Few Shot Learning in Computer Vision: Approaches & Uses

Supervised learning once dominated the artificial intelligence (AI) space, where the only way to train a deep neural network was to use an extensive amount of labeled data. However, this approach encounters significant hurdles in complex industrial and research domains, such as advanced computer vision (CV) and natural language processing (NLP) tasks.
The primary challenges include the scarcity of labeled data, the high cost of annotating complex available datasets, and the emergence of new data categories in specific domains like healthcare, where data on new diseases makes traditional CV models obsolete.
To overcome these challenges, the AI community has pivoted towards innovative frameworks allowing effective model training with limited data. Few-shot learning (FSL) emerges as a pivotal solution, creating scalable CV systems that learn from only a handful of samples. This revolutionary change leverages prior knowledge and meta-learning techniques to achieve robust performance, even in data-constrained environments.
This article will discuss the approaches to few-shot learning (FSL) and its wide-ranging applications, highlighting its critical role in advancing AI capabilities with minimal data. You will learn about:
- Different few-shot learning variations.
- Few-shot learning classification algorithms.
- Few-shot detection algorithms.
Before getting into the details, let’s first discuss a few fundamental concepts regarding what FSL is, how it works, its relationship with meta-learning, and essential terminology used in the AI community to describe FSL frameworks.
What is Few-shot Learning?
FSL is an approach for developing machine learning (ML) algorithms with only a few samples in the training datasets. This approach is distinct from traditional supervised learning, which relies on large volumes of data, by focusing on the ability to generalize from very few examples using advanced techniques and prior knowledge.
Key Terminology in Few-shot Learning
FSL involves a few technical terms requiring explanation before describing how it works. These standard terms include support and query sets, k-way, n-shot, meta-learner, and base-learner.
Support set
A support set in FSL consists of data samples from a particular class for training an FSL model. It acts as the backbone for the FSL framework by exposing the model to real-world scenarios and allowing it to capture intricate data patterns from a few samples. For instance, the support set for two classes—dogs and cats—can contain six training data points with three samples per class.
Query set
The query set contains different samples from the same classes as the support set. It challenges the model with new examples to ensure it has learned the concept, not just memorized specifics. For instance, the query set can have images of dogs and cats with other breeds, colors, shapes, and backgrounds. The number of examples per class in the query set should be the same as in the support set.
N-way
N refers to the number of classes involved in the learning task (in the support and query sets). This means a setting where the support and query sets have two classes - cats and dogs - will be a 2-way classification problem (the model learns to distinguish between the two classes).
K-shot
K is the number of samples per class. An FSL model with three samples per class will be a 3-shot classification task (the model learns from three examples of each class).
The usual term is N-way K-shot. So, a situation where you have three samples per class with two classes is a 2-way 3-shot problem.
Meta-learner and Base-learner
In FSL, the meta-learner optimizes across tasks to improve the base learner's ability to adapt to new tasks quickly. A base learner, starting from a random initialization, focuses on specific tasks, with its performance feedback used to update the meta-learner.
Overall, FSL is not just about dealing with less data; it's about smartly leveraging what's available to make significant leaps in learning efficiency. Understanding these foundational concepts equips you to learn about FSL algorithms and their diverse applications. But first off, how does it work?
How Does Few-shot Learning Work?
Few-shot Learning (FSL) operates through a structured process known as an 'episode,' which simulates multiple training tasks. Each episode comprises a support set and a query set, representing a small sample from the overall dataset designed to teach and then test the model within a narrowly defined scope.
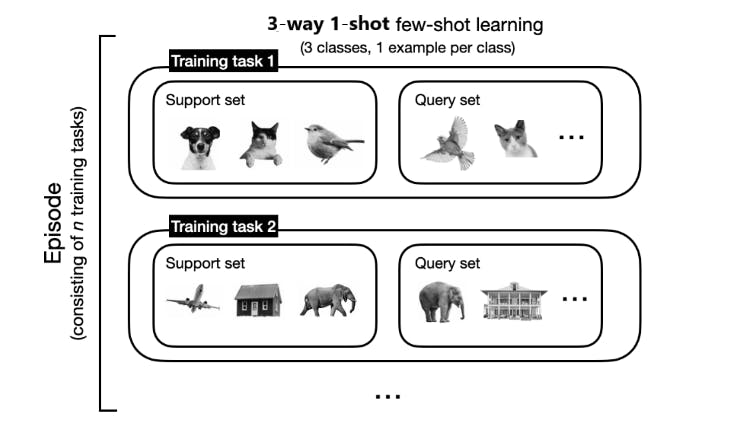
Episode - An episode consists of multiple training tasks
The FSL workflow begins with constructing a series of training tasks, each encapsulated in an episode. For a '3-way 1-shot' problem, each task is built around learning from one example of each of three different classes.
The model uses the support set to learn the distinctive features of each class from these single examples. Then, it attempts to classify new examples in the query set, which are variations of the same classes not seen during training.
Next, we evaluate the model through several test tasks. The essence of FSL is its ability to validate this learning in new, unseen classes during the evaluation phase. Each test task consists of a query and a support set. However, the sets contain samples of novel or unseen classes not present during training.
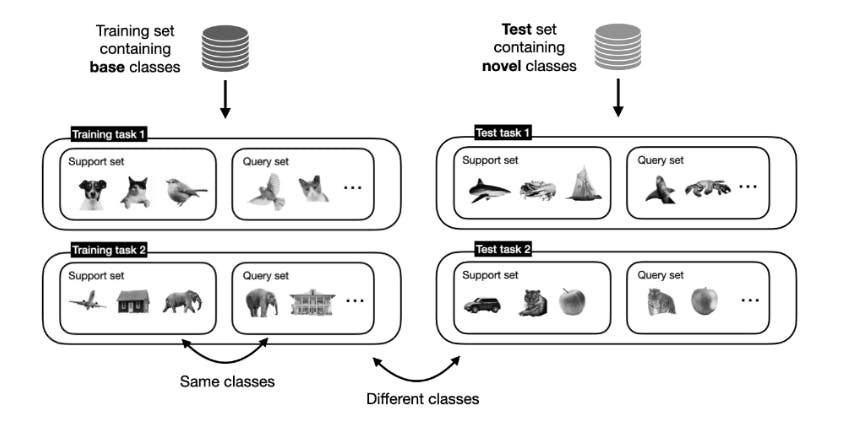
Training and Test Tasks containing different classes
Key to this process is the iterative exposure to varied episodes, each presenting unique classes and examples. This approach encourages the model to develop a flexible understanding of class characteristics and apply this knowledge to new classes it faces in test tasks.
Few-shot Learning Approaches
FSL adopts multiple approaches to address the challenge of learning from limited data, incorporating data-level, parameter-level, meta-learning, generative, and cross-modal techniques. Each strategy brings unique strengths to FSL, enabling models to generalize effectively across diverse scenarios.
Data-Level FSL Approach
The data-level approach is a straightforward concept that says to add more data in cases of insufficiently labeled examples. The premise is to use extensive, diverse datasets as a base for pre-training your model.
The samples in the base dataset will differ slightly from the support and query sets. The model learns general patterns from the base dataset during the training stage. You can then fine-tune the pre-trained model for novel classes with a few examples.
For instance, we can train a model on a base dataset containing multiple labeled images of generic anatomical structures. We can then fine-tune the model on specific medical images with limited labeled samples.
Parameter-Level FSL Approach
This approach involves finding a set of model parameters that quickly converge to the most optimal parameter space for a specific problem. The objective is to reach a parameter space where the model will require only a few training steps to generalize to the new dataset without needing extensive labeled data.
For instance, training an FSL model to classify a rare bird species will be slower and more prone to overfitting if we use random parameters for initialization. Instead, we can initialize the model with pre-trained parameters that already have prior knowledge regarding generic bird species.
Techniques such as Bayesian optimization or specialized embedding spaces prepare the model with a knowledge base that facilitates quick adaptation (i.e., classifying rare bird species), minimizing the risk of overfitting despite the sparse data.
Meta-learning
This approach is subdivided into metric-learning and gradient-based approaches.
- Metric-learning employs distance-based metrics to assess class similarity so that models can classify new examples by comparing them to known classes within embedding spaces.
- Gradient-based meta-learning, exemplified by algorithms like MAML, optimizes the model's ability to learn efficiently from a few examples by adjusting its parameters based on a meta-learner's feedback, bridging the gap between different tasks.
Generative Methods
Generative methods relate to data-level approaches that use synthetic data to augment the support and query sets in FSL. Data augmentation techniques, generative adversarial networks (GANs), and vision transformers (ViT) are standard methods that you can use to create fake data.
This approach increases the quantity of data and introduces variability, challenging the model to learn more generalized representations.
Cross-modal Few-shot Learning
Cross-modal techniques use data from different modalities, such as text and audio, for FSL. For instance, you can combine text and image data to have a richer dataset instead of using images only.
A straightforward method employed by recent research combines text and visual embeddings to compute richer prototypes for measuring similarity with the query image. This extends the traditional prototypical network, which only uses image embeddings for class prototypes.
Few-shot learning approaches vary depending on the problem’s context. However, their distinction can be hazy, as you can combine one approach to develop a new FSL framework.
Categorizing FSL based on its types can be more helpful.
So, let’s discuss FSL’s variations.
Here is a table summary of the approaches, their primary objective, and instances where they are the best approach to implement
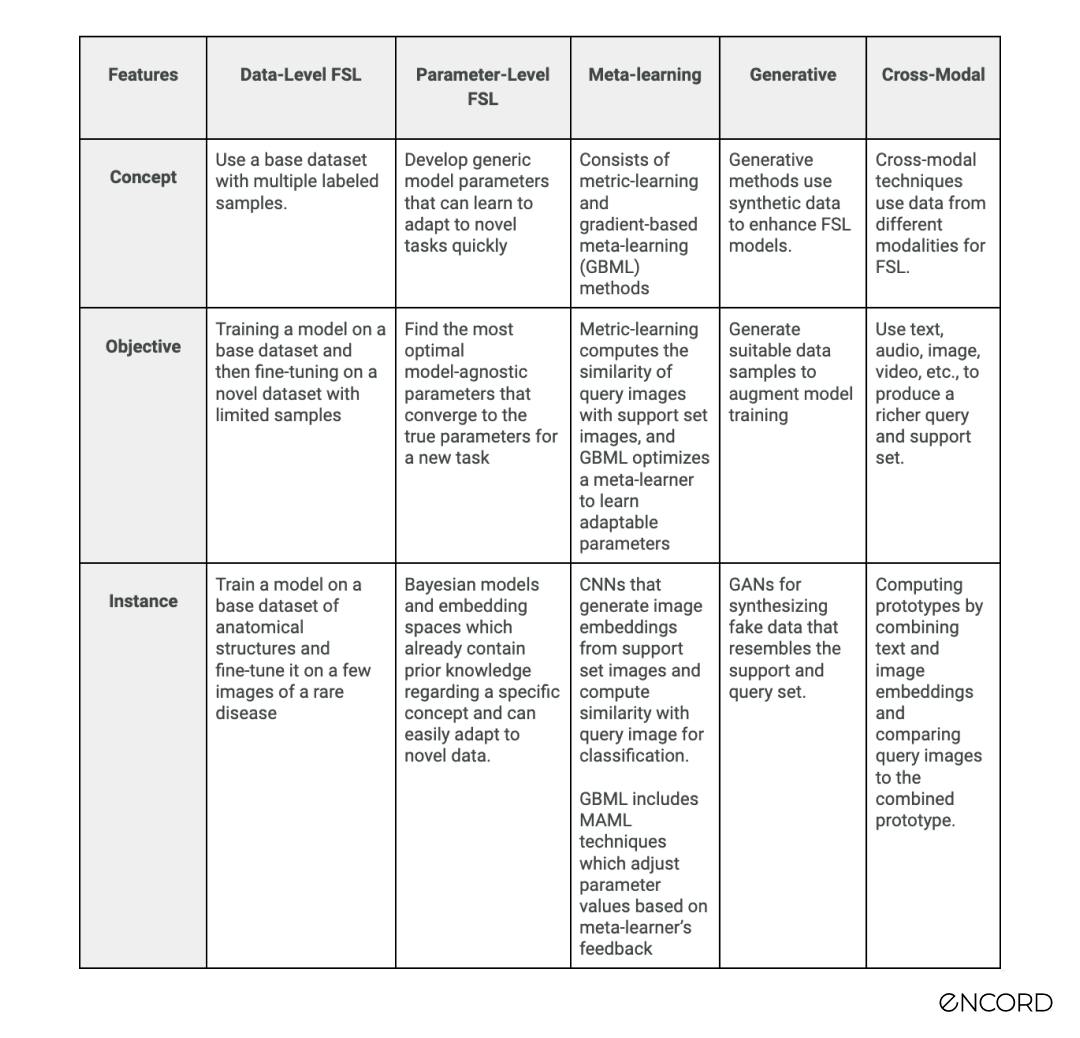
Few-shot Learning Variations
FSL encompasses a range of learning frameworks tailored to the scarcity of data, classified into n-shot, one-shot, and zero-shot learning. Each variation addresses unique challenges in machine learning with minimal examples.
- N-shot Learning: N-shot learning is a generalization of FSL models where ‘N’ refers to the number of training examples per class. For instance, training a model with only four samples per class is called 4-shot learning. This adaptable variation allows models to be tailored to the specific constraints and complexities of various tasks. N-shot learning shines in scenarios where acquiring a handful of examples is feasible, balancing learning efficiency and performance.
- One-shot Learning: One-shot learning (OSL) occurs when only one sample exists per class in the training set. OSL algorithms are helpful in facial recognition applications where you only have a single training instance for each individual, and gathering multiple instances may be challenging. They use feature extraction and comparison to recognize patterns from a single instance and avoid overfitting.
- Zero-shot Learning: Zero-shot learning (ZSL) is an extreme variation of FSL, where the model classifies items with no direct training examples. The method involves training a model on seen classes and corresponding auxiliary information—detailed descriptions, labels, and definitions of each class. The model learns to use the auxiliary information to predict labels for the seen classes correctly. Once trained, we ask the model to classify unseen or new classes based on their auxiliary information during inference. This approach is particularly valuable in domains where the class spectrum is vast and continually expanding.
Few-shot Learning Classification Algorithms
Let’s now turn to the several classification algorithms based on the abovementioned approaches and variations. The following will briefly overview six mainstream FSL algorithms: model-agnostic meta-learning (MAML), matching, prototypical, relation, and memory-augmented neural networks.
Model-agnostic Meta-learning (MAML)
MAML is a parameter-level GBML approach that involves a two-step optimization process to prepare models for quick adaptation to new tasks. In the first step, we initialize a model and train it on multiple tasks. We use the errors generated from this step to compute adapted parameters through gradient descent.
Next, we fine-tune the model, adjusting its parameters based on the errors, through stochastic gradient descent using a loss function.
The result is a generic pre-trained parameter set that can quickly adapt to new tasks in a few training steps.
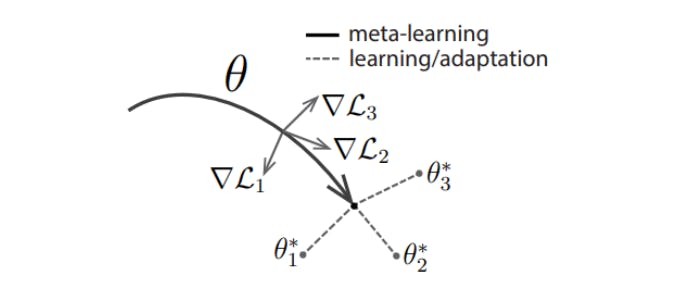
MAML - Model Agnostic Meta Learning
Once we have the pre-trained parameter, we can adapt by re-training it under a few-shot setting. The pre-trained parameter theta will approach to the true parameter theta-star of a new task with only a few gradient steps, making the learning process efficient.
Matching Networks
Matching networks (MNs) are a metric-based meta-learning approach that uses convolutional neural networks (CNNs) to generate embeddings for both support and query images.
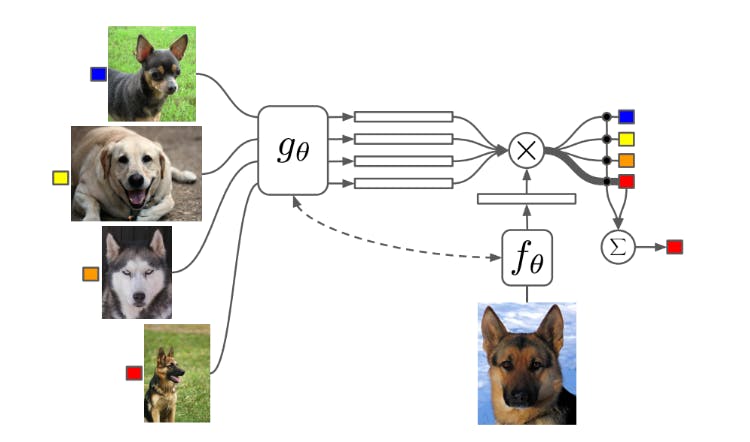
The model classifies the query image based on similarity with support set embeddings. The approach dynamically adjusts to new tasks using a contrastive loss function to backpropagate errors for optimizing a model for better task-specific performance.
Prototypical Networks
Prototypical networks (PNs) are a metric-based approach that computes an average for each class in the support set using the respective embeddings of the classes. The averages are called prototypes.
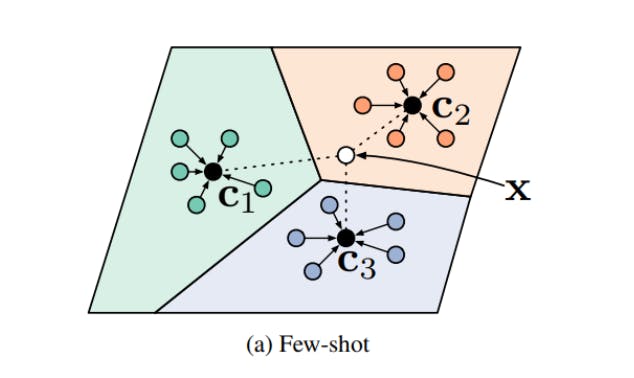
The model compares the embeddings of a query (input) image x with the prototype c for class k and classifies the image based on a similarity score (their proximity to these prototypes).
Cross-modal approaches also use prototypical networks to compute the prototypes for each class by combining its text and image embeddings.
Relation Networks
Relation networks (RNs) combine the methods of matching and prototypical networks. The framework computes prototypes for each class and concatenates the query image embeddings with the prototypes.
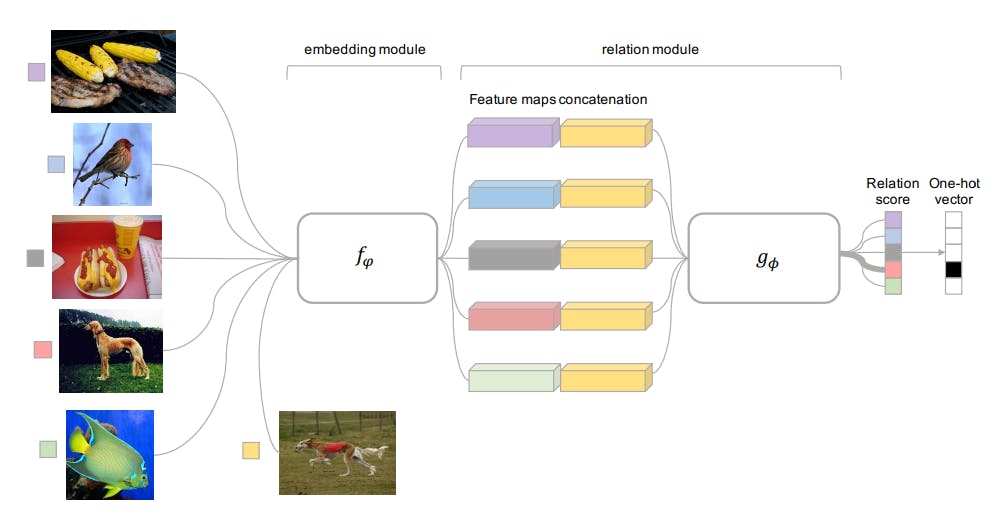
A relation module classifies the query image based on the similarity between the query embeddings and class prototypes. This method allows for a more nuanced assessment of class membership to interpret complex relations.
Siamese Networks
Siamese networks are also metric-based frameworks adept at one-shot learning. They are designed for comparison, using twin networks to process pairs of inputs and assess their similarity.
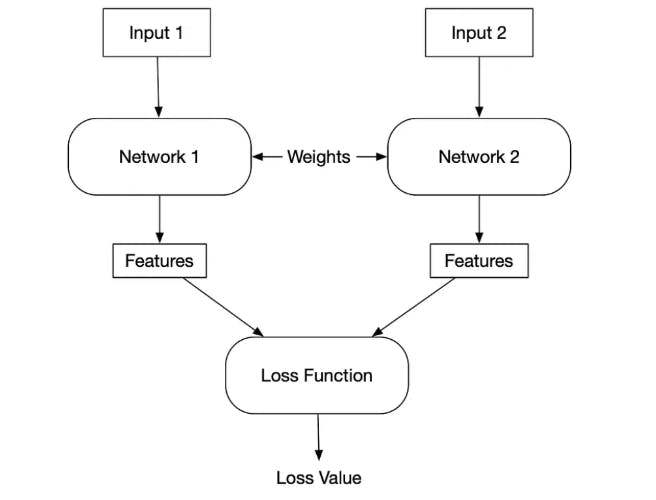
It uses a contrastive loss function to fine-tune the model's sensitivity to subtle differences and similarities.
Memory-augmented Neural Networks
Memory-augmented neural networks (MANNs) use memory modules to store data-related information such as vectors, entity relationships, and context. This enables the model to draw on this repository when encountering new tasks.
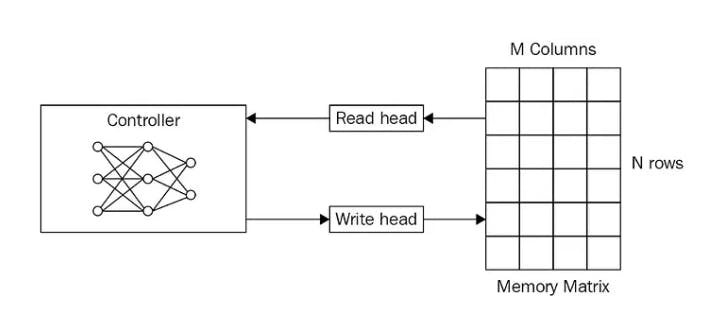
The architecture consists of a controller, read-write heads, and a memory module. The read head fetches relevant information from memory when the controller receives a query. It provides it back to the controller for classification.
Also, the write head stores new information in the memory module when the controller receives new data.
Few-shot Object Detection Algorithm
Like few-shot classification, we can also use few-shot approaches for object detection. The method involves a support set containing K class labels for each object within an image and N examples per class.
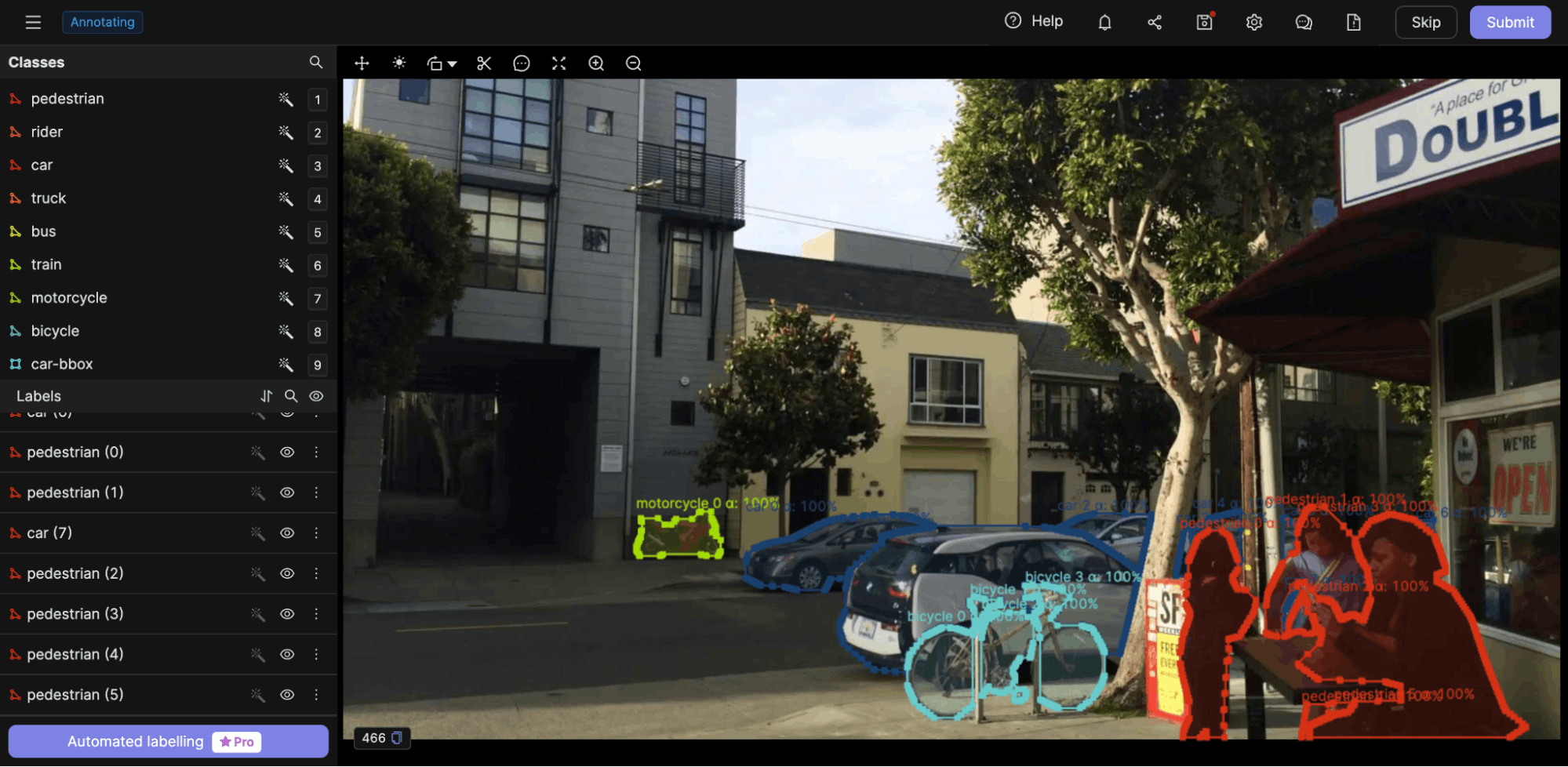
Annotating an N-class-label image using Encord Annotate
More generally, a single image can contain more than one instance of the same object, and there can be multiple images. The situation can result in a class imbalance as the support set can contain more examples for a specific class and fewer for others.
The two algorithms to solve these issues and classify objects with only a few examples are:
- YOLOMAML
- DeFRCN
YOLOMAML
YOLOMAML combines a variation of the YOLO algorithm with the MAML technique for few-shot object detection.
The architecture consists of a customized version of YOLOv3 with Tine Darknet as the backbone and two additional output blocks.
The backbone is initialized with pre-trained parameters on the ImageNet dataset, and the layers are frozen, leaving only five convolutional layers to be trained. This speeds up the learning process on a standard GPU.

Like the standard MAML, the algorithm samples several detection tasks from the support set.
For each task, it updates the initial parameters based on the loss function defined over the query set. This results in updated parameters for each task.
Finally, it updates the initial parameter set through stochastic gradient descent using the aggregate of loss functions defined over the updated parameters.
Once we have the updated parameters, we can initialize the network with this new set of parameters and provide novel images for detection. The pre-trained parameters will quickly adapt to detect the relevant objects based on limited samples.
DeFRCN
Decoupled Fast Recurrent Network (DeFRCN) is a variant of the Fast-RCNN framework which consists of a region proposal network (RPN), recurrent neural network (RCNN), and two modules for box classification and regression. Together, the box classifier and regressor help detect relevant objects within an image.
In traditional Fast-RCNN, the RPN proposes regions of interest (where to look), and the RCNN module predicts bounding boxes (what to look). However, the two modules share the same feature extractor (the backbone). This results in misalignment as the objectives of RPN and RCNN are fundamentally different.
DeFRCN overcomes these limitations by introducing separate gradient decoupled layers (GDL) for RPN and RCNN to control the effect of each on the backbone’s update process. The network is trained on a large base dataset with multiple labeled samples.
The architecture uses a Prototypical Calibration Network (PCN) for few-shot detection, which consists of a feature extractor to capture relevant features of novel classes in the support set.
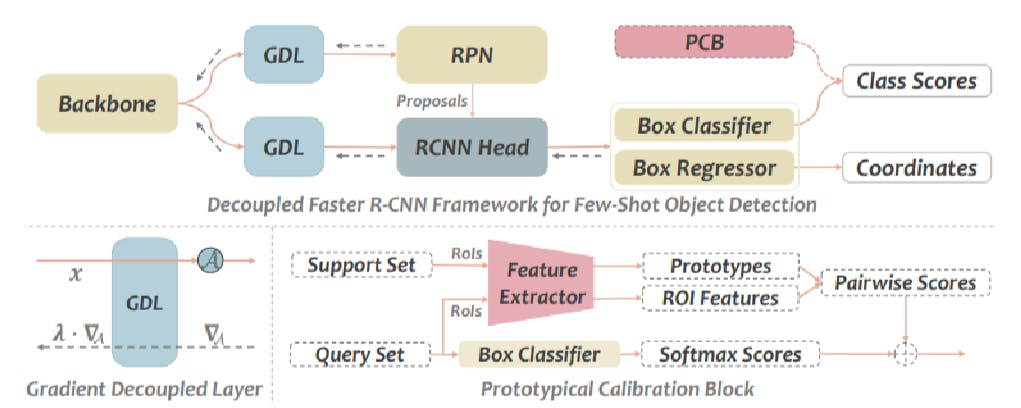
PCN computes prototypes for each class and outputs a similarity score against the query image. The query image is also given to the box classifier, which generates its own classification score.
The network backpropagates the loss based on the two scores to optimize the backbone further. This way, the DeFRCN architecture jointly trains the model on base and novel datasets for optimal detection.

Few Shot Learning: Use Cases
Since FSL requires only a few labeled samples for training machine learning models, it has widespread uses in multiple industrial applications where data is limited. The list below mentions a few popular FSL use cases.
- Robotics: FSL models can help robots recognize novel objects in unknown environments without requiring extensive prior knowledge.
- Medical imaging: Due to insufficient labeled images for rare diseases, FSL models are valuable for medical diagnosis as they can detect new diseases and anomalies with minimal training data.
- Facial recognition: Facial recognition systems mostly use OSL models like the Siamese network to authenticate users. The models compare the input image with a reference photo and detect similarity.
- Autonomous vehicles: CV models for autonomous vehicles require FSL object detection models to recognize new objects on the road for efficient navigation.
- Quality assurance: FSL frameworks can help detect new product anomalies and defects on the assembly line.
- Gesture and emotion recognition: Classifying gestures and emotions in real-time is challenging since training a model using traditional methods will require data on all kinds of emotional and physical cues. Instead, training FSL models on a few relevant images is optimal, as they can recognize anomalous behavior using minimal labeled samples.
- Video Scene Classification: FSL approaches can analyze and classify novel video scenes using the knowledge gained from a few training samples.
Few-shot Learning: Key Takeaways
With FSL overtaking the traditional learning paradigms in computer vision, the approaches, algorithms, and frameworks will likely grow exponentially in the coming years. Below are a few key points to remember regarding FSL:
- Significance of FSL: FSL is crucial in the modern AI ecosystem. It can help you build models with minimal training data, making it suitable for applications where data is limited.
- Few-shot classification approaches: The primary FSL approaches for image classification include data-level, parameter-level, metric-based, gradient-based meta-learning, generative, and cross-modal methods.
- Few-shot object detection: Few-shot object detection is an emerging field where we aim to detect multiple objects within a single image using FSL approaches. YOLOMAML is the only mainstream algorithm to address this problem.
Frequently asked questions
Few-shot learning (FSL) is a learning paradigm that aims to train models on a few labeled samples.
Facial recognition is the most significant application of one-shot learning (OSL). Authentication devices use OSL models to verify the identity of a user.
Few-shot learning requires a few labeled examples to categorize new images. However, zero-shot models require no training data to classify new images.
Few-shot learning is an approach for training deep learning models with less data. Active learning is a labeling technique that identifies samples that are difficult to classify and asks the user to label only those images to boost model performance.
Metric-based learning is one approach to few-shot learning, which involves classifying query images based on similarity scores with support set images.
Encord enables users to train deep learning models using just a few hundred images, simplifying the training process. This approach is particularly beneficial for applications like factory automation, where the labeling effort is reduced while still maintaining model performance.