How to Manage Data Annotation Pipelines: A Guide to Building Scalable Medical AI Solutions

Whether it’s identifying abnormalities in medical imaging, extracting insights from clinical texts, or analyzing sensor data, the foundation of every high-performing medical AI model lies in a well-managed data annotation pipeline.
This guide delves into managing data annotation pipelines for medical AI, with a focus on building scalable solutions tailored to the unique requirements of healthcare applications.
Understanding Medical Data Annotation
Medical data annotation involves labeling datasets like imaging, text, or signals to train AI models. It demands precision, clinical expertise, and regulatory compliance to ensure AI systems are accurate and clinically relevant.
Key Reasons Medical Data Annotation is Critical
Training AI Models for Clinical Accuracy
AI models need extensive, high-quality training data to make accurate predictions. In healthcare, incorrect predictions can have life-threatening consequences, making precise annotations essential. For instance, segmenting tumor regions in MRI scans ensures that the model learns to differentiate between healthy and abnormal tissues.
Ensuring Model Generalization
Medical AI models must work across diverse populations and imaging conditions. Well-annotated data representing various demographics and clinical scenarios ensures the model can generalize its predictions effectively.
Aligning with Regulatory Standard
Annotations play a pivotal role in meeting regulatory requirements. Agencies like the FDA or EMA require evidence that models were trained on datasets with consistent and clinically validated annotations.
Enhancing Clinical Adoption
Clinicians are more likely to trust AI solutions built on datasets annotated with medical expertise. Properly labeled datasets reduce the risk of bias and ensure that models provide outputs aligned with real-world clinical needs.
Characteristics of Medical Data Annotation
Medical data annotation is also distinct from other forms of labeling:
- Expert-Driven: Requires input from medical professionals such as radiologists, pathologists, or clinicians.
- High Stakes: Errors in annotation can directly impact patient care when AI models are deployed.
- Regulated Environment: Compliance with data privacy laws like HIPAA and GDPR is essential.
- Multimodal and Complex: Often involves imaging, text, and time-series data that require different annotation approaches.
In medical data annotation, the stakes are high, but with the right strategies and tools, it is possible to meet these challenges and build scalable annotation pipelines that drive impactful medical AI solutions.
Common Types of Medical Data and Annotation Needs
Medical Imaging
Imaging datasets like X-rays, CT scans, MRIs, and ultrasounds are central to diagnostics. Key annotation tasks include:
- Segmentation: Pinpointing structures like tumors or organs at the pixel level.
- Bounding boxes: Highlighting regions of interest, such as fractures or nodules.
- Classification: Categorizing images by diagnostic criteria (e.g., normal or abnormal).
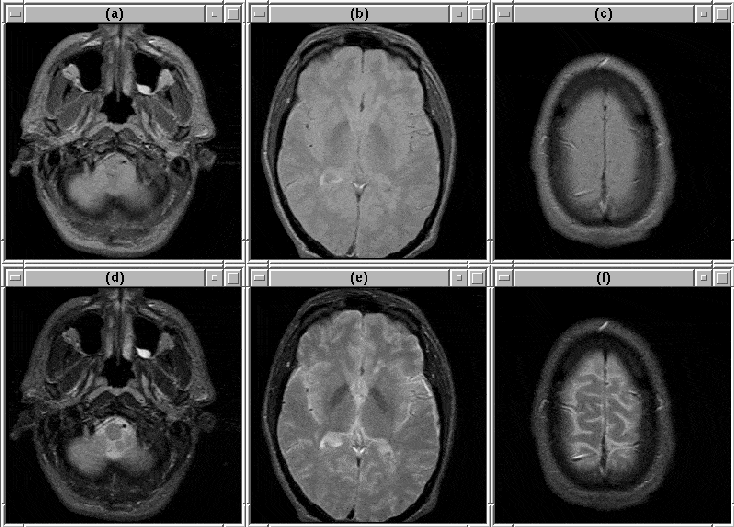
Selected slices from MRI Data Set, Source: Intracranial Boundary Detection and Radio Frequency Correction in Magnetic Resonance Images
Clinical Text Data
Clinical notes, patient histories, and discharge summaries are annotated for natural language processing (NLP). Tasks include:
- Entity recognition: Identifying terms like diagnoses, symptoms, or medications.
- Relation extraction: Linking entities, such as drug-disease interactions.
- Text classification: Categorizing text by labels like medical specialties.
Time-Series Data
Wearables, ICU monitors, and ECGs produce time-series data. Annotation involves marking events such as arrhythmias or abnormal blood pressure trends using ECG annotation tools, for example. Temporal annotations provide insights for predictive monitoring and event detection.

Source: ResearchGate
Genomic and Molecular Data
Genomic annotations focus on identifying genetic variants, mutations, or biomarkers. These labels drive research in precision medicine, aiding in diagnostics and therapeutic development.
Multimodal Data
Modern datasets often combine imaging, text, and signals. Multimodal annotations link these modalities, like connecting biopsy images with pathology reports, enabling comprehensive AI insights.
Building an Efficient Data Annotation Pipeline for Medical AI
If you’re working with medical data, building a solid annotation pipeline is a game-changer. It’s how you turn raw datasets into something AI can actually learn from—precise, clinically relevant, and scalable. Given how complex medical data can get—think everything from imaging to genomic sequences—you need a workflow that brings in expert knowledge, keeps things consistent, and checks all the boxes for privacy compliance.
Define Medical Annotation Objectives
The foundation of an effective annotation pipeline is clarity in objectives. Define what you want the annotations to achieve and how they align with the clinical problem at hand.
Begin by identifying the type of annotation your data requires. For instance, segmentation may be necessary for detecting tumor boundaries in CT scans, while classification might be used to label X-rays as normal or abnormal. In clinical text, tasks like entity recognition (e.g., identifying symptoms or drugs) or relation extraction (e.g., linking conditions to treatments) are common.
Additionally, it is important to specify the level of detail needed. For imaging datasets, pixel-level annotations may be critical for surgical planning, while high-level bounding boxes might suffice for general diagnostics. For text or time-series data, the granularity could range from single terms to longer phrases or specific time events.
Finally, tie the objectives directly to clinical needs. For example, if the goal is to aid radiologists in diagnosing lung cancer, annotations should focus on highlighting nodule locations and malignancy characteristics. This can be done using DICOM annotation tools for radiology.
Select Annotation Tools Tailored to Medical Data
Medical annotation tools must support domain-specific requirements and provide robust features for collaboration and quality control.
Look for tools that support the data formats and annotation tasks relevant to your project. For imaging datasets, DICOM compatibility and 3D annotation support are critical, especially for volumetric data like MRI scans. For text, tools should integrate medical ontologies such as SNOMED CT or ICD codes to standardize labels.
Tools should allow multiple users, such as radiologists and pathologists, to annotate and review data collaboratively. Features like annotator dashboards, version tracking, and real-time comments enhance team productivity.
Finally, medical AI projects often require tailoring annotation tools to specific needs. For example, tumor growth monitoring might need temporal annotations across multiple scans, while multimodal datasets may require linking text reports to imaging findings.
Assemble a Team of Medical Experts
Medical data annotation requires a level of domain expertise that cannot be substituted by general knowledge. Building a multidisciplinary team of professionals ensures the clinical accuracy of your annotated datasets.
Depending on your data type, include radiologists, pathologists, clinicians, or nurses. Radiologists are invaluable for imaging datasets, while pathologists excel in histopathology. Clinicians are instrumental in annotating clinical text or time-series data, as they understand the context behind terms and trends.
Even with expert annotators, consistency in labeling requires proper training. Provide detailed guidelines on the annotation protocol, including examples of correct and incorrect annotations. Training sessions can also cover using the annotation tools and understanding the project's clinical objectives.
Additionally, encourage annotators to provide feedback on ambiguous cases or unclear guidelines. This feedback loop and iterative approach improves the quality of annotations and refines protocols.
Design Annotation Protocols for Consistency
Consistency in annotations is critical, particularly in medical AI, where even minor discrepancies can affect model performance. A well-designed annotation protocol ensures uniformity across annotators and reduces variability.
- Label Definitions: Provide clear definitions for each label. For instance, define what constitutes a "tumor" versus a "cyst" in radiology or distinguish between "adverse reaction" and "side effect" in clinical text.
- Ambiguity Resolution: Establish rules for handling uncertain cases, such as blurry imaging regions or incomplete clinical notes. Annotators should know how to flag such cases for expert review.
- Examples and References: Include annotated examples as references. These serve as benchmarks for annotators and help clarify edge cases.
Incorporate Quality Assurance (QA) in Medical Annotations
Implementing a robust QA framework ensures that errors are identified and corrected early in the pipeline.
- Double Annotation: Assign the same dataset to two independent annotators. Compare their annotations and resolve discrepancies through expert review or consensus discussions.
- Gold Standards: Use a subset of data annotated by experienced clinicians as a benchmark. Compare annotations against this gold standard to measure quality.
- Inter-Annotator Agreement: Evaluate consistency between annotators using metrics like Cohen’s Kappa or F1 score. Low agreement highlights areas where protocols may need refinement.
AI-Assisted Annotation for Efficiency
AI-assisted tools can accelerate the annotation process, especially for large datasets. By combining human expertise with machine intelligence, you can streamline workflows and reduce the time spent on repetitive tasks.
- Pre-Annotations: Use pretrained models to generate initial labels. For example, an AI model could outline potential tumor regions in an MRI scan, which radiologists can refine.
- Active Learning: Prioritize annotating cases where the model is least confident, allowing the AI to learn from edge cases and improve faster.
- Smart Features: Modern tools offer smart features like highlighting probable areas of interest or suggesting likely text entities based on context.
Ensure Data Privacy and Security
Medical data is highly sensitive, and handling it responsibly is non-negotiable. Annotation pipelines must adhere to strict data privacy and security standards to protect patient information.
- De-Identification: Strip personal identifiers from datasets to anonymize them. For example, remove names, dates, and medical record numbers from clinical notes.
- Encrypted Storage: Store data on HIPAA-compliant servers with encryption to prevent unauthorized access.
- Access Control: Implement role-based access controls, allowing only authorized personnel to view or edit specific datasets. Maintain detailed audit logs to track activity.
Scaling Medical Data Annotation Pipelines
Once an efficient annotation pipeline is established, scaling it becomes the next challenge. Scaling is critical for medical AI, where datasets need to be diverse, large, and representative of various patient populations and conditions. Expanding a medical data annotation pipeline requires careful planning to maintain quality, comply with regulations, and meet the growing demands of AI development.
Expand Annotation Capacity with Expertise
Scaling medical annotation means increasing the volume of labeled data without compromising clinical accuracy. Achieving this requires a strategic approach to workforce expansion and expertise management.
- Recruiting Additional Experts: As your dataset grows, you’ll need to onboard more radiologists, pathologists, clinicians, or domain specialists. Use standardized onboarding procedures, including training on tools and annotation protocols, to ensure consistency.
- Tiered Annotation Systems: Implement a two-tier system where less complex tasks (e.g., binary image classifications) are handled by junior annotators, and complex tasks (e.g., tumor segmentation) are escalated to senior experts.
- Outsourcing with Quality Control: Partner with trusted annotation service providers, but maintain in-house QA to ensure external annotations meet your standards.
Optimize Workflow Automation
By leveraging AI and advanced tools, you can reduce manual workload and focus expert efforts on higher-value tasks.
- Pre-Annotations at Scale: Use AI models trained on existing datasets to generate initial annotations for large datasets. Experts can then refine these annotations, dramatically reducing time spent on routine tasks.
- Automated QA Checks: Incorporate automated quality checks to identify obvious errors, such as mislabeled or inconsistent annotations, before manual review.
- Streamlining Redundant Tasks: Automate data preprocessing tasks, such as converting imaging formats or anonymizing text, to save time for annotators.
Ensure Dataset Diversity
For medical AI models to generalize well, training data must represent diverse populations, diseases, and imaging conditions. Scaling your annotation pipeline should include efforts to diversify the datasets you annotate.
- Broaden Data Sources: Incorporate data from different institutions, regions, and populations. For example, include imaging datasets from facilities with varying equipment and protocols.
- Expand Clinical Scenarios: Capture rare diseases, multi-disease cases, and edge cases often underrepresented in smaller datasets.
- Monitor for Bias: Regularly evaluate datasets for potential biases, such as overrepresentation of specific demographics, and address gaps by sourcing more balanced data.
Scale Tools and Infrastructure
Your annotation tools and infrastructure need to grow alongside your dataset volume. Scaling requires more than just adding annotators—it means upgrading platforms, storage, and processing capabilities to handle the increased workload.
- Cloud-Based Solutions: Migrate data and annotation workflows to cloud-based platforms that offer scalability and secure storage. This is especially useful for large imaging datasets, such as 3D CT or MRI scans.
- High-Performance Tools: Invest in annotation tools that can handle high-resolution imaging, large volumes of text, or multimodal data efficiently. Tools should support batch processing, real-time collaboration, and integration with other systems.
- Server and Bandwidth Upgrades: Ensure your servers and networks can manage the growing demands of simultaneous annotations, reviews, and QA processes.
Maintain Quality while Scaling
As you scale, ensuring quality becomes more challenging but remains non-negotiable in medical AI. A focus on consistent, clinically accurate annotations is essential for model reliability.
- Expand QA Teams: Increase the number of QA reviewers proportional to the annotation team. These reviewers should be experts capable of catching subtle errors or inconsistencies.
- Periodic Protocol Updates: As datasets and tasks become more complex, review and refine annotation protocols. Provide regular updates to annotators and ensure changes are well-documented.
- Continuous Training: Conduct periodic training sessions to ensure all annotators, especially new ones, stay aligned with evolving clinical guidelines and project needs.
Use Active Learning for Focused Scaling
Active learning is a strategy where AI models identify the most challenging or informative data points, allowing annotators to focus on these areas. This approach ensures your effort is directed where it matters most.
- Target Difficult Cases: Use active learning to prioritize annotations for edge cases, such as rare diseases or ambiguous imaging conditions, that improve model performance significantly.
- Iterative Training: Continuously train models with newly annotated data, using the model’s feedback to select subsequent batches for annotation.
- Reduce Redundancy: Focus on annotating examples that add the most value, rather than spending resources on redundant or overly simplistic cases.
Measure and Optimize Annotation Efficiency
Continuous evaluation and optimization are vital for scaling. Track key metrics to understand where bottlenecks exist and make data-driven improvements.
- Throughput Metrics: Measure the number of annotations completed per annotator per hour to identify inefficiencies.
- Quality Metrics: Track inter-annotator agreement, precision, and recall to monitor annotation accuracy.
- Workflow Analysis: Identify repetitive or time-consuming steps that could be streamlined with new tools or automation.
How Encord Streamlines Scalable Medical Data Annotation
Encord combines flexibility, scalability, and clinical-grade accuracy to meet the unique demands of medical AI projects. Its ability to handle diverse data types, streamline collaboration, and integrate AI-driven workflows makes it an indispensable tool for teams looking to scale their annotation efforts.
Key Features
- Tailored Support for Medical Data Types: Encord is designed to handle a variety of medical data formats, including imaging, text, time-series, and multimodal datasets, ensuring flexibility for complex medical AI projects.
- Scalable Annotation Infrastructure: The platform leverages cloud-based architecture, offering scalable storage and compute resources to manage large-scale annotations efficiently and provide easy access for distributed teams.
- Collaboration and Quality Control: Encord enables real-time collaboration, allowing annotators, reviewers, and domain experts to work together efficiently while ensuring high-quality annotations through double-blind reviews and inter-annotator checks.
- AI-Assisted Annotation for Efficiency: By integrating AI-driven pre-annotations and active learning workflows, Encord helps speed up the annotation process, allowing annotators to focus on refining challenging cases and improving model performance.
- Compliance and Security for Medical Data: With built-in secure and encrypted storage, Encord ensures that medical data remains compliant with privacy regulations like HIPAA and GDPR.
- Analytics and Optimization: Encord provides comprehensive analytics to track annotator performance, assess inter-annotator agreement, and identify workflow bottlenecks, enabling teams to optimize processes and scale effectively.

Key Takeaways: Scaling Medical AI Solutions
- High-Quality Data Annotation Drives Results: Precise and clinically relevant annotations form the backbone of successful medical AI models, ensuring accuracy, safety, and real-world applicability.
- Efficiency and Scalability Are Essential: Leveraging tools like AI-assisted annotation, active learning, and cloud-based platforms enables teams to scale their annotation pipelines without sacrificing quality.
- Compliance and Security Are Non-Negotiable: Adherence to regulations such as HIPAA and GDPR ensures ethical and secure handling of sensitive medical data.
- The Right Tools and Strategies Unlock Potential: Platforms like Encord streamline workflows, enhance collaboration, and provide analytics for continuous optimization, making it easier to scale medical AI efforts.
In conclusion, building a scalable data annotation pipeline is crucial for developing effective medical AI solutions. By understanding the unique challenges and requirements of medical data, implementing efficient workflows, and leveraging advanced platforms like Encord, teams can ensure high-quality annotations, streamline operations, and scale their efforts as needed.
As medical AI continues to evolve, having the right tools and strategies in place will be essential for driving innovation and improving healthcare outcomes.
Frequently asked questions
Medical data annotation is the process of labeling datasets such as imaging, text, or time-series data to train AI models in healthcare. This involves tasks like segmentation, classification, and linking data points to make them suitable for AI training while ensuring clinical relevance and regulatory compliance.
Training AI Models: Ensures accurate predictions, crucial for clinical applications.
Generalization: Helps AI work across diverse patient populations and imaging scenarios.
Regulatory Compliance: Aligns with standards from bodies like FDA and EMA.
Building Trust: Properly labeled datasets boost clinician confidence in AI systems.
Medical Imaging: CT scans, MRIs, X-rays (e.g., segmentation, classification).
Clinical Text: Notes, histories, discharge summaries (e.g., entity recognition, relation extraction).
Time-Series Data: ECGs, ICU monitors (e.g., event marking).
Genomic Data: Identifying mutations and biomarkers.
Multimodal Data: Linking imaging with text for comprehensive analysis.
HIPAA (US): Protects patient health information.
GDPR (EU): Governs data privacy and protection.
FDA/EMA Standards: Ensures AI systems are clinically validated.
Encord's annotation platform is seamlessly integrated with its data curation capabilities, allowing users to manage the labeling and quality assurance process more efficiently. This integration facilitates faster model iteration and improves the overall annotation cycle, especially for complex projects involving video and multimodal data.
Encord provides a comprehensive solution for data curation and annotation, allowing users to explore and organize their data efficiently. The platform integrates with cloud storage, such as S3, to streamline the process of sorting and filtering data, making it easy to manage large datasets across multiple projects.
Encord prioritizes security and data privacy by implementing strict protocols for data handling and storage. The platform offers options for on-premise deployment, ensuring that sensitive data remains within the client's environment while still benefiting from Encord's powerful annotation tools.
Encord provides a structured interface for managing annotation projects that includes multiple workflow stages such as data curation, annotation, review, and automation. This comprehensive workflow management ensures that all aspects of the annotation process are organized and efficient.
Encord enhances the annotation workflow by facilitating the easy input of new datasets and providing tools for efficient review processes. This is particularly beneficial for teams managing millions of frames, ensuring that data handling remains streamlined and effective.
Encord facilitates data curation by streamlining the annotation workflow, enabling researchers to efficiently clean and prepare data. The platform is designed to support teams as they scale, ensuring that data handling and annotation remain organized and effective.
Encord allows users to review annotated data easily through its intuitive interface. Users can track the progress of their annotation tasks, provide feedback, and make necessary corrections, thereby ensuring high-quality outputs for machine learning applications.
Yes, Encord can integrate with various annotation platforms to enhance data management. This allows users to streamline their workflows, making it easier to manage data and collaborate across teams without the hassle of redundant processes.
Yes, Encord allows users to upload large datasets directly onto the platform for annotation. Users can either utilize Encord's annotation services or manage their own workforce for accurate and efficient labeling of their data.
Yes, Encord allows users to mix and match between in-house annotators and its external annotation workforce. This flexibility enables clients to choose the best approach that fits their project needs.