Data Management Solution: Key Features to Look For

ML Lead at Encord
What is data management?
In today’s data-driven world, data management is the backbone of innovation, especially in artificial intelligence (AI). Data management refers to the systematic process of collecting, organizing, and maintaining data so that it is accessible, accurate, and secure to be used for a variety of tasks. Data management in AI involves processes such as data collection, storage, cleaning, annotation and review, curation, evaluation, monitor and integration. In the context of AI, data management plays an important role.
The efficiency of AI systems largely depends upon the data on which it is trained. High-quality and well-organized data helps to build robust machine learning (ML) models. If data management is lacking, AI systems may be built on inconsistent, redundant, or biased information, resulting in inaccurate predictions and poor decision-making. This is why modern data management solutions now include advanced features such as automated data cleaning, versioning, metadata tracking, and real-time integration pipelines, all of which are essential for supporting dynamic AI workflows.

Encord as a Data Management Tool (Source)
Data management solutions are not simply used to store data and retrieve it. They also address several data related issues with the help of following features.
Unifying Data
Data management solutions combine data from various sources such as different databases, file systems etc. to create a single dataset. This makes sure that AI models are trained on complete data rather than incomplete and fragmented data.
Data management systems allow the conversion of data into standardized formats and uniform naming conventions and schemas. It helps the centralization of dataset across teams working on building the AI models.
Breaking Down Silos
Data management solutions break down silos by enabling different teams to share their data. The data management system uses automated pipelines to continuously update and merge data. This feature ensures that teams working on such data get the updated data. Metadata tracking and data catalogs features in the data management systems make it easy to find and understand data from different sources.
Solving Data Quality Problems
Data management systems also solve data quality problems by automatically cleaning data and fixing errors with the help of smart algorithms. This ensures that the data for training AI models is accurate. It helps tracking changes made in the data over time to enable teams to compare versions of data, revert changes and run reproducible experiments. It also enforces security and governance policies to protect sensitive information and ensure compliance to build trust in AI outcomes.
A good data management system not only improves the predictive accuracy of machine learning models but also facilitates faster innovation and better decision-making across the teams and organization.
Types of Data Management Solutions
There are different types of data management solutions available to handle a variety of tasks based on the specific requirement. Following are the list of some popular data management solutions.
Database Management Systems (DBMS)
DBMS is the most popular data management solution. DBMS can store, retrieve, and manage structured data in a structured format (e.g., tables). For example, DBMS can store structured training data such as customer records, transaction logs, or sensor data for training AI models. It can be used to query and retrieve data quickly to build features for machine learning models. DBMS may serve as a backend for AI applications that require real-time data access (e.g., recommendation systems). DBMS can be used to store text for building NLP models and images to train Computer Vision models. Examples are MySQL, PostgreSQL, and Oracle that manage structured data using tables and SQL queries. No-SQL databases such as MongoDB are used to handle unstructured or semi-structured data. There are few other types of data stores such as key-value NoSQL database i.e. Redis, and graph databases i.e. Neo4j.
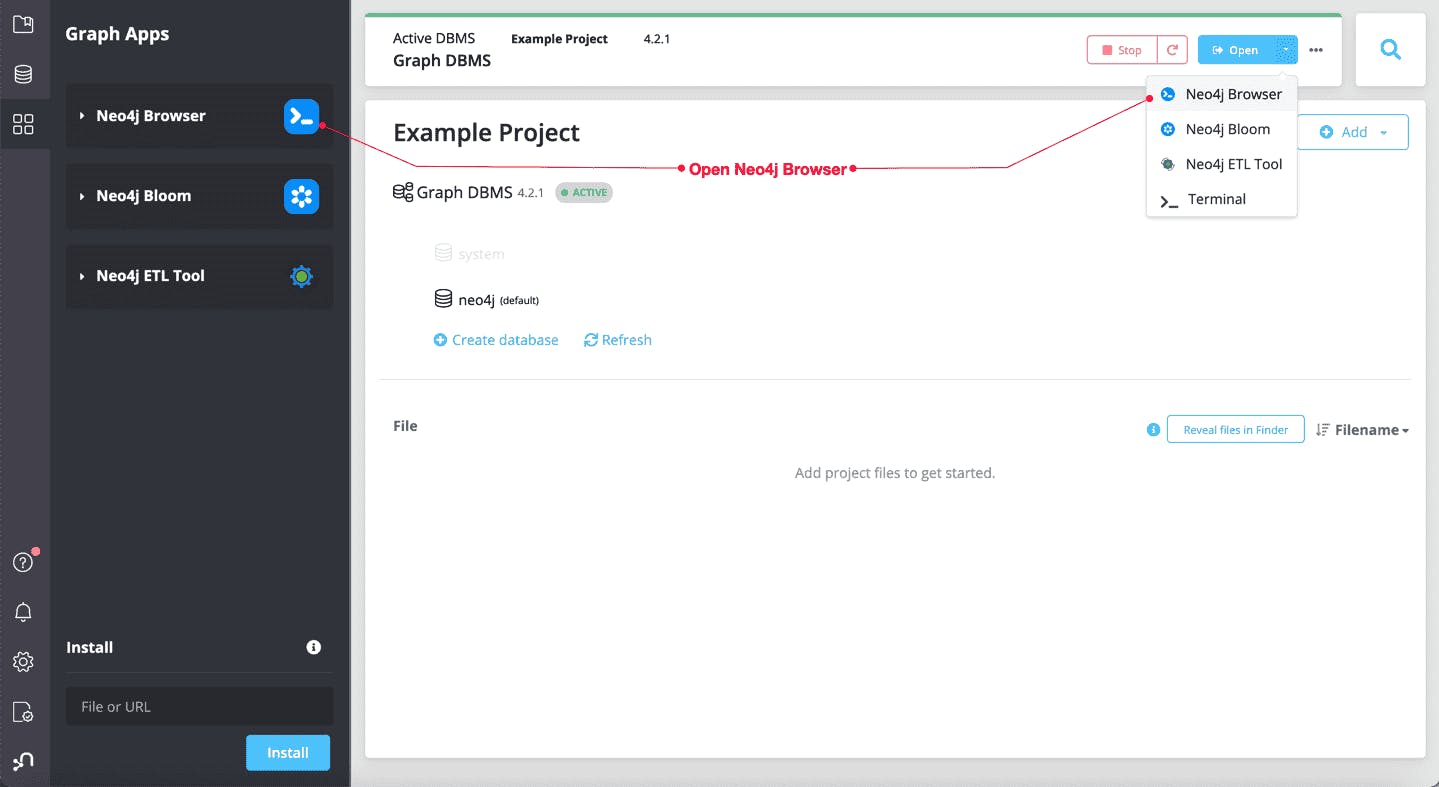
Neo4j Desktop (Source)
Data Warehouses
Data Warehouses are centralized repositories for storing and analyzing large volumes of structured data from multiple sources. Data Warehouses are used for analytical processing. Data warehouses may combine data from multiple sources into a single repository optimized for query performance.They can be used to extract features or trends from data by running complex queries and analytical operations. These features then can be used to train AI models. They also support large-scale training processes by providing high-performance data access during feature engineering. Examples of data warehouses are Amazon Redshift, Google BigQuery, and Snowflake.

Amazon Redshift (Source)
Data Lakes
Data lakes are systems that store large volumes of raw, unstructured, semi-structured, and structured data. They can store different types of data such as logs, images, videos etc. It can be useful for big data analytics, machine learning, and other purposes where data schema are not well-defined. For training AI models, it can store raw, unstructured data such as images, videos, logs and also enable exploratory data analysis (EDA). For example, to build AI models for healthcare applications, data lakes such as AWS S3 can be used to store and process medical images (X-rays, MRIs). Examples of data lakes are AWS S3, Azure Data Lake, Databricks.

Azure Data Lake (Source)
Master Data Management (MDM)
Master Data Management is used to store single, consistent business data such as customer, product, or employee data. In the context of AI, MDM eliminates data silos and ensures data consistency and helps in improving data accuracy of training data. For example, an e-commerce company can use MDM to create a unified customer profile for building personalized recommendation systems. Examples of MDM are Informatica MDM, SAP Master Data Governance.

AI-driven match and merge in Informatica MDM (Source)
Challenges in Data Management
AI models are generally trained on large amounts of data. There are many challenges in managing such data. The following are some of the common challenges:
Data Quality and Consistency
Performance of AI models depends upon high-quality data. Inconsistent, incomplete, or noisy data can lead to models that perform poorly or make biased predictions. For example, while building a computer vision project, if the collected images have different resolutions, lighting conditions, and noise levels, the model may learn incorrect features. To overcome this, advanced data cleaning and normalization techniques should be applied to the images before training.
Data Integration and Silos
A dataset is often collected from multiple sources with different formats, structures, and standards. Integrating this variety of data into a single, coherent dataset is complex and time-consuming. For example, an AI system for predictive maintenance in manufacturing may require sensor data of different machines stored in different databases. The model may overlook correlations in the data if it is not properly integrated, which would lower its capacity to generate accurate predictions.
Data Security and Privacy
AI models are generally trained on sensitive data which can include personal information in healthcare or proprietary business data etc. Therefore the security and privacy for using such data must be ensured. For example, in medical imaging, patient X-rays must be handled with strict adherence to privacy laws such as HIPAA. Techniques like data anonymization and secure data storage solutions are important to prevent breaches and unauthorized access.
Scalability and Volume
AI models require large volumes of data for training. Managing and processing such large datasets (often in the terabyte to petabyte range) requires scalable storage, processing power, and efficient data pipelines. For example, a global retailer using AI for personalized recommendations must use vast amounts of customer interaction data to train accurate models and this data is appended in the data source from time to time. Without scalable solutions like cloud storage and real-time integration pipelines, the system may lag or fail to update the data promptly.
Data Versioning and Traceability
As the data set increases over time, keeping track of different versions of the data set and ensuring reproducibility of experiments becomes a challenging task. For example, in iterative model training for autonomous vehicles, it is important to maintain versions of the training dataset as road conditions change seasonally. Data version control tools help track these changes so that models can be re-trained or compared reliably.
As these challenges directly affect the performance of AI models, a robust data management solution is needed.
Key Features in Data Management Tools
Data management tools are essential in handling, processing, and preparing data for AI and machine learning projects. Below are some key features of these tools:
Data Integration and Import Capabilities
This is a must have feature for data management tools. Every data management tool must be able to allow users to integrate and import data from multiple sources (such as APIs, databases, cloud servers or even IoT devices) and formats into the project. For example, to build healthcare AI models, the patient records, lab results, and imaging data needs to be integrated into the project pipeline from different systems and sources. A data management tool must be able to connect to these systems and allow importing the data into the project.

Importing Data from Multiple Sources in Encord (Source)
Annotation Flexibility and Customization
A data management system must also allow users to label, tag, or annotate data for supervised learning according to the specific use cases. For example, in an autonomous vehicle project the different objects in the images should be annotated with different labels or classes such as pedestrians, traffic signs, and other vehicles. A data management tool with flexible annotation capabilities allows them to customize labels and annotation formats for different object types and use cases.
Collaboration and Workflow Management
A data management system must enable teams to collaborate on data preparation, annotation, and model training with role-based access and task tracking. This is essential as AI projects involve cross-functional teams (data scientists, engineers, domain experts). Therefore the efficient collaboration for such user types ensures faster and accurate outcomes. For example, in a large-scale AI project for retail analytics, a team might include data engineers, annotators, and domain experts. The collaboration in the data management system allows team members to work on different parts of the dataset concurrently, assign review tasks, and maintain version control over annotations.
Quality Control and Validation Mechanisms
Data management tools must be able to ensure accuracy, consistency, and completeness of data and annotations using automated checks, manual reviews, and anomaly detection. Poor-quality data leads to defective and faulty AI models. Therefore a quality control mechanism is required to prevent errors from propagating through the pipeline. For example, in a computer vision project, a data management tool with quality control and validation mechanism will help in automated quality checks that flags inconsistent annotations in image annotations, such as CT scan annotation in healthcare dataset. This helps radiologists reviewers to quickly review and correct any errors to ensure that the final dataset is reliable for training diagnostic AI models in healthcare.

Identifying mislabelled annotation in Encord (Source)
Scalability and Performance
A data management platform must be able to handle large datasets and high-throughput workloads without compromising speed or reliability. Since AI projects often involve terabytes or petabytes of data, scalable tools ensure efficient processing and storage of such large data. For example, training a large language model (LLM) on billions of text documents requires a scalable data management tool with possibly distributed computing support, Cloud-native architecture for elastic scaling and optimized querying and indexing for fast data retrieval.
Automation and AI-Assisted Annotation
Data management tools should use AI to automate repetitive tasks like data labeling etc. Automation of such tasks reduces manual effort and speeds up tasks. The automated annotation is a must because manual annotation is time-consuming and expensive. AI-assisted annotation tools can improve efficiency and consistency of annotation tasks.
Integration with Machine Learning Frameworks
Data management tools should be compatible with popular ML frameworks such as TensorFlow, PyTorch, Scikit-learn for model training and deployment. Data management tools should integrate with the broader AI ecosystem to streamline workflows and allow data to be exported in formats that can be directly used for model training and testing. For example, a research lab working on deep learning models can export annotated datasets in TensorFlow or PyTorch compatible formats. This smooth integration accelerates the transition from data preparation to model development and evaluation.
Data Visualization and Reporting
A data management tool should offer reporting and visualization features that are easy to understand. It should include dashboards together with charts and reports to review data quality as well as model performance and annotation progress. The visualization of data helps in better understanding of trends present in the data to identify problems and make decisions. A data management tool should display real-time dashboards showing annotation progress alongside data distribution and error rates. The team gains insight through these findings which enables them to make accurate resource allocations and implement better processes.
How Encord helps in Data Management
Encord is a comprehensive data management platform for AI projects. It addresses the challenges of handling, annotating, and preparing data for AI workflows across multimultiple modalities. Below is a detailed explanation of how Encord’s features map to the essential functionalities needed for effective data management in AI:

Encord AI Data Management Life Cycle (Source)
Data Integration and Import Capabilities
Encord supports seamless integration with various data sources, including cloud storage (AWS, Google Cloud, Azure), databases (such as Oracle), local data sources and OTC. It allows users to import different data types such as images, videos, text, etc. into a unified platform. Encord eliminates data silos, enabling teams to centralize and manage data from disparate sources efficiently.
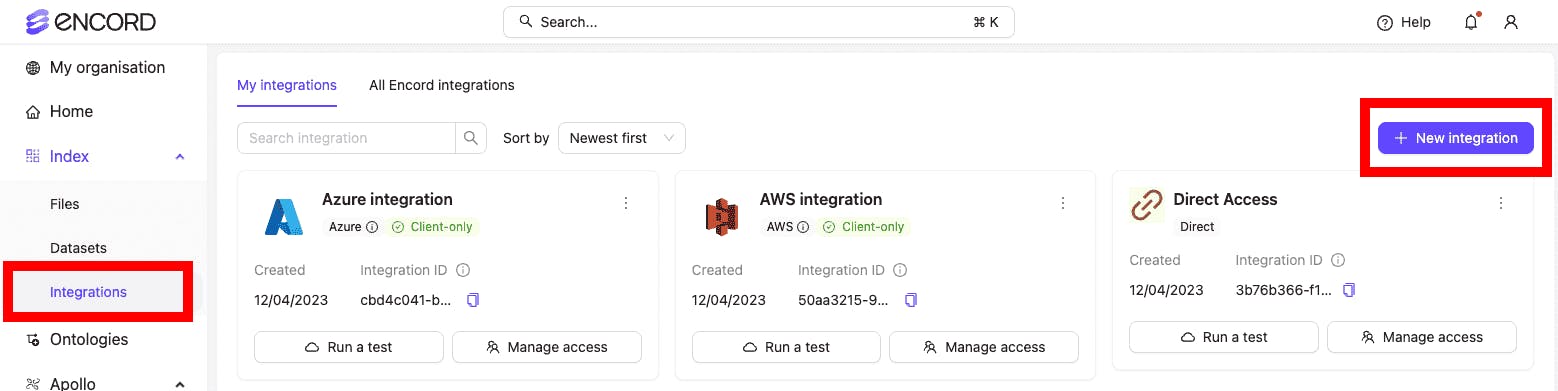
Data Integration in Encord from Different Sources (Source)
Annotation Flexibility and Customization
Encord provides a highly flexible and customizable annotation platform that supports a wide range of annotation types such as bounding boxes, polygons, keypoints, etc. for computer vision, natural language processing (NLP), and other types of AI projects.
Encord ensures high-quality annotations for specific AI use cases that help in improving model accuracy and reducing manual effort.

Keypoint Annotation in Encord (Source)
Collaboration and Workflow Management
Encord enables teams to work simultaneously on datasets. Multiple annotators, reviewers, and project managers can access the platform concurrently and get the real-time updates for the task. Built-in workflow management tools allows to assign specific tasks to team members and monitor annotation progress. This ensures that every stage of the data lifecycle is tracked which helps in maintaining high standards and meeting project deadlines.

Workflow Management in Encord (Source)
Quality Control and Validation Mechanisms
Encord includes built-in quality control features to ensure the accuracy and consistency of data. Encord has AI assisted validation processes to automatically flag inconsistencies or errors in annotations. This feature makes sure that no poor data enters the training pipeline. Encord also allows manual review cycles. Annotated data can be cross-checked by multiple experts to ensure that every label is accurate and reliable before being used in model training. Version control in Encord enables tracking and reviewing annotation histories.

Summary Tab for Performance Monitoring (Source)
Scalability and Performance Optimization
Encord is built to handle large scale datasets. The cloud-native architecture of Encord ensures scalability and performance. Its architecture is designed to maintain speed and responsiveness even when data size increases. Encord helps in managing large datasets efficiently with features such as scalability, fast retrieval etc. Encord Active also helps to evaluate the performance of models based on different metrics.

Evaluation Model Performance for Annotation Task (Source)
Automation and AI-Assisted Annotation
Encord supports AI assisted annotation to streamline the annotation process. This automated step can significantly reduce manual effort required for annotation and speed up the overall annotation process. Annotators correct or confirm AI-generated labels and the platform learns and improves these suggestions over time. This iterative cycle not only boosts efficiency but also increases the accuracy of your dataset. Encord Annotate offers high-quality annotation with automation capabilities using AI Agents to increase accuracy and speed.

Automated Annotation in Encord using AI Agents (Source)
Integration with Machine Learning Frameworks
Once the data is annotated and quality-checked, it can be exported to various formats (such as COCO, Pascal VOC, or custom JSON formats) that are directly compatible with popular ML frameworks like TensorFlow and PyTorch. Encord bridges the gap between data management and model training within the AI development lifecycle.

Exporting Labels from Annotation Projects (Source)
Data Visualization and Reporting
Encord provides visualization tools that let you monitor annotation progress, error rates, and overall project health in real time. Dashboards display key metrics that are essential for tracking performance and identifying areas for improvement. Encord generates detailed reports that offer insights into data distribution, annotation quality, and workflow efficiency. These reports can be used to inform decision-making and adjust strategies as needed.
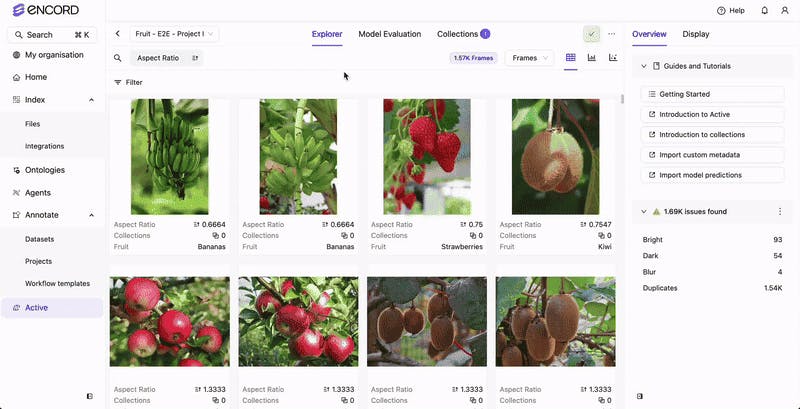
Data Visualization in Encord (Source)
Key Takeaways: Data Management Solution
Effective data management is important for building reliable and accurate machine learning models. A good data management system ensures data quality, consistency, and accessibility which as a result helps increase performance of AI.
- Importance of Data Management in AI: Proper data management ensures AI models are trained on high-quality, well-organized data. Poor data management can lead to inaccurate predictions and biased models.
- Key Features of a Data Management Solution: Data management solutions unify data from multiple sources, break down silos to assist collaboration, and perform automated data cleaning and quality control to ensure accuracy and reliability.
- Different Types of Data Management Solutions: There are different types of data management tools for specific needs, including DBMS for structured data, data warehouses for large-scale analytics, data lakes for raw and unstructured data, and MDM for maintaining consistency in business data.
- Challenges in Data Management for AI: Organizations must address data quality issues, integration complexities, security and privacy risks, scalability concerns, and the need for data versioning.
- Essential Features to Look for in Data Management Tools: AI-assisted data management tools should support data integration, flexible annotation, collaborative workflows, quality control mechanisms, scalability, and compatibility with ML frameworks like TensorFlow and PyTorch.
- How Encord Enhances AI Data Management: Encord supports data integration from different sources, AI assisted annotation, workflow management, quality control, scalability for large datasets, data export for various ML frameworks, and data visualization.
Frequently asked questions
Data management refers to the systematic process of collecting, storing, organizing, and maintaining data to ensure it is accurate, accessible, and secure. It plays a crucial role in AI by enabling efficient data preparation and processing for machine learning models.
AI models rely on high-quality, well-structured data for training. Poor data management can lead to biased, inaccurate, or inefficient AI models, affecting decision-making and overall performance.
AI-driven data management includes data collection, storage, cleaning, annotation, integration, version control, and security measures to ensure high-quality training data.
Database Management Systems (DBMS), Data Warehouses, Data Lakes, Master Data Management (MDM)
Data lakes store raw, unstructured, and semi-structured data and are useful for AI applications that require flexible data formats.
Data warehouses store structured data optimized for analytical queries and business intelligence.
Encord allows seamless integration with cloud storage solutions, such as S3, enabling teams to easily bring their data into the platform for labeling. Users can set up their S3 storage integration, which streamlines the process of importing audio files and other data types for annotation.
Encord offers robust cloud data management solutions that allow teams to efficiently store, organize, and retrieve their data from cloud platforms like S3. This enables users to streamline their workflow and ensure that their data is easily accessible for annotation and model training.
Encord helps users manage their data effectively, facilitating the evaluation of machine learning models through its comprehensive data management features. This includes organizing datasets, tracking changes, and providing insights that are essential for model performance assessment.
Encord offers robust data management tools that streamline the organization, tracking, and analysis of datasets. This eliminates the need for in-house development, allowing teams to focus on their core tasks while benefiting from a comprehensive management solution.
Encord supports scalability in data management by facilitating a seamless integration with cloud infrastructure. This allows teams to manage large volumes of data effortlessly while ensuring that their systems can grow in tandem with their operational needs.
Encord enables users to manage large data volumes by registering cloud data from sources like SRE, Azure, or GCP. Users can explore and curate their data at scale, ensuring that only relevant data is included in the annotation dataset.
Yes, Encord is built to handle diverse requirements from multiple data providers. The platform can be customized to meet specific needs, making it easier for teams to manage and annotate data consistently across different projects.
Yes, Encord supports integration with S3, allowing users to optimize storage and manage their data efficiently. This capability is essential for handling large datasets and ensuring seamless access to your annotated data.
Yes, Encord supports integration with various cloud storage solutions, allowing data to be streamed directly from there during production. This streamlines the data management process, making it more efficient for users.