Vision Fine-Tuning with OpenAI's GPT-4: A Step-by-Step Guide

Previously known primarily for its text and vision capabilities in generative AI, GPT-4o’s latest update has introduced an exciting feature: fine-tuning capabilities. This allows users to tailor the AI model to their unique image-based tasks, enhancing its multimodal abilities for specific use cases. In this blog, we’ll walk through how you can perform vision fine-tuning using OpenAI’s tools and API, diving into the technical steps, and considerations.
What is Vision Fine-Tuning?
Before diving into the "how," let’s clarify the "what." Fine-tuning refers to taking a pre-trained model, like OpenAI’s GPT-4o model, and further training it on a specialized dataset to perform a specific task. Traditionally, fine-tuning was focused on text-based tasks such as sentiment analysis or named entity recognition in large language models(llms). However, with GPT-4’s ability to handle both text and images, you can now fine-tune the model to excel at tasks involving visual data.
Multimodal Models
Multimodal models can understand and process multiple types of input simultaneously. In GPT-4’s case, this means it can interpret both images and text, making it a valuable tool for various applications, such as:
- Image classification: Fine-tuning GPT-4 to recognize custom visual patterns (e.g., detecting logos, identifying specific objects).
- Object detection: Enhancing GPT-4’s ability to locate and label multiple objects within an image.
- Image captioning: Fine-tuning the model to generate accurate and detailed captions for images.
Why Fine-Tune GPT-4o for Vision?
GPT-4 is a powerful generalist model, but in specific domains—like medical imaging or company-specific visual data—a general model might not perform optimally. Fine-tuning allows you to specialize the model for your unique needs. For example, a healthcare company could fine-tune GPT-4o model to interpret X-rays or MRIs, while an e-commerce platform could tailor the model to recognize its catalog items in user-uploaded photos.
Fine-tuning also offers several key advantages over prompting:
- Higher Quality Results: Fine-tuning can yield more accurate outputs, particularly in specialized domains.
- Larger Training Data: You can train the model on significantly more examples than can fit in a single prompt.
- Token Savings: Shorter prompts reduce the number of tokens needed, lowering the overall cost.
- Lower Latency: With fine-tuning, requests are processed faster, improving response times.
By customizing the model through fine-tuning, you can extract more value and achieve better performance for domain-specific applications.
Setting Up Fine-Tuning for Vision in GPT-4
Performing vision fine-tuning is a straightforward process, but there are several steps to prepare your training dataset and environment. Here’s what you need:
Prerequisites
- OpenAI API access: To begin, you’ll need API access through OpenAI’s platform. Ensure that your account is set up, and you’ve obtained your API key.
- Labeled dataset: Your dataset should contain both images and associated text labels. These could be image classification tags, object detection coordinates, or captions, depending on your use case.
- Data quality: High-quality, well-labeled datasets are critical for fine-tuning. Ensure that the images and labels are consistent and that there are no ambiguous or mislabeled examples.
Dataset Preparation
The success of fine-tuning largely depends on how well your dataset is structured. Let’s walk through how to prepare it.
Formatting the Dataset
To fine-tune GPT-4 with images, the dataset must follow a specific structure, typically using JSONL (JSON Lines) format. In this format, each entry should pair an image with its corresponding text, such as labels or captions. Images can be included in two ways: as HTTP URLs or as base64-encoded data URLs.
Here’s a sample structure:
{
"messages": [
{ "role": "system", "content": "You are an assistant that identifies uncommon cheeses." },
{ "role": "user", "content": "What is this cheese?" },
{ "role": "user", "content": [
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/3/36/Danbo_Cheese.jpg"
}
}
]
},
{ "role": "assistant", "content": "Danbo" }
]
}Dataset Annotation
Annotations are the textual descriptions or labels for your images. Depending on your use case, these could be simple captions or more complex object labels (e.g., “bounding boxes” for object detection tasks). Use Encord, to make sure your annotations are accurate and aligned with the task you're fine-tuning for.
Uploading the Dataset
You can upload the dataset to OpenAI’s platform through their API. If your dataset is large, ensure that it is stored efficiently (e.g., using cloud storage) and referenced properly in the dataset file. OpenAI’s documentation provides tools for managing larger datasets and streamlining the upload process.
Fine-Tuning Process
Now that your dataset is prepared, it’s time to fine-tune GPT-4. Here’s a step-by-step breakdown of how to do it.
Initial Setup
First, install OpenAI’s Python package if you haven’t already:
pip install openai
With your API key in hand and dataset prepared, you can now start a fine-tuning job by calling OpenAI’s API.
Here’s a sample Python script to kick off the fine-tuning:
from openai import OpenAIclient = OpenAI() client.fine_tuning.jobs.create( training_file="file-abc123", model="gpt-4o-mini-2024-07-18" )
Hyperparameter Optimization
Fine-tuning is sensitive to hyperparameters. Here are some key ones to consider:
- Learning Rate: A smaller learning rate allows the model to make finer adjustments during training. If your model is overfitting (i.e., it’s performing well on the training data but poorly on test data), consider lowering the learning rate.
- Batch Size: A larger batch size allows the model to process more images at once, but this requires more memory. Smaller batch sizes provide noisier gradient estimates, but they can help in avoiding overfitting.
- Number of Epochs: More epochs allow the model to learn from the data repeatedly, but too many can lead to overfitting. Monitoring performance during training can help determine the optimal number of epochs.
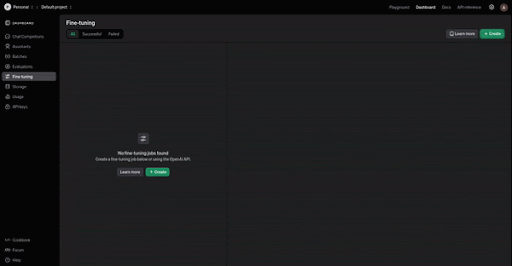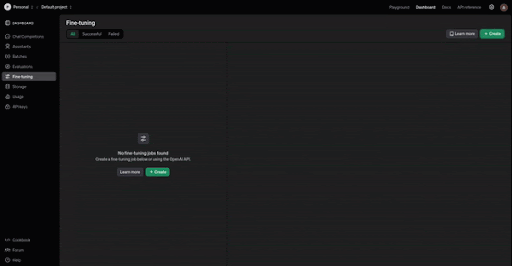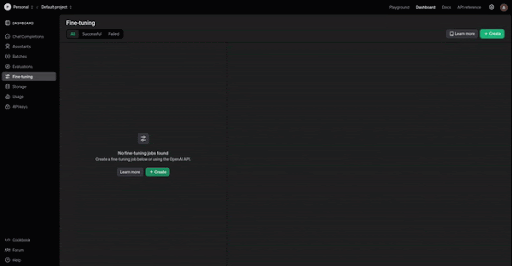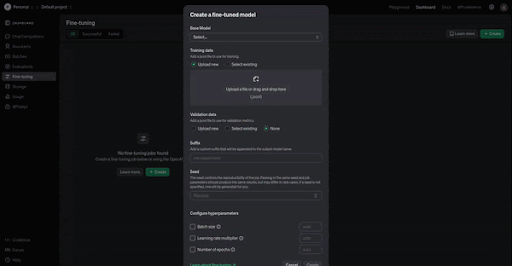
You can also get started right away in OpenAI’s fine-tuning dashboard by selecting the base model as ‘gpt-4o-2024-08-06’ from the base model drop-down.
Introducing vision to the fine-tuning API
Monitoring and Evaluating Fine-Tuned Models
After initiating the fine-tuning process, it’s important to track progress and evaluate the model’s performance. OpenAI provides tools for both monitoring and testing your model.
Tracking the Fine-Tuning Job
The OpenAI API offers real-time monitoring capabilities. You can query the API to check the status of your fine-tuning job:
response = openai.FineTune.retrieve("fine-tune-job-id")
print(response)The response will include information about the current epoch, loss, and whether the job has completed successfully. Keep an eye on the training loss to ensure that the model is learning effectively.
Evaluating Model Performance
Once the fine-tuning job is complete, you’ll want to test the model on a validation set to see how well it generalizes to new data. Here’s how you can do that:
response = openai.Completion.create( model="your-fine-tuned-model", prompt="Provide a caption for the image path/to/image.jpg", max_tokens=50 ) print(response.choices[0].text)
Evaluate the model’s output based on metrics like accuracy, F1 score, or BLEU score (for image captioning tasks). If the model’s performance is not satisfactory, consider revisiting the dataset or tweaking hyperparameters.
For a more comprehensive evaluation, including visualizing model predictions and tracking performance across various metrics, consider using Encord Active. This tool allows you to visually inspect how the model is interpreting images and pinpoint areas for further improvement, helping you refine the model iteratively.
Deploying Your Fine-Tuned Model
Once your model has been successfully fine-tuned, you can integrate it into your application. OpenAI’s API makes it easy to deploy models in production environments.
Example Use Case 1: Autonomous Vehicle Navigation
Grab used vision fine-tuning to enhance its mapping system by improving the detection of traffic signs and lane dividers using just 100 images. This led to a 20% improvement in lane count accuracy and a 13% improvement in speed limit sign localization, automating a process that was previously manual.

Introducing vision to the fine-tuning API
Example Use Case 2: Business Process Automation
Automat fine-tuned GPT-4 with screenshots to boost its robotic process automation (RPA) performance. The fine-tuned model achieved a 272% improvement in identifying UI elements and a 7% increase in accuracy for document information extraction.
Introducing vision to the fine-tuning API
Example Use Case 3: Enhanced Content Creation
Coframe used vision fine-tuning to improve the visual consistency and layout accuracy of AI-generated web pages by 26%. This fine-tuning helped automate website creation while maintaining high-quality branding.

Introducing vision to the fine-tuning API
Availability and Pricing of Fine-Tuning GPT-4o
Fine-tuning GPT-4's vision capabilities is available to all developers on paid usage tiers, supported by the latest model snapshot, gpt-4o-2024-08-06. You can upload datasets using the same format as OpenAI’s Chat endpoints. Currently, OpenAI offers 1 million free training tokens per day through October 31, 2024. After this period, training costs are $25 per 1M tokens, with inference costs of $3.75 per 1M input tokens and $15 per 1M output tokens.
Pricing is based on token usage, with image inputs tokenized similarly to text. You can estimate the cost of your fine-tuning job using the formula:
(base cost per 1M tokens ÷ 1M) × tokens in input file × number of epochs
For example, training 100,000 tokens over three epochs with gpt-4o-mini would cost around $0.90 after the free period ends.
Vision Fine-Tuning: Key Takeaways
Vision fine-tuning in OpenAI’s GPT-4 opens up exciting possibilities for customizing a powerful multimodal model to suit your specific needs. By following the steps outlined in this guide, you can use GPT-4’s potential for vision-based tasks like image classification, captioning, and object detection. Whether you’re in healthcare, e-commerce, or any other field where visual data plays a crucial role, GPT-4’s ability to be fine-tuned for your specific use cases allows for greater accuracy and relevance in your applications.
Frequently asked questions
Encord's infrastructure is uniquely designed from the ground up to support video native rendering, which alleviates common issues such as downsampling and frame analysis. This capability enables users to track objects and analyze large amounts of video data effectively without the typical challenges faced by other tools.
Yes, Encord allows users to filter videos using structured metadata, derived metadata, and metrics-based metadata. This includes custom columns from CSV files and computed metrics like brightness and contrast, enabling precise searches through video datasets.
Yes, Encord offers various controls to adjust the display settings of files. Users can filter different windowing presets and customize how files are rendered across multiple views, ensuring an optimal review experience.