Data Classification 101: Structuring the Building Blocks of Machine Learning

Machine learning depends on well-structured, high quality data. At the very core of this process is data classification when building models with supervised learning. It is organizing raw information into labeled and organized categories that the AI models can understand and learn from.
In this guide, we will discuss the fundamentals of data classification and how it impacts artificial intelligence applications.
What is Data Classification?
It is the process of organizing unstructured data into predefined categories or labels. This process is carried out after data curation, where data is carefully collected from various sources. Data classification is a foundational step in supervised machine learning, where models are trained on labeled datasets to make predictions or identify patterns. Without accurate data classification, machine learning models risk producing unreliable or irrelevant outputs.

Supervised Machine Learning
Why is Data Classification Important?
Data classification determines the quality of the training and testing data. This determines the quality of the machine learning model you are building. The models rely on well annotated data to:
- Learn patterns: Recognize correlations between the input and labels.
- Make predictions: Apply the patterns learnt to new, unseen data.
- Reduce noise: Filter out irrelevant or redundant information to improve accuracy in predictions.
Types of Data Classification
Data classification can be applied to various types of data:
- Text: Categorizing documents, emails, or social media posts.
- Images: Labeling objects, scenes, or features in visual data.
- Audio: Identifying speakers, transcribing speech, or classifying sounds.
- Video: Detecting and labeling activities or objects in motion.
Steps in Data Classification
To classify data effectively, you need to design a structured process to ensure that the data created is comprehensive, and ready for the next step, i.e., feature engineering or training the AI model.
Here are the key steps to include in the data classification process:
Data Collection
The collection of high-quality and relevant data forms the foundation of the data classification process. The goal is to build a dataset that is both representative of the problem domain and robust enough to handle edge cases. When collecting data, you need to keep these points in mind:
- Diversity: Ensure your dataset includes various scenarios, demographics, or use cases to avoid bias. For example, a facial recognition dataset should include diverse skin tones and facial features.
- Relevance: Align your data with the problem you’re solving. Irrelevant or extraneous data can introduce noise and hinder model performance.
- Volume: While more data is generally better, focus on quality. A smaller, well-annotated dataset can outperform a massive dataset filled with noisy samples
Data Labeling
This process converts raw, unstructured data into usable training examples. Here you assign meaningful labels or annotations to data samples, making them understandable for machine learning algorithms. Data labeling also helps the team to analyse the quality of the curated dataset. This helps them decide whether or not more data should be collected or if the collected dataset is suitable for the project.
Here are some of the steps involved in data annotation:
- Manual Annotation: Human annotators label data by identifying patterns or tagging content, such as marking objects in images or identifying sentiment in text. This can be highly accurate but time-intensive. There is a certain amount of time also spent in training the annotators and designing an annotation schema to ensure the quality of the annotation.
- Automated Labeling: Pre-trained models or annotation tools like Encord generate initial labels. These can then be verified or refined by humans to ensure quality. When annotating a large volumes of data, this automation can reduce the time spent significantly, but human intervention is required regularly to ensure the quality of the annotation.
- Consensus Mechanisms: Involving multiple annotators for the same data point to resolve ambiguities and improve consistency. Though the time spent here is considerably more, it is essential when building a robust training dataset for high impact projects like AI models in the medical field.
Feature Engineering
Feature engineering extracts meaningful information from the annotated data. The features extracted from the annotated data are extracted in a way to help the ML model understand the data and learn from it. Feature engineering involves:
- Identifying Features: Determine which attributes of the data are most relevant for classification. For example, in text classification, word frequencies or bigrams might be useful.
- Transforming Data: Normalize or preprocess the data to make it consistent. For images, this might involve resizing or enhancing contrast.
- Reducing Dimensionality: Remove irrelevant or redundant features to simplify the dataset and improve model efficiency.
Model Training and Testing
Once labeled and features are extracted, the data is split into training, validation, and testing sets. Each set serves a specific purpose:
- Training Set: This dataset is initially used by the model to learn the patterns in the data.
- Validation Set: This unseen set helps tune model parameters after it has been trained on the training dataset to avoid overfitting.
- Testing Set: In this stage, the model’s performance is evaluated on unseen and close to real-world dataset and used to generalise the model’s responses.
Continuous Improvement
The process doesn’t stop after initial training. Data classification models often need:
- Retraining: Incorporating new data to keep models up to date.
- Error Analysis: Reviewing misclassified examples to identify patterns and refine the process.
- Active Learning: Allowing models to request labels for uncertain or ambiguous cases, which can help focus human labeling efforts.
By continually iterating on these steps, you ensure your data classification remains accurate and effective over time.
Challenges in Data Classification
Despite its importance, the data classification system is not without its challenges. You will encounter:
Inconsistent Labels
Human annotators may interpret data differently, leading to inconsistent labeling. For example, in sentiment analysis, one annotator might label a review as “neutral” while another marks it as “positive.” These discrepancies can confuse machine learning models and reduce accuracy.
Solution
Establish clear annotation guidelines and use consensus mechanisms. Tools like Encord’s annotation platform allow multiple reviewers to collaborate, ensuring labels are consistent and aligned with project objectives.
Dataset Bias
A biased dataset leads to models that perform poorly on underrepresented groups. For instance, a facial recognition system trained on a dataset with limited diversity may fail to identify individuals from minority demographics accurately.
Solution
Incorporate diverse data sources during the collection phase and perform bias audits. Using data quality metrics to analyse the annotated dataset helps in identifying the underrepresented data groups which are necessary for building a robust deep learning model.
It is also essential to keep in mind that some projects need certain groups in small amounts and need not be overpopulated, otherwise the model may learn patterns which are not necessary for the project. Hence, the data quality metrics are essential to be analysed to ensure necessary groups are represented as requirements.
Scalability Issues
Manually labeling large amounts of data can be time-consuming and expensive, especially for high-volume projects like video annotation.
Solution
Using a scalable platform that can handle different modalities is essential. The annotation platform that provides automated labelling features helps speed up the process while maintaining accuracy.
Quality Control
Ensuring label accuracy across large datasets is challenging. Even small errors can degrade model performance. Also, migrating data from the annotation platform, and designing and implementing your own data evaluation metrics is time consuming and not very scalable.
Solution
Use a data platform that stores different annotated datasets and provides quality metrics to visualize and analyze the quality of the data. This quality control should include label validation and auditing annotation workflows while assessing the quality of the curated dataset.
How Encord Streamlines Data Classification
Encord provides a comprehensive suite of tools designed to optimize every stage of the data classification process. Here’s how it addresses common challenges and accelerates data classification algorithms:
Intuitive Annotation Platform
Encord Annotate’s interface supports diverse data types, including images, videos, and audio in various formats. Its user-friendly design ensures that annotators can work efficiently while maintaining high accuracy. The ontologies or the custom data annotation schema ensures precision in the annotated data. You can also design annotation workflows to simplify the process.
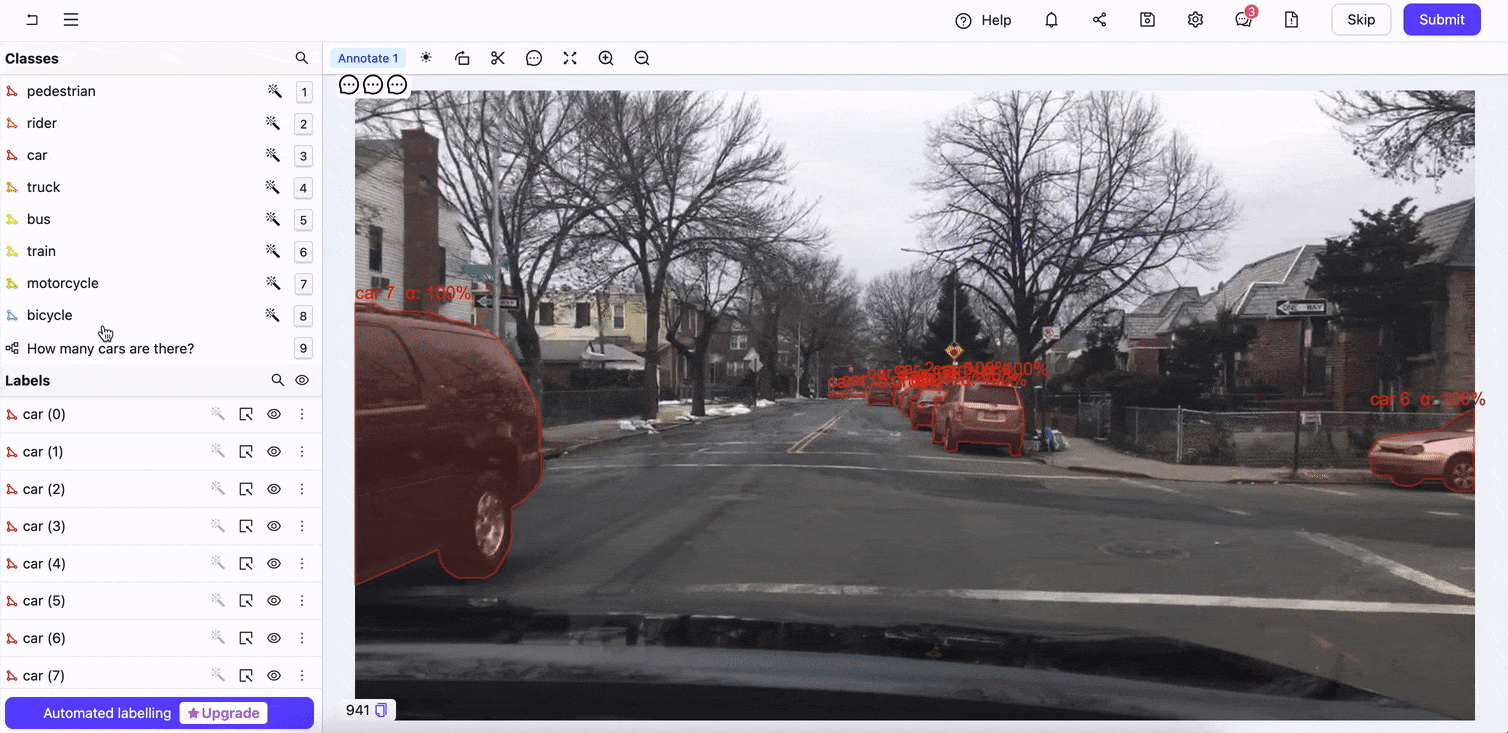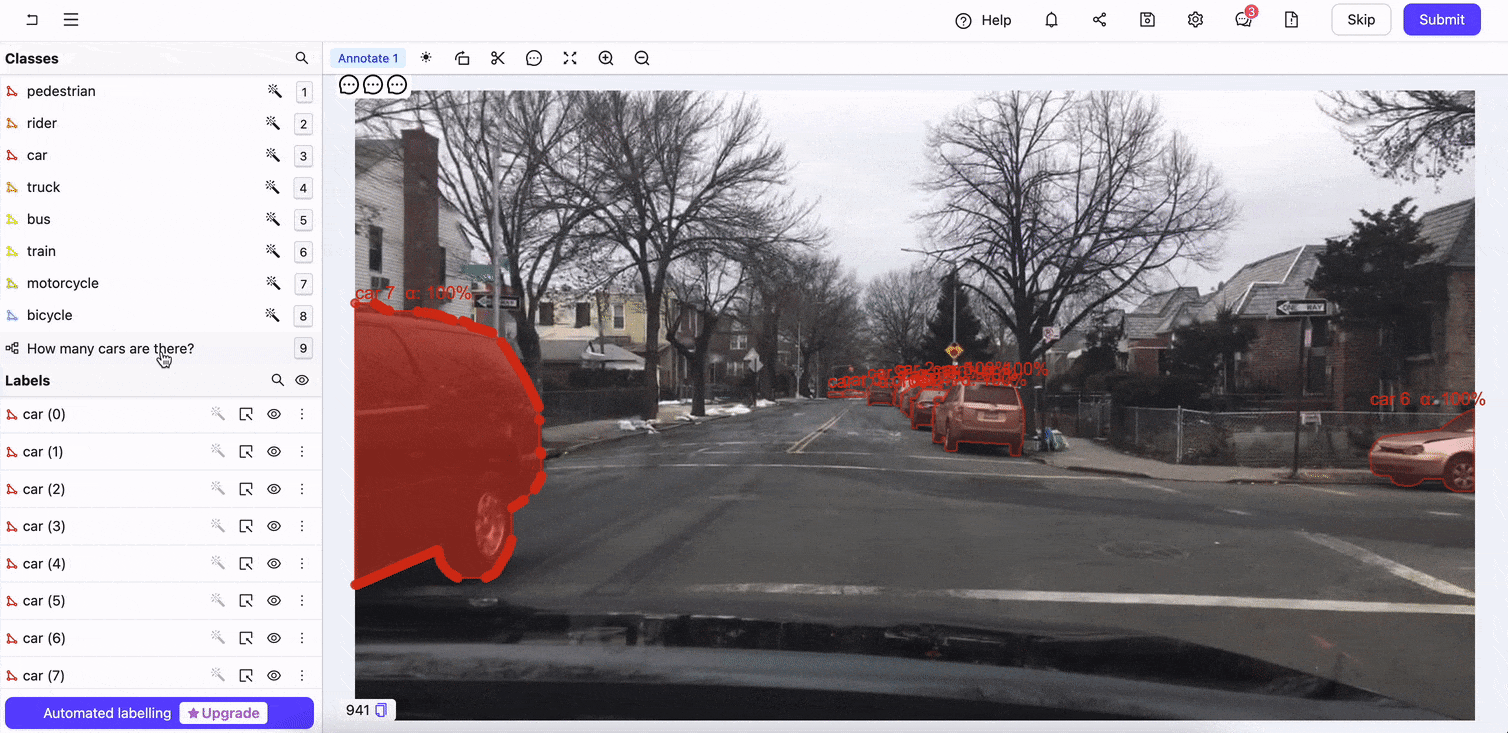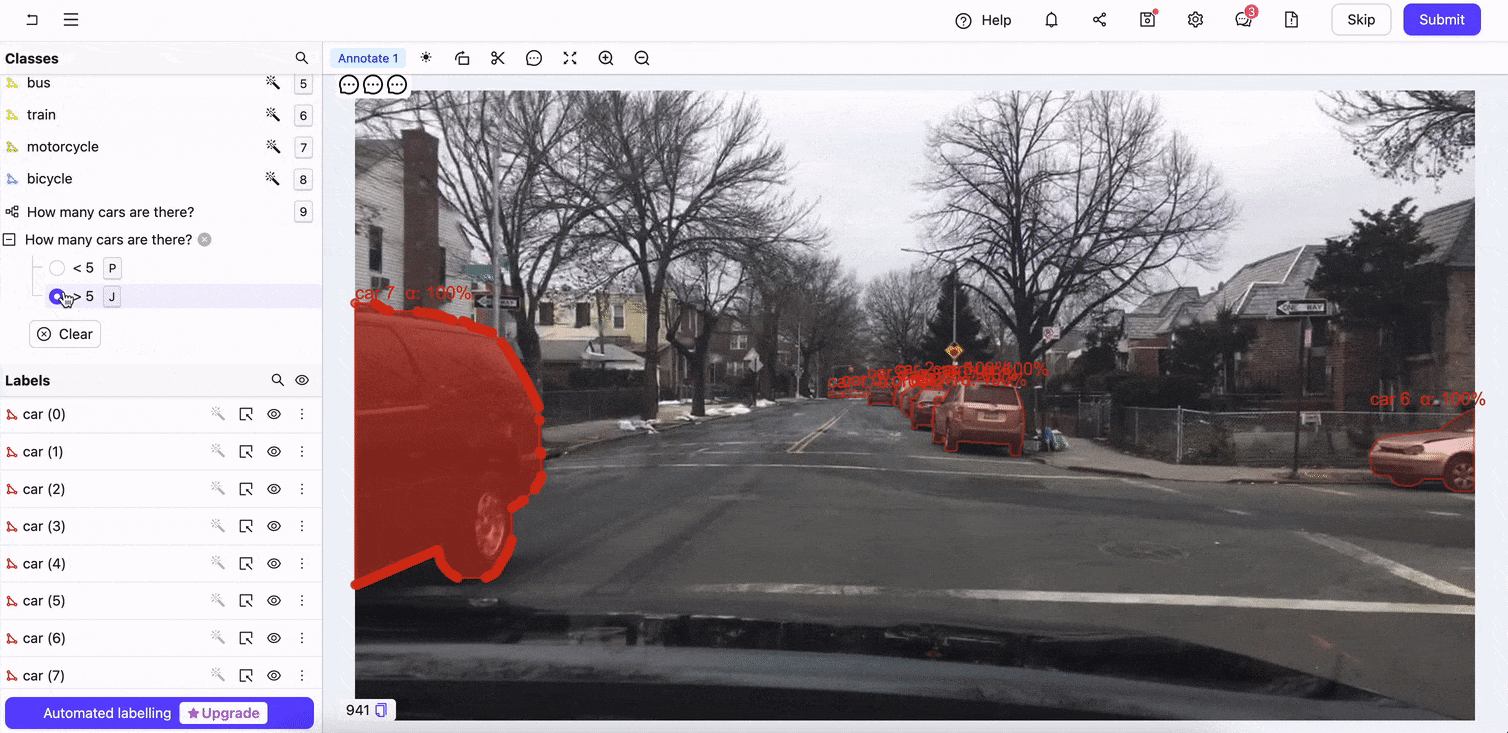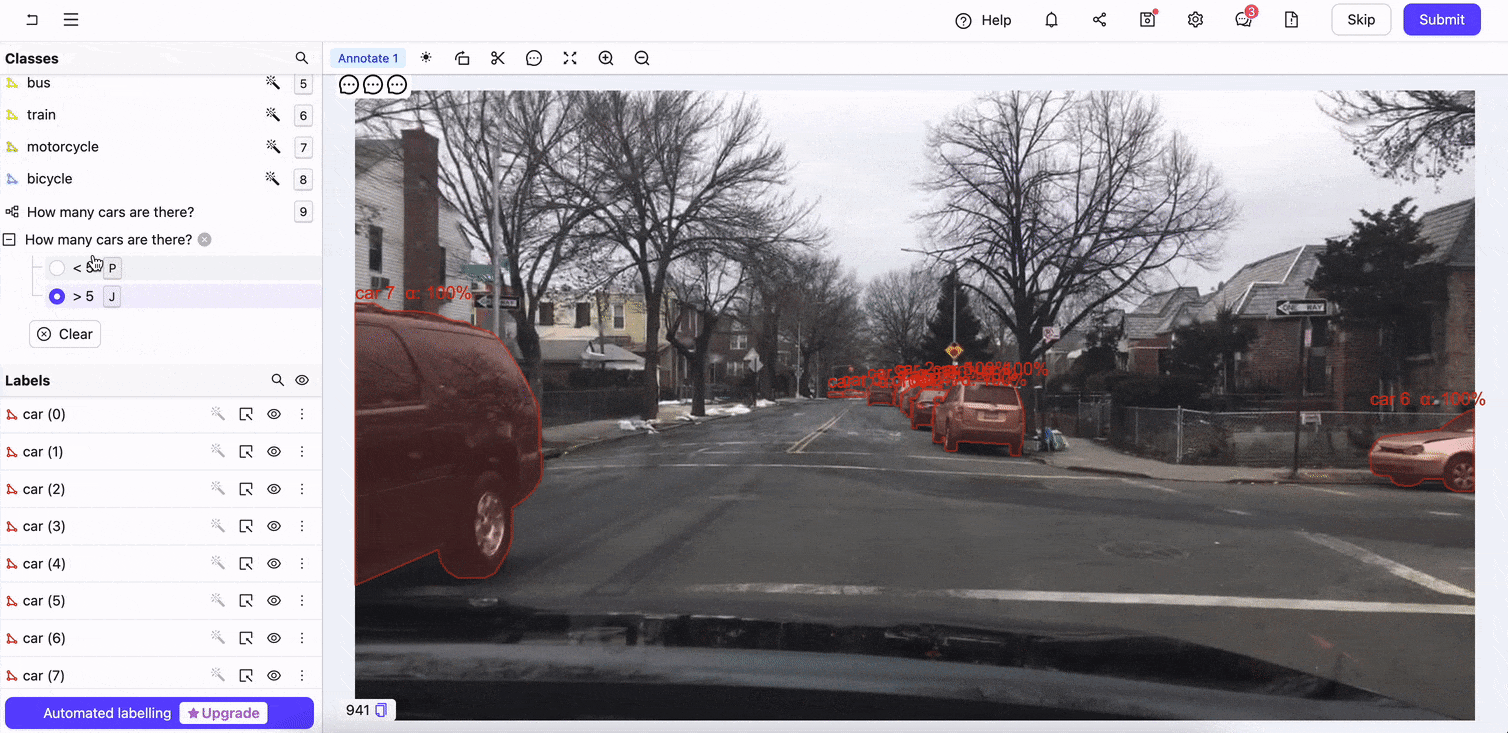
Encord Annotate in action
Automation with Human Oversight
Encord combines automated labeling with human review, allowing teams to label large datasets faster without sacrificing quality. For example:
- Pre-trained models generate initial labels.
- Human reviewers validate and refine these labels.
Collaboration and Consensus
With built-in collaboration tools, Encord enables teams to work together seamlessly. Features like comment threads and real-time updates improve communication and ensure consensus on labeling decisions.
Quality Assurance Tools
Encord’s quality control features include:
- Inter-annotator Agreement Metrics: Measure consistency across annotators.
- Audit Trails: Track changes and identify errors in labeling workflows.
- Validation Workflows: Automate error detection and correction.
Analytics and Insights
Encord provides actionable insights into dataset composition, annotation progress, and model readiness. These analytics help teams identify bottlenecks and optimize workflows for faster time-to-market.
By addressing these challenges, Encord empowers teams to build high-quality datasets that accelerate machine learning development and reduce labeling errors.
Evaluating the Impact of Effective Data Classification
When done correctly, data classification leads to better model performance, faster development cycles, and real-world applicability. By using platforms like Encord to streamline the classification process, organizations can focus on deploying AI systems that drive tangible outcomes.
Here are the key benefits:
Improved Model Accuracy
When data is properly classified, machine learning models can learn from clear and consistent patterns in the training data. This reduces noise and ambiguity, allowing the models to make more accurate predictions. For example, in applications like fraud detection or medical diagnostics, precise labeling ensures that the model correctly identifies anomalies or critical conditions. This not only improves precision and recall but also minimizes errors in high-stakes environments where accuracy is paramount.
Enhanced Generalization for Models
Accurate classification ensures that datasets are diverse and balanced, which directly impacts a model’s ability to generalize to new data. For example, a facial recognition model trained on a well-classified dataset that includes various skin tones, age groups, and lighting conditions will perform reliably across different scenarios.
Streamlined Decision-Making
Properly classified data provides a solid foundation for drawing actionable insights. Clean and organized datasets make it easier to analyze trends, identify patterns, and make data-driven decisions. In industries like finance or retail, this can mean quicker identification of fraud, improved inventory management, or a better understanding of customer behavior.
Regulatory Compliance and Data Security
In regulated industries like healthcare and finance, proper data classification is essential for meeting compliance standards such as GDPR, HIPAA, or PCI-DSS. Classifying sensitive information correctly ensures that it is stored, accessed, and processed in line with regulatory requirements according to data protection laws. Also, classification helps in cybersecurity as you segregate sensitive data from less critical information, improving overall security and reducing the risk of data breaches.
Laying the Foundation for Active Learning
Effective data classification supports iterative improvements in machine learning models through active learning. In this process, models can request additional labels for ambiguous or uncertain cases, ensuring that they are trained on the most relevant examples. This approach not only enhances long-term accuracy but also focuses human labeling efforts where they are most needed, optimizing both time and resources.
Key Takeaways: Data Classification
- Data classification organizes raw data into labeled datasets essential for training machine learning models.
- Accurate, diverse, and relevant data ensures better model performance and generalization.
- Automated tools like Encord speed up labeling while maintaining quality through human oversight.
- Clear guidelines, bias audits, and validation workflows address issues like inconsistent labels and dataset bias.
- Regular retraining, error analysis, and active learning keep models accurate and effective.
- Effective classification improves decision-making, supports compliance, and enhances data security.
Data classification is more than just a preparatory step; it’s the foundation of any successful machine learning project. With the growing demand for AI algorithms, the need for efficient, accurate, and scalable classification workflows is higher than ever. Data management and annotation platforms like Encord simplify this process, offering powerful classification tools to reduce errors, improve quality, and speed up development.
Frequently asked questions
Data classification is the process of organizing unstructured data into predefined categories or labels. It transforms raw information into a structured format that machine learning models can understand and learn from. This step is foundational for supervised learning models, as it provides the labeled datasets needed for training.
Data classification ensures the quality of the training and testing datasets, which directly impacts model performance. It helps machine learning models:
Learn patterns and correlations between input data and labels.
Make accurate predictions on new, unseen data.
Filter out irrelevant or noisy information to improve overall accuracy.
Continuous improvement ensures models remain relevant and accurate over time. This includes:
Retraining models with updated data.
Analyzing errors to identify and correct weaknesses.
Using active learning to address ambiguous cases and optimize labeling efforts.
Encord provides a comprehensive platform for data annotation and management, enabling users to organize, label, and refine their datasets efficiently. With features tailored for various use cases, Encord supports a wide range of data types and industries, making it a versatile solution for businesses seeking to enhance their data quality.
Encord provides tools that enable users to efficiently conduct bulk classification tasks by utilizing various filtering approaches. The platform allows for quick and interactive data curation, ensuring that users can manage large datasets without the bottlenecks typically associated with traditional annotation workflows.
Encord provides robust annotation tools that help in creating golden data sets by allowing users to annotate a wide range of classifications. This process enables the identification of edge cases and quantifies the model's accuracy, ensuring that the training data is reliable and comprehensive.
Data is critical in machine learning, with teams spending approximately 80% of their time on data-related tasks. Encord emphasizes that while models and compute resources may be commoditized, quality data remains unique and irreplaceable, making it essential for successful AI initiatives.
Encord offers a comprehensive platform that streamlines data management and visibility, allowing teams to efficiently handle training data post-collection. This includes features for data annotation and model debugging, ensuring a smooth workflow for data operations.
Yes, Encord can accommodate telemetry data, such as environmental readings from sensors, including temperature, humidity, and pressure. Its platform allows users to groom this raw data before it is fed into models, ensuring it becomes actionable and meaningful.
Encord supports a range of annotation types including object classification, counting, and anomaly detection. The platform is designed to handle both static and dynamic classifications, enabling users to annotate complex workflows effectively.
Yes, Encord is versatile and can be applied to various machine learning use cases, including livestock monitoring and other animal sanitation projects. Its flexible features allow users to adapt the platform to meet specific industry needs.
Encord's Index feature allows users to identify and curate the data needed for training sets. This helps customers streamline their data selection process and ensure they are utilizing the most relevant information for model training.