How to Build Your First Machine Learning Model

In this article, we will be discussing the universal workflow of all machine learning problems. If you are new to ‘applied’ artificial intelligence, this post can form your step-by-step checklist to help you bring your first machine learning model to life. If you have previous experience building neural networks or machine learning models more broadly, this blog will help ensure you haven’t missed any step; it’ll also outline the best-practice process you are (hopefully!) already familiar with and give you practical tips on how to improve your model.
Step 1: Contextualize your machine learning project
The initial step in building a machine learning model is to set out its purpose. The objectives of your project should be set clear before you start building your model – if the deployed model is in line with your and your team’s goals, then it will be far more valuable. At this stage, the following points should be discussed extensively and agreed upon:
- The goal of the project, i.e., the question that the project sets out to answer
- A definition of what ‘success’ will look like for the project
- A plan of where training data will be sourced from, as well as its quantity and quality
- The type of algorithm that will be used initially, or whether a pre-trained model can be used
An obvious point that cannot be overstated here, is that machine learning can only be used to learn and predict the patterns as seen in the training data – i.e., the model can only recognize what it has already seen.

Step 2: Explore the data and choose the type of machine learning algorithm
The next step in building a machine learning model is to explore the data hands-on through the process of exploratory data analysis. Depending on your project’s objective, as well as the size, structure, and maturity of the team, this step will often be led by a data scientist. The goal of this step is to provide the team with a fundamental grasp of the dataset’s features, components, and grouping. Understanding the data at hand allows you to choose the type of algorithm you want to build – the ultimate choice then depends on the type of task the model needs to perform, and the features of the dataset at hand.
The type of machine learning algorithm selected will also depend on how well the core data - and the problem at hand - are understood. Machine learning models are typically bucketed into three main categories – each one trains the model in a different way, and as a result, requires a different type of dataset. Being intentional about these differences ahead of model-building is fundamental, and will have a big impact on the outcome of the project. Let’s have a look at the three types of machine learning algorithms, and the type of data required for each.
Supervised learning
This approach requires data scientists to prepare labeled datasets. The model will learn from training data consisting of both input data and labeled output data, and it will set out to learn the relationship between input and output in order to be able to replicate and predict this relationship when fed new data points. This is why supervised machine learning models are often used to predict results and classify new data.
Unsupervised learning
Unlike supervised learning models, unsupervised machine learning models do not require labeled datasets for model training; only the input variables are required for the training dataset. This type of machine learning model learns from the dataset and is used to identify trends, groupings or patterns within a dataset; it is primarily used to cluster and categorize data as well as to identify the dataset’s governing principles.
Reinforcement learning
Reinforcement machine learning is the third primary type of machine learning algorithm. Reinforcement learning differs from supervised learning in that it needs neither the labeled input/output pairs nor the explicit correction of suboptimal behaviors. Learning is done by trial-and-error, or a feedback loop, in this procedure: every time a successful action is carried out, reward signals are released, and the system gains knowledge by making mistakes. A real-world example of reinforcement learning algorithms in action is in the development of driverless cars – systems learn by interacting with their environment to carry out a given task, learn from their prior experiences, and improve.
Step 3: Data collection
Large volumes of high-quality training data are required for machine learning models to be robust and capable of making accurate predictions since the model will learn the connections between the input data and output present in the training set and try to replicate these when fed new data points.
Depending on the kind of machine learning training being done, these datasets will contain different types of data. As we mentioned, supervised machine learning models will be trained on labeled datasets that have both labeled input and labeled output variables. This process starts with an annotator, usually completing the labor-intensive process of preparing and classifying the data manually. Annotation tools are also starting to be built, that can help you in labeling your data – in order to speed up the process and accuracy, it is necessary to choose the right annotation tool for your use case. For example, if you are building a computer vision model and need to label your images and videos, platforms like Encord have features to assist you in data labeling. Optimizing this step, not only significantly reduces the time required to complete the data-preparation process, but also results in higher-quality data, which in turn increases the accuracy of the model and its performance, thus saving you time later on – so investing in this step is very important, and often overlooked by teams who are just starting out.
In contrast, since unsupervised machine learning models won't require labeled input data, the training dataset will only include input variables or features. In both cases, the quality of the input data will significantly impact the model's overall success – since the model learns from the data, low-quality training data may result in the model's failure to perform as expected once it is put into use. In order to standardize the data, identify any missing data, and find any outliers, the data should be verified and cleaned.
Step 4: Choose your model evaluation method
Before preparing the dataset and building your model, it is essential to first have some metrics to measure success step-by-step. You should be clear on how you are going to measure the progress towards achieving the goal of the model, and this should be the guiding light as you go onto the next steps of evaluating the project’s success. There are three most common methods of evaluation:
Maintaining a hold-out validation set
This method involves designating a specific subset of the data as the test data, and then tuning the model's parameters using the validation set, training the model using the remaining portion of the data, and then assessing its performance using the test data.
Under this method, data is divided into three sections to prevent information leaks.
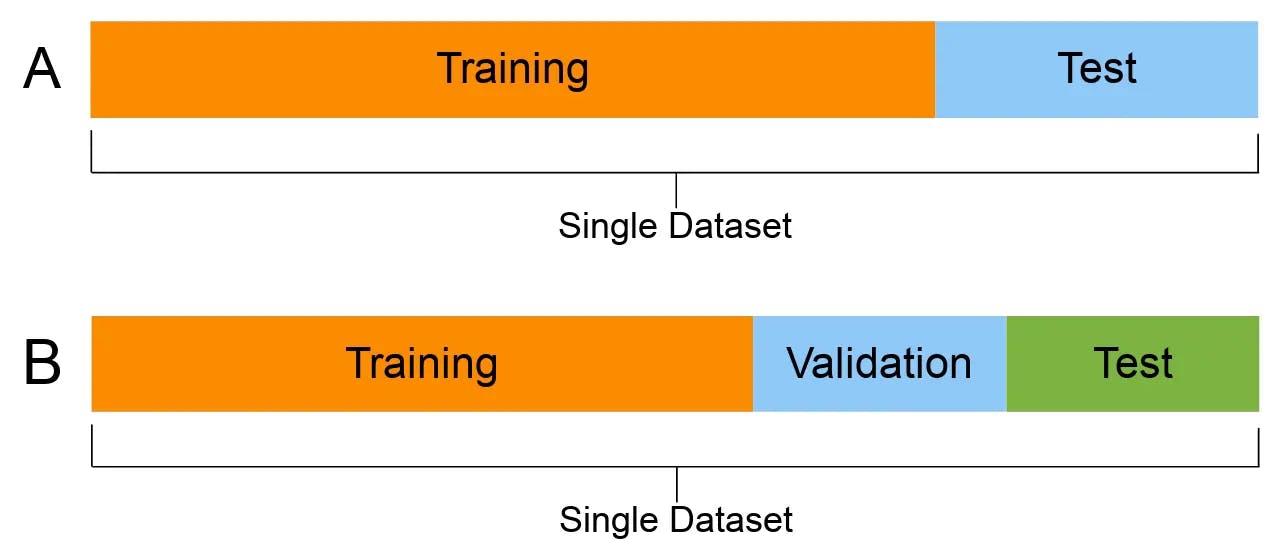
Fig 1: A doesn’t contain the validation dataset. B holds out the validation dataset.
K-fold validation
Here, the data is divided into K equal-sized divisions using the K-fold method. The model is trained on the remaining K-1 divisions for each division i and it is then evaluated on that division i.
The average of all K scores is used to determine the final score. This method is especially useful when the model’s performance differs noticeably from the train-test split.

Fig 2: Image showing K-fold validation till k iterations.
Iterated K-fold Validation with Shuffling
This technique is especially relevant when trying to evaluate the model as precisely as possible while having little data available.
This is done by performing K-fold validation repeatedly while rearranging the data, before dividing it into K parts. The average of the scores attained at the conclusion of each K-Fold validation cycle constitutes the final score.
As there would be I x K times as many models to train and evaluate, this strategy could be exceedingly computationally expensive. I represent the iterations, while K represents the partitions.
Step 5: Preprocess and clean your dataset
To build a machine learning model, data cleaning and preprocessing are key in order to minimize the impact of common challenges like overfitting and bias. Real-world data is messy; non-numeric columns, missing values, outlier data points, and undesirable features are just a few examples of data errors you will come across when performing this step.
Before you begin preprocessing data, you must carefully examine and comprehend the dataset; both at an individual column level (if feasible), as well as at an aggregate level. Let’s look at a few of the ways you should access your data and how you could preprocess your dataset.
Dealing with nonnumerical columns
Machine learning algorithms understand numbers, but not strings, so if columns with strings are present, they should be converted to integers. Methods like label encoding and one-hot encoding can be used to convert strings to numbers. However, what if every point in the column is a distinct string (for instance, a dataset with unique names)? In that case, the column must typically be dropped, so it's important to look at the dataset carefully.
Solving for missing values
Real-world datasets may have missing values for a number of reasons. These missing values are commonly recognized as NaN, empty strings, or even blank cells(“”). The missing values can be dealt with the following techniques based on how the input data is missing:
- Drop the row: Drop the rows containing missing values, after ensuring there are enough data points available.
- Mean/Median or Most Frequent/Constant: The mean or median of the values in the same column can be used to fill in the missing data. With categorical features, the most common or consistent values from the same column could also be used (although for obvious reasons, this may introduce bias to the data and not be optimal in many cases). Both of these approaches ignore the relationship between the features.
- Imputation using regression or classification: Using the features that do not contain missing values, you can use an algorithm like linear regression, support vector machine (SVM), or K-nearest neighbor (KNN) to predict the missing values.
- Multivariate imputation by chained equations: If there are missing values in all columns, the previous techniques likely wouldn’t work. In the case where missing values are present in multiple places, the multivariate imputation by chained equations (MICE) technique can often be the best option for completing the dataset.
- If you are using Python, then scikit-learn has inbuilt impute classes to make it easier. Impute by scikit-learn is a great starting point for learning more about implementing the imputation of missing classes in your machine learning model.
Detecting outliers
In any given dataset, a few observations deviate from the majority of other observations, resulting in a biased weightage in their favor. These data points are known as outliers, and they must be removed in order to avoid unwanted bias. If the data points are two-dimensional, then they can be visualized, and thresholding the outliers may work. However, datasets with a large number of features are usually of higher dimensions and hence cannot be easily visualized. So you have to rely on algorithms to detect those outliers. Let’s discuss two of the common outlier detection algorithms:
Z-score
Z-score, intuitively, informs us of how distant a data point is from the median position (where most of the data points lie). It is mostly helpful if the data is Gaussian. If not, then the data should be normalized by using log transformations, or Bob Cox transformation (in case of skewed columns). One of the limitations of z-score outlier detection is that it can’t be used on nonparametric data.
Density Based Spatial Clustering of Applications with Noise (DBSCAN)
The clustering algorithm DBSCAN groups the data points based on their density; outliers can be identified as points located in low-density regions.
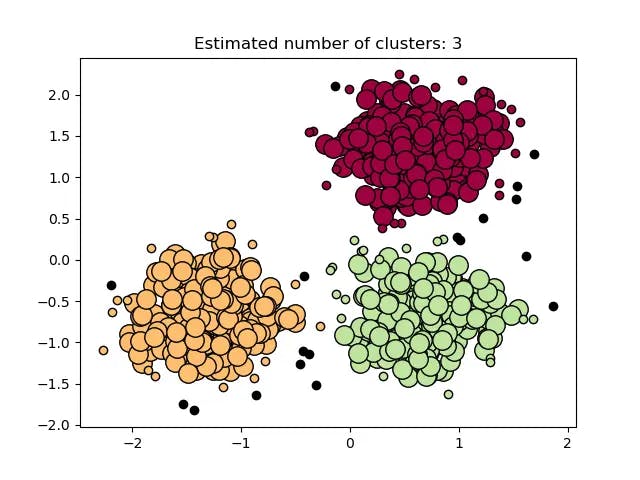
Fig 3: An example of DBSCAN forming clusters to find which data points lie in a low-density area. Source
Analyzing feature selection
Features are essential for establishing a connection between data points and the target value. These features won't be of any assistance in mapping that relationship if any of them are corrupt or independent from the target values, so an important part of data cleaning is seeking these out and eliminating them from the dataset.
We can look for these properties using two different kinds of algorithms: univariate and multivariate.
Univariate
The goal of univariate algorithms is to determine the relationship between each feature and the target columns, independent of other features. Only if the connection is strong, should the feature be kept.
Multivariate
Multivariate algorithms identify the feature-to-feature dependencies, essentially calculating the scores for each characteristic and choosing the best ones.
Statistical methods and algorithms like the F-test and the mutual information test are univariate algorithms; recursive feature selection is a commonly used multivariate feature selection. It is important to remember here, that the feature selection algorithm should be chosen based on your dataset. Articles by scikit-learn, like the comparison between f-test and mutual information, show the difference between these algorithms, as well as their Python implementation.
Step 6: Build your benchmark model
After preparing your dataset, the next objective is to create a benchmark model that acts as a baseline against which we can measure the performance of a more effective algorithm.
Depending on the use case, and on the size, maturity, and structure of your team, this step will often be carried out by a machine learning engineer. For the experiments to be used as benchmarks, they must be similar, measurable, and reproducible. Currently, available data science libraries randomly split the dataset; this randomness must remain constant throughout all runs. Benchmarking your model allows you to understand the possible predictive power of the dataset.
Step 7: Optimize your deep learning model
When developing a machine learning model, model optimization - which is the process of reducing the degree of inaccuracy that machine learning models will inevitably have - is crucial to achieving accuracy in a real-world setting. The goal of this step is to adjust the model configuration to increase precision and effectiveness. Models can also be improved to fit specific goals, objectives, or use cases.
There are two different kinds of parameters in a machine learning algorithm: the first type is the parameters that are learned during the model training phase, and the second type is the hyperparameters, whose values are used to control the learning process.
The parameters that were learned during the training process can be analyzed while debugging the model after the model training process. This will allow you to find the failure cases and build better models on top of the benchmarked model. There are tools featuring an active learning framework, which improves your model visibility and allows you to debug the learned parameters.
Choosing the right hyperparameters when building a machine learning model is also key - the book Hyperparameter Optimization in Machine Learning is a great guide to hyperparameter optimization and provides a tutorial with code implementations.
Conclusion
In this blog, we have discussed the most important parts of building a machine learning model. If you are an experienced data science practitioner, I hope this post will help you outline and visualize the steps required to build your model. If you are a beginner, let this be your checklist for ensuring your first machine learning project is a success!
Frequently asked questions
Encord specializes in the data operations segment of the machine learning lifecycle. We assist users in cleaning, curating, and visualizing datasets, ensuring they are well-organized before being pushed into the annotation workflow. Our goal is to streamline the entire data preparation process, ultimately providing high-quality training data for effective model training.
Encord is designed to support machine learning teams by simplifying the data curation process. With features that enhance data management and annotation efficiency, teams can focus on developing and iterating models more effectively, ultimately leading to faster deployment of machine learning applications.
Integrating Encord with existing machine learning workflows is straightforward, as the platform is designed to work seamlessly with various data processing pipelines. Users can easily upload datasets, annotate them, and export labeled data in formats compatible with their machine learning frameworks.
Encord offers a range of features aimed at optimizing machine learning models for production environments. This includes tools for model quantization, transfer learning, and strategies to enhance detection accuracy, ensuring models perform effectively on edge devices in real-time scenarios.
Encord supports seamless integration of data pipelines, enabling users to efficiently bring in data and orchestrate processes. This feature is essential for teams looking to streamline their workflows and enhance collaboration between data management and machine learning model training.
Yes, Encord is well-suited for companies looking to enhance existing machine learning models. It supports fine-tuning and training of open-source models, allowing businesses to leverage their existing data and improve their machine learning capabilities without starting from scratch.
To build a business case for Encord, it is important to identify specific functionalities and features that align with project goals. Engaging with Encord's team to discuss capabilities and how they can meet the needs of RD projects is a crucial step in this process.
Encord provides tools that facilitate both the training and evaluation phases of machine learning development. The platform can handle diverse datasets to enhance model performance, ensuring that the critical testing and evaluation processes are met effectively.
Encord is designed to enable users to build better models faster. By providing features like native video rendering, dynamic classifications, and efficient data curation, it helps streamline the model training process, particularly for motion data applications.
Encord's platform supports a variety of models, including statistical models and machine learning models. Customers can select which models to use based on performance metrics and specific KPIs relevant to their projects.