Guide to Panoptic Segmentation

The term "panoptic" is derived from two words: "pan," meaning "all," and "optic," signifying "vision." Panoptic segmentation, a pivotal concept in computer vision, offers a comprehensive approach to image segmentation. It stands out by simultaneously segmenting objects and classifying them. Thus, panoptic segmentation can be interpreted as viewing everything within a given visual field. This technique is a hybrid, merging semantic and instance segmentation strengths.
Introduced by Alexander Kirillov and his team in 2018, panoptic segmentation aims to provide a holistic view of image segmentation rather than relying on separate methodologies. A key distinction of panoptic segmentation is its ability to classify objects into two broad categories: "things" and "stuff." In computer vision, "things" refer to countable objects with a defined geometry, such as cars or animals. On the other hand, "stuff" pertains to objects identified primarily by texture and material, like the sky or roads.
Understanding Image Segmentation
What is Image Segmentation?
Image segmentation, a pivotal concept in computer vision, involves partitioning a digital image into multiple segments, often called image regions or objects. This process transforms an image into a more meaningful and easier-to-analyze representation. Image segmentation assigns labels to pixels so those with the same label share specific characteristics. This technique is instrumental in locating objects and boundaries within images. For instance, in medical imaging, segmentation can create 3D reconstructions from CT scans using geometry reconstruction algorithms.
Types of Image Segmentation
Semantic Segmentation: This approach identifies the class each pixel belongs to. For instance, in an image with multiple people, all pixels associated with persons will have the same class label, while the background pixels will be classified differently.
Instance Segmentation: Every pixel is identified for its specific belonging instance of the object. It's about detecting distinct objects of interest in the image. For example, in an image with multiple people, each person would be segmented as a unique object.
Panoptic Segmentation: A combination of semantic and instance segmentation, panoptic segmentation identifies the class each pixel belongs to while distinguishing between different instances of the same class.

What is Panoptic Segmentation?
The term "panoptic" derives from encompassing everything visible in a single view. In computer vision, panoptic segmentation offers a unified approach to segmentation, seamlessly merging the capabilities of both instance and semantic segmentation.
Panoptic segmentation is not just a mere combination of its counterparts but a sophisticated technique that classifies every pixel in an image based on its class label while identifying the specific instance of that class it belongs to. For instance, in an image with multiple cars, panoptic segmentation would identify each car and distinguish between them, providing a unique instance ID for each.
This technique stands out from other segmentation tasks in its comprehensive nature. While semantic segmentation assigns pixels to their respective classes without distinguishing between individual instances, and instance segmentation identifies distinct objects without necessarily classifying every pixel, panoptic segmentation does both.
Every pixel in an image processed using panoptic segmentation would have two associated values: a label indicating its class and an instance number. Pixels that belong to "stuff" regions, which are harder to quantify (like the sky or pavement), might have an instance number reflecting that categorization or none at all. In contrast, pixels belonging to "things" (countable objects like cars or people) would have unique instance IDs.
This advanced segmentation technique has potential applications in various fields, including medical imaging, autonomous vehicles, and digital image processing. Its ability to provide a detailed understanding of images makes it a valuable tool in the evolving landscape of computer vision.
Working Mechanism
Panoptic segmentation has emerged as a groundbreaking technique in computer vision. It's a hybrid approach that beautifully marries the strengths of semantic and instance segmentation. While semantic segmentation classifies each pixel into a category, instance segmentation identifies individual object instances. On the other hand, panoptic segmentation does both: it classifies every pixel and assigns a unique instance ID to distinguishable objects.
One of the state-of-the-art methods in panoptic segmentation is the Efficient Panoptic Segmentation (EfficientPS) method. This technique leverages deep learning and neural networks to achieve high-quality segmentation results. EfficientPS is designed to be both efficient in terms of computational resources and effective in terms of segmentation quality. It employs feature pyramid networks and convolutional layers to process input images and produce segmentation masks. The method also utilizes the COCO dataset for training and validation, ensuring that the models are exposed to diverse images and scenarios.
The beauty of panoptic segmentation, especially methods like EfficientPS, lies in their ability to provide a detailed, pixel-level understanding of images. This is invaluable in real-world applications such as autonomous vehicles, where understanding the category (road, pedestrian, vehicle) and the individual instances (specific cars or people) is crucial for safe navigation.
Key Components of Panoptic Segmentation
Imagine a painter who not only recognizes every object in a scene but also meticulously colors within the lines, ensuring each detail stands out. That's the magic of panoptic segmentation in the world of computer vision. By understanding its key components, we can grasp how it effectively delineates and classifies every pixel in an image, ensuring both coherence and distinction.
Fully Convolutional Network (FCN) and Mask R-CNN
Fully Convolutional Networks (FCN) have emerged as a pivotal component in the panoptic segmentation. FCN's strength lies in its ability to process images of varying sizes and produce correspondingly-sized outputs. This network captures patterns from uncountable objects, such as the sky or roads, by classifying each pixel into a semantic label. It's designed to operate end-to-end, from pixel to pixel, offering a detailed, spatially dense prediction.
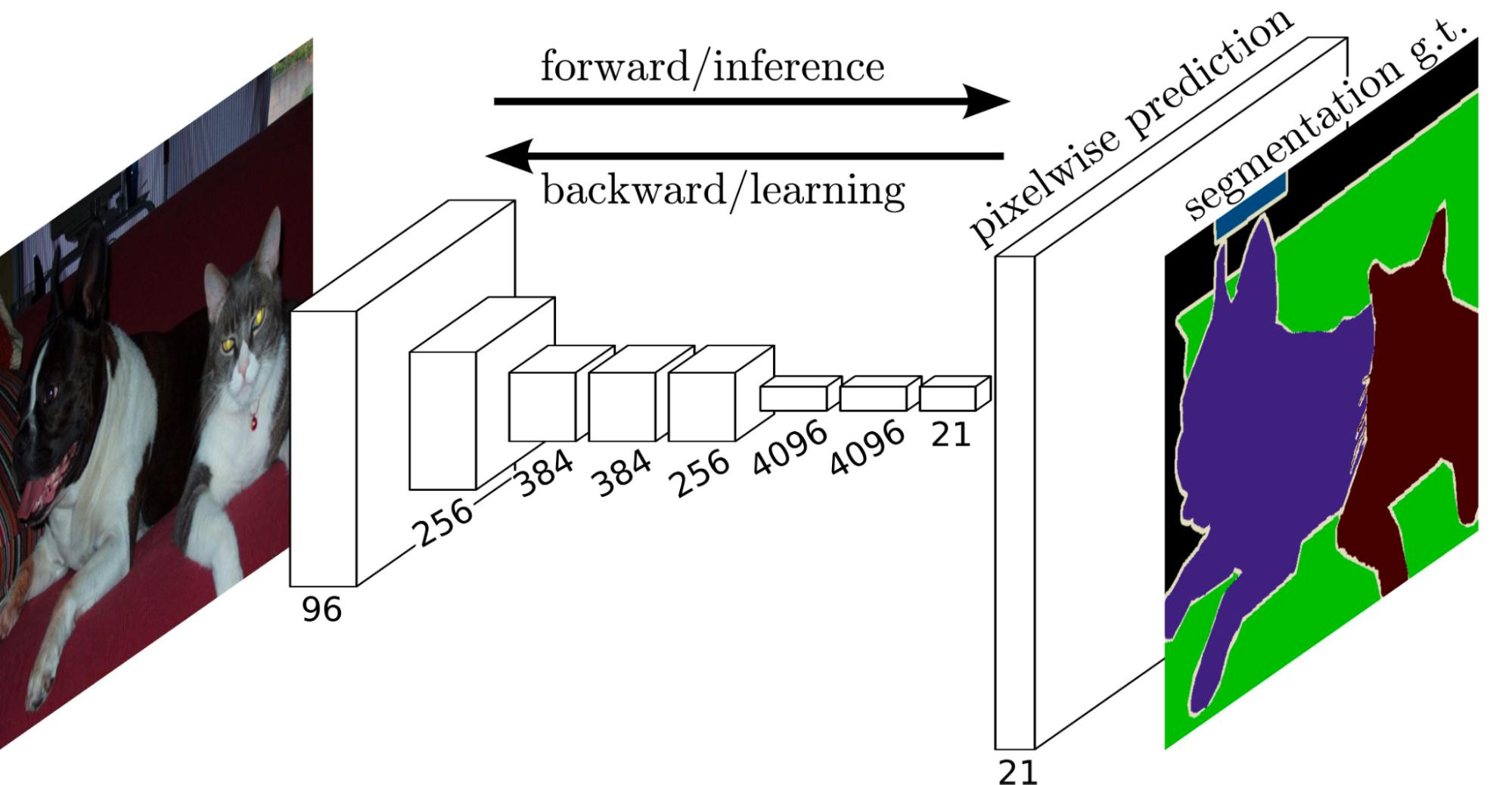
Fully Convolutional Neural Networks
Conversely, Mask R-CNN, an extension of the Faster R-CNN, plays a crucial role in recognizing countable objects. While Faster R-CNN is adept at bounding box recognition, Mask R-CNN adds a parallel branch for predicting an object mask. This means that for every detected object, Mask R-CNN identifies it and generates a high-quality segmentation mask for each instance. This dual functionality makes it an invaluable tool for tasks requiring object detection and pixel-level segmentation, such as identifying and distinguishing between individual cars in a traffic scene.
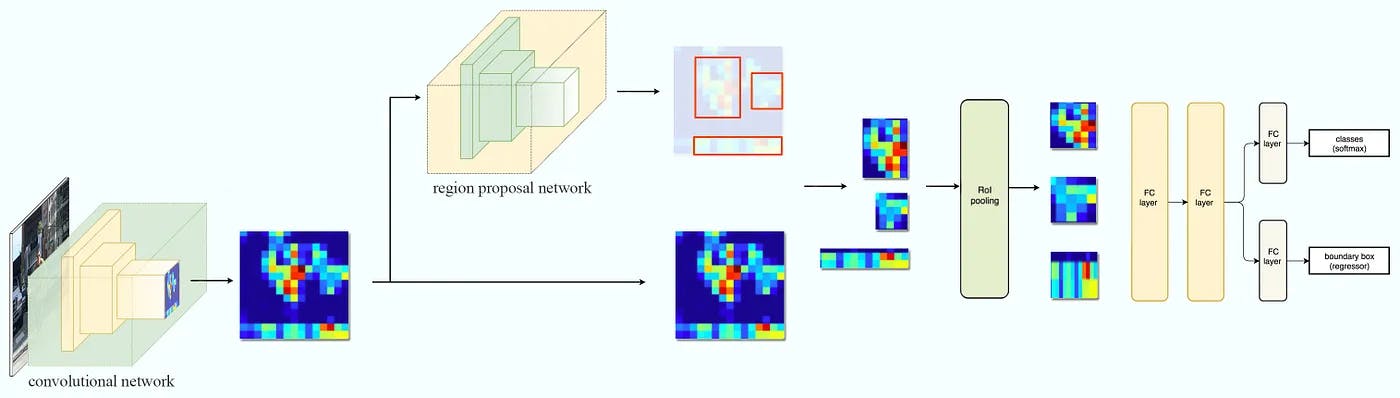
FCN and Mask R-CNN form the backbone of panoptic segmentation, ensuring that every pixel in an image is accurately classified and, if applicable, associated with a unique instance ID.
EfficientPS Architecture
One of the foundational elements of this architecture is Efficient Panoptic Segmentation (EfficientPS). EfficientNet is a model designed to systematically scale the network depth, width, and resolution. This ensures the model achieves optimal performance across various tasks without consuming excessive computational resources.
A significant aspect of the EfficientPS architecture is the two-way Feature Pyramid Network (FPN). The FPN is adept at handling different scales in an image, making it invaluable for tasks that require understanding both the broader scene and the finer details. This two-way FPN ensures that features from both low-level and high-level layers of the network are utilized, providing a rich set of features for the segmentation task.
Fusing outputs from semantic and instance segmentation is another hallmark of the EfficientPS architecture. While semantic segmentation provides a class label for each pixel, instance segmentation identifies individual object instances. EfficientPS combines these outputs, ensuring that every pixel in an image is classified and associated with a unique instance ID if it belongs to a countable object.
What makes EfficientPS truly special is its loss function. The architecture employs a compound loss that combines the losses from semantic and instance segmentation tasks. This ensures the model is trained to perform optimally on both tasks simultaneously.
The EfficientPS architecture, integrating EfficientNet, two-way FPN, and a compound loss function, set a new benchmark in panoptic segmentation, delivering state-of-the-art results across various datasets.
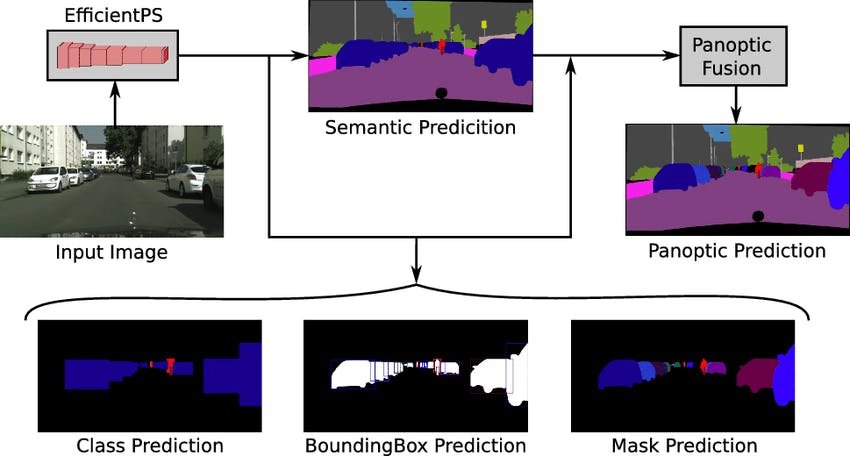
Practical Applications of Panoptic Segmentation
Medical Imaging
Panoptic segmentation has made significant strides in medical imaging. Panoptic segmentation offers a detailed and comprehensive view of medical images by leveraging the power of both semantic and instance segmentation. This is particularly beneficial in tumor cell detection, where the model identifies the presence of tumor cells and differentiates between individual cells. Such precision is crucial for accurate diagnoses, enabling medical professionals to devise more effective treatment plans. Using datasets like COCO and Cityscapes, combined with deep learning algorithms, ensures that the segmentation models are trained on high-quality data, further enhancing their accuracy in medical diagnoses.
Autonomous Vehicles
The world of autonomous vehicles is another domain where panoptic segmentation proves its mettle. For self-driving cars, understanding the environment is paramount. Panoptic segmentation aids in this by providing a pixel-level understanding of the surroundings. It plays a pivotal role in distance-to-object estimation, ensuring the vehicle can make informed decisions in real-time. By distinguishing between countable objects (like pedestrians and other vehicles) and uncountable objects (like roads and skies), panoptic segmentation ensures safer navigation for autonomous vehicles.
Digital Image Processing
Modern smartphone cameras are a marvel of technology, and panoptic segmentation enhances their capabilities. Features like portrait mode, bokeh mode, and auto-focus leverage the power of image segmentation to differentiate between the subject and the background. This allows for the creation of professional-quality photos with depth effects. The fusion of semantic and instance segmentation ensures that the camera can identify and focus on the subject while blurring out the background, resulting in stunning photographs.
Research in Panoptic Segmentation
With the integration of advanced algorithms and neural networks, the research community has been pushing the boundaries of what's possible in computer vision. One notable model that has emerged as a leader in this space is the "OneFormer (ConvNeXt-L, single-scale, 512x1024), which has set new benchmarks, especially on the Cityscapes val dataset.
Important Papers
2023 has seen the publication of several influential papers that have shaped the trajectory of panoptic segmentation.
- Panoptic Feature Pyramid Networks: This paper delves into a minimally extended version of Mask R-CNN with FPN, referred to as Panoptic FPN. The study showcases how this model is a robust and accurate baseline for semantic and instance segmentation tasks.
- Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation: The work introduces Panoptic-DeepLab, a system designed for panoptic segmentation. The paper emphasizes its simplicity, strength, and speed, aiming to establish a solid baseline for bottom-up methods.
- OneFormer: This model has emerged as a leader in panoptic segmentation in 2023, setting new benchmarks, especially on the Cityscapes val dataset.
Panoptic Segmentation: Key Takeaways
Panoptic segmentation has emerged as a pivotal technique in computer vision, offering a comprehensive approach to image segmentation. This method seamlessly integrates the strengths of semantic and instance segmentation, providing a holistic view of images. Let's recap the significant insights and applications of panoptic segmentation:
- Unified Approach: Panoptic segmentation is a hybrid technique that combines semantic and instance segmentation best. It assigns every pixel in an image a class label while distinguishing between individual object instances. This unified approach ensures every pixel has a clear, singular label, eliminating ambiguities.
- Diverse Applications: The applications of panoptic segmentation are vast and varied. In the medical field, it aids in precise tumor cell detection, enhancing the accuracy of diagnoses. For autonomous vehicles, it plays a crucial role in distance-to-object estimation, ensuring safer navigation. Additionally, panoptic segmentation enhances smartphone camera capabilities in digital image processing, enabling features like portrait mode and auto-focus.
- Innovative Research: The field has witnessed rapid advancements, with state-of-the-art models like EfficientPS pushing the boundaries of what's possible. These models leverage architectures like EfficientNet and Feature Pyramid Networks to deliver high-quality segmentation results efficiently.
- Datasets and Benchmarks: Research in panoptic segmentation is supported by many datasets, with Cityscapes being notable. The benchmark scores on these datasets provide a clear metric to gauge the performance of various models, guiding further research and development.
- Future Trajectory: The future of panoptic segmentation looks promising. With continuous research and integration of deep learning techniques, we can expect even more accurate and efficient models. These advancements will further expand the applications of panoptic segmentation, from healthcare to autonomous driving and beyond.
Panoptic segmentation stands at the intersection of technology and innovation, offering solutions to complex computer vision challenges. As research progresses and technology evolves, its potential applications and impact on various industries will only grow.

Frequently asked questions
Panoptic segmentation can be best visualized in a crowded street scene. Imagine a photo capturing cars, pedestrians, buildings, trees, and the road. With panoptic segmentation, not only will the AI system identify and categorize each object type (like car, pedestrian, or tree), but it will also individually segment each instance of these objects. So, every single car in the traffic jam or each person in a group of pedestrians will be distinctly outlined and labeled, ensuring no overlap between them.
Panoptic segmentation is classified into two main categories:
Semantic Segmentation: This involves classifying each pixel in an image into a set category, like road, building, or sky. It doesn't differentiate between individual instances of these categories. For instance, all cars would be painted with the same car label without distinguishing between them.
Instance Segmentation: This goes a step further by identifying each individual object instance in the image. So, if there are three cars, each car would be separately outlined and labeled.
Panoptic segmentation combines these two classifications. It provides a comprehensive segmentation that labels every pixel with a category and differentiates between individual object instances within those categories.
The panoptic segmentation task uniquely combines semantic and instance segmentation strengths. While semantic segmentation classifies each pixel in categories like stuff classes (e.g., sky, road) or different objects, instance segmentation identifies individual object instances. Panoptic segmentation achieves both, ensuring every pixel in an image is assigned a category while distinguishing between individual instances.
EfficientPS stands out because its architecture integrates EfficientNet and a two-way Feature Pyramid Network (FPN). This combination and a specialized encoder allow the model to efficiently process images at multiple scales. Its unique loss function, which combines semantic and instance segmentation losses, ensures high panoptic quality. The model's efficiency and compatibility with frameworks like PyTorch and its ResNet backbone have made it a leading method on platforms like GitHub.
The panoptic segmentation task provides a comprehensive understanding of the surroundings of autonomous vehicles. It not only classifies every pixel (e.g., distinguishing between stuff classes like roads or trees) but also identifies different objects, such as individual pedestrians. This detailed scene comprehension is crucial for use cases like distance-to-object estimation and decision-making, ensuring safer navigation.
Achieving high panoptic quality is challenging. Differentiating between overlapping objects, handling similar-looking instances, and the real-time processing demands can be daunting. Moreover, the ground truth annotations required for training are often resource-intensive to create. Tools and APIs that facilitate the creation of panoptic segmentation datasets are essential in addressing these challenges.
Several panoptic segmentation datasets are pivotal for training. The COCO dataset is widely recognized, but Cityscapes, focused on urban scenes, is especially crucial for autonomous driving applications. Mapillary Vistas and ADE20K are also significant. Regarding tools, PyTorch is a popular framework, and ResNet is a commonly used backbone. For evaluation, metrics like IoU (Intersection over Union) are essential, and platforms like GitHub serve as repositories for state-of-the-art models and tools.
Encord is equipped to handle panoptic segmentation, allowing users to annotate data more effectively. The platform supports the export of masks and labels in panoptic COCO format, addressing the specific needs of projects that require detailed and nuanced segmentation.