NVLM 1.0: NVIDIA's Open-Source Multimodal AI Model

Nvidia has released a family of frontier-class multimodal large language models (MLLMs) designed to rival the performance of leading proprietary models like OpenAI’s GPT-4 and open-source models such as Meta’s Llama 3.1.
In this blog, we’ll break down what NVLM is, why it matters, how it compares to other models, and its potential applications across industries and research.
What is NVLM?
NVLM, short for NVIDIA Vision Language Model, is an AI model developed by NVIDIA that belongs to the category of Multimodal Large Language Models (MLLMs). These models are designed to handle and process multiple types of data simultaneously, primarily text and images, enabling them to understand and generate both textual and visual content. NVLM 1.0, the first iteration of this model family, represents a significant advancement in the field of vision-language models, bringing frontier-class performance to real-world tasks that require a deep understanding of both modalities.
At its core, NVLM combines the power of large language models (LLMs), traditionally used for text-based tasks like natural language processing (NLP) and code generation, with the ability to interpret and reason over images. This fusion of text and vision allows NVLM to tackle a broad array of complex tasks that go beyond what a purely text-based or image-based model could achieve.

NVLM: Open Frontier-Class Multimodal LLMs
Key Features of NVLM
State-of-the-Art Performance
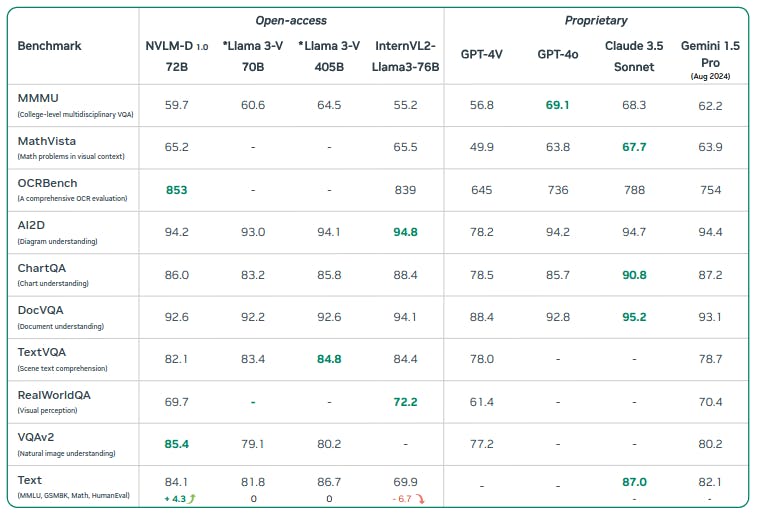
NVLM is built to compete with the best, both in the proprietary and open-access realms. It achieves remarkable performance on vision-language benchmarks, including tasks like Optical Character Recognition (OCR), natural image understanding, and scene text comprehension. This puts it in competition with leading proprietary artificial intelligence models like GPT-4V and Claude 3.5 as well as open-access models such as InternVL 2 and LLaVA.
Improved Text-Only Performance After Multimodal Training
One of the most common issues with multimodal models is that their text-only performance tends to degrade after being trained on vision tasks. However, NVLM improves on its text-only tasks even after integrating image data. This is due to the inclusion of a curated, high-quality text dataset during the supervised fine-tuning stage. This ensures that the text reasoning capabilities of NVLM remain robust while enhancing its vision-language understanding.
This feature is especially important for applications that rely heavily on both text and image analysis, such as academic research, coding, and mathematical reasoning. By maintaining—and even improving—its text-based abilities, NVLM becomes a highly versatile tool that can be deployed in a wide range of settings.
NVLM’s Architecture: Key Features
Decoder-Only vs Cross-Attention Models
NVLM introduces three architectural options: NVLM-D (Decoder-only), NVLM-X (Cross-attention-based), and NVLM-H (Hybrid). Each of these architectures is optimized for different tasks:
- Decoder-only models treat image tokens the same way they process text token embeddings, which simplifies the design and unifies the way different types of data are handled. This approach shines in tasks that require reasoning with both text and images simultaneously.
- Cross-attention transformer models process image tokens separately from text tokens, allowing for more efficient handling of high-resolution images. This is particularly useful for tasks involving fine details, such as OCR or document understanding.
- Hybrid models combine the strengths of both approaches, using cross-attention for handling high-resolution images and decoder-only processing for reasoning tasks. This architecture balances computational efficiency with powerful multimodal reasoning capabilities.
Dynamic High-Resolution Image Processing
Instead of processing an entire image at once (which can be computationally expensive), NVLM breaks the image into tiles and processes each tile separately. It then uses a novel 1-D "tile tagging" system to ensure that the model understands where each tile fits within the overall image.
This approach of dynamic tiling mechanism boosts performance on tasks like OCR, where high-resolution and detailed image understanding are critical. It also enhances reasoning tasks that require the model to understand the spatial relationships within an image, such as chart interpretation or document understanding.
NVLM’s Training: Key Features
High-Quality Training Data
The training process is split into two main phases: pretraining and supervised fine-tuning. During pretraining, NVLM uses a diverse set of high-quality datasets, including captioning, visual question answering (VQA), OCR, and math reasoning in visual contexts. By focusing on task diversity, NVLM ensures that it can handle a wide range of tasks effectively, even when trained on smaller datasets.
Supervised Fine-Tuning
After pretraining, NVLM undergoes supervised fine-tuning (SFT) using a blend of text-only and multimodal datasets. This stage incorporates specialized datasets for tasks like OCR, chart understanding, document question answering (DocVQA), and more.
The SFT process is critical for ensuring that NVLM performs well in real-world applications. It not only enhances the model’s ability to handle complex vision-language tasks but also prevents the degradation of text-only performance, which is a common issue in other models.
NVLM vs Other SOTA Vision Language Models
NVLM competes directly with some of the biggest names in AI, including GPT-4V and Llama 3.1. So how does it stack up?
NVLM: Open Frontier-Class Multimodal LLMs
- GPT-4V: While GPT-4V is known for its strong multimodal reasoning capabilities, NVLM achieves comparable results, particularly in areas like OCR and vision-language reasoning. Where NVLM outperforms GPT-4V is in maintaining (and even improving) text-only performance after multimodal training.
- Llama 3-V: Llama 3-V also performs well in multimodal tasks, but NVLM’s dynamic high-resolution image processing gives it an edge in tasks that require fine-grained image analysis, like OCR and chart understanding.
- Open-Access Models: NVLM also outperforms other open-access vision models, like InternVL 2 and LLaVA, particularly in vision-language benchmarks and OCR tasks. Its combination of architectural flexibility and high-quality training data gives it a significant advantage over other models in its class.
Applications of NVLM

NVLM: Open Frontier-Class Multimodal LLMs
Here are some of the real-world applications of NVLM based on its capabilities:
- Healthcare: NVLM could be used to analyze medical images alongside text-based patient records, providing a more comprehensive understanding of a patient’s condition.
- Education: In academic settings, NVLM can help with tasks like diagram understanding, math problem-solving, and document analysis, making it a useful tool for students and researchers alike.
- Business and Finance: With its ability to process both text and images, NVLM could streamline tasks like financial reporting, where the AI could analyze both charts and written documents to provide summaries or insights.
- Content Creation: NVLM’s understanding of visual humor and context (like memes) could be used in creative industries, allowing it to generate or analyze multimedia content.
How to Access NVLM?
NVIDIA is open-sourcing the NVLM-1.0-D-72B model, which is the 72 billion parameter decoder-only version. The model weights are currently available for download and the training code will be made public to the research community soon. To enhance accessibility, the model has been adapted from Megatron-LM to the Hugging Face platform for easier hosting, reproducibility, and inference.
Frequently asked questions
Encord supports complex workflows for multimodal AI projects, including the use of large language models (LLMs) and vision-language models (VLMs). These advanced features enable users to implement intricate annotation tasks, such as evaluating queue scenarios and assessing object presence in varied inputs, which are essential for building accurate AI models.
While Encord primarily focuses on the annotation and preparation of data, we understand the complexities involved in multimodal data analysis, especially for video content. Our platform can help curate and annotate the necessary datasets, enabling users to build models that analyze multiple data types, such as text, sound, and visuals, for deeper insights.
Encord is equipped to manage multimodal data annotation, enabling users to annotate complex datasets such as video and images. Our platform supports various annotation types and can cater to specific use cases, such as segmenting humans in inward-facing camera footage, providing comprehensive solutions for challenging annotation requirements.
Encord facilitates the annotation of various data types, including video, audio, and image data, making it suitable for diverse applications such as object detection, audio classification, and more. This multimodal support allows users to integrate different types of data sources for comprehensive model training.
Encord supports various integration options for multimodal robot data, allowing users to seamlessly incorporate video, sensor data, and robot state measurements into their annotation processes. This flexibility is vital for developing comprehensive AI systems in robotics.
Encord specializes in audio annotations and is unique in its ability to handle multimodal data, allowing users to annotate audio in conjunction with other assets such as video. This flexibility supports a wide range of applications, enhancing the training of AI models.
Encord provides a comprehensive platform for visualizing and managing multimodal data, including audio, video, and text documents. Users can effectively organize their datasets, understand their data, and prepare it for labeling to create training data for AI models.
Encord supports multimodal annotation, allowing users to annotate various types of data, such as combining temperature sensor data with CCTV footage. This capability is essential for industries like robotics, where complex data visualization is required.
Encord supports a variety of data types, including image data, Lidar, and point clouds. This multimodal approach allows teams to leverage different data sources to create more comprehensive and accurate models for autonomous driving applications.
Yes, Encord can support annotation needs for multiple AI models by providing scalable tools that can accommodate various project requirements. This flexibility is key for teams managing numerous models in production and development.