The Complete Guide to Object Tracking [Tutorial]

Visual object tracking is an important field in computer vision. Numerous tracking algorithms with promising results have been proposed to date, including ones based on deep learning that have recently emerged and piqued the interest of many due to their outstanding tracking performance. Before we dive into some of the most famous deep learning algorithms for object tracking, let’s first understand object learning and its importance in the field of computer vision.
What is Object Tracking in Computer Vision?
Object tracking involves an algorithm tracking the movement of a target object, and predicting the position and other relevant information about the objects in the image or video.
Object tracking is different from object detection (which many will be familiar with from the YOLO algorithm): whereas object detection is limited to a single frame or image and only works if the object of interest is present in the input image, object tracking is a technique used to predict the position of the target object, by tracking the trajectory of the object whether it is present in the image or video frame or not.
Object tracking algorithms can be categorized into different types based on both the task and the kind of inputs they are trained on. Let’s have a look at the four most common types of object tracking algorithms:
- Image tracking
- Video tracking
- Single object tracking
- Multiple object tracking

What are the Different Types of Object Tracking?
Image Tracking
The purpose of image tracking is to detect two-dimensional images of interest in a given input. The image is then continuously tracked as it moves around the environment. As a result, image tracking is best suited for datasets with sharply contrasted images, asymmetry, patterns, and several identifiable differences between the images of interest and other images within the image dataset.
Video Tracking
As the name suggests, video tracking is the task of tracking objects of interest in a video. It involves analyzing the video frames sequentially and stitching the past location of the object with the present location by predicting and creating a bounding box around it. It is widely used in traffic monitoring, self-driving cars, and security monitoring, as it can predict information about an object in real-time.
Both image and video object tracking algorithms can further be classified based on the number of objects they are tracking:
Single Object Tracking
Single object tracking, as the name suggests, involves tracking only one target at a time during a video or a sequence of images. The target and bounding box coordinates are specified in the first frame or image, and it is recognized and tracked in subsequent frames and images.
Single object tracking algorithms should be able to track any detected object they are given, even the object on which no available classification model was trained.
![]()
Fig 1: A single object (i.e. the car) being tracked. Source
Multiple Object Tracking
On the other hand, multiple object tracking involves tracking multiple objects. The tracking algorithms must first determine the number of objects in each frame, and then keep track of each object’s identity from frame to frame.

Fig 2: Applications of multiple object tracking. Source
Now that we have a brief understanding of object tracking, let’s have a look at a couple of its use cases, and then dive into the components of an object tracking algorithm.
Use Cases for Object Tracking in Computer Vision
Surveillance
Real-time object tracking algorithms are used for surveillance in numerous ways. They can be used to track both activities and objects – for example, object tracking algorithms can be used to detect the presence of animals within a certain monitored location, and send out alerts when intruders are detected. During the pandemic, object tracking algorithms were often used for crowd monitoring, i.e. to track if people were maintaining social distance in public areas.
Retail
In retail, object tracking is often used to track customers and products – an example of this is the Amazon Go stores, where these algorithms were essential in building cashierless checkout systems. The multi-object tracking system will not only track each customer, it will also track each object the customer picks up, allowing the algorithms to determine which products are put into the basket by the customer in real-time and then generate an automated receipt when the customer crosses the checkout area. This is a practical example of how computer vision tasks can also allow for tangible customer benefits (e.g. faster checkout and a smoother experience).
Autonomous Vehicles
Perhaps the most well-known use of AI-driven object detection and tracking is self-driving cars. Visual object tracking is used in cars for numerous purposes, including obstacle detection, pedestrian detection, trajectory estimation, collision avoidance, vehicle speed estimation, traffic monitoring, and route estimation. Artificial intelligence is at the core of autonomous transportation, and image classification and moving object detection will have a huge influence on the future of the space.
Healthcare
Visual object tracking is becoming increasingly adopted across the healthcare industry. Pharmaceutical companies, for example, use both single and multi-object tracking to monitor medicine production in real-time and ensure that any emergencies, such as machine malfunctioning or faulty medicine production lines, are detected and addressed in real-time.
Now that we’ve highlighted a few examples of object tracking - let’s dive deeper into its components.
Object Tracking Method
Step 1: Target Initialization
The first step of object tracking is defining the number of targets and the objects of interest. The object of interest is identified by drawing a bounding box around it – in an image sequence this will typically be in the first image, and in a video in the first frame.
The tracking algorithm must then predict the position of the object in the remaining frames while simultaneously identifying the object.
This process can either be done manually or automatically. Users do manual initialization to annotate object’s positions with bounding boxes or ellipses. Object detectors, on the other hand, are typically used to achieve automatic initialization.
Step 2: Appearance modeling
Appearance modeling is concerned with modeling an object’s visual appearance. When the targeted object goes through numerous differing scenarios - such as different lighting conditions, angles or speeds - the appearance of the object may vary, resulting in misinformation and the algorithm losing track of the object. Appearance modeling must be performed in order for modeling algorithms to capture the different changes and distortions introduced while the object of interest moves.
This type of optimization consists primarily of two components:
- Visual representation: constructing robust object descriptions using visual features
- Statistical modeling: building effective mathematical models for object identification using statistical learning techniques

Fig 3: Illustration of complicated appearance changes in visual object tracking. Source
Step 3: Motion estimation
Once the object has been defined and its appearance modeled, motion estimation is leveraged to infer the predictive capacity of the model to predict the object’s future position accurately. This is a dynamic state estimation problem and it is usually completed by utilizing predictors such as linear regression techniques, Kalman filters, or particle filters.
Step 4: Target positioning
Motion estimation approximates the region where the object is most likely to be found. Once the approximate location of the object has been determined, a visual model can be utilized to pinpoint the exact location of the target – this is performed by a greedy search or maximum posterior estimation based on motion estimation.
Challenges for object tracking
A few common challenges arise while building an object tracking algorithm. Tracking an object on a straight road or in a simple environment is simple. In a real-world environment, the object of interest will have many factors affecting it, making object tracking difficult. Being aware of these common challenges is the first step in being able to address these issues when designing object tracking algorithms. A few of the common challenges of object tracking are:
Background Clutters
It is difficult to extract features, detect or even track a target object when the background is densely populated, as it introduces more redundant information or noise, making the network less receptive to important features.

Fig 4: Showing background clutter. Source
Illumination Variation
In a real-life scenario, the illumination on an object of interest changes drastically as the object moves – making its localization more challenging to track and estimate.

Fig 5: The target object is shadowed.
Occlusion
As different objects and bodies enter and leave the frame, the target object’s bounding box is often occluded – preventing the algorithm from being able to identify and track it, as the background or foreground are interfering. This often happens when the bounding boxes of multiple objects come too close together, causing the algorithms to get confused, and identify the tracked object as a new object.

Fig 6: Full occlusion. Source
Low Resolution
Depending on the resolution, the number of pixels inside the training dataset bounding box might be too low for object tracking to be consistent.

Fig 7 : Low resolution making it difficult to detect an object. Source
Scale Variation
Scale is also a factor, and the algorithm’s ability to track the target object can be challenged when the bounding boxes of the first frame and the current frame are out of the range.

Fig 8 : Scale variation of the car’s proportions. Source
Change in the shape of the target
Across images and frames, the shape of the object of interest may rotate, dimish in size, deform, etc. This could be due to multiple factors like viewpoint variation, or changes in object’s scale, and will often interfere with the algorithm’s object tracking intuition.

Fig 9 : Rotation changes the shape of the target. Source
Fast Motion
Particularly when tracking rapidly-moving objects, the object’s rapid motion can often impact the ability to accurately track the object across frames and images.
Now, we have discussed each component necessary for building an object tracking algorithm and the challenges one faces when it is used in the real-world. The algorithms we are building are for the applications in the real-world, hence, it is essential to build robust and efficient object tracking algorithms. Deep learning algorithms have proven to achieve success in object tracking. Here are few of the famous algorithms:
Deep Learning Algorithms for Object Tracking
Object tracking has been around for roughly 20 years, and many methods and ideas have been developed to increase the accuracy and efficiency of tracking models.
Traditional or classical machine learning algorithms such as k-nearest neighbor or support vector machine were used in some of the methodologies – these approaches are effective at predicting the target object, but they require the extraction of important and discriminatory information by professionals.
Deep learning algorithms, on the other hand, extract these important features and representations on their own. So let’s have a look at some of these deep learning algorithms that are used as object tracking algorithms:
DeepSORT
DeepSORT is a well-known object tracking algorithm. It is an extension of the Simple Online Real-time Tracker or SORT, an online tracking algorithm. SORT is a method that estimates the location of an object based on its past location using the Kalman filter. The Kalman filter is quite effective against occlusion.
SORT is comprised of three components:
- Detection: Firstly, the initial object of interest is detected.
- Prediction: The future location of the object of interest is predicted using the Kalman filter. The Kalman filter predicts the object’s new filter, which needs to be optimized.
- Association: The approximate locations of the target object which has been predicted needs to be optimized. This is usually done by detecting the position in the future using the Hungarian algorithm.
Deep learning algorithms are used to improve the SORT algorithms. They allow the SORT to estimate the object’s location with much higher accuracy because these networks can now predict the features of the target image. The convolutional neural network (CNN) classifier is essentially trained on a task-specific dataset until it reaches high accuracy. Once achieved, the classifier is removed, leaving simply the features collected from the dataset. These extracted features are then used by the SORT algorithm to track targeted objects.
DeepSORT operates at 20Hz, with feature generation taking up nearly half of the inference time. Therefore, given a modern GPU, the system remains computationally efficient and operates at real time.
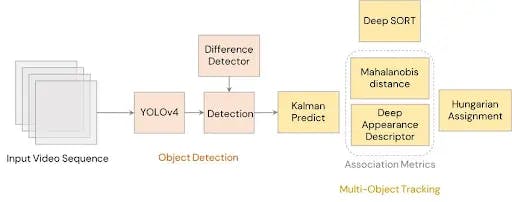
Fig 10: Architecture of DeepSORT. Source
MDNet
Multi-Domain Net or MDNet is a type of CNN-based object tracking algorithm which uses large-scale data for training. It is trained to learn shared representations of targets using annotated videos, i.e., it takes multiple annotated videos belonging to different domains. Its goal is to learn a wide range of variations and spatial relationships.
There are two components in MDNet:
- Pretraining: Here, the deep learning network is required to learn multi-domain representation. The algorithm is trained on multiple annotated videos in order to learn representation and spatial features.
- Online visual tracking: The domain-specific layers are then removed, and the network has the shared layers. This consists of learned representations. During inference, a binary classification layer is added, which is then further trained or fine-tuned online.
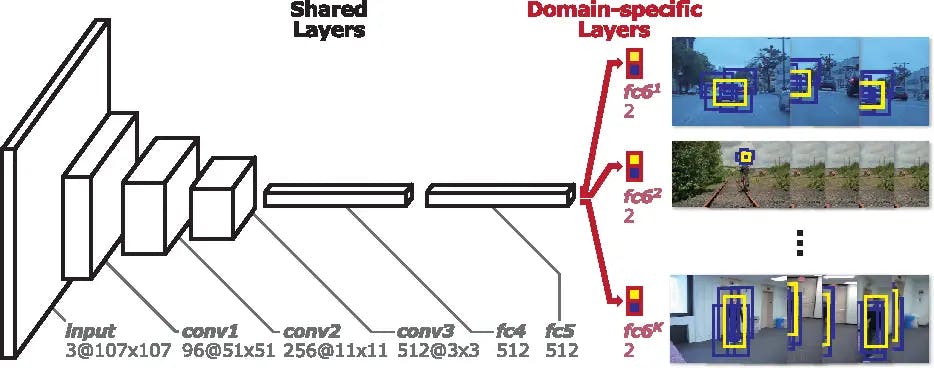
Fig 11: Architecture of Multi-domain network showing shared layers and K branches of domain specific layers. Source
SiamMask
The goal of SiamMask is to improve the offline training technique of the fully-convolutional Siamese network. Siamese networks are convolutional neural networks which use two inputs to create a dense spatial feature representation: a cropped image and a larger search image.
The Siamese network has a single output. It compares the similarity of two input images and determines whether or not the two images contain the same target objects. By augmenting the loss with a binary segmentation task, this approach is particularly efficient for object tracking algorithms. Once trained, SiamMask operates online and only requires a bounding-box initialization, providing class agnostic object segmentation masks and rotating bounding boxes at 35 frames per second.

Fig 12: SiamMask (green bounding box) showing better results from ECO (red bounding box) after it has been initialized with a simple bounding box (blue bounding box). Source
GOTURN
Most generic object trackers are trained from scratch online, despite the vast amount of videos accessible for offline training. Generic Object Tracking Using Regression Networks, or GOTURN utilizes the regression based neural networks to monitor generic objects in such a way that their performance can be improved by training on annotated videos.
This tracking algorithm employs a basic feed-forward network that requires no online training, allowing it to run at 100 frames per second during testing. The algorithm learns from both labeled video and a large collection of images, preventing overfitting. The tracking algorithm learns to track generic objects in real-time as they move throught different spaces.
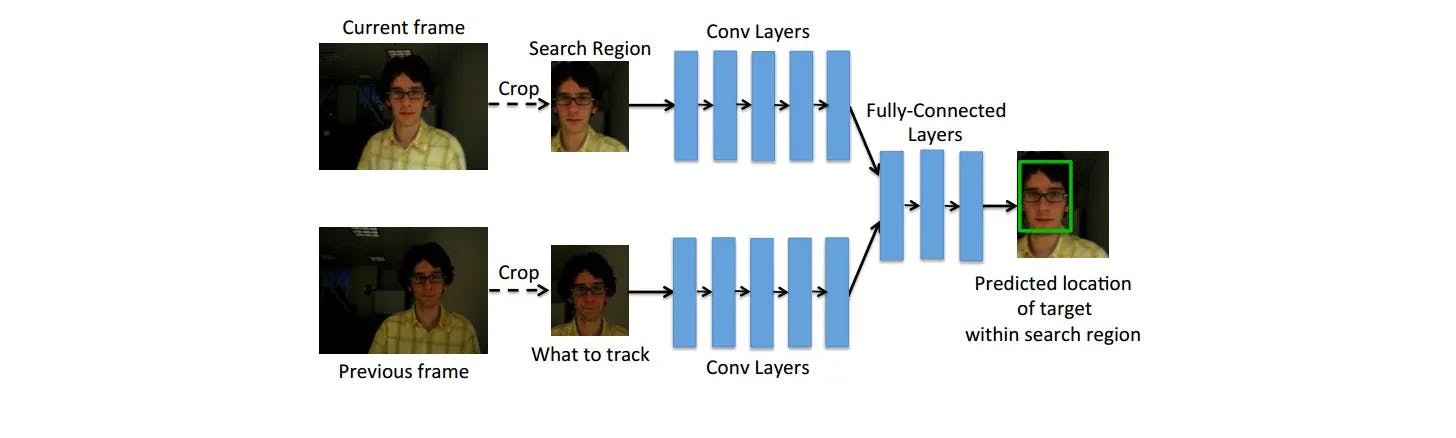
Fig 13: GOTURN network architecture. A search region from the current frame and a target from the previous frame is input into the network. The network learns to compare these crops to find the target object in the current image. Source
All these algorithms have been trained on publicly available datasets – which highlights the importance of well-labeled data. This a key topic for anyone in the field of machine learning and computer vision, since building an accurate object tracking algorithm starts with a strong annotated dataset.
Platforms that help you annotate your video and image stream dataset efficiently often include features like automated object tracking built in as well. This helps in reducing the time spent in building a good dataset and getting a jump start on your deep learning solution to object tracking. Let’s have a look at how to use Encord to build your dataset for object tracking algorithms:
Guide to Object Tracking in Encord
Step 1: Create new project
In the home page, click on the “New project” to begin, and add a Project Name and Description – this will help others understand the dataset once it’s shared across the team, or referred to in future.
Fig 15
Step 2: Add the dataset
Here, you can either use an existing dataset or add in a new dataset. I had already added my dataset using the “new dataset” icon, so I select it.
Adding a description can also be helpful to other team members when you share the dataset you have built and annotated. It can also be saved in a private cloud as a security measure.
Here I have selected and uploaded 100 images from the VOT2022 challenge dataset of a car.
Fig 16
Step 3: Set the Ontology
You can think of the ontology as the questions you are asking of the data. Here, I have added “car” as an object in the ontology – you can track as many objects as required in any given image or frame. To learn more about ontologies, you can read more of Encord’s documentation.
Fig 17
Step 4: Set up quality assurance
This step is crucial when working with a large dataset to ensure that at each stage a certain quality is maintained. This can be done either manually or automatically – more details are in Encord’s documentation.
Fig 18
Fig 19

All set!
By creating a project in 4 simple steps, you are all set to start (and to automate!) labeling. The How to Automate Video Annotation blog post will help you automate the labeling process for object tracking.
Conclusion
Object tracking is used to identify objects in a video and interpret them as a series of high accuracy trajectories. The fundamental difficulty is to strike a balance between computational efficiency and performance – and deep learning algorithms offer such balance.
In this article, we discussed a few real-life use cases of object tracking, as well as some of the main challenges of building object tracking algorithms, and how these deep learning algorithms are paving the way in accuracy and efficiency. We hope this article will motivate you to build an efficient object tracking algorithm!
Frequently asked questions
Encord provides advanced annotation tools that streamline the process of training models for single object tracking. With a focus on accuracy and efficiency, Encord allows users to create high-quality training datasets, ensuring models can reliably identify and engage targets based on specific parameters.
Encord provides robust features for object detection and tracking, allowing users to manage large datasets effectively. The platform supports various tasks in computer vision, making it easier to work with detection and tracking datasets, regardless of their source or licensing restrictions.
Encord provides tools and resources that enable users to optimize their object detection and tracking models through extensive benchmarking and performance analysis. This helps teams assess the effectiveness of traditional AI versus generative AI approaches in their specific applications.
Encord provides tools for integrating object detection and tracking, allowing users to build and optimize tracking pipelines for sports analysis. This includes capabilities for team classification and the ability to easily manage and visualize the data collected during tracking.
Tracking player performance can be challenging due to the need for precise recognition of players and equipment, along with complex calculations based on camera positioning. Encord addresses these challenges by providing users with tools to validate and correct data as needed.
Encord supports a variety of tracking use cases beyond face tracking, including hand tracking and object tracking. This flexibility allows users to apply tracking functionality to a wide range of applications, ensuring that diverse projects can be effectively addressed.
Encord's annotation capabilities focus on reducing the time needed for annotations while improving overall quality. Key features include enhanced object tracking and video native support, which streamline the annotation process and boost efficiency.
Currently, Encord focuses primarily on tracking people within the footage, although it can also accommodate tracking other objects like luggage and bags. Users can expand tracking capabilities based on their specific needs and project requirements.
Encord enables continuous tracking of project progress, allowing team managers to monitor performance and identify areas requiring intervention. This capability helps ensure that projects stay on track and meet their objectives efficiently.
Encord includes comprehensive administrative tools that allow teams to track annotations efficiently. This helps eliminate the need for external tracking solutions like spreadsheets, reducing errors and improving overall project management.