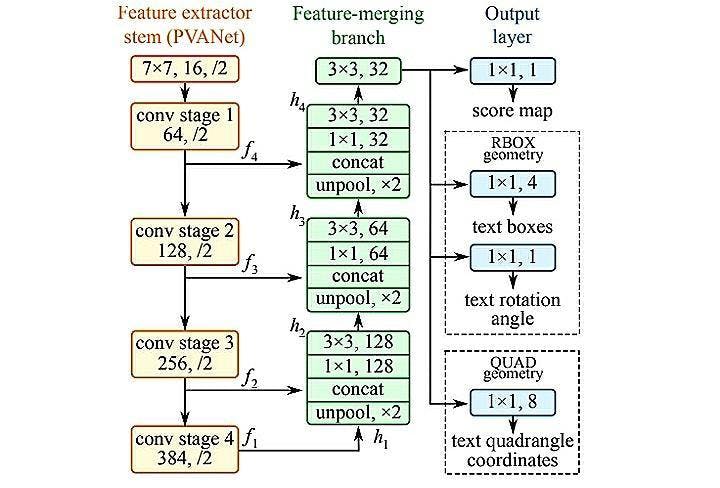
Applying Tesseract OCR to Perform Text Detection on Each Frame
In the text detection step, the Tesseract OCR will annotate a box around the text in the videos. Then, it will show the detected text above the box. But this technique works by breaking the video frame-by-frame and applying the tesseract detection to the video frame. The caveat here is that sometimes, you may experience difficulties in text detection due to the abrupt movements of the video objects.
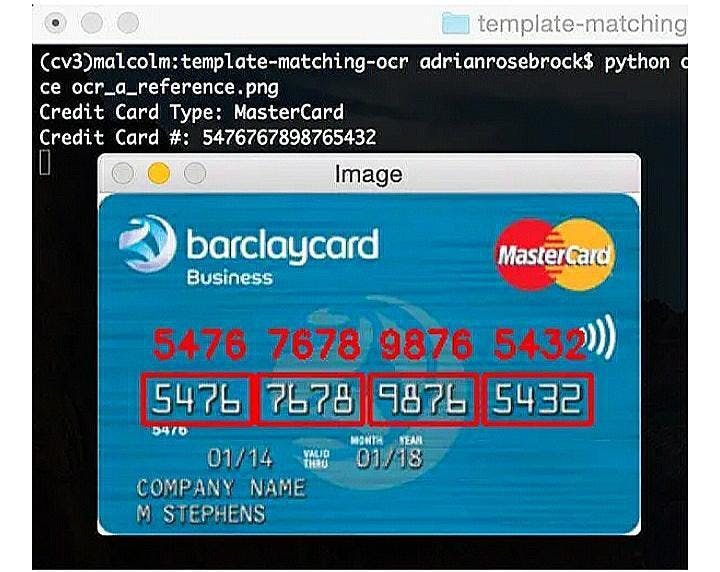
Text detection through Tesseract OCR
Main Loop - Real-Time Text Detection
The following code enters a loop to capture frames from the webcam (or screen capture). It performs text detection on each frame using Tesseract OCR irrespective of the frame rate (fps).
# Perform text detection on the frame using Tesseract OCR recognized_text = pytesseract.image_to_string(frame)
Bounding Box Detection
To draw bounding boxes around the detected text, the code utilizes Tesseract's built-in capabilities for bounding box detection. It uses `pytesseract.image_to_data` with the `pytesseract.Output.DICT` option to obtain information about individual text boxes. The code then loops through the detected boxes, and for each box with a confidence level greater than 0, it draws a green rectangle using `cv2.rectangle`
# Perform bounding box detection using Tesseract's built-in capabilities
d = pytesseract.image_to_data(frame, output_type=pytesseract.Output.DICT)
n_boxes = len(d['text'])
for i in range(n_boxes):
if int(d['conf'][i]) > 0:
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
frame = cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)Detected text is displayed on the frame with green and drawn with `cv2.putText`
# Draw the detected text on the frame frame_with_text = frame.copy() frame_with_text = cv2.putText(frame_with_text, detected_text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
The Google Cloud Vision API is an example of a text extraction API. It can detect and extract text from an image. It has two annotation features to support an OCR. The annotations are:
- TEXT_DETECTION: It detects and extracts text from any type of image. For example, you might consider a photograph related to a signboard about traffic rules. The JSON of the API formats and stores strings and individual words from the text of that image. Also, it creates bounding boxes around the texts.
- DOCUMENT_TEXT_DETECTION: The vision API uses this annotation to extract text instancess from a document or dense text. The JSON formats and stores the extracted paragraph, page, word, block, and break information. Four vertices form a quadrilateral bounding box with orientation information in the text instance annotations.
The vision API detects text from a local image file through the feature detection process. So, when you send REST requests to the API, it should be a Base64 encoding string for the image file's contents within the body of your request.
Base64 is a group of schemes that encodes binary data into readable text for an image. It represents binary data in a 24-bit sequence. This 24-bit sequence can be further represented as four 6-bit Base64 digits. Base64 reliably carries binary data throughout channels that support text contents.
Real-Time Display and Video Output
Generally, the text in a video appears in multiple frames. So, you need to detect and recognize the texts present in each frame of the video. The OCR software converts the text content from the video into an editable format. The alphanumeric information in the video must be converted into its ASCII equivalent first. Then, they will be converted to readable text. This way, it detects texts from videos and other imagery formats.
Modern OCR systems, such as Tesseract, are designed to automatically extract and recognize text from videos. The OCR identifies the locations of text within the video and proceeds to extract strokes from the segmented text regions, taking into account factors like text height, alignment, and spacing. Subsequently, the OCR processes these extracted strokes to generate bounding boxes, within which the recognized texts are displayed upon completion of the process. Text localization in real time text detection using Tesseract is a crucial step in optical character recognition (OCR) systems. By accurately identifying the location of text within an image or video frame, Tesseract enables the extraction and analysis of textual information. This process involves employing advanced computer vision techniques to detect and outline text regions, allowing for efficient recognition and subsequent interpretation of the detected text. This is often done using an image annotation tool.

Display the Detected Text
The processed frame with the detected text and bounding boxes is displayed using `cv2.imshow`.
# Display the frame with detected text
cv2.imshow("Frame with Detected Text", frame_with_text)User Interaction
The model displays real-time video with a detected text overlay until the user presses the 'q' key. Upon pressing 'q', the loop exits, the webcam is released, and the OpenCV window is closed.
# Exit the loop when 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
self.cap.release()
self.video_output.release()
cv2.destroyAllWindows()
def playback(self):Moreover, you can customize your outputs by using white-listing and black-listing characters. When you choose white-listing characters, Tesseract only detects the characters white-listed by your side. It ignores the rest of the characters in the video or image. Also, you can use black-list characters when you don't want to get the output of some specific characters. Tesseract will black-list them. So, it will not produce the output for these characters.
Here is the link to the full code on the GitHub repository.
OCR for Mobile Apps
If you need real-time text detection from a mobile scanning app, you must have an OCR as part of that scanning app. The best mobile scanning OCR apps, like Image to Text, usually have these features -
- Scanning efficiency: A mobile OCR app must focus on every region of a document. Even the sensor can accurately detect the borders of the document. Also, it doesn’t take too much time to scan the document.
- Modes of scanning: You can get different scanning modes through this app, such as IDs, books, documents, passports, and images.
- Document management: It supports a file management activity by saving, organizing, printing, sharing, and exporting digitized files.
- Customization: You can customize your document scanning by adding a signature, text, watermark, or password protection.
- Accuracy: The OCR app emphasizes document digitization. Thus, it produces digitized text from a document without too much delay.
For mobile scanning apps, integrating OCR is essential. An ideal OCR app should scan efficiently and offer various scanning modes, robust document management, customization options, and high accuracy in digitizing text from documents.
Wrapping Up
So, you have learned text detection in real-time with Tesseract OCR, OpenCV, and Python. OCR software uses text detection algorithms to implement real-time text detection. Moreover, OCR software can solve other real-world problems, such as - object detection from video and image datasets, text detection from document scanning, face recognition, and more.
Real Time Text Detection - OpenCV Tesseract: Key Takeaways
Real-time text detection is crucial for applications involving text extraction and NLP applications, dealing with diverse fonts, colors, sizes, orientations, languages, and complex backgrounds.
- Tesseract OCR and OpenCV are open-source tools for real-time text detection.
- Preprocessing steps in OCR include binarization, de-skewing, despeckling, word and line detection, script recognition, and character segmentation.
- OCR accuracy can be enhanced with lexicon constraints and near-neighbor analysis.
- Video frames can be processed in real-time for text detection and recognition, converting alphanumeric information into editable text.
- Customization options, such as white-listing and black-listing characters, are available in OCR for tailored text detection.
Frequently asked questions
Real-time text detection works by utilizing advanced computer vision algorithms and machine learning techniques to analyze and interpret the visual data captured by a camera in real-time. These algorithms identify patterns and features within the image that correspond to text, and then extract and process this text for various applications such as translation, transcription, or augmented reality overlays. The accuracy and speed of real-time text detection heavily rely on the quality of the algorithms used, as well as the processing power of the device or cloud infrastructure supporting it.
One key challenge in real-time text detection is dealing with variations in different font styles, and background clutter, along with different lighting environments can affect the visibility and clarity of the text. Another challenge is handling text that may be distorted, skewed, or occluded by other objects in the image, which requires robust algorithms capable of accurately detecting and extracting text under such conditions. Moreover, accurately detecting and processing text in different languages or scripts can also be a challenge.
Some industries that benefit most from real-time text detection include retail, where it can be used for price comparison and product information; transportation, where it can assist with license plate recognition and signage interpretation; and healthcare, where it can aid in medical document processing and patient identification. Real-time text detection also has applications in the gaming, education, and advertising industries.
Some best practices for implementing real-time text detection include using high-quality cameras or scanners to capture clear and accurate text, utilizing advanced algorithms and machine learning techniques to improve accuracy and speed, and regularly updating and maintaining the software to ensure optimal performance. It is also important to consider privacy and security measures when handling sensitive text data in industries such as healthcare or finance. Furthermore, conducting thorough testing and validation processes can help identify any potential issues or limitations before deploying the system.
AI has revolutionized real-time text detection technologies by enabling faster and more accurate recognition of text in various languages and fonts. With AI, these technologies can adapt and learn from vast amounts of data, continuously improving their performance over time. Additionally, AI-powered algorithms can detect and correct errors in real-time, enhancing the overall efficiency and reliability of text detection systems.
Yes, Encord includes models that can perform Optical Character Recognition (OCR) to automatically extract text from images and videos. This feature streamlines the process of analyzing text content in visual media.