Top 10 Multimodal Use Cases

Product Manager at Encord
What is Multimodal AI?
Multimodal AI is a type of artificial intelligence, driven by machine learning, that can process and integrate multiple types of dataset, also called "modalities," to perform tasks or generate outputs. Unlike traditional AI systems (which is a unimodal system) that focus on a single type of data (like text, images, or audio), multimodal AI combines information from different sources to gain a deeper and more nuanced understanding of a given situation or problem. The Multimodal AI can process and understand multiple forms of data simultaneously.
For example, GPT-4 Vision (GPT-4V) from OpenAI, one of the most popular vision-language models, is a multimodal AI that analyzes, interprets, and generates responses considering both visual and textual inputs.

Reading the contents of an image using OpenAI GPT-4V (Source)
The common modalities that multimodal AI system use include:
- Text: Written language, such as articles, social media posts, or dialogue.
- Images: Visual data, including photographs, illustrations, or video frames.
- Audio: Sounds, including speech, music, or environmental noise.
- Video: A combination of images and audio, representing moving visuals.
- Sensors: Data from IoT devices, like temperature readings, GPS, or accelerometer data etc.
Combining different modalities enhances the system's ability to understand and interpret complex, real-world situations. Here are some key reasons why integrating multiple data modalities is important:
Richer Understanding and Contextual Awareness
Different modalities provide complementary information. For instance, combining images and text can give a more complete understanding of a scene or situation than either modality alone. This richer insight allows AI systems to make better-informed decisions.
Improved Accuracy and Robustness
Multiple modalities can cross-validate each other, reducing the likelihood of errors. For instance, if a system uses both video and audio data, discrepancies in one modality can be checked against the other, leading to more reliable outcomes. For example, if a camera feed is blurry, sensor data or audio input might still provide enough information for accurate analysis.
Enhanced User Interaction and Experience
Combining modalities enables more natural and intuitive user interactions. For example, a virtual assistant that can process both voice commands (audio) and gestures (visual) provides a more human-like interaction experience.
Broader Applicability and Versatility
A system that integrates multiple modalities can handle a wider range of tasks. For instance, in healthcare, a multimodal AI can analyze patient records (text), medical images (visual), and vitals (sensor data) to provide comprehensive diagnostics and treatment recommendations.
More Effective Decision-Making
Multimodal AI systems can make more informed decisions by considering all relevant data types. For example, in autonomous vehicles, combining visual data from cameras, depth data from LiDAR, and positional data from GPS results in safer and more effective navigation.
Enhanced Understanding of Complex Phenomena
Some problems require a multi-faceted approach to be understood fully. For example, in climate science, integrating satellite imagery (visual), temperature readings (sensor data), and weather reports (text) can provide a more accurate model of climate change impacts.
Ethical and Responsible AI Development
Relying on a single modality can introduce bias. For example, a facial recognition system based only on visual data might struggle with certain skin tones. Adding audio or other modalities can help balance this and create a more fair system.
Greater Accessibility
Multimodal AI can make technology more accessible by accommodating different user needs and preferences. For example, combining text-to-speech (audio) with visual cues can help users with disabilities interact more easily with technology.
The importance of combining different modalities in AI systems lies in their ability to provide richer, more accurate, and context-aware insights. This integration enhances user experiences, improves decision-making, fosters creativity, and broadens the applicability of AI across various domains. As AI continues to evolve, multimodal approaches will become increasingly central to developing intelligent, adaptive, and responsible systems.
How Multimodal AI works
Multimodal AI works by integrating and processing multiple types of data (such as text, images, audio, and sensor data) through a series of steps:
- Data Collection and Preprocessing: Different data types are collected and preprocessed to make them compatible with the AI system. This includes cleaning, normalizing, and extracting relevant features from each modality.
- Modality Specific Processing: Each data type is processed using specialized techniques. For example, text is analyzed using Natural Language Processing (NLP), while images are processed using Computer Vision.
- Data Fusion: The features from each modality are combined through early fusion (integrated at the start), late fusion (combined after individual processing), or hybrid fusion (a mix of both), creating a unified representation.
- Model Training: The machine learning model is trained to learn the relationships between the modalities, allowing it to create a comprehensive understanding of the data.
- Inference and Decision Making: The model makes predictions or decisions by integrating information from all modalities, leading to more accurate and context-aware outcomes.
- Output Generation: The system generates multimodal outputs, such as text descriptions, interactive responses, or creative content.
Components of Multimodal Modal
Multimodal AI models typically have three main components:
Input Module
The input module in a multimodal AI system is responsible for receiving and preprocessing raw data from different modalities (e.g., text, images, audio, video, sensor data) to prepare it for further processing by the unimodal encoder. This module plays a crucial role in ensuring that the diverse types of input data are properly aligned and standardized before they are passed through the system for feature extraction, fusion, and decision-making. The input module gathers data from multiple sources or sensors.
Fusion Module
The fusion module in a multimodal AI system integrates information from different data modalities, such as text, images, audio, or sensor data, into a unified, meaningful representation. By combining data from various sources, the fusion module enables the AI system to leverage the strengths of each modality, capturing more complex patterns and improving decision-making.
Output Module
The output module in a multimodal AI system is the final stage where the system generates predictions, classifications, or decisions based on the fused representation of the multimodal data. This module translates the learned knowledge from the model into usable and understandable outputs for the given task.

Components of multimodal AI (Source)
Top 10 Multimodal AI Use Cases
Discuss about different multimodal applications in different domains. Tentative applications are:
Sentiment Analysis

Multimodal Sentiment Analysis (Source)
Sentiment analysis is a technique used to determine the emotional tone or sentiment expressed in a piece of text, speech, or other forms of communication. When we talk about multimodal AI for sentiment analysis, we're referring to systems that analyze multiple types of data (i.e. text, facial expressions, and voice tone) to gain a more nuanced understanding of a user's sentiment. This approach provides a more comprehensive analysis compared to using just one modality.
Components of Multimodal Sentiment Analysis:
- Text Analysis: Determine the sentiment expressed in written or spoken text. Natural Language Processing (NLP) models such as sentiment classifiers that categorize text into sentiments like positive, negative, or neutral.
- Facial Expressions Analysis: Detects emotions based on facial expressions using computer vision. Convolutional Neural Network (CNN) or specialized models for emotion recognition analyze facial features to classify emotions such as happiness, sadness, anger, or surprise.
- Voice Tone Analysis: Analyze the tone of voice to infer emotions. Speech analysis models examine vocal attributes like pitch, tone, and volume to detect emotions. For example, a high-pitched, excited voice might indicate enthusiasm.
For example, a company wants to understand customer sentiment about its new product by analyzing feedback from multiple sources (i.e. social media posts, customer reviews, and survey responses). It gathers text reviews, social media comments, video reviews, and audio recordings related to the product. Categorize the sentiment of written feedback into positive, negative, or neutral. Apply facial recognition algorithms to video content to interpret the emotional tone conveyed through facial expressions. Analyze audio data to detect variations in tone and pitch, associating them with positive or negative sentiments. Combine the results from text analysis, facial expression analysis, and voice tone analysis to form a comprehensive understanding of overall customer sentiment.
Translation

Multimodal Machine Translation (Source)
Multimodal AI enhances machine translation by integrating visual context, such as images or videos, with text to improve the accuracy and contextual understanding of translations. Traditional machine translation systems rely solely on text to translate between languages, but often, the text alone lacks sufficient context, especially for words with multiple meanings or ambiguous phrases. By adding visual information to the translation process, multimodal AI can better understand the nuances of the original message and produce more accurate and contextually appropriate translations.
Key Components of Multimodal Translation
- Text Analysis: Analyze and translate the text content using traditional natural language processing (NLP) techniques. Machine translation models, such as Google Translate or neural machine translation (NMT) models, generate translations by analyzing the grammar, syntax, and meaning of the text.
- Visual Context (Images/Videos): Use images or video frames associated with the text to provide additional context for the translation. Computer vision models extract visual information and identify objects, scenes, or actions from images or videos. This visual data is then combined with the text to disambiguate meanings.
For example, The text "bat" can refer to a flying mammal or a sports equipment. In traditional text-based translation, the context can be unclear, making translation difficult. If the sentence "bat" is accompanied by an image of a baseball game, the system will understand that "bat" refers to the sports equipment rather than the animal. The multimodal AI will then understand it and produce desired translation.
Social Media Analytics
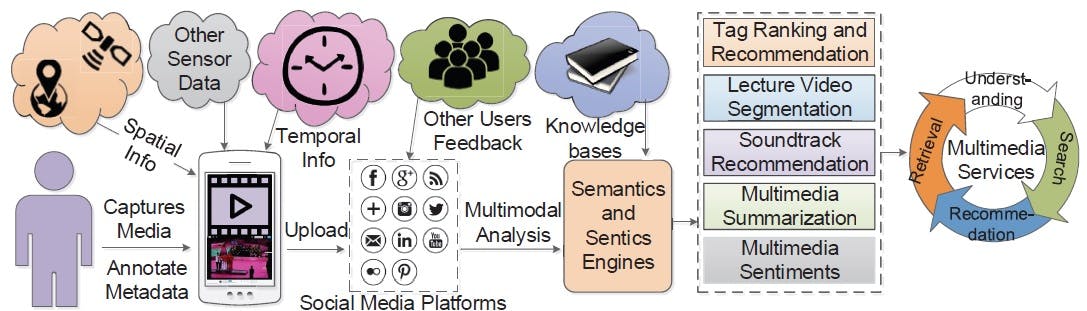
Multimodal Social Media Analysis (Source)
In this multimodal AI analyze text, images, videos, and user interactions to gain deeper insights into social media trends and public opinion.
Advanced Medical Imaging

Medical Multimodal Large Language Model (Med-MLLM) (Source)
Advanced Medical Imaging using multimodal AI combines different medical images, such as MRI, CT scans, and X-rays, with patient records (e.g., medical history, lab results, genetic data) to improve diagnostic accuracy and patient care. By integrating multiple data sources, AI models can create a more comprehensive view of the patient's condition, leading to more precise diagnoses, better treatment planning, and improved patient outcomes.
Key Components of Multimodal AI in Advanced Medical Imaging:
- Multiple Imaging Modalities: MRI provides detailed images of soft tissues, organs, and structures inside the body. CT Scans produce detailed cross-sectional images of bones, blood vessels, and soft tissues.X-rays offer a quick, non-invasive way to view bones and some internal organs. Ultrasound uses sound waves to capture images of organs and tissues.
- Patient Records and Clinical Data: AI systems integrate patient data, including medical history (e.g., past surgeries, chronic conditions) to create personalized diagnostic models. Blood tests, biomarkers, and other lab data can be combined with imaging data to enhance diagnostic accuracy.
For example, in the field of oncology, particularly for diagnosing and treating brain tumors, multimodal AI can combine multiple medical imaging techniques such as MRI, CT scans, PET scans, and patient health records to provide a more accurate and comprehensive diagnosis. By fusing data from these different sources, multimodal AI helps doctors make better-informed decisions about treatment plans, monitoring, and prognosis.
Disaster Response and Management

Multimodal Data Analytics for Pandemics and Disaster Management (Source)
In disaster response and management, multimodal AI system integrates various data sources (such as satellite imagery, social media data, and ground sensors) to improve disaster preparedness, response, and recovery efforts. By combining information from different modalities, AI systems can provide a comprehensive understanding of disaster situations, predict impacts, and support faster, more informed decision-making during crises.
Key Components of Multimodal AI in Disaster Response and Management
- Satellite Imagery: Capture real-time and historical visual data of large geographic areas to assess disaster impact. Computer vision algorithms analyze satellite images to detect changes in landscapes, infrastructure, and urban areas.
- Ground Sensors (IoT Devices): Provide real-time data on environmental conditions such as temperature, humidity, seismic activity, air quality, and water levels. Sensors deployed in key locations (e.g., near rivers, fault lines, or forests) transmit data to AI systems, which process the information to detect anomalies and trigger alerts.
For example, in Earthquake Disaster Response after the earthquake, high-resolution satellite images are captured to assess the affected areas, drones equipped with cameras and thermal sensors fly over the affected areas to gather real-time images and videos and images and sensors deployed in the region provide real-time data on aftershocks, potential landslides, or rising water levels. The system processes data from these multiple sources simultaneously. For example, satellite images and drone footage are fused with sensor data to generate a comprehensive damage map, and AI models rank areas based on severity and need for rescue efforts.
Emotion Recognition in Virtual Reality (VR)

VR Emotion Detection System (Source)
In this multimodal AI system enhances VR experiences by integrating visual, auditory, and physiological data to recognize and respond to user emotions. This real-time analysis allows the VR system to adapt its content dynamically, creating more immersive and personalized interactions. By understanding emotions, VR can adjust elements like game difficulty, learning environments, or therapeutic sessions to better suit the user’s needs.
Key Components of Multimodal AI in Emotion Recognition for VR:
- Visual Data (Facial Expressions and Body Language): Through headsets equipped with cameras or external sensors, VR systems capture facial muscle movements to interpret emotions such as happiness, anger, fear, or surprise. Eye movements, pupil dilation, and gaze direction are used to determine the user's focus, interest, or emotional engagement. Motion sensors track body movements, gestures, and posture, which can provide additional context to the user's emotional state.
- Auditory Data (Voice and Speech Analysis): AI models analyze the tone, pitch, volume, and speed of speech to detect emotions like excitement, frustration, or calmness. The words and phrases a user speaks during a VR session are processed to detect emotional cues. For example, positive or negative sentiments can be extracted from the language used.
- Physiological Data (Heart Rate, Skin Conductance, etc.): Sensors within the VR headset or external wearables monitor heart rate variability (HRV), which can indicate stress, anxiety, or relaxation. Measures how much the skin sweats, a reliable indicator of emotional arousal. This data is particularly useful in detecting fear, excitement, or stress.
For example, imagine a VR horror game where multimodal AI system is used to monitor the player's emotions, adapting the game experience based on real-time feedback. The player’s face is tracked through internal sensors in the VR headset, detecting fear-related expressions like widened eyes or a tense jaw. The player’s speech is analyzed for tremors or shakiness in their voice, indicating fear or stress. If the player speaks in short, tense sentences, the system may register increased anxiety. A rising heart rate and increased skin conductance suggest that the player is experiencing heightened fear or stress. If the AI detects that the player is feeling overly stressed or fearful, the system may decrease the intensity of the game. For example, it could reduce the frequency of enemy encounters or brighten the game environment to lessen the tension. If the player is calm and collected, the AI might increase the challenge by introducing more enemies, darker environments, or unexpected events to create a more thrilling experience.
Biometrics for Authentication

Multimodal Biometrics Authentication System(Source)
This multimodal AI system enhances security by integrating multiple biometric modalities such as face recognition, voice recognition, fingerprint, iris scans, and even behavioral biometrics (e.g., typing patterns or gait analysis). Instead of relying on a single mode of authentication (e.g., just a fingerprint), multimodal AI increases accuracy, reduces the risk of fraud, and offers a more robust solution for user authentication by validating multiple characteristics of an individual simultaneously.
Key Components of Multimodal Biometrics for Authentication:
- Facial Recognition: AI systems analyze the unique structure of a user's face, including features like the distance between the eyes, the shape of the cheekbones, jawline, and more. Advanced systems use depth sensors to capture 3D images of the face, adding another layer of accuracy, making it difficult to spoof using photos or masks.
- Voice Recognition: The system identifies the user by analyzing the unique characteristics of their voice, including pitch, tone, and the way they pronounce words.
- Fingerprint Scanning: Fingerprints have unique ridge patterns that are used to authenticate the identity of an individual.
- Iris or Retina Scanning: The iris (colored part of the eye) has complex patterns that remain stable throughout a person’s life, and AI can capture and analyze these patterns for authentication.
For example, in a secure access to a banking app multimodal biometric authentication is used to ensure that only authorized users can access the system by analyzing face, voice and fingerprint data. The AI system combines all biometric inputs (i.e. face, voice, fingerprint); if all match, the user is granted access to the app. If one modality is unclear (e.g., the user’s voice due to background noise), the other modalities compensate to ensure the correct user is authenticated.
Human-Computer Interaction (HCI)

Multimodal interface system in driving simulator (Source)
In HCI the multimodal AI enhances interactions between humans and machines more intuitively, efficiently, and seamlessly. Multimodal AI achieves this by integrating various input types, such as speech, gestures, facial expressions, and touch, allowing systems to interpret user intent more accurately and deliver a richer, more natural user experience.
Key Components of Multimodal AI in HCI
- Speech Recognition: Multimodal AI allows users to interact with machines using natural language commands.
- Gesture Recognition: AI systems track and interpret hand movements and body gestures to understand commands or responses.
- Facial Expression Recognition: AI can analyze facial expressions to infer the user’s emotional state and adapt the interaction accordingly.
- Eye Tracking: AI tracks eye movement to detect where a user is focusing their attention. This helps systems respond to what the user is looking at.
- Touch and Haptic Feedback: The system processes inputs from touchscreens or devices that provide haptic feedback (e.g., vibrations) to make interactions more tactile.
- Context Awareness: Multimodal AI enhances context awareness by combining various inputs to better understand the situation and environment.
For example, a learner driver is using a multimodal driving simulator to practice real-world driving skills. The learner driver approaches a complex intersection where they need to make a quick decision. They say, “Show the closest gas station,” and the system uses speech recognition to display nearby options. As they focus on the road, the eye-tracking system confirms that their attention is on the intersection, and no warnings are triggered. The driver swipes their hand to adjust the virtual dashboard controls for air conditioning. The system also tracks their facial expressions for signs of stress and, if needed, could provide encouraging audio cues to ease anxiety.
Sports Analytics
In Sports Analytics, multimodal AI plays a crucial role by integrating data from various sources such as video footage, player statistics, and sensor data to offer a comprehensive understanding of player performance, team strategies, and game outcomes. By combining these diverse inputs, multimodal AI can provide insights that go beyond traditional statistical analysis, helping coaches, teams, and analysts make informed decisions.
Key Components of Multimodal AI in Sports Analytics:
- Video Footage Analysis: AI processes video feeds from games, matches, or training sessions to track player movements, ball trajectories, and team formations in real time.
- Player Statistics: Multimodal AI incorporates historical and real-time player statistics (e.g., points scored, pass accuracy, distance covered) to enhance performance evaluation.
- Sensor Data (Wearables and GPS): Wearable sensors or GPS devices provide detailed data on a player’s physical condition, including heart rate, acceleration, and energy expenditure.
- Body Pose Estimation: AI uses computer vision techniques to analyze player postures and movements. This helps in detecting specific actions like jumping, shooting, or tackling.
- Facial Expression Recognition: AI analyzes facial expressions to understand a player’s emotional state, which can affect performance.
For example, in a tennis match analysis, a tennis coach wants to evaluate a player’s technique and stamina during a match. Video analysis tracks the player’s movements across the court, focusing on the speed of their footwork and the accuracy of their shots. Body pose estimation examines the player’s posture during serves, backhands, and forehands, comparing it to optimal biomechanics for reducing injury risk. Wearable sensors track heart rate and energy levels, identifying when the player starts to fatigue. The multimodal AI reveals that the player’s backhand accuracy drops when their heart rate exceeds a certain threshold. The coach uses this information to recommend breathing exercises during matches to manage the player’s exertion and maintain performance.
Environmental Monitoring

Multimodal Environmental Sensing (Source)
In environmental monitoring, multimodal AI integrates diverse data sources like satellite imagery, drone footage, ground sensors, and environmental reports to track, analyze, and manage changes in the environment. This holistic approach helps in detecting patterns, predicting environmental risks, and implementing sustainable solutions for managing natural resources and addressing environmental challenges such as pollution, deforestation, or climate change.
Key Components of Multimodal AI in Environmental Monitoring:
- Satellite Imagery: Satellites provide large-scale data on land use, vegetation, weather patterns, and urbanization over time.
- Drone Footage: Drones capture high-resolution images and videos from the ground or difficult-to-reach areas to provide detailed, real-time data.
- Ground Sensors: Ground-based sensors measure specific environmental parameters such as air quality, temperature, humidity, soil moisture, and water quality in real-time.
- Environmental Reports and Historical Data: AI incorporates scientific research, government reports, and historical environmental data to analyze long-term environmental changes.
- Weather and Climate Models: AI integrates weather models with real-time sensor data to predict future environmental conditions, such as droughts, floods, and heatwaves.
- Remote Sensing Data: Remote sensing technologies use radar, LiDAR, or infrared imaging to detect changes in the environment that may not be visible to the naked eye.
For example, in water resource management and pollution detection an environmental organization wants to monitor a river system for signs of water pollution and changes in water quality. Ground-based water sensors measure pH levels, temperature, turbidity, and pollutant concentrations in the river. Drone footage is used to detect visible signs of pollution, such as oil slicks or waste dumping. Satellite images track changes in water flow and vegetation around the river, which may indicate potential pollution sources or drought conditions. Historical data on previous pollution events and water management policies are analyzed to understand trends in water quality. The multimodal AI system detects rising pollutant levels in a section of the river near an industrial area. Drone footage confirms visible oil slicks, and historical reports suggest this area has been a frequent source of pollution. The system alerts local authorities to investigate and take corrective actions.
Robotics

Bio-Inspired Robotics (Source)
In robotics, multimodal AI improves the ability of robots to perceive, interpret, and interact with their environment by integrating dataset from multiple sensory modalities such as cameras (visual data), microphones (audio data), tactile sensors (touch feedback), and sometimes even radar, LiDAR, and other specialized sensors. This multimodal approach enables robots to perform complex tasks in dynamic environments, making them more adaptive, intelligent, and responsive to changes.
Key Components of Multimodal AI in Robotics:
- Visual Data (Cameras): Cameras provide robots with visual perception, allowing them to recognize objects, track movements, and navigate environments.
- Audio Data (Microphones): Microphones allow robots to understand and respond to speech, recognize sound patterns, and identify audio cues.
- Tactile Sensors (Touch Feedback): Tactile sensors give robots the ability to feel and measure pressure or texture, enabling them to handle objects with care and interact with delicate materials.
- Proprioception Sensors (Internal State Feedback): These sensors provide the robot with feedback about its own body, including joint positions, motor performance, and balance.
- LiDAR and Radar Sensors: LiDAR (Light Detection and Ranging) and radar sensors help robots detect objects in their surroundings by mapping distances and surfaces.
- Environmental Sensors (Temperature, Humidity, etc.): Robots can use environmental sensors to perceive changes in their surroundings, such as temperature, humidity, or light levels.
For example, in a healthcare facility social robots are deployed to interact with patients, provide companionship, and assist with basic tasks like reminding patients to take medications. Microphones and speech recognition systems allow the robots to engage in conversations, understand patient requests, and provide verbal reminders. Cameras and facial recognition software help the robots identify patients, detect facial expressions, and assess emotional states. Tactile sensors provide haptic feedback, allowing the robot to offer a reassuring touch or assist patients with mobility, such as helping them stand up. The robot, equipped with a chatbot powered by ChatGPT, becomes an empathetic assistant, not only following commands but also responding to emotional cues, providing a more human-like interaction with patients, and supporting healthcare staff by handling repetitive tasks.
Automated Drug Discovery
Multimodal AI in automated drug discovery enhances the process by integrating diverse dataset types such as chemical structure images, process data, and experimental results. By combining these various modalities, multimodal AI helps in accelerating drug development, improving the accuracy of predictions, and generating new insights in identifying potential drug candidates.
Key Components in Multimodal AI for Drug Discovery:
- Chemical Structure Images (Molecular Representation): Images of chemical structures (such as molecular graphs or 3D conformations) are used to understand the molecular makeup of potential drug compounds.
- Process Data (Lab Procedures, Chemical Reactions, Production Steps): This includes data from laboratory procedures, chemical reactions, and various steps in the drug synthesis process.
- Experimental Results (Biological and Pharmacological Data): Data from biological assays, clinical trials, and pharmacological testing is critical for understanding how a drug behaves in biological systems.
For example, consider a pharmaceutical company searching for new drugs that can selectively kill cancer cells without harming healthy tissues. The company uses 3D molecular structures from public databases like the Protein Data Bank (PDB) and generates structural images for millions of compounds that could potentially inhibit proteins involved in cancer growth. The company’s chemists provide data on how each compound can be synthesized, including reaction times, chemical reagents, and environmental conditions (e.g., temperature, pH). This helps AI optimize synthesis routes for drug candidates that are difficult to produce. The company runs biological assays to test these compounds in cancer cell lines. The multimodal AI system identifies several promising drug candidates that have favorable structural properties (from molecular images), are easy to synthesize (from process data), and show strong anti-cancer effects in laboratory tests (from experimental data). These candidates are moved to clinical trials faster than traditional methods would allow.
Real Estate
Multimodal AI in real estate uses a combination of housing images, pricing information, and purchase data to provide comprehensive insights and improve decision-making for buyers, sellers, and real estate professionals. By integrating these diverse dataset types, multimodal AI enhances property evaluation, market analysis, and personalized recommendations, making the real estate process more efficient and informed.
Key Components in Multimodal AI for Real Estate:
- Housing Images (Visual Data): High-quality images or videos of properties are analyzed to evaluate key features such as architecture, condition, amenities, and overall aesthetics.
- Pricing Information (Market Data): Data on current and historical property prices, trends in neighborhood pricing, and comparisons with similar homes help determine a property’s market value.
- Purchase Data (Transactional Data): Historical data on property purchases, including buyer demographics, transaction history, financing methods, and market demand, help provide insights into the buying behavior and investment potential.
For example, consider a scenario where a real estate company wants to offer instant home valuations to potential sellers, providing them with a fair market price and suggesting improvements that could increase their property value. The platform uses high-resolution images of homes submitted by sellers. The AI model evaluates these images for key property features, such as the condition of the kitchen, the number of bedrooms, and curb appeal. The artificial intelligence system integrates local market data, including recent sales of comparable homes, neighborhood trends, and price fluctuations over time. This allows for a dynamic estimation of the property’s current value. The platform references purchase data to understand buyer behavior in the area. For example, it analyzes whether buyers in the region are more likely to purchase homes with modern amenities, or whether they prioritize affordability. The multimodal AI system combines insights from housing images, local pricing data, and purchase history to generate a home valuation report for the seller. The report includes an estimated market price for the home, suggested improvements (e.g., upgrading the kitchen or landscaping) based on property images, which could increase the home’s value and a comparison with recent sales of similar homes in the neighborhood. The homeowner receives an instant valuation report, helping them decide whether to list their property at the suggested price or make improvements before selling.
Future of Multimodal AI
Multimodal AI represents the next frontier in artificial intelligence by enabling systems to process and integrate information from diverse modalities, such as text, images, audio, video, and even sensory data. As artificial intelligence advances, multimodal systems will become increasingly sophisticated, driving innovation across various industries and transforming the way we interact with technology. Below are key trends and potential impacts of multimodal AI in the future.
Enhanced Human-Computer Interaction
- Natural language understanding: Multimodal AI will enable more intuitive and natural interactions with computers, allowing us to communicate using both speech and gestures.
- Personalized experiences: AI systems can tailor experiences based on our preferences, emotions, and context, leading to more engaging and relevant interactions.
Advanced Content Creation and Analysis
- Generative AI: Multimodal AI can create new forms of content, such as music, art, and stories, by combining different modalities. There are various AI tools available, such as AI detectors and humanizers, that can enhance AI-generated content. These tools help refine the output, ensuring it reads more naturally and resonates better with human audiences. Or an AI image generator to create high-quality images for a number of different applications.
- Content analysis: AI can analyze vast amounts of multimedia data to extract insights, trends, and patterns, aiding in fields like marketing, research, and education.
Revolutionizing Healthcare
- Medical image analysis: AI can assist in diagnosing diseases and monitoring patient health by analyzing medical images like X-rays, MRIs, and CT scans.
- Personalized medicine: Multimodal AI can help develop personalized treatment plans based on a patient's genetic makeup, medical history, and lifestyle.
Autonomous Systems
- Enhanced perception: Multimodal AI can provide autonomous systems with a more comprehensive understanding of their environment, improving their decision-making and safety.
- Human-robot collaboration: AI-powered robots can work alongside humans in various industries, enhancing efficiency and productivity.
New Applications and Innovations
- Virtual and augmented reality: Multimodal AI can create more immersive and interactive experiences in virtual and augmented reality.
- Smart cities: AI can help optimize urban infrastructure and services by analyzing data from various sources, such as sensors, cameras, and social media.
While the potential benefits of multimodal AI are immense, there are also challenges to address:
- Data privacy and ethics: The use of large amounts of personal data raises concerns about privacy and ethical implications.
- Technical limitations: Developing and training multimodal AI models requires significant computational resources and expertise.
- Bias and fairness: Ensuring that multimodal AI systems are fair and unbiased is crucial to avoid perpetuating harmful stereotypes.
As researchers and developers continue to address these challenges, we can expect multimodal AI to play a central role in shaping the future of technology and society.
Frequently asked questions
Encord provides robust capabilities for managing and annotating multimodal data, allowing users to work with various data forms including DICOM images and surgical videos. The platform helps clients efficiently curate their data, identifying key moments in lengthy videos that can enhance AI training and improve overall data insights.
Encord provides a comprehensive solution for multimodal annotation, allowing users to handle various file types, including images, PDFs, and videos. This flexibility enables ML and data ops teams to create custom workflows tailored to their specific needs, improving efficiency in the annotation process.
Encord offers robust multimodal capabilities that allow users to integrate various types of data, such as video, audio, and documents. This flexibility is beneficial for a wide range of use cases, enabling teams to combine different modalities seamlessly for enhanced analysis and insights.
Encord can assist in analyzing brand archetypes by providing tools that facilitate natural language analysis of brand communications across various platforms. This enables teams to identify historical voice usage and develop prompts for future communications to maintain brand consistency.
Encord provides robust tools designed to handle various types of multimodal data, allowing users to effectively annotate and manage diverse datasets. This feature is particularly beneficial for teams transitioning from traditional OCR methods to more advanced, multimodal approaches.
Encord is equipped to handle multimodal data projects, allowing users to annotate and manage data from various sources seamlessly. This capability is essential for organizations that require a comprehensive approach to data handling across different modalities.
Encord supports multimodal data creation by enabling users to annotate and manage various types of data, including audio, text, and vision. This integration allows teams to leverage multiple data formats for enhanced model training and performance prediction.
Encord's anchor feature is designed to support multiple use cases by providing a unified framework for annotation. This allows teams to streamline their workflows across different modalities, ensuring efficient data curation, annotation, and model evaluation.
Yes, Encord is designed to support a variety of complex modalities and use cases. Our platform's flexibility and advanced features allow organizations to explore and implement innovative solutions tailored to their specific needs.
Encord can centralize and manage a variety of data types, including documents, images, video, and audio, which is essential for organizations looking to leverage multi-modal use cases in their machine learning initiatives.