How to Find and Fix Label Errors

Product Manager at Encord
Introduction
As Machine Learning teams continue to push the boundaries of computer vision, the quality of our training data becomes increasingly important. A single data or label error can impact the performance of our models, making it critical to evaluate and improve our training datasets continuously.
In this first part of the blog post series “Data errors in Computer Vision”, we'll explore the most common label errors in computer vision and show you how you can quickly and efficiently mitigate or fix them. Whether you're a seasoned ML expert or just starting out, this series has something for everyone. Join us as we dive into the world of data errors in computer vision and learn how to ensure your models are trained on the highest quality data possible.
The Data Error Problem in Computer Vision
At Encord, we work with pioneering machine learning teams across a variety of different use cases. As they transition their models into production, we have noticed an increasing interest in continuously improving the quality of their training data.
Most Data Scientists and ML practitioners spend much time debugging data to enhance their model performance. Even with automation and AI-supported breakthroughs in labeling, data debugging is still a tedious and time-consuming process based on manual inspection and one-off scripts in Jupyter notebooks.
Before we dive into the data errors and how to fix them, let us quickly recollect what a good training dataset is.
What is a good training dataset?
- Data that is consistently and correctly labeled.
- Data that is not missing any labels.
- Data that covers critical edge cases.
- Data that covers data outliers in your data distribution.
- Data that is balanced and mimics the data distribution faced in a deployed environment (for example, in terms of different times of the day, seasons, lighting conditions, etc.).
- Data that is continuously updated based on feedback from your production model to mitigate data drift issues.
Note! This post will not dive into domain-specific requirements such as data volume and modality. If you are interested in reading more about healthcare-specific practices, click here.
Today we will explain how to achieve points one and two for a good training data set, and in the upcoming posts in the series, we will cover the rest.
Let’s dive into it!
The Three Types of Label Errors in Computer Vision
Label errors directly impact a model’s performance. Having incorrect ground truth labels in your training dataset can have major downstream consequences in the production pipeline for your computer vision models. Identifying label errors in a dataset containing hundreds of images or frames can be done manually, but when working with large datasets containing 100.000s or millions of images, the manual process becomes impossible.
The three types of labeling errors in computer vision are 1) inaccurate labels, 2) mislabeled images, and 3) missing labels.
Inaccurate Labels
When a label is inaccurate, your algorithm will struggle to correctly identify objects correctly. The actual consequences of inaccurate labels in object detection have been studied previously, so we will not dive into that today.
The precise definition of an inaccurate label depends on the purpose of the model you are training, but generally, the common examples of inaccurate labels are:
- Loose bounding boxes/polygons
- Labels that do not cover the entire object
- Labels that overlap with other objects
Note! In certain cases, such as ultrasound labeling, you would label the neighboring region of the object of interest to capture any changes around it. Thus the definition of inaccurate labels depends on the specific case.
For example, if you’re building an object detection model for computer vision to detect tigers in the wild, you want your labels to include the entire visible area of the tiger, no more and no less.

Mislabeled Images
When a label attached to an object is mislabeled, it can lead to wrong predictions when deploying your model into the real world. Mislabeled images are common in training datasets. Research from MIT has shown that, on average, 3.4% of labels are mislabeled in common best practice datasets.

Missing Labels
The last common type of label error is missing labels. If a training data set contains missing labels the computer vision algorithm will not learn from samples without labels.

What Causes Label Errors?
Erroneous labels are prevalent in many datasets, both open-source, and proprietary datasets. They happen for a variety of reasons, mainly:
- Unclear ontology or label instructions: When labelers lack a clear definition of the objects and concepts that are labeled it can confuse the person performing the task. This can make it difficult to accurately and consistently understand the images and what is required of the annotator.
- Annotator fatigue: A burnout that can occur for labelers who are performing repetitive labeling tasks. The process can at times be tedious and time-consuming, and it can take a toll on the energy of the person doing it.
- Hard-to-annotate images: A hard labeling task can be difficult for various reasons. For example, it can require a high level of skill or knowledge to identify the objects in question. The image quality can be low, or the images can have many different objects confusing the annotator.
Next, we will show you a series of actions to prevent label errors in your labeling operations going forward!
How to Fix Label Errors?
To find label errors, you historically had to manually sift through your dataset, a time-consuming process at the best and impossible at worst. If you have a large data set, it would be like finding a needle in a haystack.

Luckily label errors can be mitigated today before deploying your model into production. In this section, we propose three strategies to can help you mitigate label errors during the labeling process or fix them later on:
1. Provide Clear Labeling Instructions
If you are not going to label the images yourself, providing your data annotation team with clear and concise instructions is essential. Good label instructions contain descriptions of the labeling ontology (taxonomy) and reference screenshots of high-quality labels. A good way to test the instructions is to have a non-technical colleague on your team review the instructions and see if they make sense on a conceptual level. Even better, dog food label instructions with your team to find potential pitfalls.
2. Implement a Quality Assurance System
In today's computer vision data pipelines, reviewing a subset, or all, of the created labels is the best practice. This can be done using a standard review module where you can decide upon the sampling rate of all labels or define different sampling rates for specific hard classes.
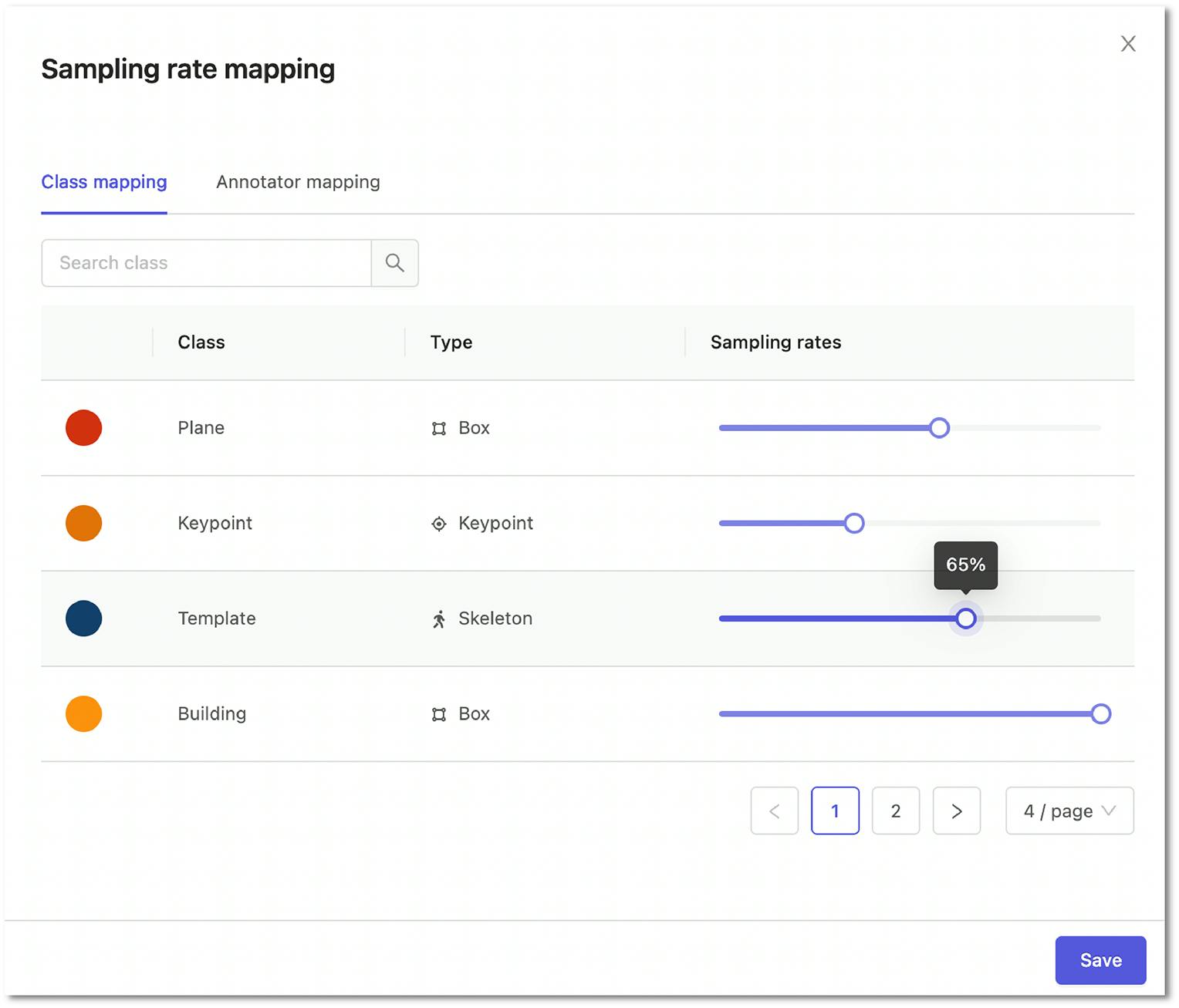
In special cases, such as medical use cases, it is frequently required to use an expert review workflow. This entails sending labels initially rejected in the review stage for an extra expert opinion in the expert review stage. Depending on the complexity of the use case, this can be tailored to the situation.
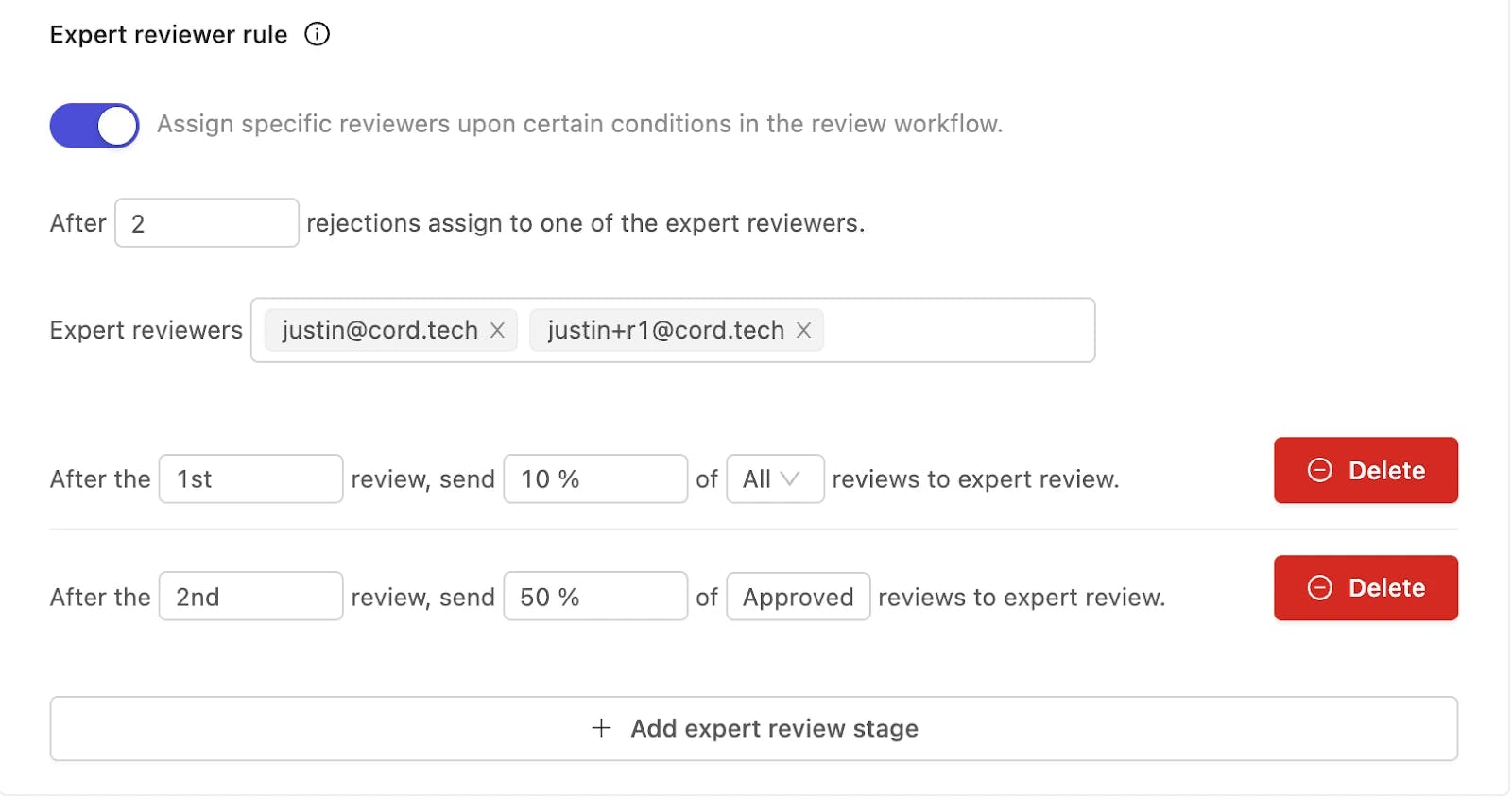
Check out this post to learn how to structure quality assurance workflow for medical use cases.
3. Use a Trained Model to Find Label Errors
As you progress on your computer vision journey, you can use a trained model to identify mistakes in your data labeling. This is done by running the model on your annotated images and using a platform that supports label debugging and model predictions. The platform should be able to compare high-confidence false positive model predictions with the ground truth labels and flag any errors for re-labeling.
In this example, we will use Encord Active, an open-source active learning framework, to find how a trained model can be used to find label errors.
The dataset used in this example is the COCO validation dataset combined with model predictions from a pre-trained MASK R-CNN RESNET50 FPN V2 model. The sandbox dataset with labels and predictions can be downloaded directly from Encord Active's GitHub repo.
Note! Check out the full guide on how to use Encord Active to find and fix label errors in the COCO validation dataset.
Using the UI we sort for the highest confidence false positives to find images with possible label errors.
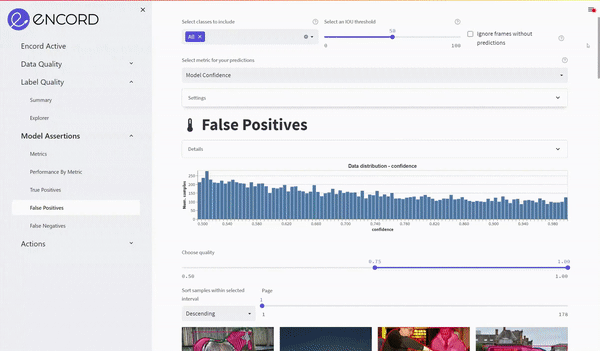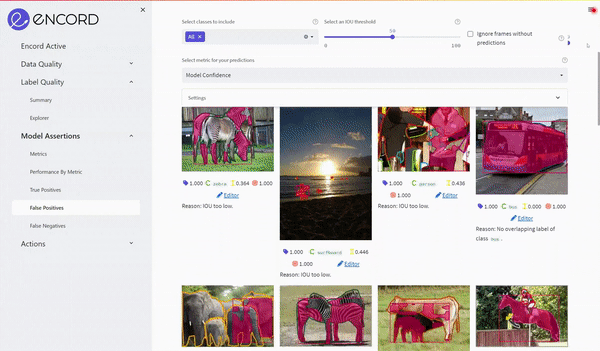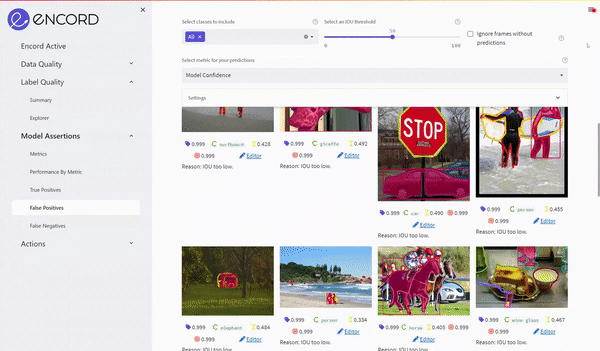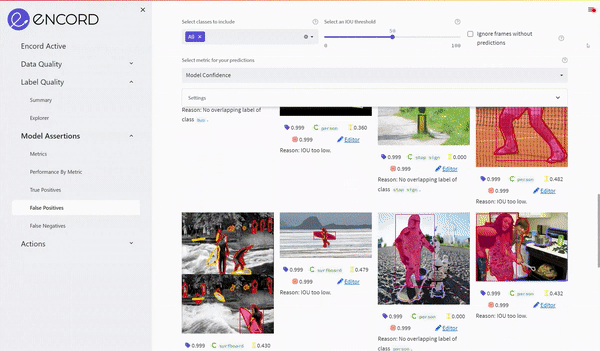
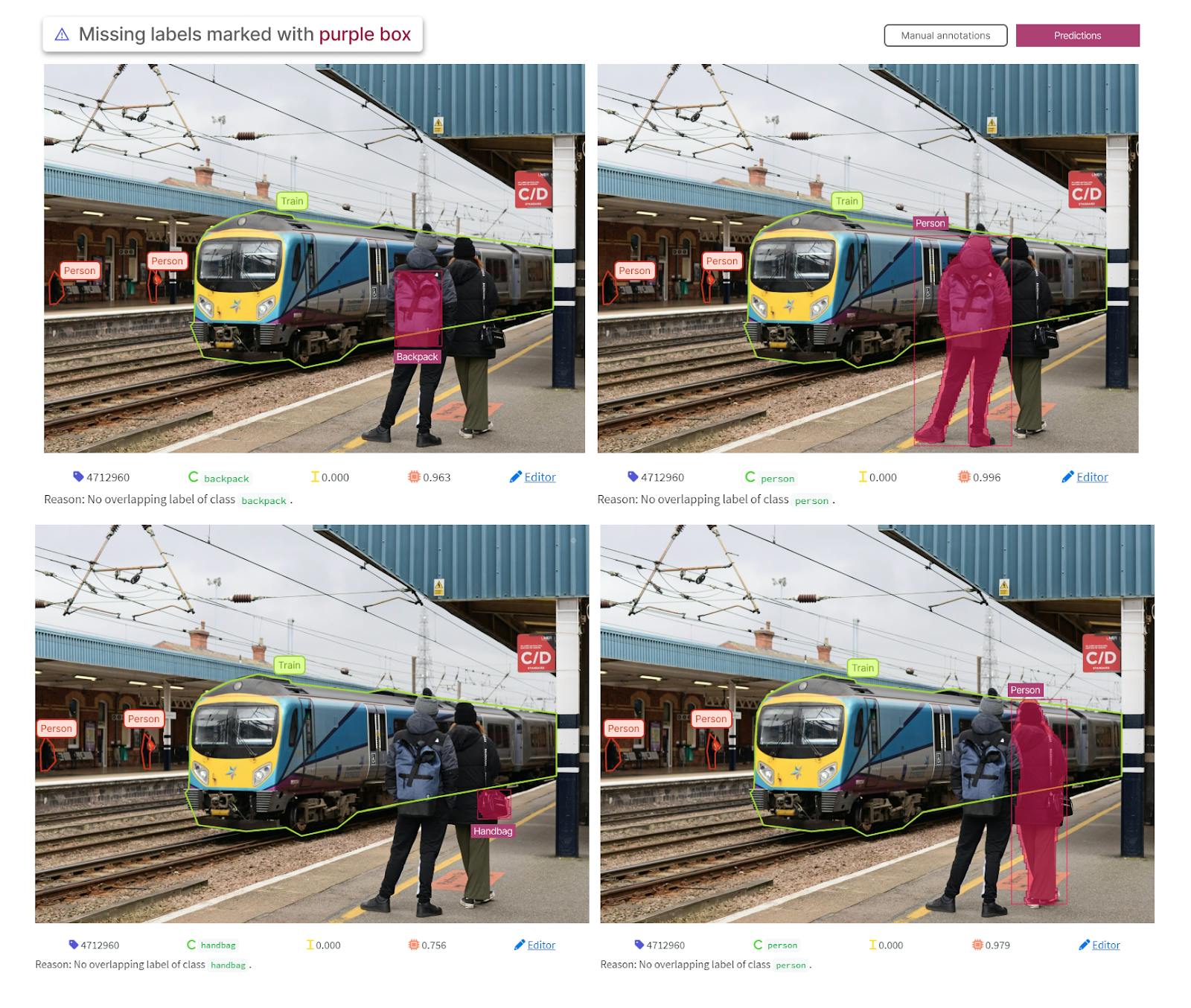
In the example below, we can see that the model has predicted four missing labels on the selected image. The objects missing are a backpack, a handbag, and two people. The predictions are marked in purple with a box around them.
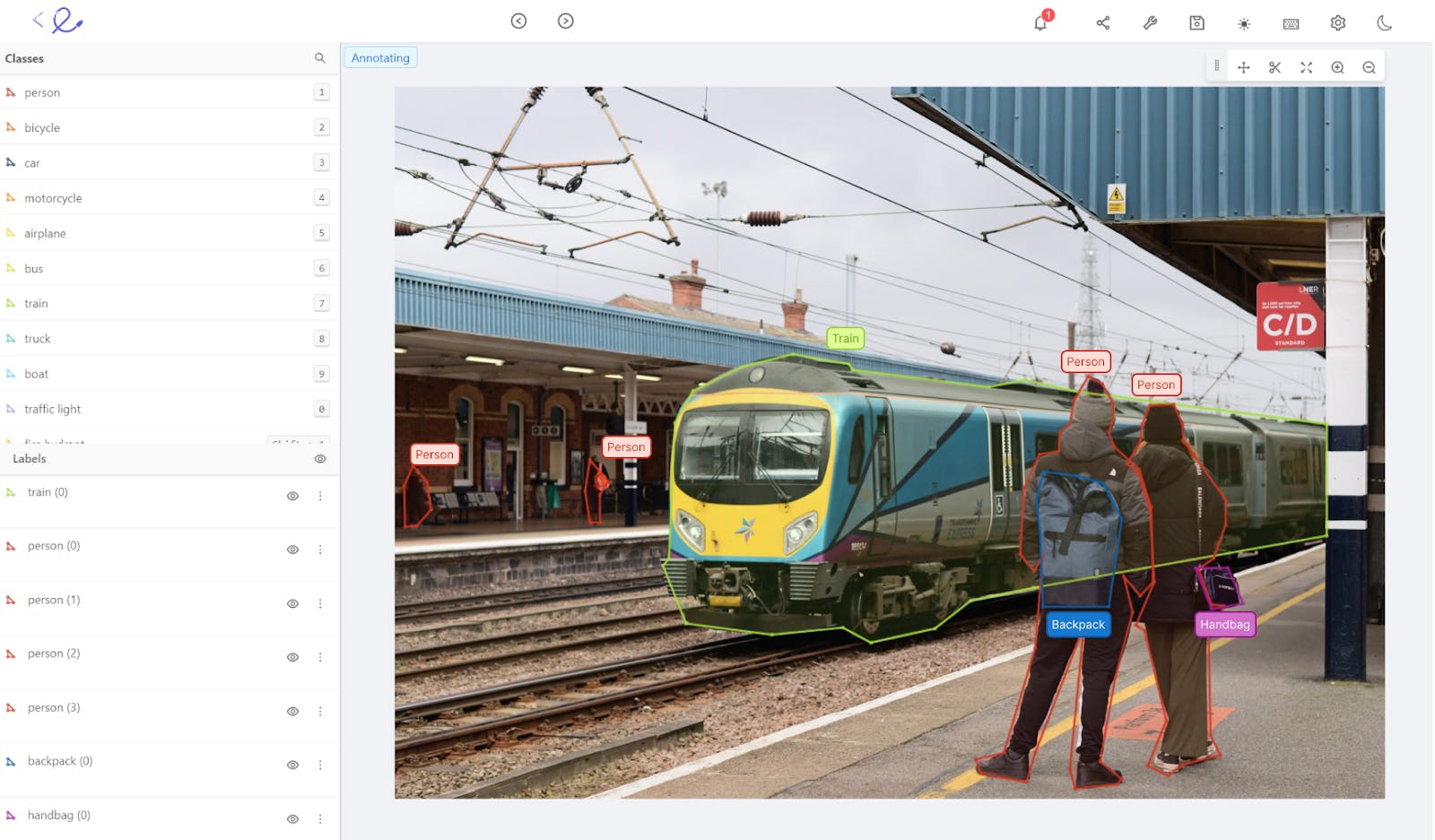
As all four predictions are correct, the label errors can automatically be sent back to the label editor to be corrected immediately.
This operation is repeated with the rest of the dataset to find and fix the remaining erroneous labels.
If you’re interested in finding label errors in your training dataset today, you can download the open-source active learning framework, upload your own data, labels, and model predictions, and start finding label errors.
Conclusion
In summary, to mitigate label errors and missing labels, you can follow three best practice strategies:
- Provide clear labeling instructions that contain descriptions of the labeling ontology (taxonomy) and reference screenshots of high-quality labels.
- Implement a Quality Assurance system using a standard review workflow or expert review workflow.
- Use a trained model to find label errors to spot label errors in your training dataset by running a model on your newly annotated samples to get model predictions and using a platform that supports model-driven label debugging.
Want to test your own models?
"I want to get started right away" - You can find Encord Active on Github here.
"Can you show me an example first?" - Check out this Colab Notebook.
"I am new, and want a step-by-step guide" - Try out the getting started tutorial.
If you want to support the project you can help us out by giving a Star on GitHub :)
Want to stay updated?
- Follow us on Twitter and Linkedin for more content on computer vision, training data, and active learning.
- Join our Discord channel to chat and connect.
Frequently asked questions
If the interpolation feature in Encord is not functioning properly, it is advisable to check the labels assigned to the frames and ensure they are set up correctly. If issues persist, users can reach out for support to troubleshoot any verification or feature-related concerns.
Encord provides a robust annotation platform that integrates error detection capabilities, allowing teams to identify mislabelled annotations quickly. This includes finding annotations that should not have been labelled and vice versa, ensuring high-quality training data.
To clean old labels in Encord, users should first assess the existing data for inaccuracies such as wrong classifications or missing classes. Following this, they can establish a workflow that includes reviewing and updating labels based on current ontology standards.
While some features have been deprecated, users can now access similar functionalities through the new buttons and view options. The label export functionality has been moved for easier access, and users can now view items in their queue without initiating a task.
Encord offers extensive support for setting up annotation projects, including guidance on determining workflows and best practices. Our customer success team is available to assist with project configurations and any questions that arise during the setup process.
Manual annotation in Encord involves reviewing and annotating documents based on specific criteria. This process includes matching the annotations to a structured JSON format that captures essential details, facilitating accurate data extraction and verification.
While Encord provides tools for managing labeling tasks, users can also conduct their own analyses of labeling accuracy, such as identifying common classification errors. This feature is valuable for teams looking to refine their labeling processes over time.
Setting up the Encord platform involves updating your labeling SOPs and ensuring your current documents align with the new processes. It's crucial to get your data uploaded onto the platform as soon as possible to facilitate training for your labeling team.
Encord provides tools to analyze label errors through label metrics, allowing users to pinpoint issues without manually reviewing every case. This feature helps in identifying problematic areas and enhancing overall model performance.
Encord provides access to a variety of experienced labeling partners who can support your annotation needs. This allows teams to execute projects efficiently while ensuring high-quality results.