Phi-3: Microsoft’s Mini Language Model is Capable of Running on Your Phone

Phi-3 is a family of open artificial intelligence models developed by Microsoft. These models have quickly gained popularity for being the most capable and cost-effective small language models (SLMs) available.
The Phi-3 models, including Phi-3-mini, are cost-effective and outperform models of the same size and even the next size across various benchmarks of language, reasoning, coding, and math. Let’s discuss how these models in detail.
What are Small Language Models (SLM)?
Small Language Models (SLMs) refer to scaled-down versions of large language models (LLMs) like OpenAI’s GPT, Meta’s LLama-3, Mistral 7B, etc. These models are designed to be more lightweight and efficient both in terms of computational resources for training and inference for simpler tasks and in their memory footprint.
The “small” in SLMs refers to the number of parameters that the model has. These models are typically trained on a large corpus of high-quality data and learn to predict the next work in a sentence, which allows them to generate coherent and contextually relevant sentences.
These lightweight AI models are typically used in scenarios where computational resources are limited or where real-time inference is necessary. They sacrifice some performance and capabilities compared to their larger counterparts but still provide valuable language understanding and generation capabilities.
SLMs find applications in various fields such as mobile devices, IoT devices, edge computing, and scenarios that have low-latency interactions. They allow for more widespread deployment of natural language processing capabilities in resource-constrained environments.
Microsoft's Phi-3 is a prime example of an SLM that pushes the boundaries of what's possible with these models, offering superior performance across various benchmarks while being cost-effective.
Phi-3: Introducing Microsoft’s SLM
Tech giant Microsoft launches Phi-3, a Small Language Model (SLM) designed to deliver great performance while remaining lightweight enough to run on resource-constrained devices like smartphones. With an impressive 3.8 billion parameters, Phi-3 represents a significant milestone in compact language modeling technology.
Prioritizing techniques in dataset curation and model architecture, Phi-3 achieves competitive performance comparable to much larger models like Mixtral 8x7B and GPT-3.5.

Performance Evaluation
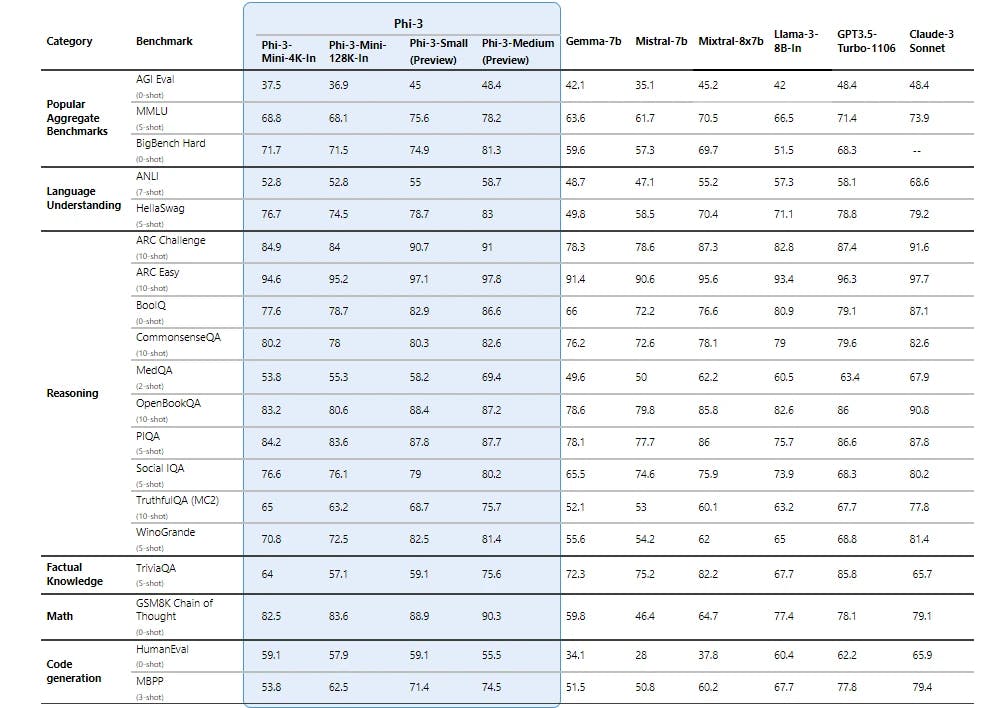
Phi-3's performance is assessed through rigorous evaluation against academic benchmarks and internal testing. Despite its smaller size, Phi-3 demonstrates impressive results, achieving 69% on the MMLU benchmark and 8.38 on the MT-bench metric.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
When comparing the performance of Phi-3 with GPT-3.5, a Large Language Model (LLM), it's important to consider the tasks at hand. For many language, reasoning, coding, and math benchmarks, Phi-3 models have been shown to outperform models of the same size and those of the next size up, including GPT-3.5.
Phi-3 Architecture
Phi-3 is a transformer decoder architecture with a default context length of 4K, ensuring efficient processing of input data while maintaining context awareness. Phi-3 also offers a long context version, Phi-3-mini-128K, extending context length to 128K for handling tasks requiring broader context comprehension. With 32 heads and 32 layers, Phi-3 balances model complexity with computational efficiency, making it suitable for deployment on mobile devices.
Microsoft Phi-3: Model Training Process
The model training process for Microsoft's Phi-3 has a comprehensive approach:
High-Quality Data Training
Phi-3 is trained using high-quality data curated from various sources, including heavily filtered web data and synthetic data. This meticulous data selection process ensures that the model receives diverse and informative input to enhance its language understanding and reasoning capabilities.
Extensive Post-training
Post-training procedures play a crucial role in refining Phi-3's performance and ensuring its adaptability to diverse tasks and scenarios. Through extensive post-training techniques, including supervised fine-tuning and direct preference optimization, Phi-3 undergoes iterative improvement to enhance its proficiency in tasks such as math, coding, reasoning, and conversation.
Reinforcement Learning from Human Feedback (RLHF)
Microsoft incorporates reinforcement learning from human feedback (RLHF) into Phi-3's training regime. This mechanism allows the model to learn from human interactions, adapting its responses based on real-world feedback. RLHF enables Phi-3 to continuously refine its language generation capabilities, ensuring more contextually appropriate and accurate responses over time.
Automated Testing
Phi-3's training process includes rigorous automated testing procedures to assess model performance and identify potential areas for improvement. Automated testing frameworks enable efficient evaluation of Phi-3's functionality across various linguistic tasks and domains, facilitating ongoing refinement and optimization.
Manual Red-teaming
In addition to automated testing, Phi-3 undergoes manual red-teaming, wherein human evaluators systematically analyze model behavior and performance. This manual assessment process provides valuable insights into Phi-3's strengths and weaknesses, guiding further training iterations and post-training adjustments to enhance overall model quality and reliability.
Advantages of Phi-3: SLM Vs. LLM
Small Language Model (SLM), offers several distinct advantages over traditional Large Language Models (LLMs), highlighting its suitability for a variety of applications and deployment scenarios.
- Resource Efficiency: SLMs like Phi-3 are designed to be more resource-efficient compared to LLMs. With its compact size and optimized architecture, Phi-3 consumes fewer computational resources during both training and inference, making it ideal for deployment on resource-constrained devices such as smartphones and IoT devices.
- Size and Flexibility: Phi-3-mini, a 3.8B language model, is available in two context-length variants—4K and 128K tokens1. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.
- Instruction-tuned: Phi-3 models are instruction-tuned, meaning that they’re trained to follow different types of instructions reflecting how people normally communicate.
- Scalability: SLMs like Phi-3 offer greater scalability compared to LLMs. Their reduced computational overhead allows for easier scaling across distributed systems and cloud environments, enabling seamless integration into large-scale applications with high throughput requirements.
- Optimized for Various Platforms: Phi-3 models have been optimized for ONNX Runtime with support for Windows DirectML along with cross-platform support across GPU, CPU, and even mobile hardware.
While LLMs will still be the gold standard for solving many types of complex tasks, SLMs like Phi-3 offer many of the same capabilities found in LLMs but are smaller in size and are trained on smaller amounts of data.
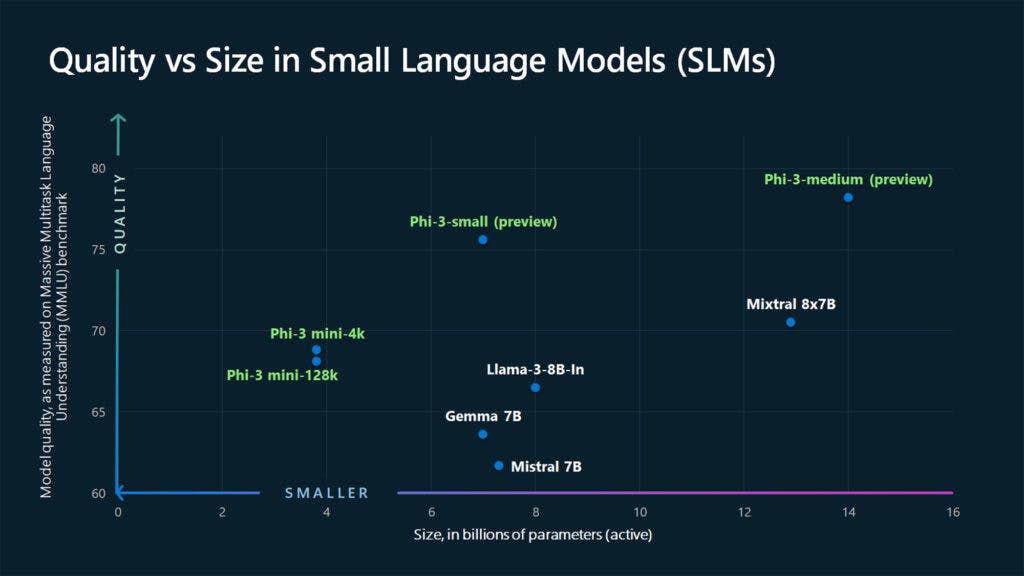
Quality Vs. Model Size Comparison
In the trade-off between model size and performance quality, Phi-3 claims remarkable efficiency and effectiveness compared to larger models.
Performance Parity
Despite its smaller size, Phi-3 achieves performance parity with larger LLMs such as Mixtral 8x7B and GPT-3.5. Through innovative training methodologies and dataset curation, Phi-3 delivers competitive results on benchmark tests and internal evaluations, demonstrating its ability to rival larger models in terms of language understanding and generation capabilities.
Optimized Quality
Phi-3 prioritizes dataset quality optimization within its constrained parameter space, leveraging advanced training techniques and data selection strategies to maximize performance. By focusing on the quality of data and training processes, Phi-3 achieves impressive results that are comparable to, if not surpass, those of larger LLMs.
Efficient Utilization
Phi-3 shows efficient utilization of model parameters, demonstrating that superior performance can be achieved without exponentially increasing model size. By striking a balance between model complexity and resource efficiency, Phi-3 sets a new standard for small-scale language modeling, offering a compelling alternative to larger, more computationally intensive models.
Quality of Phi-3 models’s performance on MMLU benchmark compared to other models of similar size
Client Success Case Study
Organizations like ITC, a leading business in India, are already using Phi-3 models to drive efficiency in their solutions. ITC's collaboration with Microsoft on the Krishi Mitra copilot, a farmer-facing app, showcases the practical impact of Phi-3 in agriculture. By integrating fine-tuned versions of Phi-3, ITC aims to improve efficiency while maintaining accuracy, ultimately enhancing the value proposition of their farmer-facing application.
Limitations of Phi-3
The limitations of Phi-3, despite its impressive capabilities, are primarily from its smaller size compared to larger Language Models (LLMs):
Limited Factual Knowledge
Due to its limited parameter space, Phi-3-mini may struggle with tasks that require extensive factual knowledge, as evidenced by lower performance on benchmarks like TriviaQA. The model's inability to store vast amounts of factual information poses a challenge for tasks reliant on deep factual understanding.
Language Restriction
Phi-3-mini primarily operates within the English language domain, which restricts its applicability in multilingual contexts. While efforts are underway to explore multilingual capabilities, such as with Phi-3-small and the inclusion of more multilingual data, extending language support remains an ongoing challenge.
Dependency on External Resources
To compensate for its capacity limitations, Phi-3-mini may rely on external resources, such as search engines, to augment its knowledge base for certain tasks. While this approach can alleviate some constraints, it introduces dependencies and may not always guarantee optimal performance.
Challenges in Responsible AI (RAI)
Like many LLMs, Phi-3 faces challenges related to responsible AI practices, including factual inaccuracies, biases, inappropriate content generation, and safety concerns. Despite diligent efforts in data curation, post-training refinement, and red-teaming, these challenges persist and require ongoing attention and mitigation strategies.
Phi-3 Availability
The first model in this family, Phi-3-mini, a 3.8B language model, is now available. It is available in two context-length variants—4K and 128K tokens.
The Phi-3-mini is available on Microsoft Azure AI Model Catalog, Hugging Face, and Ollama. It has been optimized for ONNX Runtime with support for Windows DirectML along with cross-platform support across graphics processing unit (GPU), CPU, and even mobile hardware.
In the coming weeks, additional models will be added to the Phi-3 family to offer customers even more flexibility across the quality-cost curve Phi-3-small (7B) and Phi-3-medium (14B) will be available in the Azure AI model catalog, and other model families shortly. It will also be available as an NVIDIA NIM microservice with a standard API interface that can be deployed anywhere.
Phi-3: Key Takeaways
- Microsoft's Phi-3 models are small language models (SLMs) designed for efficiency and performance, boasting 3.8 billion parameters and competitive results compared to larger models.
- Phi-3 utilizes high-quality curated data and advanced post-training techniques, including reinforcement learning from human feedback (RLHF), to refine its performance. Its transformer decoder architecture ensures efficiency and context awareness.
- Phi-3 offers resource efficiency, scalability, and flexibility, making it suitable for deployment on resource-constrained devices. Despite its smaller size, it achieves performance parity with larger models through dataset quality optimization and efficient parameter utilization.
- While Phi-3 demonstrates impressive capabilities, limitations include limited factual knowledge and language support. It is currently available in its first model, Phi-3-mini, with plans for additional models to be added, offering more options across the quality-cost curve.
Frequently asked questions
Microsoft Phi-3 is a family of open small language models developed by Microsoft, designed for specific tasks.
Phi-3 models outperform larger models across various benchmarks, including language, reasoning, coding, and math.
Yes, Phi-3 models are open-source and are available on platforms like Microsoft Azure AI Studio, Hugging Face, and Ollama.
Phi-3 models leverage high quality training data and optimizations like quantization to maximize their efficiency.
Phi-3 models are cost-effective, especially for scenarios with limited computing power, low latency requirements, or cost constraints.
The advantages of Phi-3 models include high performance, cost-effectiveness, and accessibility.
The current limitation of Phi-3 models is the lack of factual knowledge and they primarily support English, limiting their applicability in global, multilingual contexts.
Encord's annotation workflow is highly customizable, allowing users to define multiple stages within their projects. Users can easily drag in different stages relevant to their process, such as annotation and review stages, and can specify who is involved at each stage. This flexibility helps teams manage resources effectively while ensuring high-quality QA.
Encord's no-code interface allows users to customize their annotation workflows by defining stages and nodes that match the skill sets of their teams. This ensures that tasks can be effectively distributed among annotators, whether they're labeling or verifying pre-annotated data, optimizing the overall efficiency of the project.
Encord allows you to manage attributes in your annotations through its ontology feature. You can define attributes such as jersey number and secondary number, and even configure binary attributes to indicate whether a number is secondary or not. This flexibility helps streamline the annotation process for complex datasets.
Encord supports the generation and management of language data for VLA projects by allowing users to integrate heuristics and ground truth information. This helps in creating foundational models, although we recognize the challenges of ensuring the quality of language data through heuristic approaches.
Encord provides tools that enhance team collaboration, making it easier for teams to iterate and improve their models. By enabling seamless communication and workflow integration, teams can work together effectively, which is crucial for refining and enhancing machine learning models.
Encord enables users to integrate model-generated annotations alongside human annotations seamlessly within the same workflow. This functionality allows for efficient correction and auditing of annotators' performance, ensuring that tasks are understood and executed correctly.
Encord provides a flexible and customizable interface for setting up workflows and ontologies. Users can create basic structures and utilize them for efficient labeling, allowing for a streamlined annotation process tailored to specific project needs.
Encord offers pluggability for custom models, enabling users to swap in and out models conveniently during the annotation process. This flexibility allows teams to tailor the annotation experience to their specific machine learning problems.
Encord supports integration with multiple large language models, including OpenAI, Llama, and Mistral. This flexibility enables users to choose the best model based on their specific use cases in generative AI applications.