How to Implement Audio File Classification: Categorize and Annotate Audio Files

Audio classification is revolutionizing the way machines understand sound, from identifying emotions in customer service calls to detecting urban noise patterns or classifying music genres.
By combining machine learning with detailed audio annotation techniques, AI systems can interpret and label sounds with remarkable precision.
This article explores how audio data is transformed through annotation, the techniques and tools that make it possible, and the real-world applications driving innovation. If you've ever wondered how AI distinguishes between a dog bark and a car horn—or how it knows when you're happy or frustrated—read on to uncover process behind audio classification.
What is Audio Classification?
Audio classification in the context of Artificial Intelligence (AI) refers to the use of machine learning and related computational techniques to automatically categorize or label audio recordings based on its content. Instead of having a human listen to an audio clip and describe what it is (e.g. whether it’s a musical piece, a spoken sentence, a bird call, or an ambient noise) an AI system attempts to identify patterns within the sound signal and assign one or more meaningful labels accordingly.

Audio Classification (Source)
Audio classification can be done by annotating audio files to train machine learning models. Audio annotation is the process of adding meaningful labels to raw audio data to prepare it for training ML models. Since audio data is complex and consists of various sound signals, speech, and sometimes noise, it needs to be broken down into smaller, structured segments for effective learning. These labeled segments serve as training data for machine learning or deep learning models, enabling them to recognize patterns and make accurate predictions.

Audio Data Annotation (Source)
For example, imagine a recording with two people talking. To classify this audio file into meaningful categories, it needs to be annotated first. During the annotation process, the speech of each person can be marked with a label such as "Speaker A" and "Speaker B" along with precise timestamps indicating when each speaker starts and stops talking. This technique is known as speaker diarization, where each speaker's contributions are identified and labeled. Additionally, the emotional tone of the speakers, such as "Happy" or "Angry," can be annotated for models that detect emotions, such as those used in emotion recognition systems. By doing this, the annotated data provides the machine learning model with clear information about:
- Who is speaking (speaker identification).
- The time frame of the speech.
- The nature of the speech or sound (emotion, sentiment, or event).
The annotated data is then fed into the machine learning pipeline, where the model learns to identify specific features within the audio signals. Audio annotation bridges the gap between raw audio and AI models. By providing labeled examples of speech, emotions, sounds, or events, it allows machine learning models to classify audio files accurately. Whether it is recognizing speakers, understanding emotions, or detecting background events, annotation ensures that the machine understands the content of the audio in a structured way, enabling it to make intelligent decisions when exposed to new data.
Types of Audio Annotations for AI
Audio annotation is an important process in developing AI systems that can process and interpret audio data. By annotating audio data, AI models can be trained to recognize and respond to various auditory elements. Different types of audio annotations help capture various features and structures of audio data. Here are the main types of audio annotations used for audio classification. Below are detailed explanations of key types of audio annotations:
Label Annotation
Label annotation refers to assigning a single label to an entire audio file or segment to classify the type of sound.This annotation is helpful in building AI systems to classify environmental sounds like "dog bark," "car horn," or "rain."
Example:
Audio Clip: Recording of rain.
Label: "Rain."

Timestamp Annotation
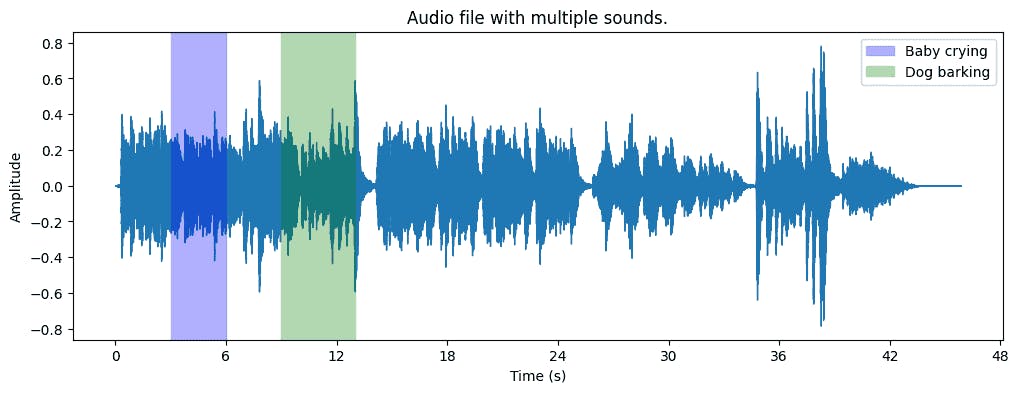
Timestamp annotation refers to marking specific time intervals where particular sounds occur in an audio file. This annotation is helpful in building AI systems to detect when specific events (e.g., "baby crying") happen in a long audio recording.
Example:
Audio Clip: Audio file with multiple sounds.
Annotations:
00:03–00:06: "Baby crying"
00:09–00:13: "Dog barking"
Segment Annotation
Segment annotation refers to dividing an audio file into segments, each labeled with the predominant sound or event. This annotation is helpful in building AI systems to identify different types of sounds in a podcast or meeting recording.
Example:
Audio Clip: A podcast excerpt.
Segments:
00:00–00:10: "Intro music"
00:12–00:20: "Speech"
00:23–00:: "Background noise"

Phoneme Annotation
Phoneme annotation refers to labeling specific phonemes (smallest units of sound) within an audio file. This may be helpful in building AI systems for speech recognition or accent analysis.
Example:
Audio Clip: The spoken word "cat."
Annotations:
00:00–00:05: /k/
00:05–00:10: /æ/
00:10–00:15: /t/

Event Annotation
Event annotation refers to annotating discrete audio events that may overlap or occur simultaneously. This annotation is useful in building AI systems for urban sound classification to detect overlapping events like "siren" and "car horn."
Example:
Audio Clip: Urban sound.
Annotations:
00:05–00:10: "Car horn"
00:15–00:20: "Siren"

Speaker Annotation
Speaker Annotation refers to identifying and labeling individual speakers in a multi-speaker audio file. This annotation is useful in building AI systems for speaker diarization in meetings or conversations.
Example:
Audio Clip: A user conversation.
Annotations:
00:00–00:08: "Speaker 1"
00:08–00:15: "Speaker 2"
00:15–00:20: "Speaker 1"

Sentiment or Emotion Annotation
Sentiment or Emotion Annotation refers to labeling audio segments with the sentiment or emotion conveyed (e.g., happiness, sadness, anger). This annotation is useful in building systems for emotion recognition in customer service calls.
Example:
Audio Clip: Audio from a call center.
Annotations:
00:00–00:05: "Happy"
00:05–00:10: "Neutral"
00:10–00:15: "Sad"

Language Annotation
Language annotation refers to identifying the language spoken in an audio file or segment. This annotation is useful in building systems for multilingual speech recognition or translation tasks.
Example:
Audio Clip: Audio with different languages.
Annotations:
00:00–00:15: "English"
00:15–00:30: "Spanish"

Noise Annotation
Noise annotation refers to labeling background noise or specific types of noise in an audio file. This may be used in noise suppression or enhancement in audio processing.
Example:
Audio Clip: Audio file with background noise.
Annotations:
00:00–00:07: "White noise"
00:07–00:15: "Crowd chatter"
00:15–00:20: “Traffic noise
00:20–00:25: "Bird chirping"

Why Annotate Audio Files Using Encord?
Encord’s audio annotation capabilities are designed to assist the annotation process for users or teams working with diverse audio datasets. The platform supports various audio formats, including .mp3, .wav, .flac, and .eac3, facilitating seamless integration with existing data workflows.
Flexible Audio Classification
Encord's audio annotation tool allows users to classify multiple attributes within a single audio file with millisecond precision. This flexibility supports various use cases, including speech recognition, emotion detection, and sound event classification. The platform accommodates overlapping annotations, enabling the labeling of concurrent audio events or multiple speakers. Customizable hotkeys and an intuitive interface enhance the efficiency of the annotation process.
Advanced Annotation Capabilities
Encord integrates with SOTA models like OpenAI's Whisper and Google's AudioLM to automate audio transcription. These models provide highly accurate speech-to-text capabilities, allowing Encord to generate baseline annotations for audio data. Pre-labeling simplifies the annotator's task by identifying key elements such as spoken words, pauses, and speaker identities, reducing manual effort and increasing annotation speed.
Seamless Data Management and Integration
Encord supports various audio formats, including .mp3, .wav, .flac, and .eac3. This helps in integrating audio datasets with existing data workflows. Users can import audio files from cloud storage services like AWS, GCP, Azure, or OTC, and organize large-scale audio datasets efficiently. The platform also offers tools to assess data quality metrics, ensuring that only high-quality data is used for AI model training.
Collaborative Annotation Environment
For teams working on large-scale audio projects, Encord provides unified collaboration features. Multiple annotators and reviewers can work simultaneously on the same project, facilitating a smoother, more coordinated workflow. The platform's interface enables users to track changes and progress, reducing the likelihood of errors or duplicated efforts.
Quality Assurance and Validation
Encord’s AI-assisted quality assurance tools compare model-generated annotations with human reviews(HITL), identifying discrepancies and providing recommendations for corrections. This dual-layer validation system ensures annotations meet the high standards required for training robust AI models.
Integration with Machine Learning Workflows
Encord platform is designed to integrate easily with machine learning workflows. Its comprehensive label editor offers a complete solution for annotating a wide range of audio data types and use cases. It supports annotation teams in developing high-quality models.
How to Annotate Audio Files Using Encord?
To annotate audio files in Encord, you can follow these steps:
Step 1: Navigate to the queue tab
Navigate to the Queue tab of your Project and select the audio file you want to label.

Step 2: Select annotation type
For audio files, you can use two types of annotations:
Audio Region objects:
- Select an Audio Region class from the left side menu.
- Click and drag your cursor along the waveform to apply the label between the desired start and end points.
- Apply any attributes to the region if required.
- Repeat for as many regions as necessary.
Classifications:
- Select the Classification from the left side menu.
- For radio buttons and checklists, select the value(s) you want the classification to have.
- For text classifications, enter the desired text.

Step 3: Save your labels
Save your labels by clicking the Save icon on the editor header.
Important to note:
It's important to note that only Audio Region objects and classifications are supported for audio files. Regular object labels (like bounding boxes or polygons) are not available for audio annotation.
For more detailed information on audio annotation, you can refer to the How to Label documentation.
Use Case Examples of Audio Classification
Encord offers advanced audio annotation capabilities that facilitate the development of multimodal AI models. Here are the three key features supported by Encord:
Speaker Recognition
Speaker recognition involves identifying and distinguishing between different speakers within an audio file. Encord's platform enables precise temporal classifications, allowing annotators to label specific time segments corresponding to individual speakers. This is essential for training AI models in applications like transcription services, virtual assistants, and security systems.
Example:
Imagine developing an AI system for transcribing and identifying speakers during a multi-participant virtual meeting or call. Annotators can use Encord to label specific sections of an audio file where individual speakers are talking. For example, the orange-highlighted segment represents Speaker A, speaking between 00:06.14 and 00:14.93, with an emotion tag labeled as Happy. The purple-highlighted segment identifies Speaker B, who begins speaking immediately after Speaker A.

Speaker Recognition (Source)
These annotations enable the AI model to learn:
- Speaker Identification: Accurately recognize and attribute each spoken segment to the correct speaker, even in overlapping or sequential dialogues.
- Emotion Recognition: Understand emotional tones within speech, such as happiness, sadness, or anger, which can be particularly useful for sentiment analysis.
- Speech Segmentation: Divide an audio file into distinct time frames corresponding to individual speakers to improve transcription accuracy.
For instance, in a customer support call, the AI can distinguish between the representative (Speaker A) and the customer (Speaker B), automatically tagging emotions like "Happy" or "Frustrated." This capability allows businesses to analyze conversations, monitor performance, and understand customer sentiment at scale.
By providing precise speaker-specific annotations and emotional classifications, Encord ensures that AI models can identify, segment, and analyze speakers with high accuracy, supporting applications in transcription services, virtual assistants, and emotion-aware AI systems.
Sound Event Detection
Sound event detection focuses on identifying and classifying specific sounds within an audio file, such as alarms, footsteps, or background noises. Encord's temporal classification feature allows annotators to mark the exact time frames where these sound events occur, providing precise data for training models in surveillance, environmental monitoring, and multimedia indexing.
Example:
Imagine developing an AI system for weather monitoring that identifies specific weather sounds from environmental audio recordings. Annotators can use Encord to label occurrences of sounds such as thunder, rain, and wind within the audio. For instance, as shown in the example, the sound of thunder is highlighted and labeled precisely with timestamps (00:06.14 to 00:14.93). These annotations enable the AI model to accurately recognize thunder events, distinguishing them from other sounds like rain or wind.

Sound Event Detection (Source)
With these well-annotated audio segments, the AI system can:
- Monitor Weather Conditions: Automatically detect thunder in real-time, triggering alerts for potential storms.
- Improve Weather Forecasting Models: Train AI models to analyze sound events and predict extreme weather patterns.
- Support Smart Devices: Enable smart home systems to respond to weather events, such as closing windows when rain or thunder is detected.
By providing precise, timestamped annotations for weather sounds, Encord ensures the AI model learns to identify and differentiate between environmental sound events effectively.
Audio File Classification
Audio file classification entails categorizing entire audio files based on their content, such as music genres, podcast topics, or environmental sounds. Encord supports global classifications, allowing annotators to assign overarching labels to audio files, streamlining the organization and retrieval of audio data for various applications.
Imagine developing an AI system for classifying environmental sounds to improve applications like smart audio detection or media organization. Annotators can use Encord to globally classify audio files based on their dominant context. In this example, the entire audio file is labeled as "Environment: Cafe" with a global classification tag.
The audio file spans a full duration of 00:00.00 to 13:45.13, and the annotator has assigned a single global label, "Cafe", under the Environment category. This classification indicates that the entire file contains ambient sounds typically heard in a café, such as background chatter, clinking of cups, and distant music.

Audio File Classification (Source)
Suppose you are building an AI-powered sound classification system for multimedia indexing:
- The AI can use global annotations like "Cafe" to organize large audio datasets by environment types, such as Park, Office, or Street.
- This labeling enables media platforms to automatically categorize and tag audio clips, making them easier to retrieve for specific use cases like virtual reality simulations, environmental sound recognition, or audio-based content searches.
- For applications in smart devices, an AI model can learn to recognize "Cafe" sounds to optimize noise cancellation or recommend ambient soundscapes for users.
By providing precise global classifications for audio files, Encord ensures that AI systems can quickly analyze, organize, and act on sound-based data, improving their efficiency in real-world applications.
Best Practices for Categorizing and Annotating Audio
Below are best practices for categorizing and annotating audio files, organized into key focus areas that ensure a reliable, effective, and scalable annotation process.
Consistency in Labels
This refers to ensuring that every annotator applies the same definitions and criteria when labeling audio. Consistency is achieved through well-defined categories, clear guidelines, thorough training, and frequent checks to ensure everyone interprets labels the same way. As a result, the dataset remains uniform and reliable, improving the quality of any analysis or model training done on it.
Team Collaboration
This involves setting up effective communication and coordination among all individuals involved in the annotation process. By having dedicated communication channels, Q&A sessions, and peer review activities, the annotating team can quickly resolve uncertainties, share knowledge, and maintain a common understanding of the labeling rules, leading to more accurate and efficient work.
Quality Assurance
Quality assurance (QA) ensures the accuracy, reliability, and consistency of the annotation work. QA includes conducting spot checks on randomly selected samples, and continuously refining the guidelines based on feedback and identified errors. Effective QA keeps the labeling process on track and gradually improves its overall quality over time.
Handling Edge Cases
Edge cases are unusual or ambiguous audio samples that don’t fit neatly into predefined categories. Handling them involves having a strategy in place (such as providing an “uncertain” label) and allowing annotators to leave notes, and updating the taxonomy as new or unexpected types of sounds appear. This ensures that the annotation task remains flexible and adaptive.
Key Takeaways: Audio File Classification
- Audio classification uses AI to categorize audio files into meaningful labels, enabling applications like speaker recognition, emotion detection, and sound event classification.
- Handling noisy data, overlapping sounds, and diverse audio patterns can complicate annotation. Consistent labeling and precise segmentation are essential for success.
- Accurate annotations, including timestamps and labeled events, ensure robust datasets. These are key for training AI models that perform well in real-world scenarios.
- Encord streamlines annotation with support for diverse file formats, millisecond precision, collaborative workflows, and AI-assisted quality assurance.
- Consistency, collaboration, and automation tools enhance annotation efficiency, while strategies for edge cases improve dataset adaptability and accuracy.
Frequently asked questions
Audio classification is the process of using AI and machine learning techniques to automatically categorize audio recordings based on their content. This can include identifying sounds such as music, speech, environmental noises, or specific events.
Audio classification relies on machine learning models trained on annotated audio data. Annotators label audio segments with meaningful categories, such as "Speaker A," "Happy emotion," or "Car horn," which the model uses to learn patterns and make predictions on new audio.
Audio annotation involves adding labels to raw audio data to prepare it for training machine learning models. Examples include labeling speakers, marking timestamps for events, or identifying emotions conveyed in speech.
Annotated audio provides structured data for training AI models. Precise labels, timestamps, and segmentation ensure the model learns the correct features, enabling accurate predictions in tasks like speaker recognition, emotion detection, and sound event classification.
Speaker recognition, emotion detection, sound event detection, audio file classification.
To transform archived media into training datasets with Encord, users can extract and transcribe audio from videos, generate descriptions of images, and structure this data for fine-tuning large language models (LLMs). This approach can streamline the creation of content that aligns with established brand narratives.
Encord supports the development of multi-identity models by providing the necessary tools to curate and manage both video and audio data. Users can filter through extensive datasets to ensure they are working with high-quality, synchronized content, which is essential for training effective machine learning models.
Encord provides the capability to create audio classification models that can recognize and categorize various sounds, such as identifying falls or ambient noise in a home setting. By leveraging the platform's annotation tools, users can train their models with labeled audio data to enhance recognition accuracy.
Yes, Encord can handle audio files with mixed languages, allowing users to annotate different languages within the same file. The platform also provides transcription support, enabling users to view and edit text transcriptions while listening to the audio, enhancing the efficiency of the annotation process.
Encord stands out in the industry by offering native video rendering capabilities, allowing for seamless audio and video annotation without the need for frame-by-frame breakdown. This unique approach streamlines the annotation process and improves the overall user experience.
Encord supports a diverse range of data files, including images, videos, and various other formats. This versatility allows teams to manage and annotate multiple data types within a single platform, facilitating comprehensive AI model development.
Yes, Encord is designed to accommodate different types of data, including images and videos. The platform can manage the annotation of various data formats, allowing users to efficiently work with their preferred data types.
Encord supports a variety of media types, including videos, images, audio files, and PDF documents. This flexibility allows users to work with diverse data formats and extract valuable insights from multimodal content.
Yes, Encord allows users to slice and filter video content based on specific qualities or attributes. This feature is particularly useful for creating custom datasets tailored to particular research or project needs.