From Vision to Edge: Meta’s Llama 3.2 Explained

Meta just released Llama 3.2, the next era of its open sourced AI models building on Llama 3.1. It introduces high-performance lightweight models optimized for mobile devices and vision models capable of advanced image reasoning, making it ideal for tasks like summarization, instruction following, and image analysis across a range of environments.
Key Features of Llama 3.2
- Expanded Model Variants: Llama 3.2 offers both lightweight large language models (LLMs) (1B and 3B) and medium-sized vision models (11B and 90B). This variety allows developers to select models tailored to their specific use cases, ensuring optimal performance whether running on edge devices or more powerful systems.
- Context Length Support: The lightweight 1B and 3B models support an impressive context length of up to 128K tokens, making them state-of-the-art for on-device applications such as summarization, instruction following, and rewriting tasks.
- Hardware Compatibility: These models are optimized for deployment on Qualcomm and MediaTek hardware, as well as Arm processors, enabling efficient use in mobile and edge environments right from day one.
Llama 3.2: Vision Models
Llama 3.2 is the first of the Llama series to incorporate vision capabilities.
Here are its key vision features:
- Image Understanding: The 11B and 90B vision models can perform complex tasks such as document-level understanding (including charts and graphs), image captioning, and visual grounding. For example, these models can analyze a sales graph and provide insights on business performance or interpret maps to answer geographical queries.
- Integration of Vision and Language: These multimodal models can extract details from images, understand contexts, and generate coherent text, making them ideal for AI applications that require comprehensive understanding and reasoning across different modalities.
- Drop-In Compatibility: The vision models serve as drop-in replacements for their corresponding text model equivalents, allowing developers to easily transition between text and vision tasks without extensive modifications to their existing applications.
Llama 3.2: Lightweight Models
The lightweight LLMs in the Llama 3.2 family (1B and 3B) are engineered for high efficiency and performance, particularly in constrained environments.
Here’s what sets them apart:
- Multilingual Capabilities: These models support multilingual text generation and are equipped with tool-calling functionalities.
- On-Device Privacy: A standout feature of the lightweight models is their ability to run locally on devices. This offers significant advantages, such as instantaneous processing of prompts and responses, as well as enhanced privacy by keeping sensitive data on the device and minimizing cloud interactions.
- Training Techniques: The lightweight models benefit from advanced training methods, including pruning and knowledge distillation. Pruning reduces model size while retaining performance, and knowledge distillation allows smaller models to learn from larger, more powerful models, ensuring they deliver high-quality results even in limited environments.

Technical Overview of Llama 3.2
Model Architecture
- Vision Models (11B and 90B): Designed for image reasoning tasks, integrating an image encoder with the pre-trained language model. This allows them to excel in tasks like image captioning and visual grounding.
- Lightweight Models (1B and 3B): Optimized for edge and mobile devices, these models utilize pruning and knowledge distillation to retain performance while reducing size, making them suitable for on-device applications.
Training Process
Llama 3.2's training involves several stages:
- Pre-training: It begins with the Llama 3.1 text models, adding image adapters and pre-training on large-scale image-text pair data.
- Adapter Training: This stage aligns image and text representations while maintaining existing language capabilities.
- Post-training: The models undergo supervised fine-tuning and synthetic data generation to optimize performance and safety.
The lightweight models support a context length of 128K tokens and outperform competitors in summarization, instruction following, and multilingual generation.
Llama 3.2 vs Llama 3.1
- Model Variants: Llama 3.2 offers multiple models (1B, 3B, 11B, and 90B) with multimodal capabilities (text + vision), while Llama 3.1 primarily features a large 405B parameter text-only model.
- Multimodal Capabilities: Llama 3.2 introduces vision models that can process images and text, enabling tasks like visual reasoning and image captioning, whereas previous Llama models are limited to text inputs.
- Efficiency and Deployment: Llama 3.2's smaller models are optimized for edge and mobile devices while Llama 3.1 requires significant computational resources for deployment.
- Context Length: Both models support an extensive context length of 128K tokens (approximately 96,240 words), allowing for detailed input processing.
- Language Support: Llama 3.2 officially supports eight languages and can be fine-tuned for more, while Llama 3.1 has multilingual capabilities but with less specificity on language support.
Performance of Llama 3.2
The performance of Llama 3.2 has been evaluated against leading foundation models such as Anthropic’s Claude 3 Haiku and OpenAI’s GPT4o-mini in image recognition and a variety of visual understanding tasks.

Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
Specifically, the 3B model has shown superior performance over models like Gemma 2 (2.6B) and Phi 3.5-mini in critical areas such as following instructions, summarization, prompt rewriting, and tool usage. Meanwhile, the 1B model remains competitive with Gemma in several benchmarks.

Llama Stack Distributions
The Llama Stack distributions offer developers a standardized interface through the Llama Stack API. This API provides essential toolchain components for fine-tuning and synthetic data generation, facilitating the creation of agentic applications.
The Llama Stack offers several key components to enhance usability and accessibility. The Llama CLI (command line interface) enables users to build, configure, and run Llama Stack distributions seamlessly. The client code is available in multiple programming languages, including Python, Node.js, Kotlin, and Swift, ensuring broad compatibility for developers.
Docker containers are provided for the Llama Stack Distribution Server and Agents API Provider, facilitating easy deployment across different environments. The distribution options include:
- Single-node Llama Stack Distribution: Available through Meta's internal implementation and Ollama.
- Cloud Llama Stack Distributions: Supported by platforms such as AWS, Databricks, Fireworks, and Together.
- On-device Llama Stack Distribution: Designed for iOS using PyTorch ExecuTorch.
- On-prem Llama Stack Distribution: Supported by Dell for localized deployments.

Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
Llama 3.2 Safety

Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
Llama 3.2 incorporates Llama Guard 3 to enhance safety and responsibility. This update includes Llama Guard 3 11B Vision, which filters text and image prompts to support new image understanding capabilities. The 1B and 3B models have also been optimized for lower deployment costs, with Llama Guard 3 1B reduced from 2,858 MB to 438 MB for greater efficiency in constrained environments. These safeguards are integrated into reference implementations and are readily available for the open-source community.
Real-World Applications of Llama 3.2
The availability of Llama 3.2 on edge devices is going to open up many generative AI applications.
On-Device Personal Assistants
The lightweight 1B and 3B models facilitate the development of personalized, privacy-focused applications. For example, users can create agents that summarize recent messages, extract action items from conversations, and even send calendar invites—all while ensuring that data remains local and secure.
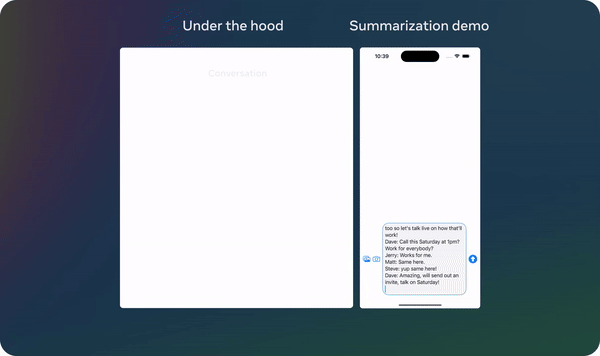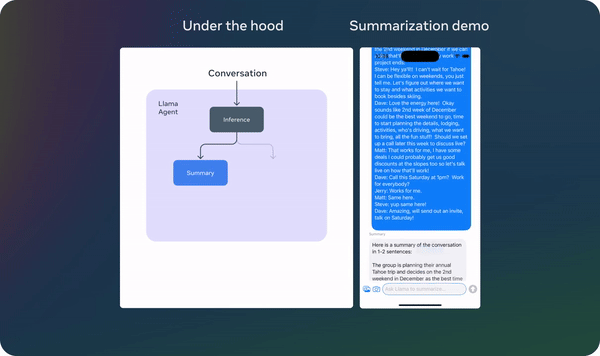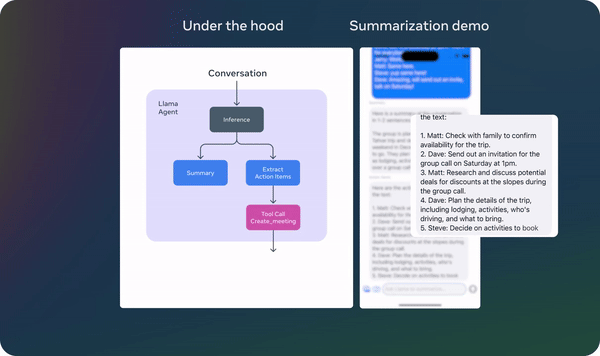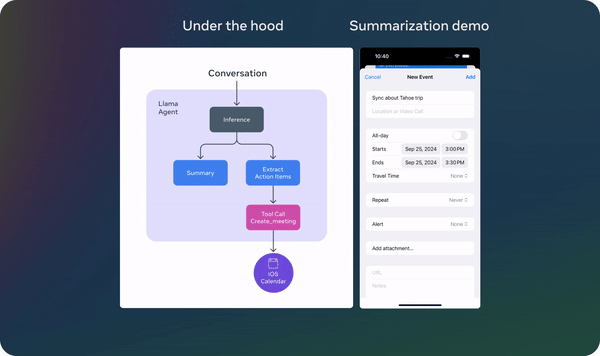
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
Image Understanding and Analysis
The 11B and 90B vision models excel in tasks requiring image reasoning, such as analyzing charts and graphs or providing image captions. Businesses can leverage these models for document-level understanding, enabling users to quickly retrieve insights from visual data—like identifying trends in sales reports or navigating maps based on user queries.
Education and Training
Llama 3.2 can be integrated into educational apps to support adaptive learning experiences. It can assist students in summarizing lecture notes or following instructional content, providing tailored support based on individual learning needs.
Data Retrieval and Analysis
The retrieval-augmented generation (RAG) capabilities of Llama 3.2 allow organizations to build applications that can fetch relevant information from large datasets. This is particularly useful in research and business intelligence, where quick access to data insights is crucial for decision-making.
How to Access Llama 3.2?
There are several options to access Llama 3.2.
- Direct Downloads: You can directly download the Llama 3.2 models from Meta’s official website or Hugging Face.
- Cloud Platforms: Llama 3.2 is also available on various cloud platforms like Amazon Bedrock, IBM watsonx, Google Cloud, Microsoft Azure, NVIDIA, Snowflake, etc.
- For edge and mobile device deployment: Meta is working with partners like Arm, MediaTek, and Qualcomm to offer a broad range of services at launch, ensuring optimized on-device distribution via PyTorch ExecuTorch.
- Single-node Distribution: This is facilitated through Ollama, allowing for versatile deployment options across various environments.