Active learning is a machine learning technique that allows algorithms to selectively choose which data samples to request labels for, optimizing their learning process. This approach is particularly useful when labeled data is limited or when labeling is expensive or time-consuming. By focusing on the most informative data samples, active learning can reduce the labeling cost and improve the performance of the model.

In traditional machine learning, the model is trained using a labeled dataset where all the samples are labeled. However, labeling a large amount of data can be expensive and time-consuming. In contrast, active learning aims to train the model using the minimum number of labeled samples while achieving high accuracy.
Active Learning Query Strategies
As we discussed above, active learning improves the efficiency of the training process by selecting the most valuable data points from an unlabeled dataset. This step of selecting the data points, also known as query strategy, can be categorized into three methods.
Stream-based Selective Sampling
Stream-based selective sampling is an active learning strategy used when data is generated in a continuous stream, such as in real-time or online data analysis. The model is trained incrementally on the stream of data, selecting the most informative samples for labeling to improve its performance. A sampling strategy is employed to measure the informativeness of each sample and determine which samples the model should request labels for. Uncertainty sampling selects the samples the model is most uncertain about, while diversity sampling selects samples most dissimilar to the already seen samples. Stream-based selective sampling is advantageous in handling large volumes of continuously generated data. However, the effectiveness of the technique is dependent on the quality of the sampling strategy used, and care must be taken to minimize the risk of selection bias. Stream-based selective sampling is particularly useful in real-time or online data processing applications.
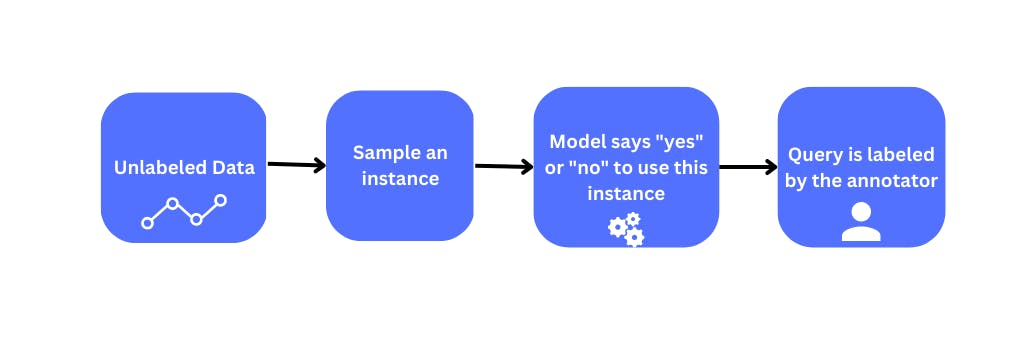
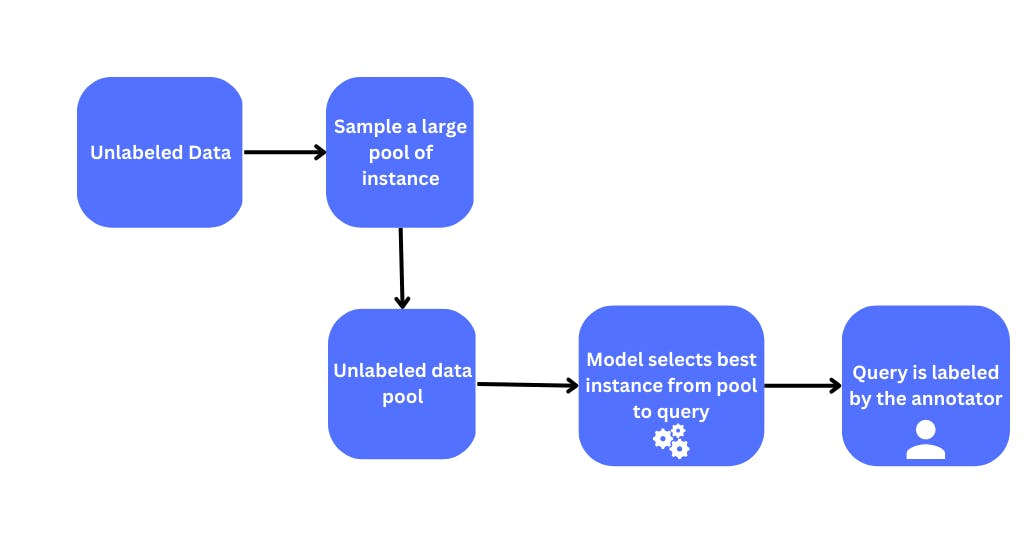
Pool Based Sampling
Pool-based sampling is a popular method used in active learning to select the most informative examples for labeling. This approach creates a pool of unlabeled data, and the model selects the most informative examples from this pool to be labeled by an expert or a human annotator.
The newly labeled examples are then used to retrain the model, and the process is repeated until the desired level of model performance is achieved. pool-based sampling can be further categorized into uncertainty sampling, query-by-committee, and density-weighted sampling.
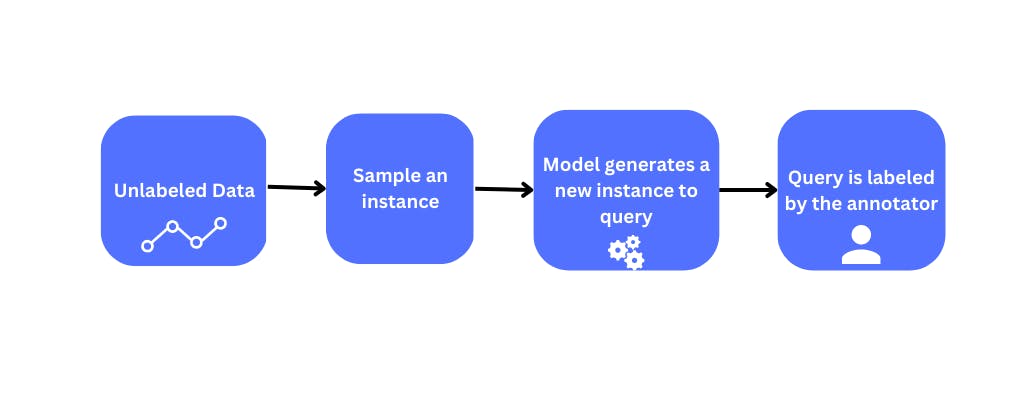
Query Synthesis Methods
Query synthesis methods are a set of active learning techniques that create new samples for labeling by synthesizing them from existing labeled data. These methods are particularly useful when the labeled dataset is small or obtaining new labeled samples is expensive.
One approach to query synthesis is to perturb existing labeled data, for example, by adding noise or flipping labels. Alternatively, new samples can be generated by interpolating or extrapolating from existing labeled samples, and the model is retrained. Generative Adversarial Networks (GANs) are commonly used for generating synthetic data samples, which are then labeled by annotators and added to the training dataset. The model then learns from these synthetic samples generated by the GANs.
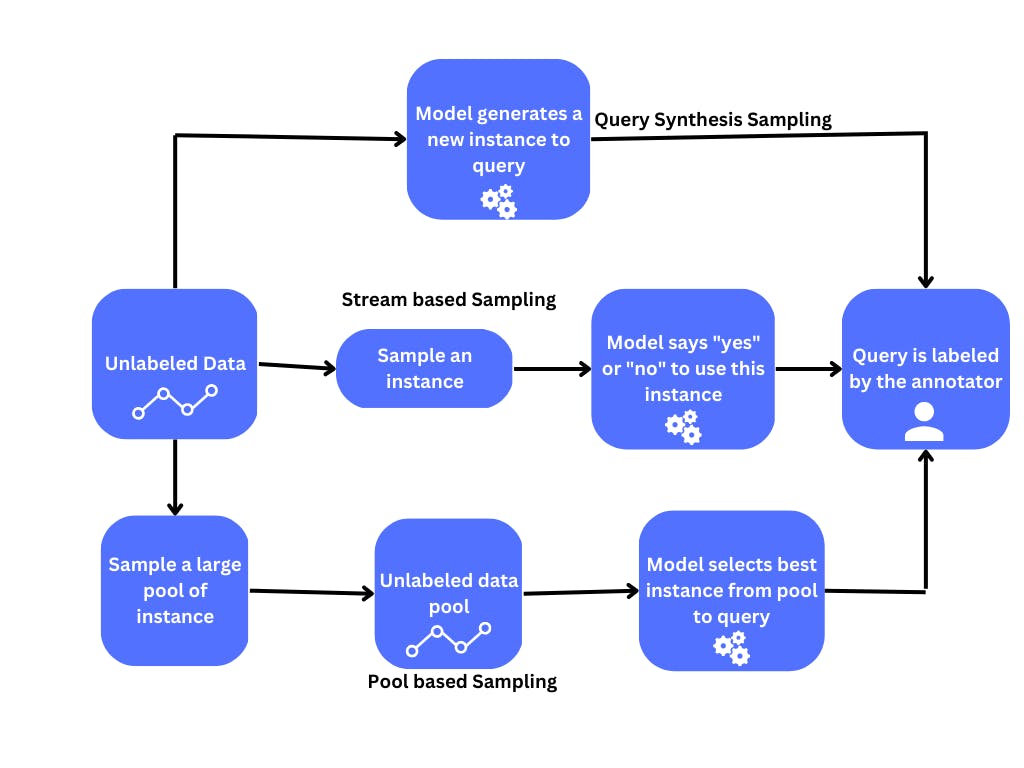
Below is an image showing the comparison between the query strategies for active learning.
Active learning has been successfully applied in many fields, including text classification, object recognition, speech recognition, and many others. Active learning has been used to classify emails, documents, and web pages in text classification. In object recognition, active learning has been used to recognize objects in images and videos. In speech recognition, active learning has been used to recognize speech commands and transcribe audio recordings.
Active learning has many benefits over traditional machine learning. It reduces the labeling cost and improves the performance of the model by focusing on the most informative data samples. It also reduces the amount of labeled data needed to achieve a certain level of accuracy, making it a valuable tool in many practical applications. Moreover, active learning can be combined with other machine learning techniques such as transfer and deep learning to further improve the model's performance.
However, active learning also has some limitations and challenges. One of the main challenges is selecting the right active learning strategy for a given problem. Different strategies may perform differently depending on the type of data and the task. Another challenge is the uncertainty of the selected samples, which can lead to incorrect labeling and bias in the model. Finally, active learning may not be applicable in some scenarios where labeling is not possible or where the data is already labeled.
In conclusion, active learning is a powerful machine learning technique that enables algorithms to learn efficiently from unlabeled data. By selecting the most informative samples, active learning can improve the performance of the model while reducing the labeling cost. This technique has been successfully applied in many fields and is a valuable tool for many practical applications.