Label images 10x faster with Encord’s AI annotation tool
Combine human precision with AI-assisted labeling to accurately detect, segment, and classify objects 10x faster - supercharge annotation with built-in automated labelling tools like SAM 3.
Suite of labeling tools for any image annotation project
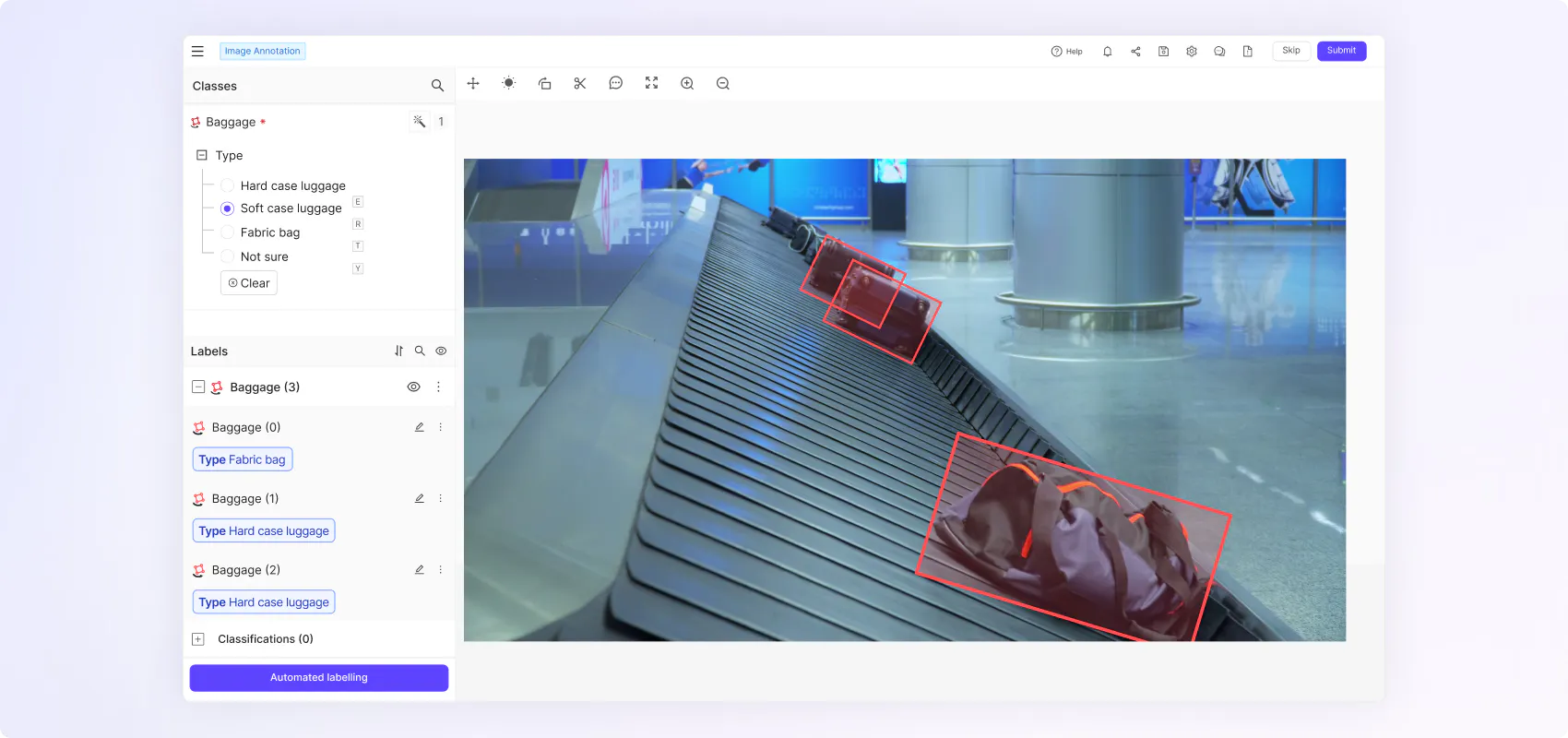
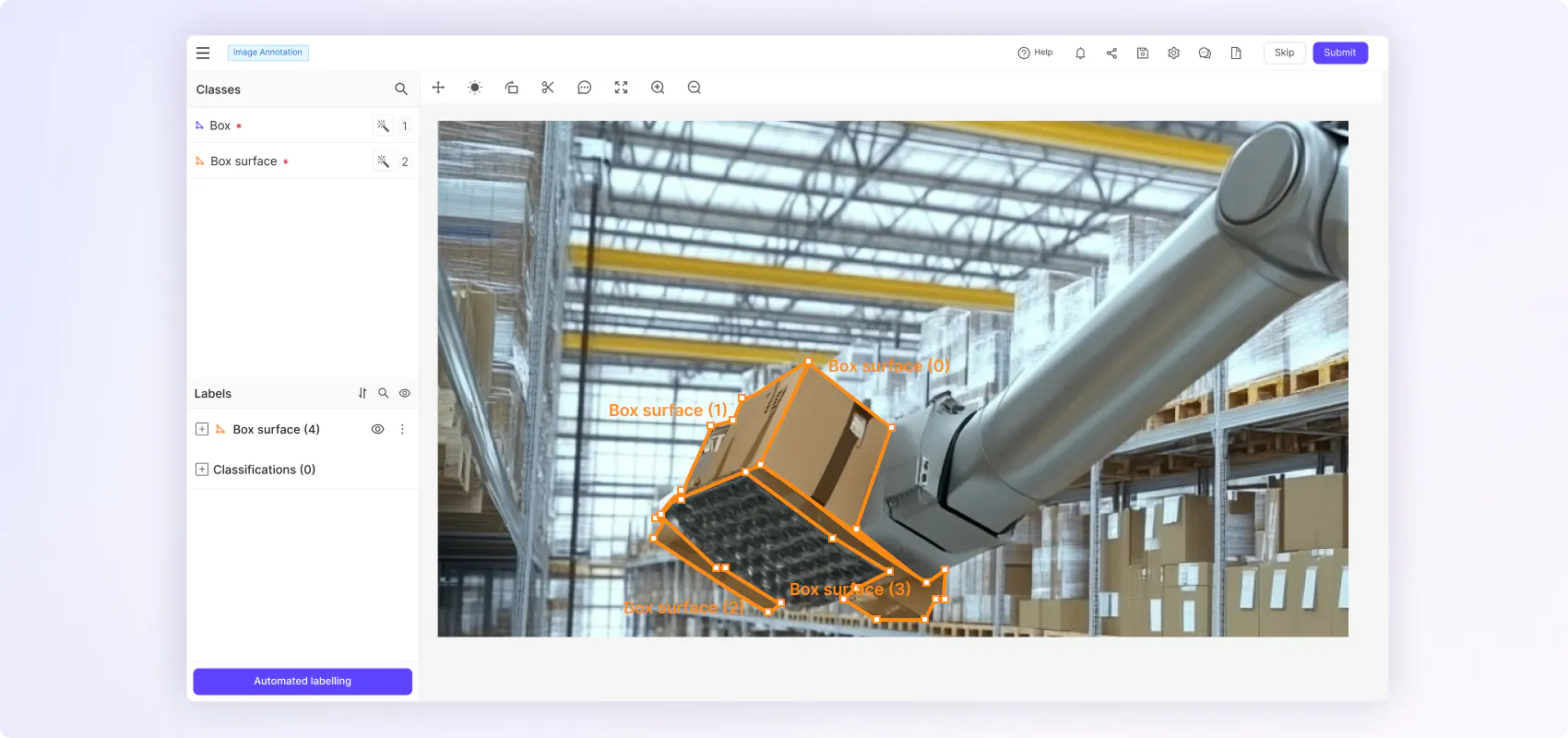
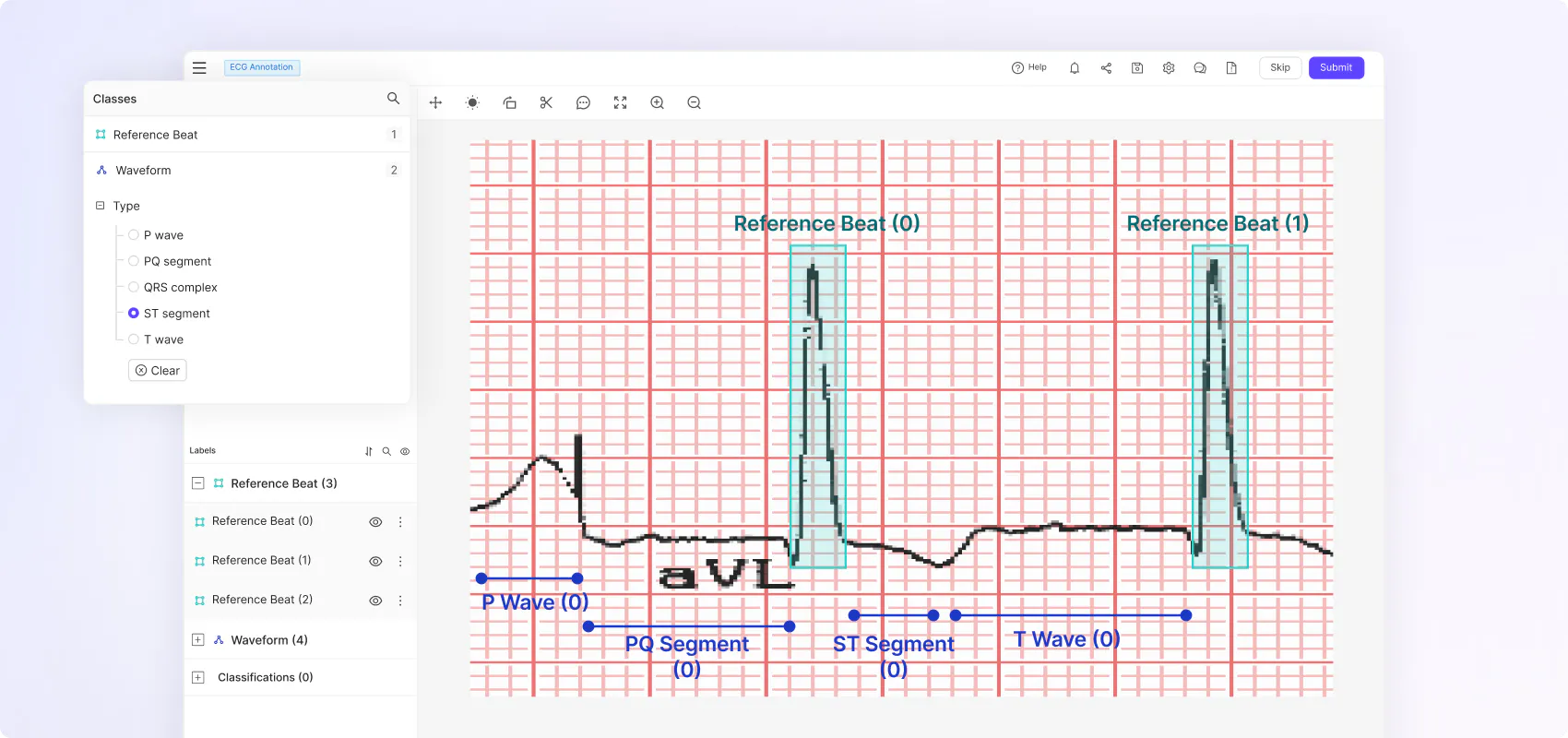
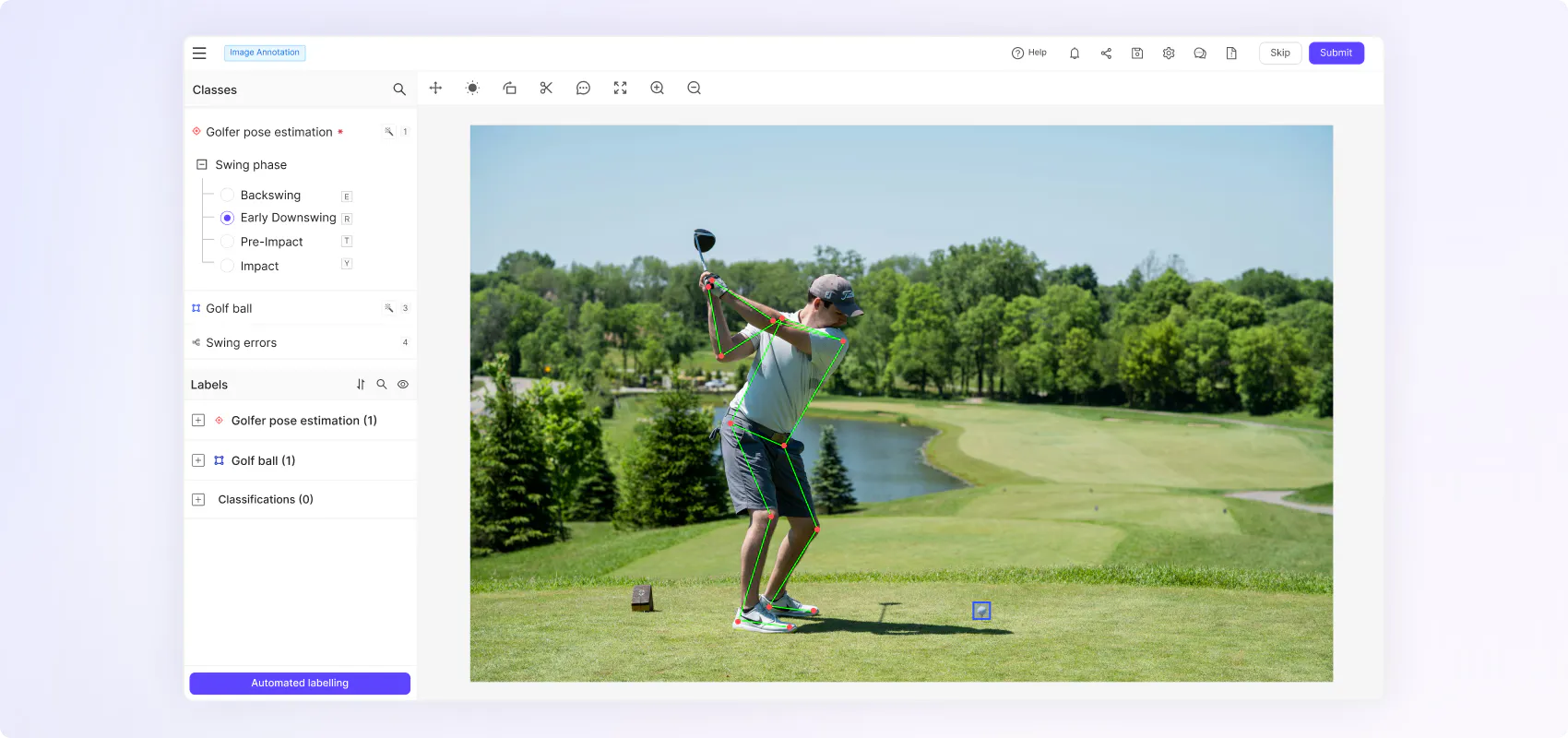
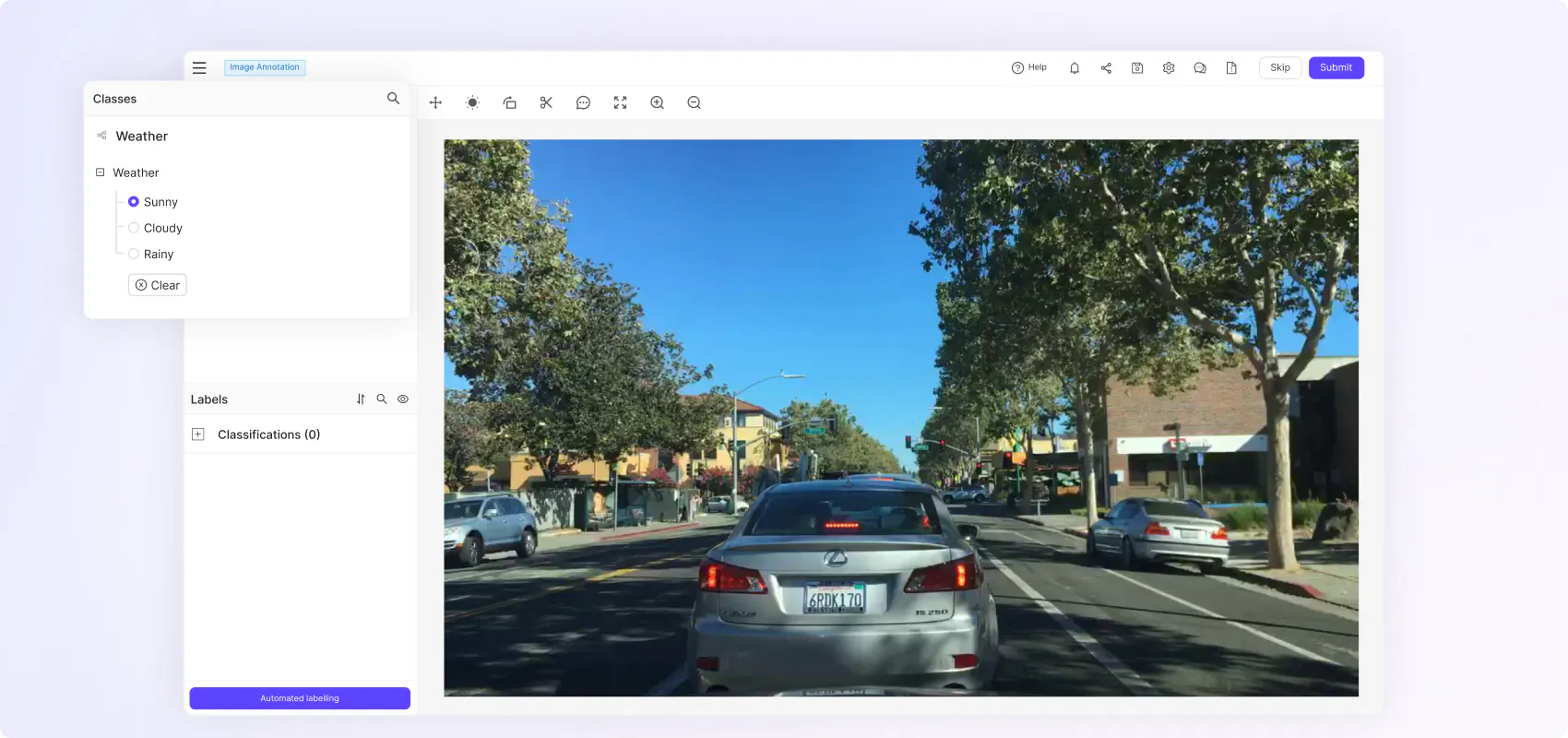
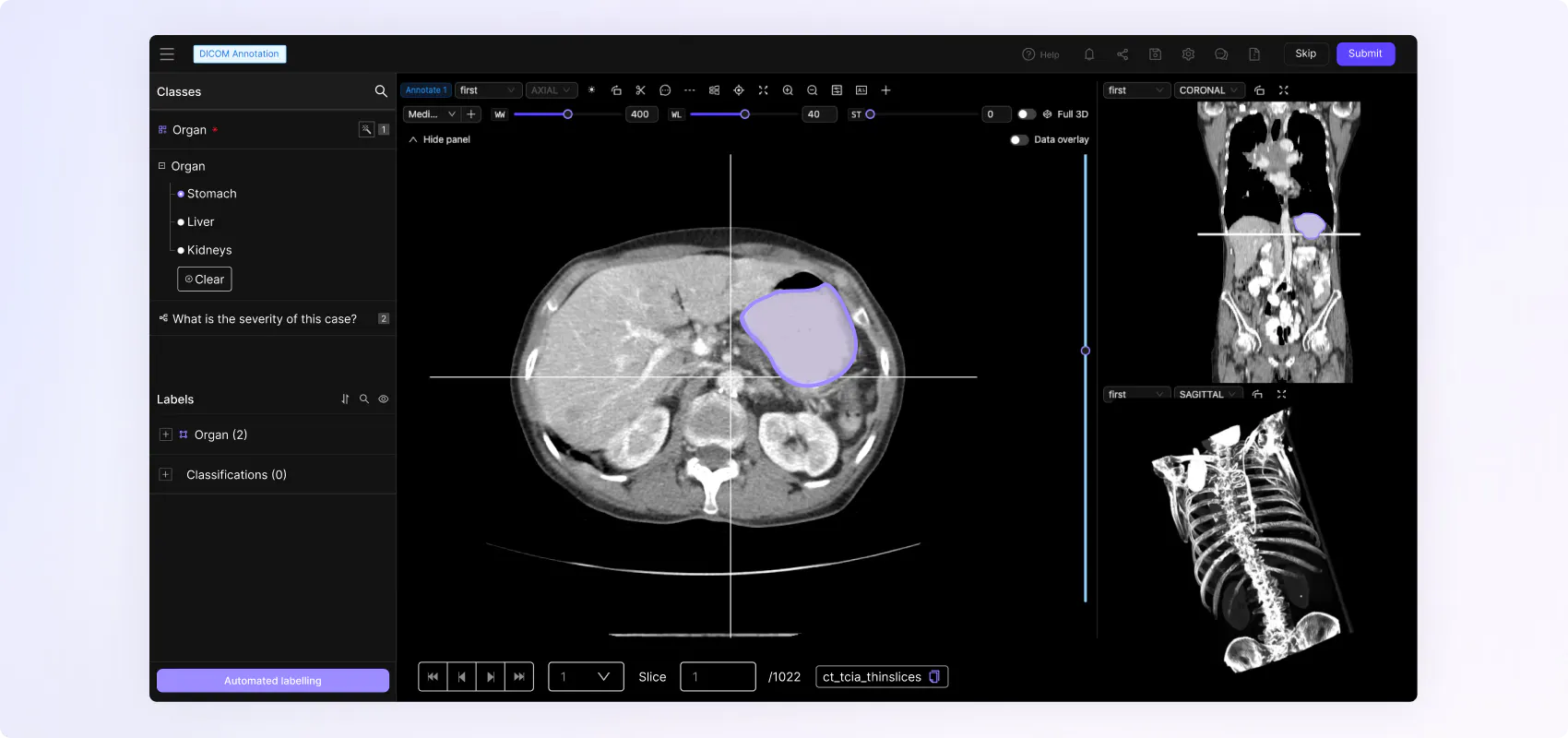
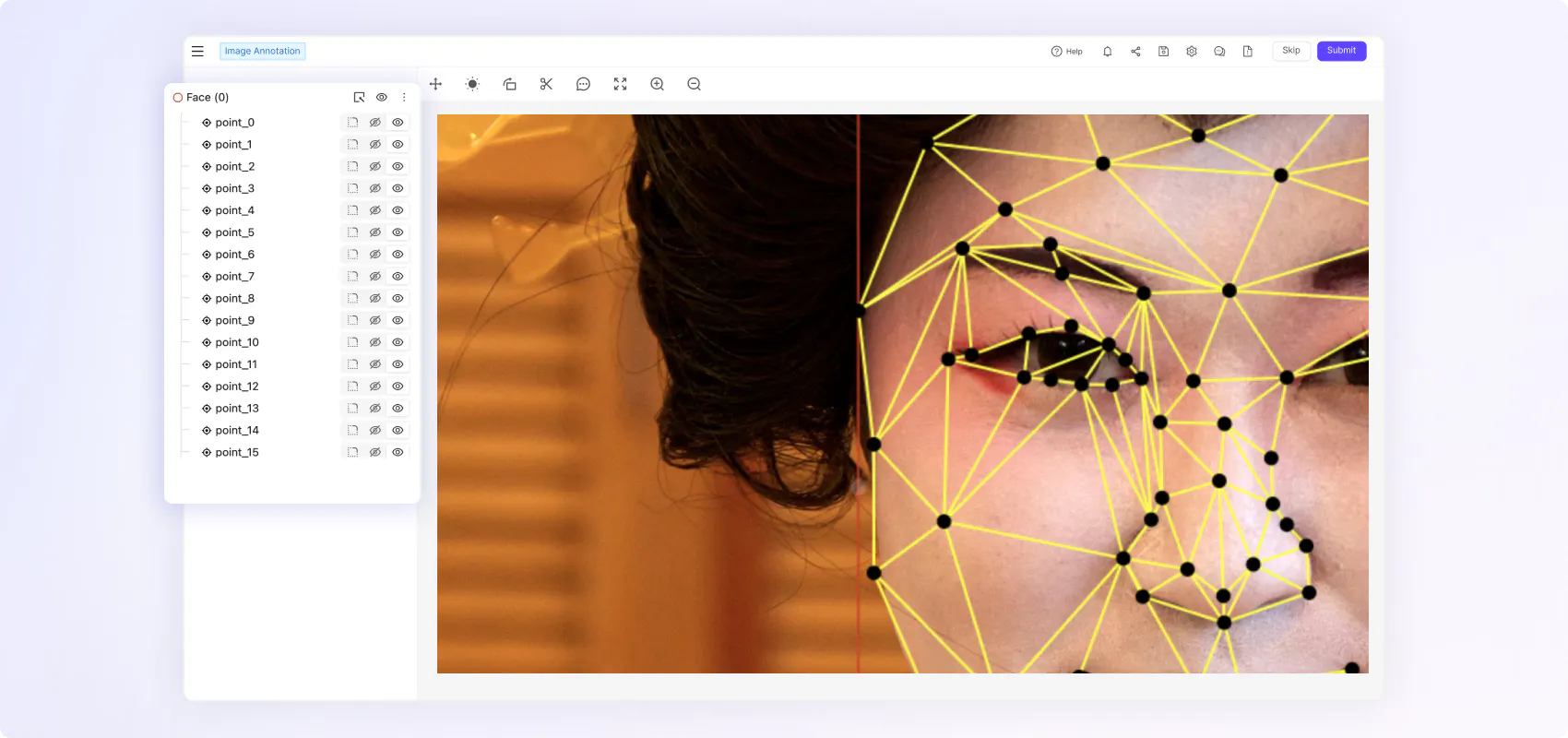
“We needed a platform that enabled various different types of labeling because we have different types of machine learning challenges. Our goal is to diagnose the condition of an object, which requires several steps that include individual issue detection– e.g. damage to a scooter frame– and the condition of where something is placed, like where a scooter is parked.”

Charlotte Bax
Founder at Captur
Increase image annotation throughput and accuracy
Use AI assisted image segmentation and mask prediction to accelerate annotations. Use customizable workflows to orchestrate review steps throughout labeling pipelines for increased label quality. Effectively label the most granular and complex scenarios with nested ontologies and monitor annotator performance with real-time analytics.
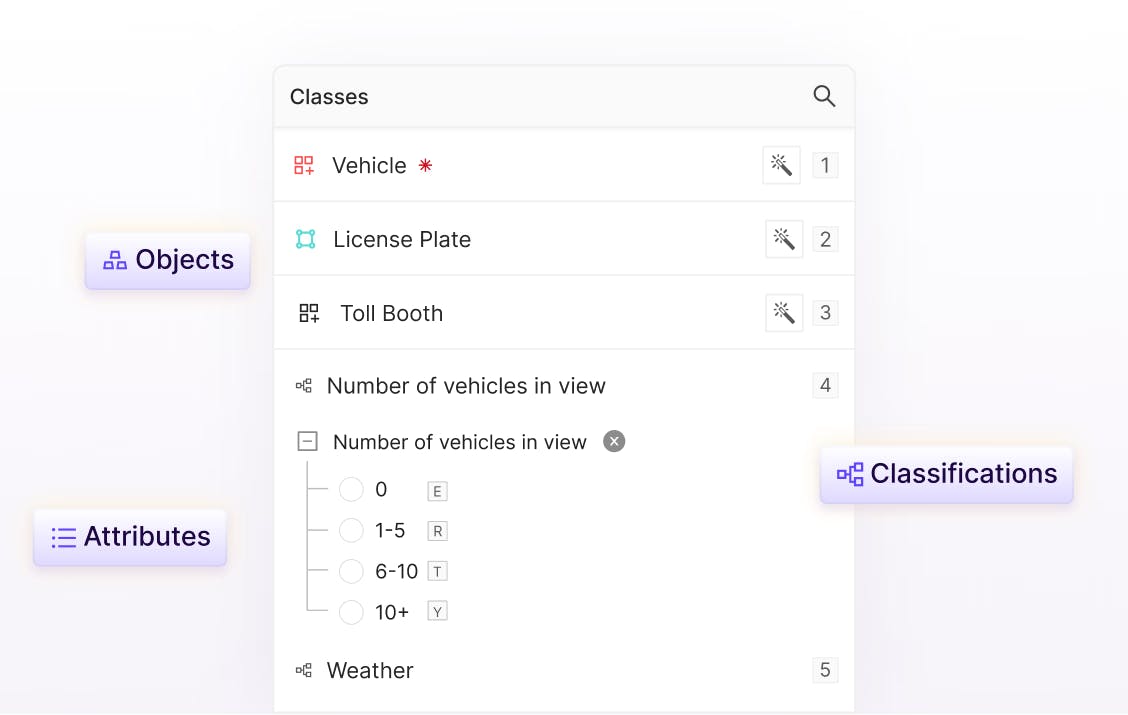
Customizable ontologies for every use case
Create multiple nested classifications with advanced labeling ontologies to establish accurate ground truth datasets.
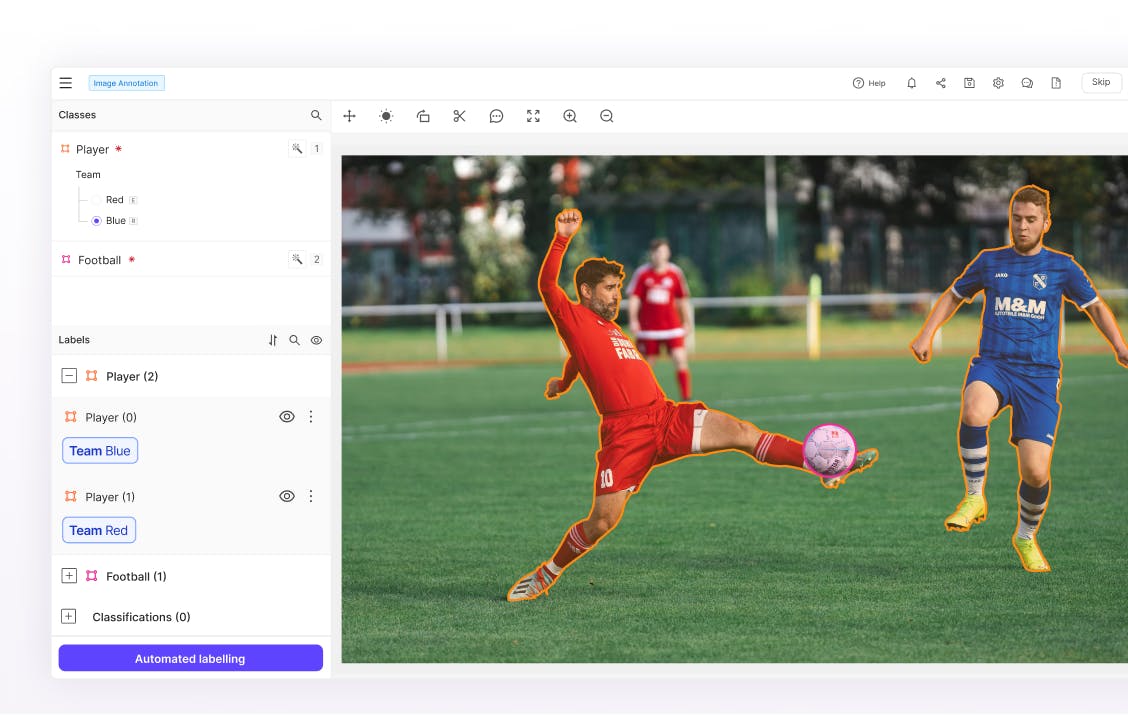
Native AI-assisted labeling with SAM 3
Access SAM 3 natively within Encord for AI-assisted labeling to achieve faster and more accurate mask prediction and object tracking.
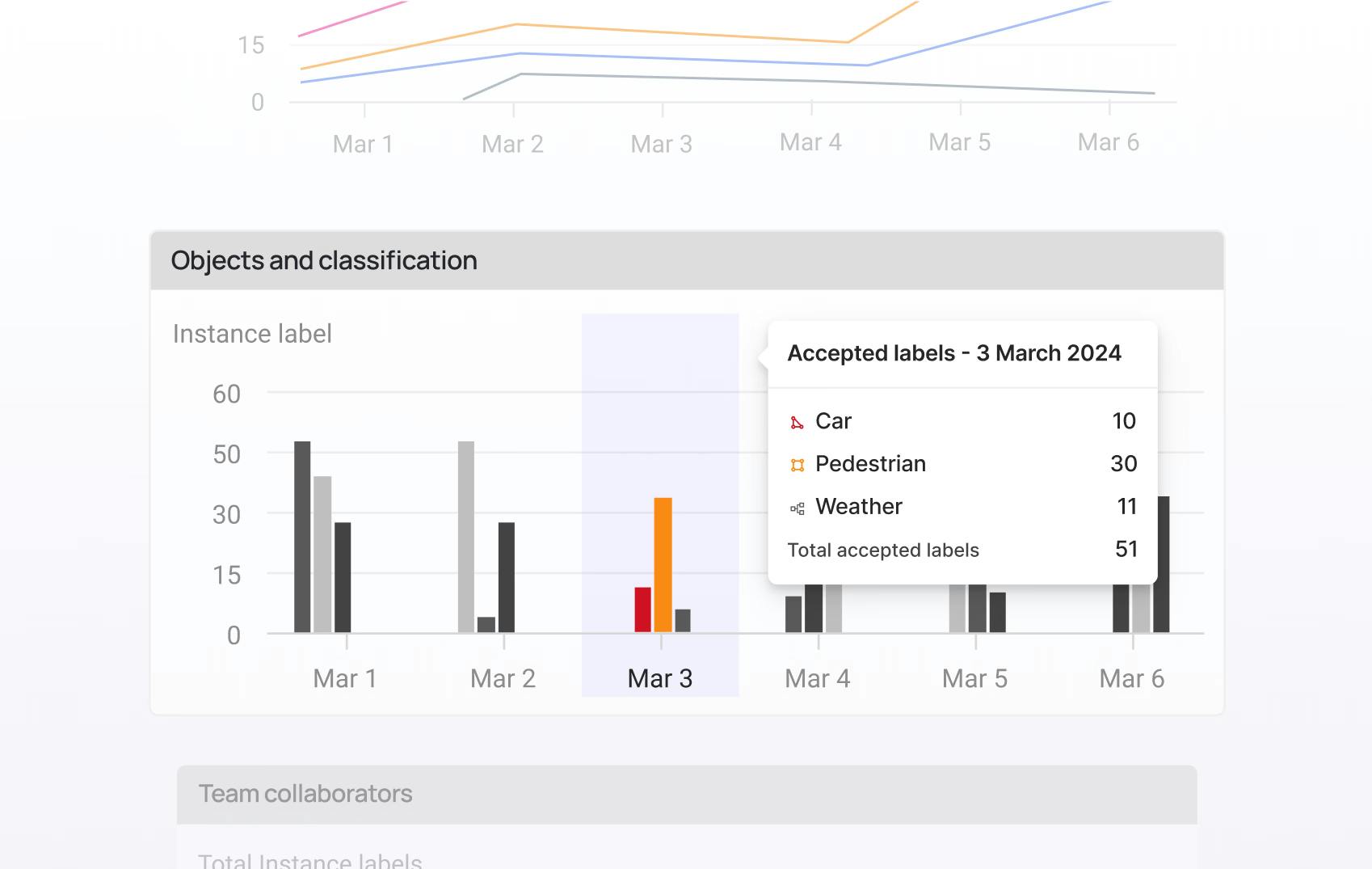
In-depth performance analytics
Uncover rich insights on label quality and annotator performance, to optimize throughput, quality, and workforce efficiency.
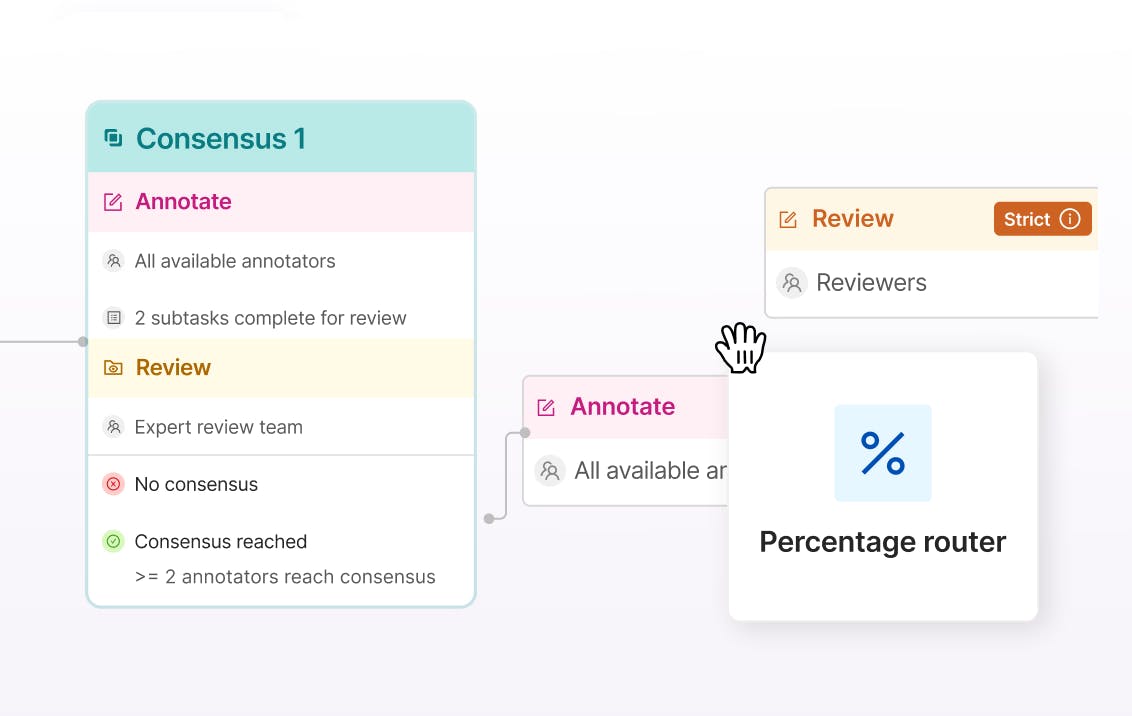
Configurable workflows for quality control
Gaurantee quality control throughout labeling pipelines with customizable data workflows and multi-stage reviews. Assign roles, tasks, and manage project completion.
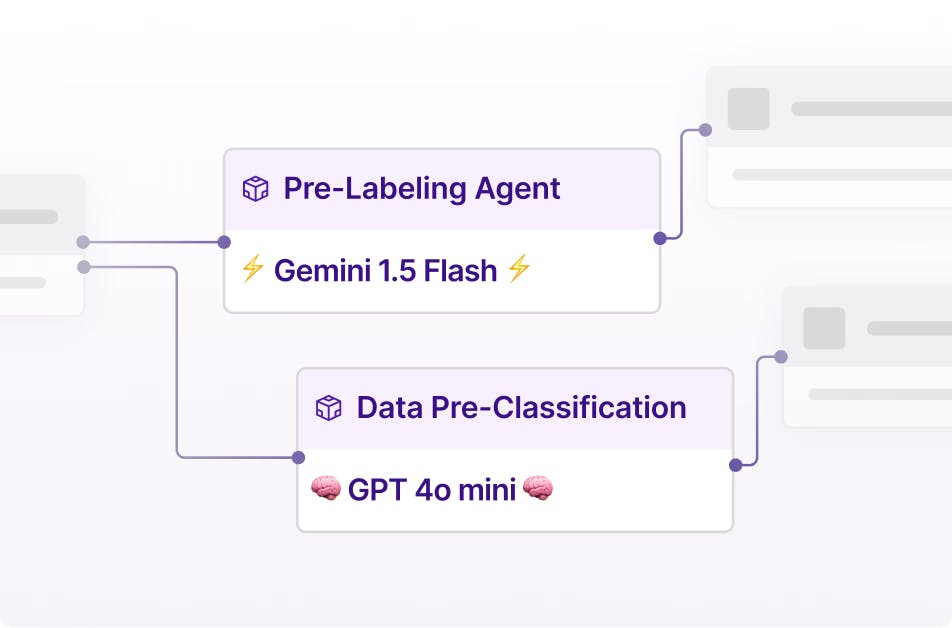
AI-assisted labeling with SOTA foundation models
Integrate SOTA models or your own models directly into your data workflows to automate data reviews, pre-labeling, data classification, filtering, and more.
AI-assisted labeling with SOTA foundation models
Integrate SOTA models or your own models directly into your data workflows to automate data reviews, pre-labeling, data classification, filtering, and more.
Curate and manage billions of images
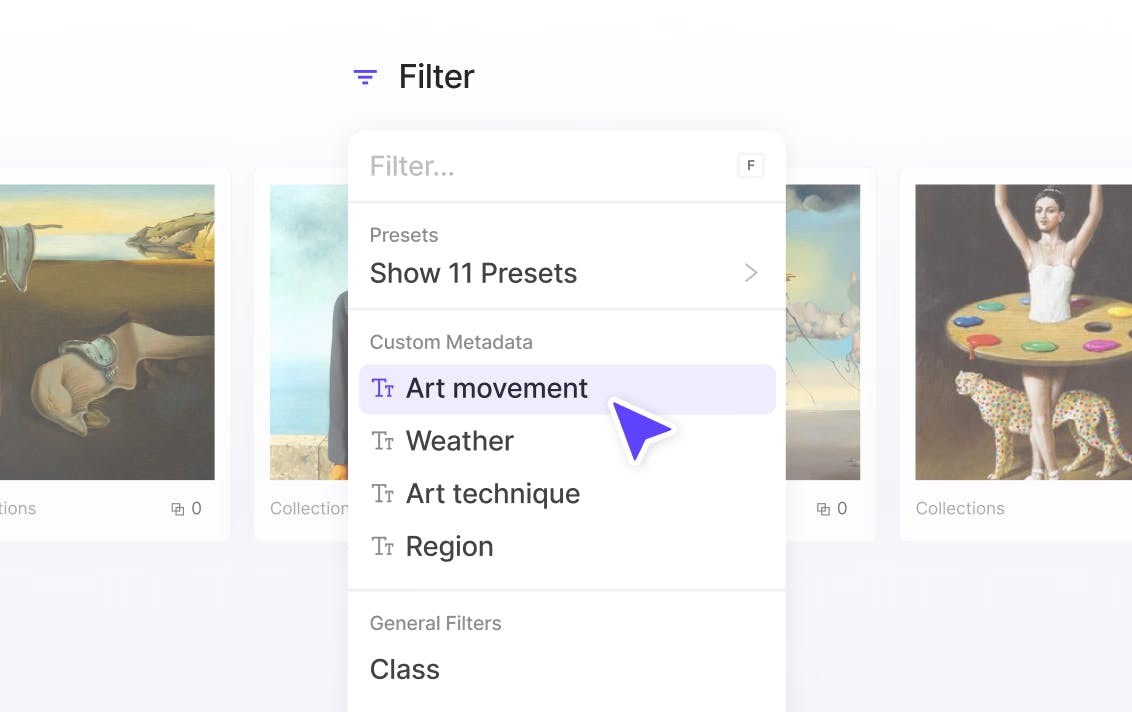
Curate using data metrics and custom metadata
Filter, sort, and organize large image datasets using 40+ data metrics and metadata to efficiently use high quality data for AI model development.
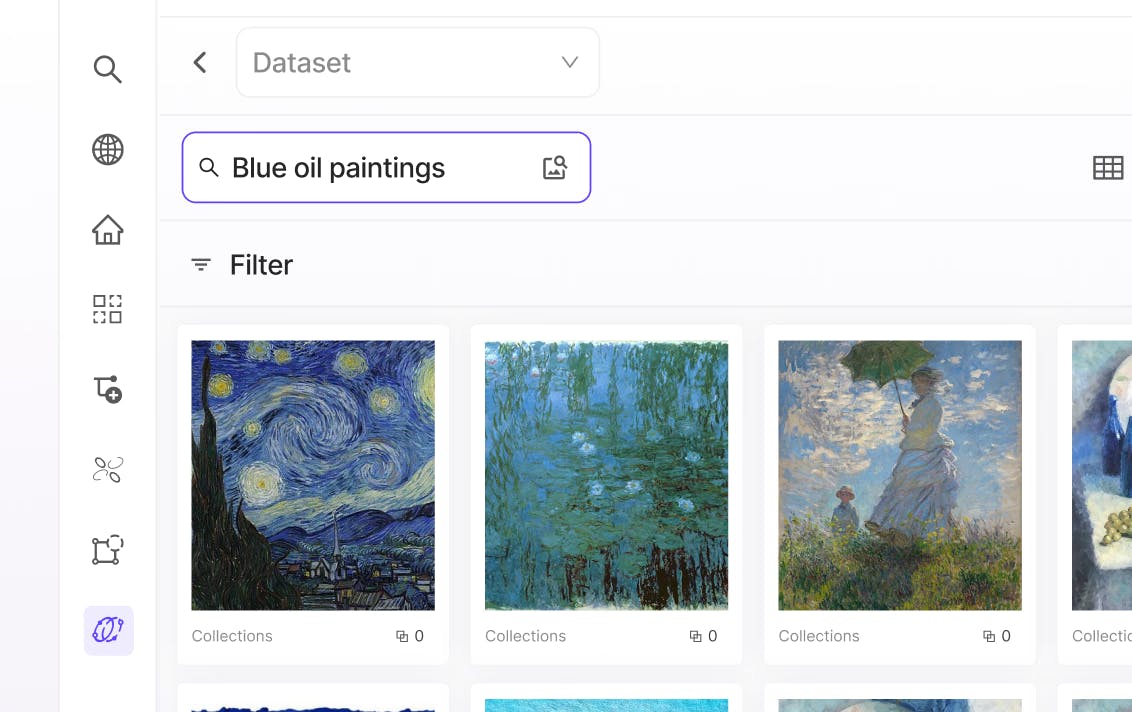
Use English to search large image datasets
Embeddings-based natural language search and similarity search level up data curation to easily discover the most relevant data for AI model training and fine-tuning.
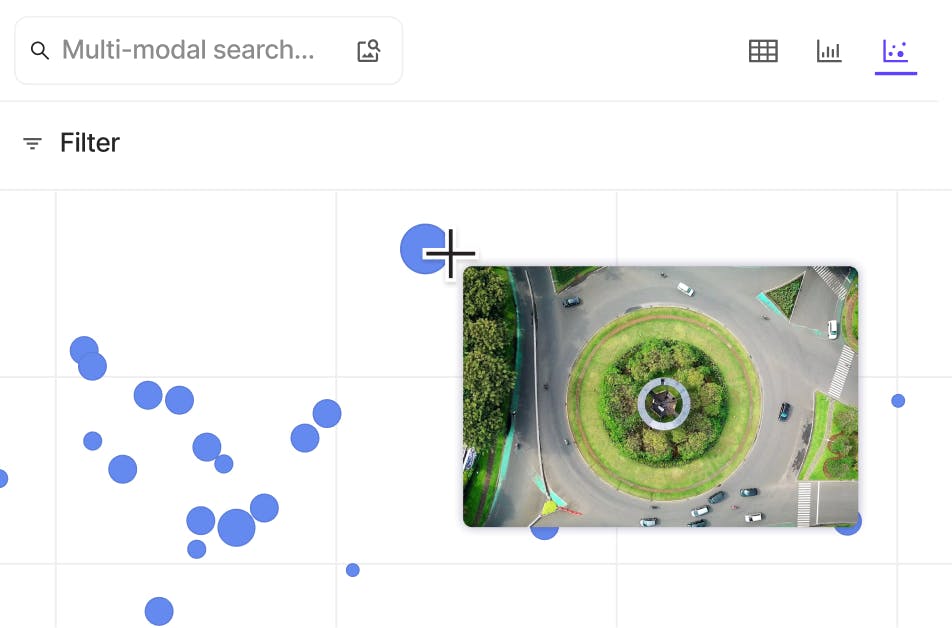
Visually explore with embeddings plots
Identify underrepresented areas, anomalies, and edge cases to create balanced and diverse training datasets to improve model robustness and performance.
Visually explore with embeddings plots
Identify underrepresented areas, anomalies, and edge cases to create balanced and diverse training datasets to improve model robustness and performance.
You're in good company
Encord is used by 300+ frontier AI teams to deploy production-ready AI models.
Frequently asked questions
Encord provides an AI-assisted image annotation platform that combines human-in-the-loop labeling with state-of-the-art models to detect, segment, and classify objects up to 10x faster.
The platform supports rotatable bounding boxes, polygons, polylines, keypoints, classifications, bitmasks, and 3D/object primitives—covering simple to granular image annotation tasks.
Encord supports multimodal data including image, video, documents & text, audio, DICOM & NIfTI for medical imaging, and LiDAR.
Yes. Encord provides managed labeling services alongside the platform, so you can scale high-quality annotations with expert workflows.
Enterprise-grade.
Built for scale.
Designed for reliable AI.
Built for scale.
Designed for reliable AI.
API/SDK-first. Zero data migration. Your data stays in your cloud.
Visit trust centre



Get the data right
300+ of the best AI teams in the world use Encord. Join them.