The data platform for ID verification teams
Annotate millions document images, video selfies, and biometric data in one place. Detect fraud edge cases before they reach production. That's why the leading ID verification teams are supported by Encord.
Vida provides verified digital identity. They needed to manage a large labeling team and keep personally identifiable information inside their infrastructure. With Encord they implemented a tiered labeling management system and a signed URL architecture that keeps all data in their own S3 buckets.
Read the full case studyimages annotated monthly
reduction in false acceptance rate
labeler team managed with tiered roles & QA
Why the top ID verification teams are switching

Annotation tooling with SDK-level programmability
Encord allows for custom model plug-ins for pre-labeling, ontology versioning, and configurable review workflows without writing infrastructure. ML engineers stop maintaining tooling and start building models.
Annotation tooling with SDK-level programmability
Encord allows for custom model plug-ins for pre-labeling, ontology versioning, and configurable review workflows without writing infrastructure. ML engineers stop maintaining tooling and start building models.

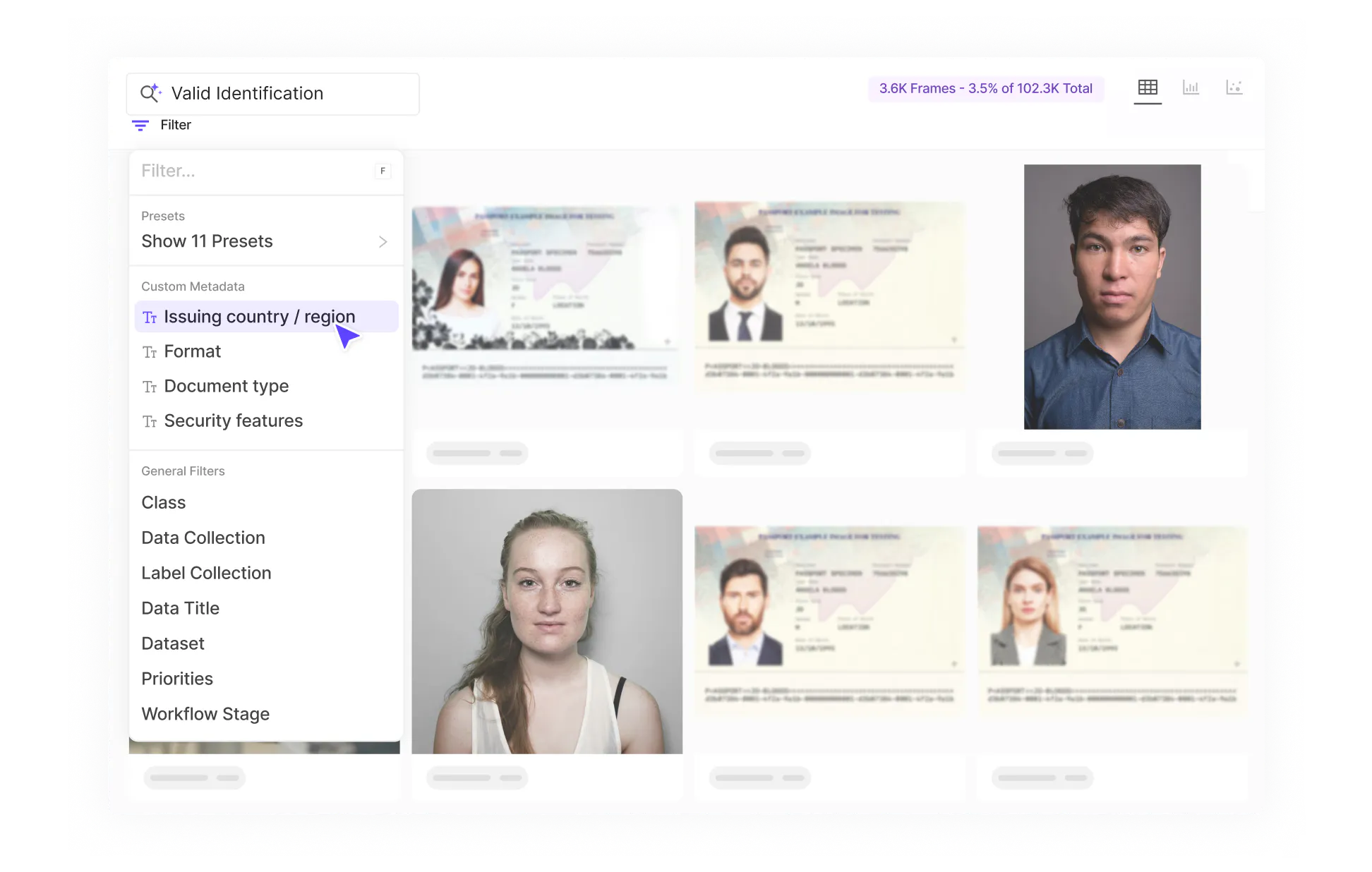
Embeddings-based visual search
Upload your embeddings or generate them via Encord. Cluster by document type or image quality. Surface outliers before annotation. Stop annotating low-signal data and instead label the data that matters.
Active learning pipeline for data prioritisation
Identify which images have the highest impact on model performance before the retention window closes. Focus annotation budget on signal, not volume. Refresh sets automatically as new data comes in.

Private cloud and on-premise installation
Deploy within your own AWS, GCP, or Azure environment. Connect directly to your existing cloud storage. SOC 2 Type II and GDPR compliance standard.
Private cloud and on-premise installation
Deploy within your own AWS, GCP, or Azure environment. Connect directly to your existing cloud storage. SOC 2 Type II and GDPR compliance standard.
OCR & Video Validation in One Workflow

Our additional resources for ID verification teams.



Frequently asked questions
Encord supports full VPC deployment on AWS, GCP, and Azure, as well as on-premise installation. Your raw images, video, and biometric data never leave your environment. Encord connects to your existing cloud storage (S3, GCS, Azure Blob) via secure links. No raw data transfer to Encord servers. SOC 2 Type II and GDPR compliance are standard.
Most IDV teams eventually hit the same wall: every ontology change breaks downstream pipelines, a single engineer owns the tool, and maintenance cost quietly balloons. Encord replaces internal tooling with a maintained, extensible platform; so your ML engineers spend time on models, not annotation infrastructure. Migration support is included.
Encord's active learning pipeline helps you prioritise which data to annotate first, so you maximise signal before the retention window closes. You can also configure Encord to automatically purge data from the platform in line with your DPA requirements, with a full audit trail retained.
Yes. You can connect your own OCR models, fraud classifiers, or embedding models via the Encord SDK. These run pre-labeling passes on new data; human reviewers then inspect and approve inside the same interface. You're not locked into Encord's model stack, your IP stays yours.
Encord is natively multimodal. You can curate, annotate, and evaluate document images, video liveness recordings, and biometric captures within a single project. Cross-modal comparison, viewing a passport scan alongside the video selfie taken at the same session, is built in, which is particularly useful for matching and spoof detection workflows.
Encord lets you upload your own embeddings or generate them using Encord's models, then visually cluster your dataset. You can filter by metadata, search using natural language, and identify outliers before annotation. You stop annotating low-signal data and focus budget on what actually moves model performance.