Encord as a Step Up from CVAT + Voxel51: Why Teams Are Making the Switch

Co-Founder & Co-CEO at Encord
When building computer vision models, many machine learning and data ops teams rely on a combination of open-source tools like CVAT and FiftyOne (Voxel51) to manage annotation and data curation. While this setup can work for small-scale projects, it quickly breaks down at scale, creating friction and inefficiencies.
CVAT handles manual annotation, while Voxel51 mainly powers dataset visualization and filtering. However, neither tool spans the full AI data development lifecycle, leading to fragmented workflows. As complexity increases, particularly with video, LiDAR, or multimodal data, so do the limitations.
In this article, we’ll explore the standard CVAT + Voxel51 workflow, highlight the key bottlenecks teams encounter, and explain why many AI teams are making the switch to Encord — a unified platform designed for scalable, secure, and high-performance data development.
Typical Existing Workflow Stack: CVAT + Voxel51
CVAT and V51 make up different parts of the AI data development pipeline – annotation and visualization. Both of these are key drivers of successful AI development so let’s understand how these two tools play a role to support these processes.
In large scale AI pipelines, before data can be annotated, it needs to be curated. This includes visualising the data and filtering it in order to exclude outliers, get a deeper understanding of the type of data being worked with, or organising it into relevant segments depending on the project at hand. V51 supports this element of the workflow stack by providing interactive dataset exploration, using filters or similarity search. However, it only supports lightweight image labeling capabilities, with very limited automation. Which leads us to the next part of the AI data workflow.
CVAT is used for manual image annotation, such as creating bounding boxes and doing segmentation on visual data. The tool supports a range of annotation types, such as bounding boxes, polygons, polylines, keypoints, and more. It allows for frame-by-frame annotation, tracking, and managing large datasets. However, it does not support frame-based video annotation and only has basic timeline navigation, as it does not natively work with video.
However, since neither of these two tools are built to span the entire AI data pipeline, they need to be chained together. Outlining what this stack would look like, raw data would be visualised in Voxel51, to gain deeper understanding of distributions and edge cases. Then it would be loaded into CVAT for annotation. However then the data would need to be re-imported into V51 to evaluate annotation quality.
The challenge with this workflow is that it is fragmented. One tool handles curation while the other handles annotation. However, the data then has to be moved between platforms. This can lead to inefficiencies within the data pipeline, especially when developing models at scale or iterating quickly. Additionally, this fragmentation means there is no unified review workflow. Once a model is evaluated, the data then has to be handed off between tools, hindering accuracy improvements at scale. This could mean there is little clarity on version control as there is no central history or audit trail.
The CVAT plus V51 workflow is also at the mercy of both tools’ generally sluggish UI. For example, 3D and video are not natively supported and other modalities like audio and text are lacking.
Additionally, for industries with high data security standards, because CVAT and V51 are open source, they are not SOC2 compliant and the lack of traceability can pose risks for those dealing with sensitive data.
Why Teams Should Choose Encord
TL;DR – Top 3 Reasons to Switch:
- Stop wasting time gluing tools together — unify your stack.
- Handle video, LiDAR, and multimodal data natively.
- Scale securely with built-in governance, QA, and automation.
Here are the main reasons ML and data ops teams switch from CVAT + FiftyOne to Encord, based on customers we have engaged with:
Unify their AI data pipeline
Encord serves as the universal data layer for AI teams, covering the entire data pipeline, from curation and annotation to QA and active learning. This eliminates the need to glue together CVAT, V51, and others. With the CVAT plus V51 stack, an additional tool would also need to be used for model evaluation. By unifying their data pipelines, AI teams have been able to achieve faster iteration, less DevOps overhead, and fewer integration failures.
Native video support
For complex use cases that require native video annotation, such as physical AI, autonomous vehicles, and logistics, native video support is key. Encord is built for annotating video directly rather than breaking it into frames that have to be annotated individually. When videos are annotated at the frame level, as if they were a collection of images, there is greater risk of error as frames can be missed. A tool that has native video support allows for keyframe interpolation, timeline navigation, and real-time preview. All of which drive greater efficiency and accuracy for developing AI at scale. Additionally, support for long-form videos (up to 2 hours, 200k+ frames) means that thousands of hours of footage can be annotated. This is often the case for physical AI training.

Built-In active learning and labeling
Traditional annotation workflows (like CVAT + Voxel51) are heavily manual. Encord, however, provides native active learning and automated pre-labeling for feedback-driven workflows. Instead of labeling every piece of data, Encord helps you prioritize the most high-impact data to label. You can intelligently sample based on embedding similarity, performance metrics, etc.
Model integration in Encord allows users to plug in their own models to automate labeling and integrate predictions directly into the annotation workflow. These predictions can be used as initial pre-labels, which annotators only need to verify or correct, dramatically reducing time spent on repetitive tasks.
Using pre-labeling to annotate large datasets automatically, then route those to human reviewers for validation reduces manual effort. It also allows for targeting the most impactful data, teams using Encord can reduce annotation costs, speed up model training cycles and increase annotation throughput.
Scales with business needs
Because Encord is an end to end data platform, data pipelines can scale with business needs and volumes of data. When it comes to increasing volumes of data, it supports millions of images and frames and up to 5M+ labels/project, whereas CVAT supports 250K - 500K. As a dataset grows, many tools (like CVAT or other open-source platforms) begin to lag, freeze, or break entirely. For example, teams risk the UI taking seconds (or minutes) to load a single frame or even crash during long video sessions or when using complex ontologies. However, Encord is purpose-built to handle large-scale datasets efficiently; it also has fast API calls for programmatic access (Python SDK, integrations) that return quickly even when querying huge data volumes. Therefore, your annotators don’t lose time waiting for images or tools to load. And, developers and MLOps teams can run queries or updates programmatically without performance bottlenecks Finally, faster iteration loops mean quicker time to model improvements.
A key feature of Encord that allows for scaling model development is that it allows for 100+ annotators working concurrently, without degrading performance. At the same time, model training can run in parallel, leveraging continuously labeled data to update models faster. To keep teams organized and efficient, Encord includes workflow management tools like task assignment, progress tracking, built-in reviewer roles, and automated QA routing, making it easy to manage large, distributed labeling teams without losing oversight or quality control.
Comparing CVAT, Voxel 51 & Encord for scaling data development:
| Capability | CVAT | Voxel51 | Encord |
| Max # of images/frames per project | ~250k–500k (UI slows significantly) | Scales better, but not designed for annotation at scale | ✅ 1M+ images, 200k+ frames/video |
| Max # of labels per project | ~1M practical ceiling (performance degrades) | N/A (not an annotation tool) | ✅ 5M+ labels/project |
| Concurrent annotators | Limited collaboration support | N/A | ✅ 100+ active users per project |
| Video support | ❌ Frame-based only (no native video UI) | ❌ No annotation tools | ✅ Native video engine (timeline, keyframes) |
| 3D / LiDAR support | 🟡 Basic cuboid in image only (no PCD support) | 🟡 Visualization only (no native annotation) | ✅ Native support: PCD, cuboids w/ RPY, projection, polylines |
| Multi-sensor / Multi-view | ❌ No native support | ❌ Manual stitching | ✅ Yes, supports multi-sensor fusion projects |
| Performance at scale | ⚠️ Slows down with larger datasets | ✅ Good for exploration, but not part of data ops loop | ✅ Optimized backend + infra for massive datasets |
SOC2-Compliant with Full Traceability
CVAT and FiftyOne are powerful tools, but they are not built for enterprise data governance or QA at scale. For example, they lack reviewer approval flows. CVAT, for instance, doesn’t have a built-in way to assign reviewers, approve/reject annotations, or track review status. However, this is key in enterprise settings to ensure high-quality outputs for downstream ML models. Without this, QA is manual, ad hoc, and hard to scale.
Additionally, open-source tools aren’t SOC2 compliant and lack enterprise-grade security features. SOC2 is a rigorous standard for data handling, access controls and audit logging. It is essential for ML teams working with regulated data (e.g. healthcare, finance, defense). Therefore, teams might choose to switch to Encord for role-based access controls, SSO integration and SOC2 compliance when working in specific industries.
Multimodal & 3D native support
When it comes to AI development, multimodal capabilities are crucial across a number of different use cases. For example, in surgical video applications, data is required across video, image and documents for maximum context on not only surgery but also the patient’s medical history. For teams requiring 3D, video or other modalities, a platform that can support multiple allows for more accurate and streamlined workflows.
Businesses with complex use cases also require a platform that can handle multi-camera, multi-sensor projects (e.g. LiDAR + RGB). Multiple angles can also be annotated within one frame, providing annotators with additional context without having to switch between tabs to improve efficiency.
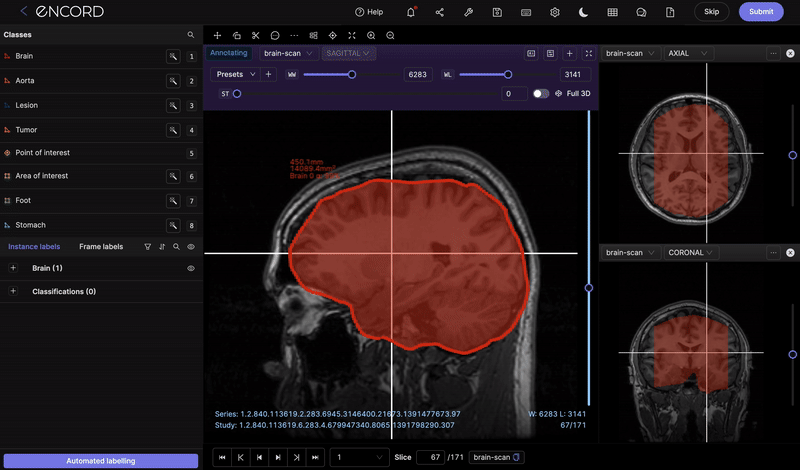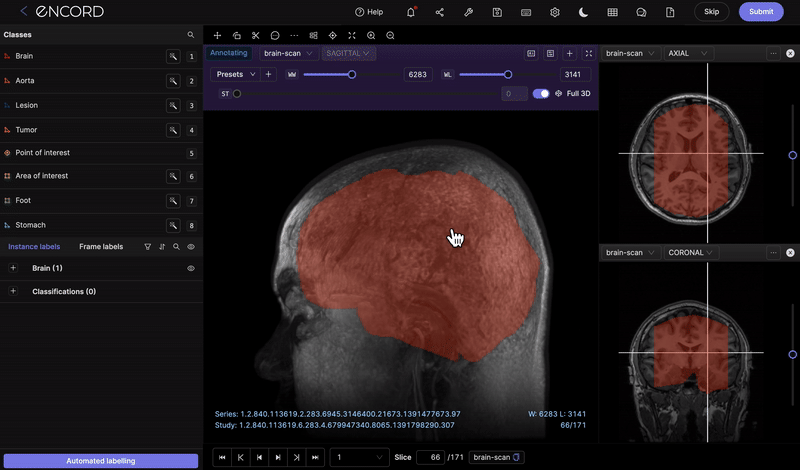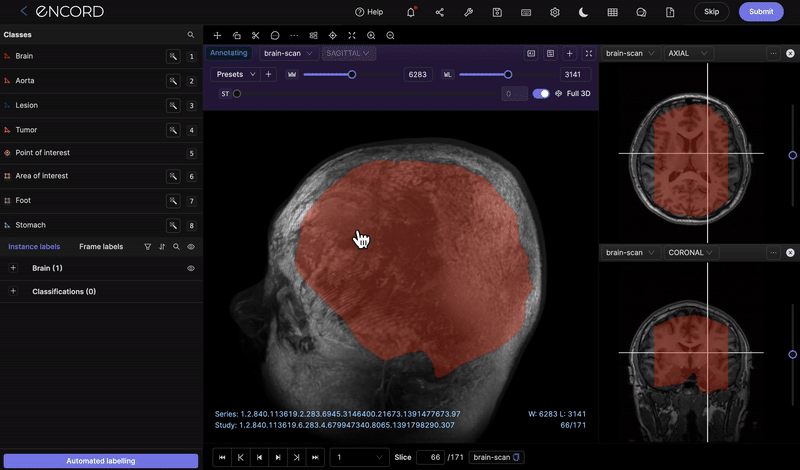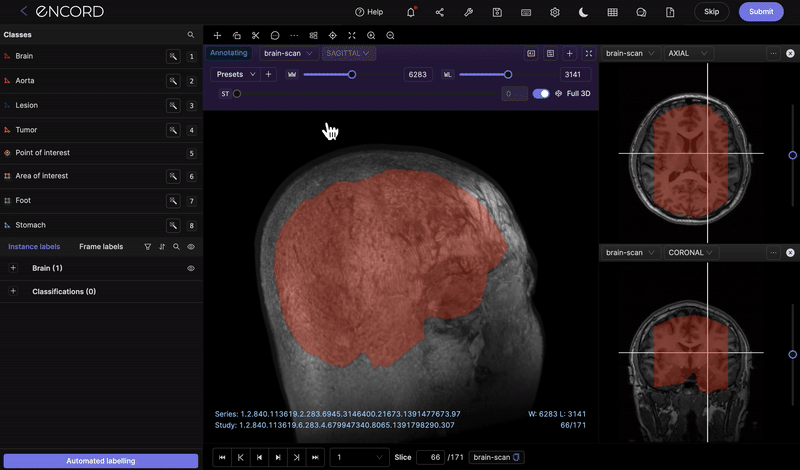
QA, Review, and Annotation Analytics
When it comes to scaling AI data pipelines, having more annotators is step one. However, this requires management and QA, especially if annotation is outsourced. Having built-in review workflows ensures that annotations are correct, especially in cases where annotators need industry-specific knowledge to label successfully.
Not only can users build review workflows in Encord but these workflows can be automated using agents. Reviewers can be assigned to certain tasks and leaders can assess annotators’ work through the analytics dashboard. Additionally, label accuracy metrics and consensus scoring are built in, flagging low-consensus annotations for QA.
Resolution of discrepancies happen directly in the platform, allowing for quick iteration and maximum accuracy. Most open-source tools like CVAT don’t offer this – you have to build it yourself with scripts or custom QA layers. Encord gives you this out of the box, making quality management and scale possible without reinventing infrastructure.

Faster Onboarding and Migration
Encord supports direct imports from the most common open-source formats, so teams can migrate quickly without re-labeling or writing custom scripts. This includes but is not limited to: CVAT (XML, JSON) and COCO (JSON). You can upload your existing labels as-is, and Encord will automatically convert them into the internal format with matching ontology and label structure.
There is also no need to write scripts or use third-party conversion tools as Encord includes a visual ontology mapping tool (to match your old classes to the new schema) as well as annotation converters that handle anything from bounding boxes to 3D cuboids. It also supports multi-class, multi-object, and nested hierarchies. For example, if you’ve labeled images in YOLO format, you can import that straight into Encord, and continue working immediately.
Another key reason using Encord beats the CVAT plus Voxel 51 stack is that it offers dedicated onboarding support (especially for mid-size and enterprise customers) and hands-on help to migrate your data. This reduces friction and helps your team become productive within days.
Key Takeaway
The combination of CVAT and Voxel51 has served many ML teams well for early-stage experimentation, but it comes with trade-offs: disconnected workflows, limited scalability, and manual QA overhead. As teams grow and use cases become more complex, particularly involving video, 3D, or multi-sensor data, this stack hinders scaling.
Encord offers a step-change improvement by unifying annotation, curation, review, and automation in one secure platform, removing the need to use multiple tools, write custom scripts, or manually manage QA processes. Teams switching to Encord can achieve 10–100x improvements in throughput, better model iteration speed, and far less operational complexity.
If you're hitting the ceiling of open-source tooling and need an AI data platform that can scale, it's time to consider a switch.
Frequently asked questions
Encord's platform is designed to support a wide range of projects, particularly those involved in building machine learning models. Whether it's analyzing advertising campaigns, developing computer vision applications, or exploring narrative structures in video content, our tools and services cater to diverse data preparation needs across various industries.
Encord offers several advantages over open-source labeling tools, such as increased scalability and advanced features for sophisticated classifications. Unlike many open-source platforms, Encord utilizes AI-assisted labeling to enhance efficiency and reduce the manual effort required, making it a more robust solution for organizations at scale.
Encord allows reviewers to set up customizable variables for rating annotators. These can include options such as a numeric scale from one to five, free text fields for qualitative feedback, and boolean responses for yes/no questions. This flexibility ensures that the evaluation criteria can be tailored to specific needs.
Turbo mode in Encord is a feature designed to expedite the quality assurance (QA) process by allowing annotators to quickly review the pre-populated results. This mode enables rapid checking of annotations, making it easier to ensure high-quality outputs without spending excessive time on each image.
Encord includes best-in-class tools for model evaluation, enabling users to identify areas where models perform well or poorly. This insight allows teams to selectively incorporate specific data or labels back into the annotation workflow, streamlining the overall model development process.
Encord's platform is built from the ground up, allowing for greater adaptability and customization compared to competitors who often rely on open-source solutions. This foundational strength enables us to cater to a wide array of data modalities and continuously evolve to meet users' needs.
Encord Index plays a pivotal role in the data curation process by providing a structured overview of the platform and the data being handled. It helps users navigate through different areas of the tool effectively, ensuring a streamlined approach to data management and annotation.
Yes, Encord can support multiple annotators for a project. While a dedicated annotator offers consistency and efficiency, the platform also allows for consensus-based annotation, enabling your team to involve multiple members or average input from a crowd for subjective tasks.
Yes, Encord allows users to configure custom classes and attributes for each annotation project. This adaptability ensures that the platform can meet the specific needs of various projects, making it a versatile tool for different applications.
Encord consolidates various data management processes into a single platform, reducing the need for multiple tools. It allows for effective management of both internal and external annotators, streamlining workflows and enhancing productivity.