Deploy production AI faster
with leading AI teams
Join thousands of ML practitioners deploying production-ready AI applications using best-in-class data curation, labeling, and model evaluation tools with Encord.
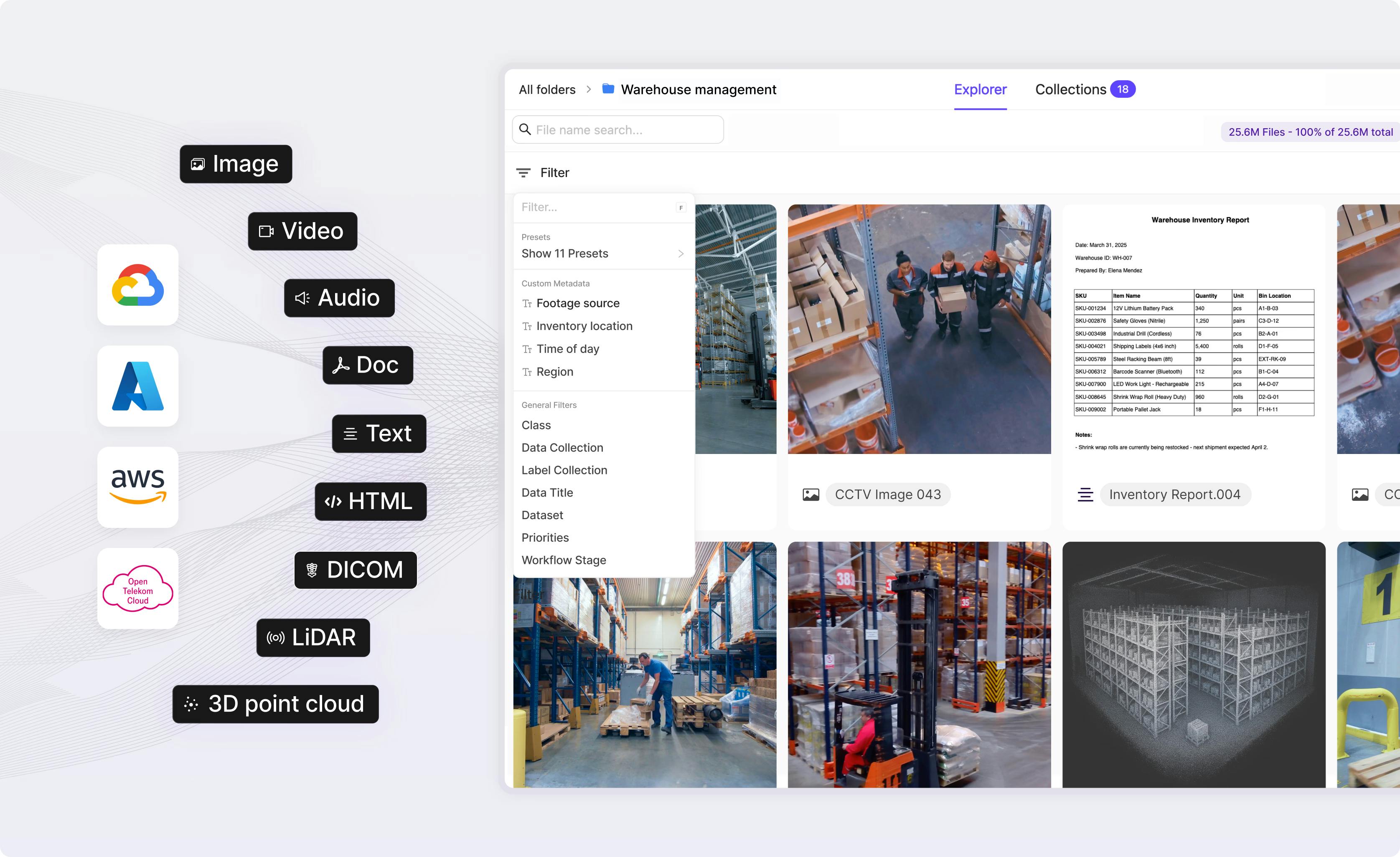
The most scalable way to manage, curate and annotate AI data
Transform petabytes of unstructured multimodal data into high quality data for training, fine-tuning, and aligning AI models, fast.
Trusted by pioneering AI Teams
Deploy production AI faster
with leading AI teams

Nick Gillian
Founder & Head of AI
Archetype
“Encord brought together scalability, video-native annotation, clear label visibility, and the flexibility to support other modalities in a single, cohesive platform.”
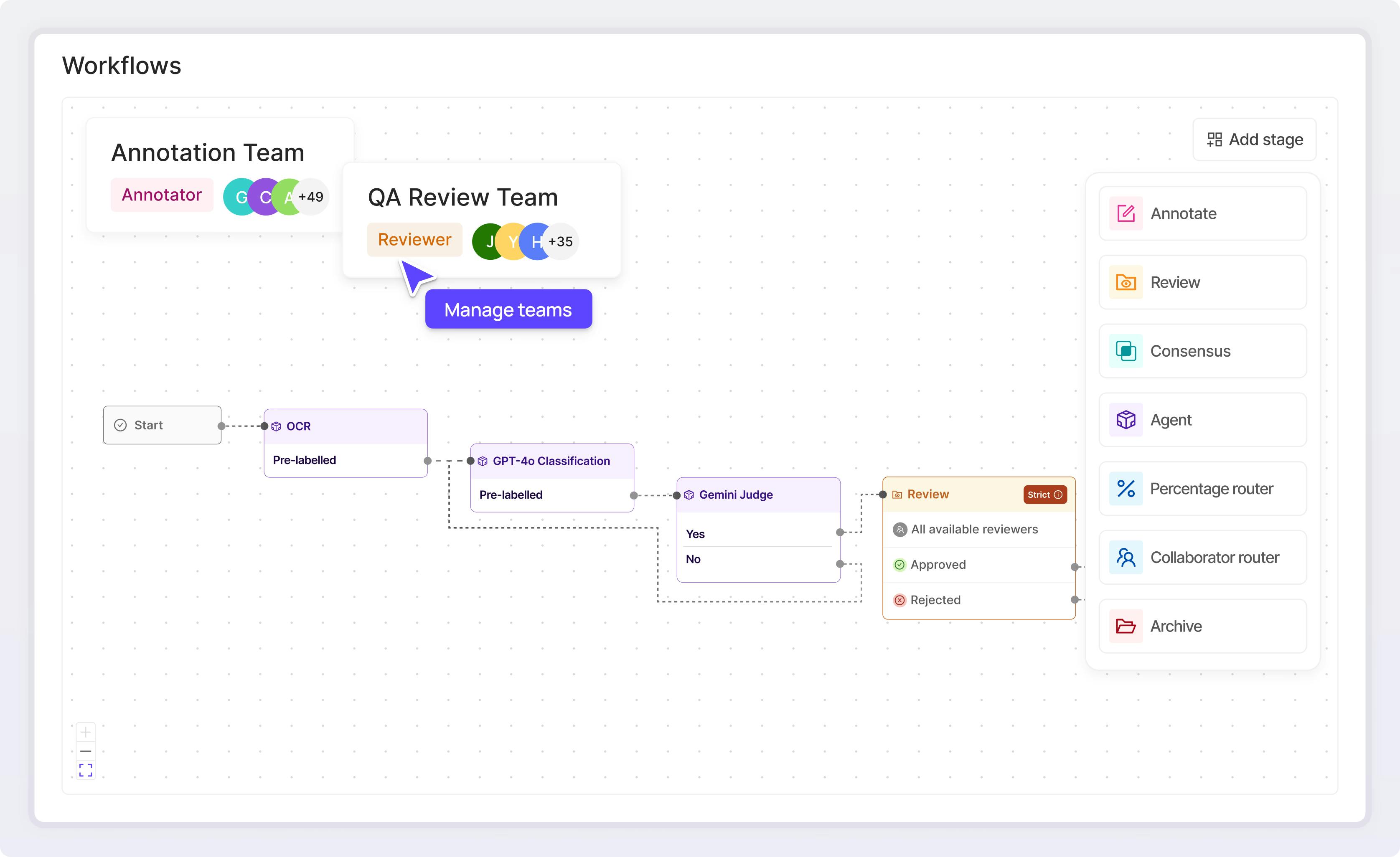
Read case studyIndex and curate petabytes of data
Securely manage and organize millions of unstructured files with full visibility and traceability of data lineage.
Explore Index
40,000 images efficiently curated for Conxai

25% reduction in dataset size for Automotus
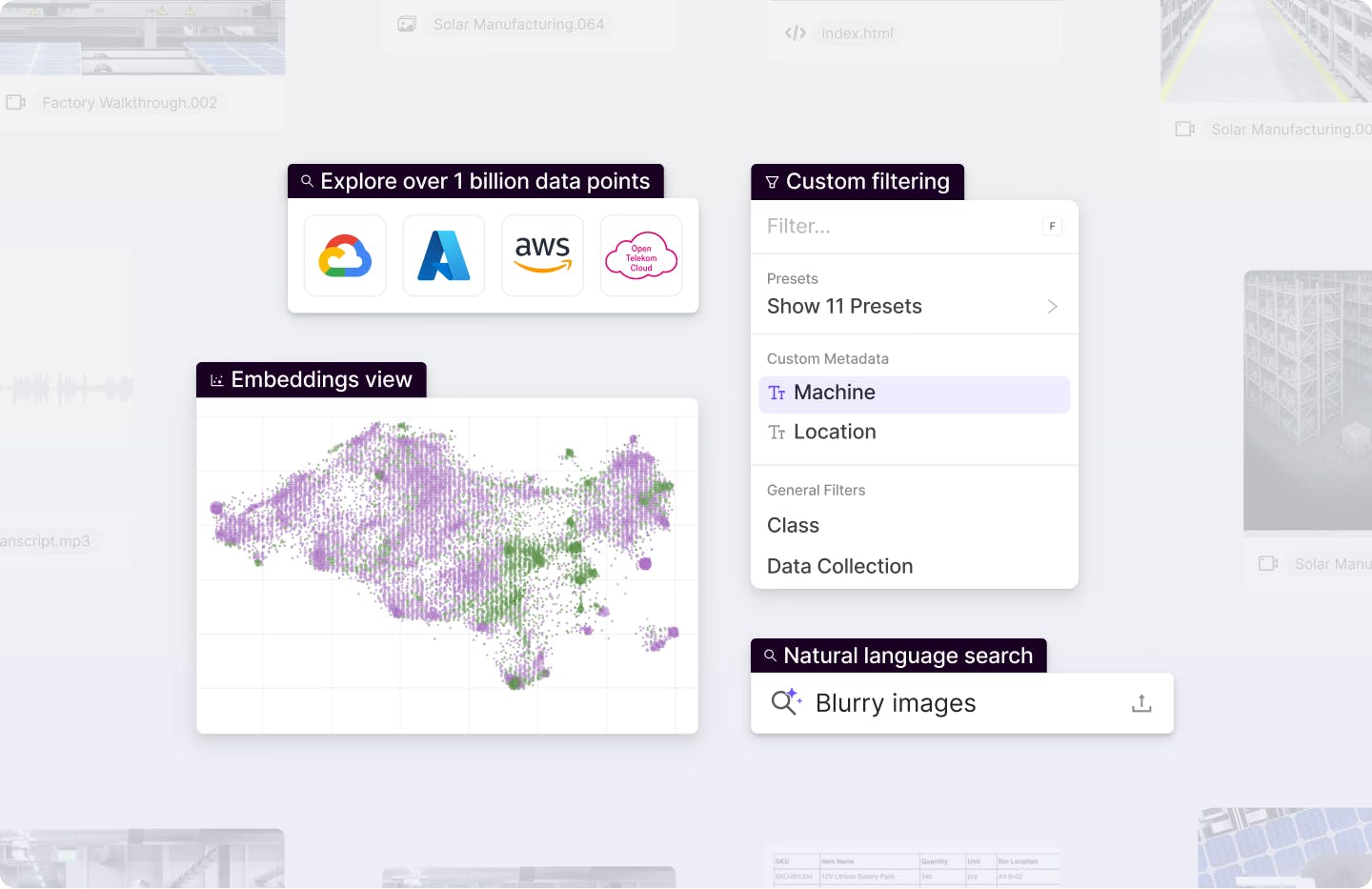
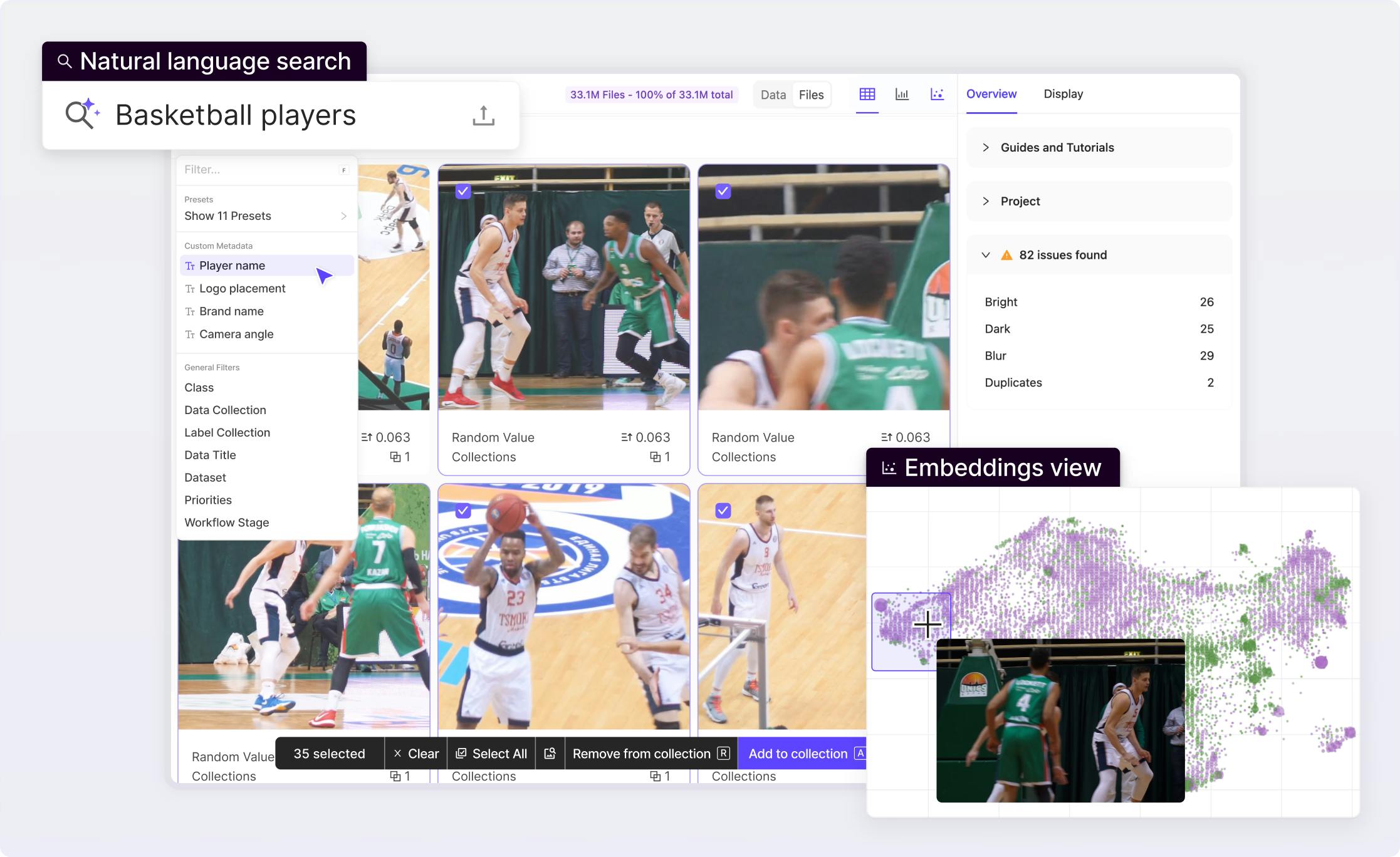
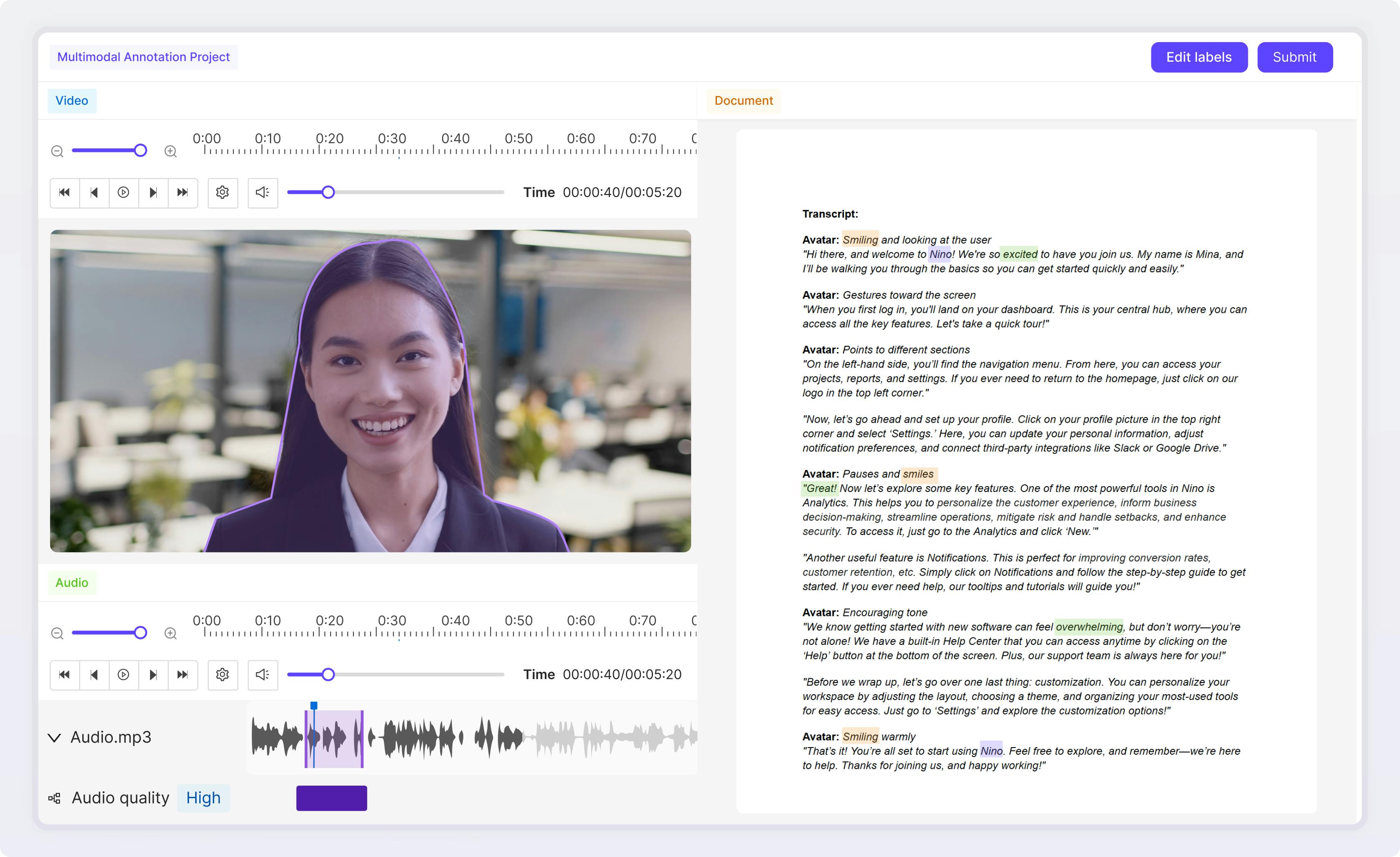
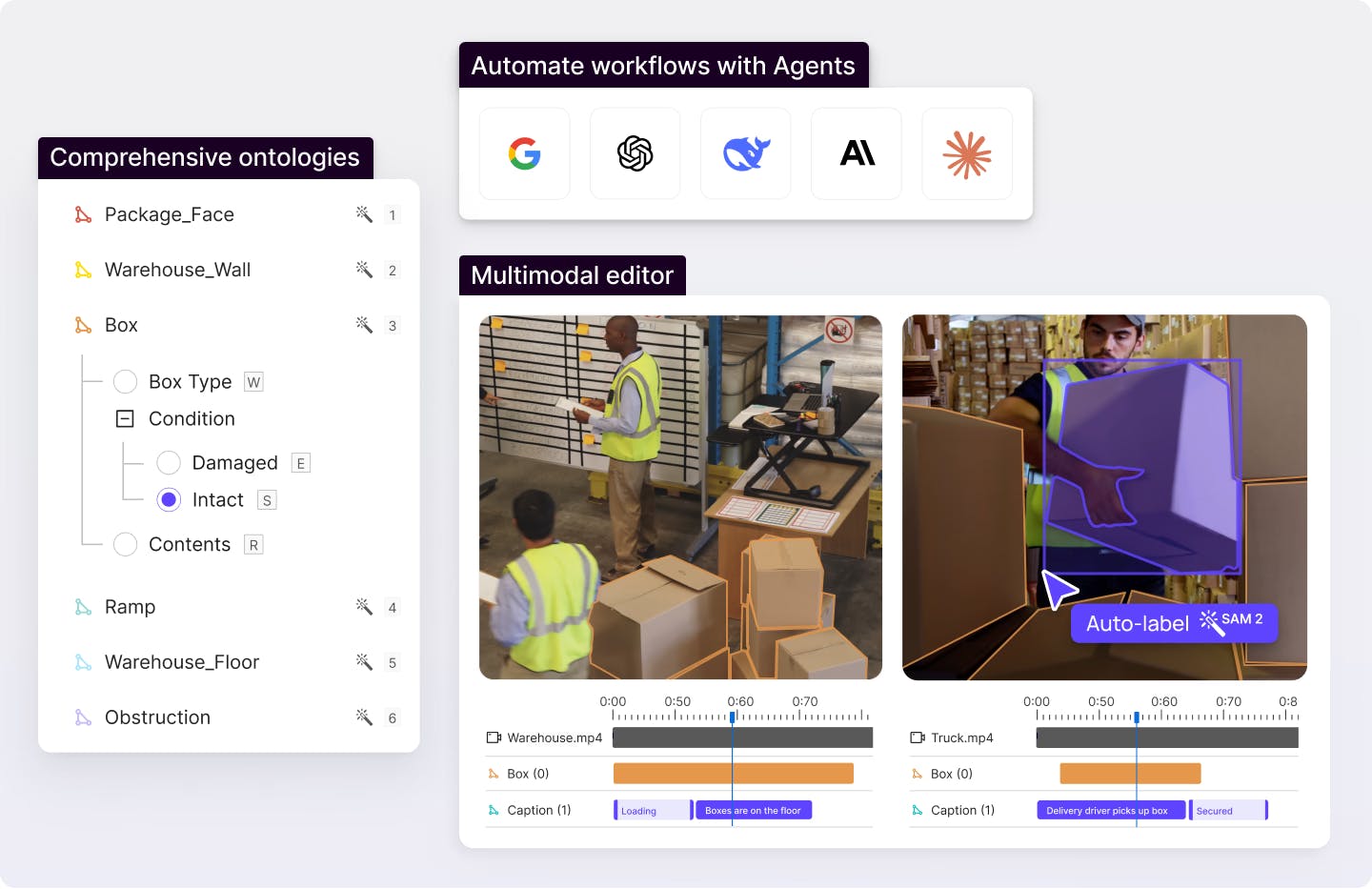
Generate multimodal labels at scale
Integrate AI agents into your project workflow for advanced model and human-in-the-loop labeling use cases.
Explore Annotate
60% faster model deployment for Hudl

30% more accurate annotations for Pickle Robot
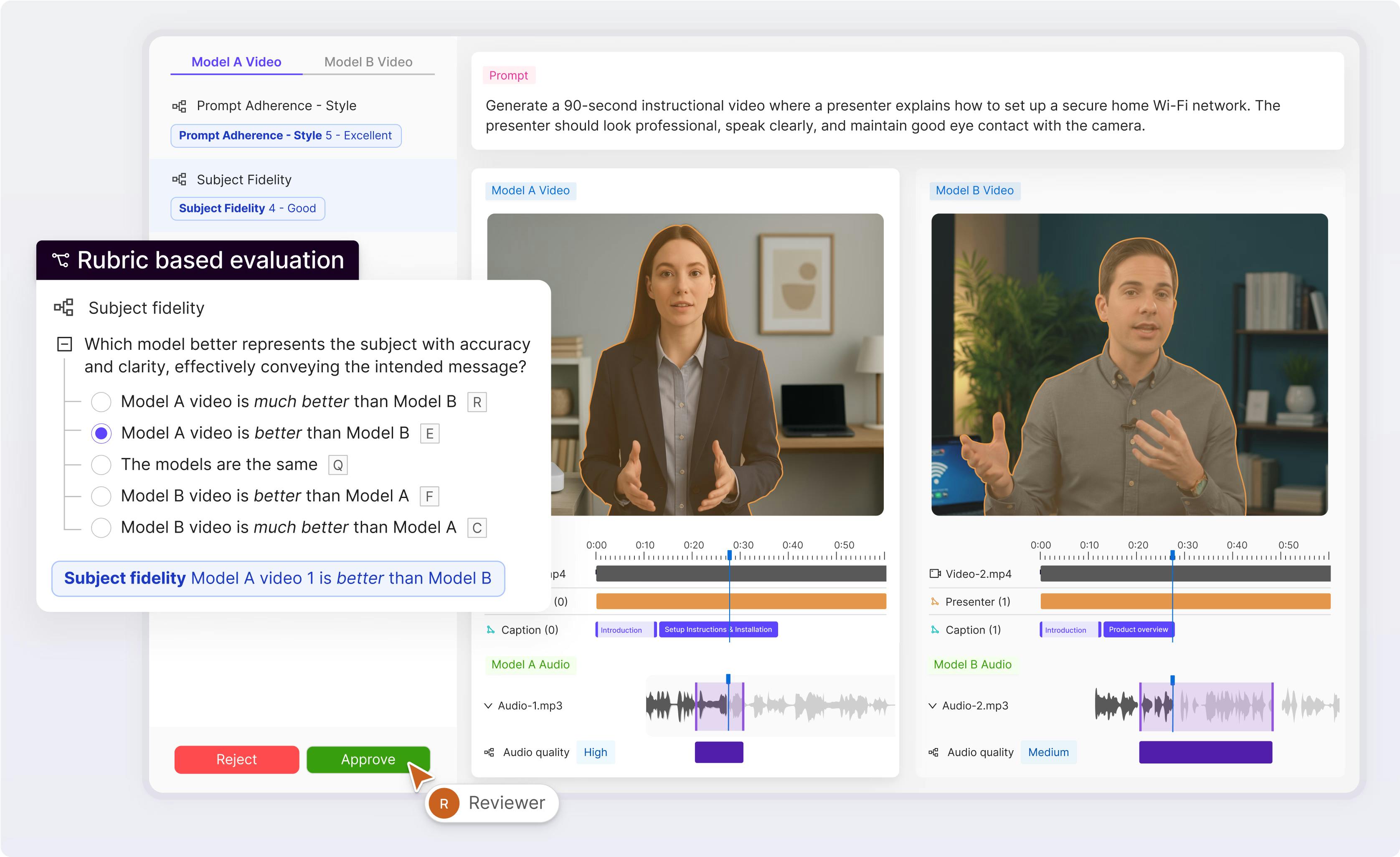
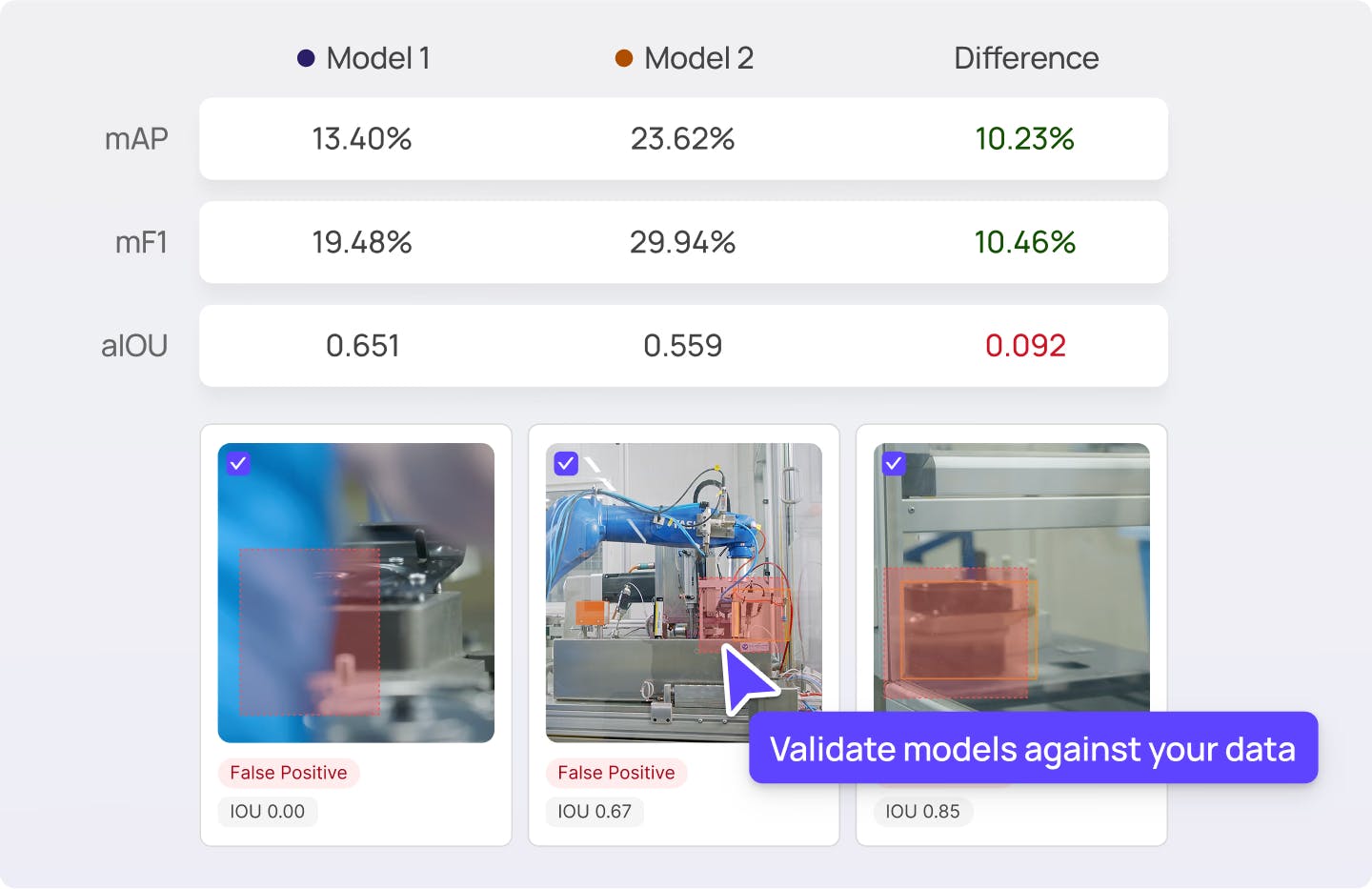
Align your AI models
Validate AI models against your data to surface, curate, and prioritize the most valuable data for training and fine-tuning.
Explore Active20% increase in model performance for Automotus
90% reduction in data management complexity for Plainsight
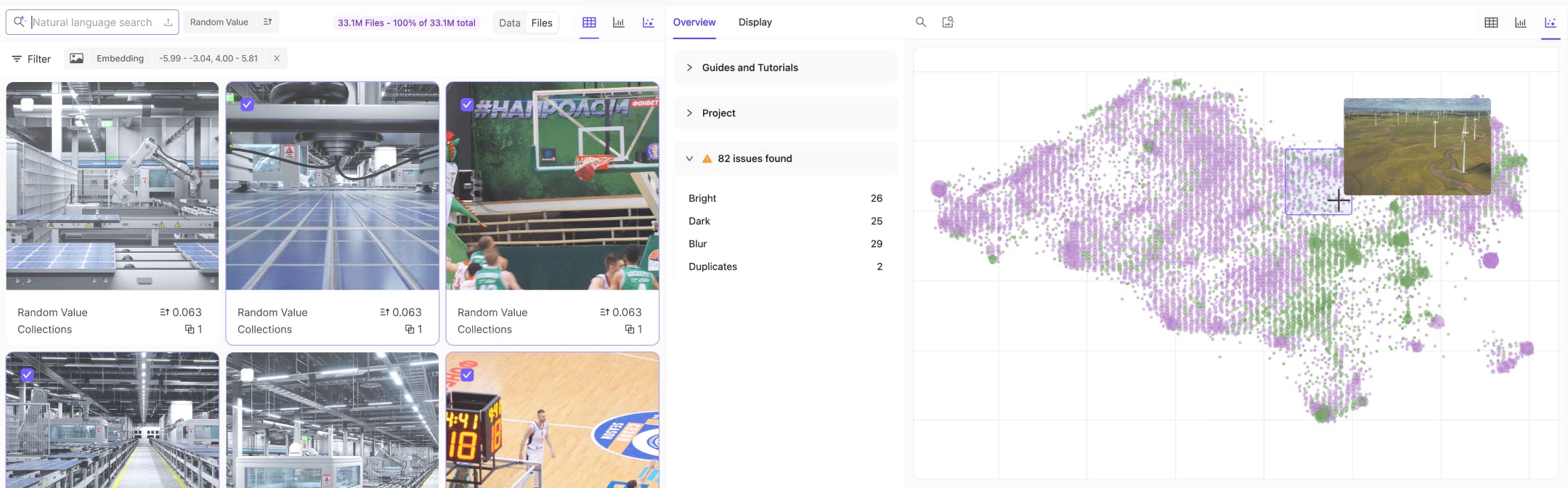
The unified data layer for AI development
Integrate your workflows
securely at </scale>
Connect your cloud storage, MLOps tools, and infrastructure through dedicated integrations. Access projects, datasets, and annotations via our API/SDK. Enterprise-grade security with SOC2, HIPAA, and GDPR compliance plus robust encryption standards.
Visit our Trust Center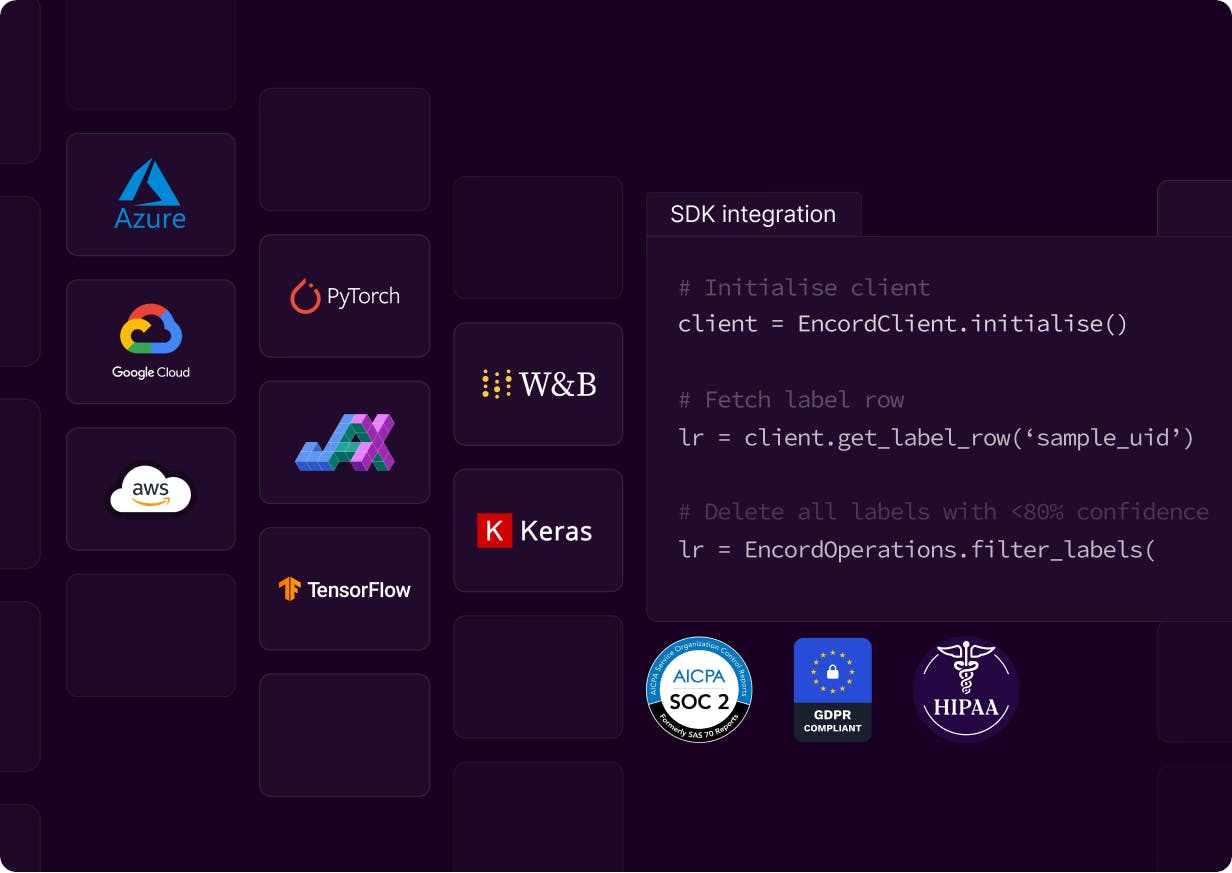
Trusted by 200+ of the world’s top AI teams deploying production AI

