Web Agents and LLMs: How AI Agents Navigate the Web and Process Information

Imagine having a digital assistant that could browse the web, gather information, and complete tasks for you, all while you focus on more important things. That's the power of web agents, a new breed of AI systems, changing how we interact with the internet.
Web agents use large language models (LLMs) – the reasoning layer required to understand and navigate the unstructured data space of the web. The LLMs allow agents to read, comprehend, and even write text, making them incredibly versatile.
But why are web agents suddenly becoming so important?
In today's data-driven world, businesses are drowning in online information. Web agents offer a lifeline by automating research, data extraction, and content creation. They can sift through mountains of data in seconds, freeing up valuable time and resources.
This blog post will dive deeper into web agents and LLMs. We'll explore how they work, the incredible benefits they offer, and how businesses can implement them to gain a competitive edge. Get ready to discover the future of online automation!
Understanding How Web Agents & LLMs Work
Core Components of a Web Agent
Web agents are like specialized computer programs designed to automatically explore and interact with the internet. They are meant to perform tasks that normally require human interaction, such as browsing web pages, collecting data, and making decisions based on the information they find.
Think of a web agent as having several key functions:
- Crawling involves systematically browsing the web, following links, and exploring different pages. It's similar to how a search engine indexes the web, but web agents usually have a more specific goal in mind.
- Parsing: When a web agent lands on a page, it must make sense of the content. Parsing involves analyzing the code and structure of the page to identify different elements, such as text, images, and links.
- Extracting: The web agent can extract the necessary information once the page is parsed. This could be anything from product prices on an e-commerce site to comments on a social media platform.
By combining these functions, web agents can collect and process information from the web with minimal human intervention. When you add LLMs to the mix, web agents become even more powerful as they enable web agents to reason about the information they collect, make more complex decisions, and even converse with users.
Role of LLMs in Interpreting Web Data
LLMs can comprehend and reorganize raw textual information into structured formats, such as knowledge graphs or databases, by leveraging extensive training on diverse datasets. This process involves identifying the text's entities, relationships, and hierarchies, enabling more efficient information retrieval and analysis.
The accuracy of LLMs in interpreting web data is heavily dependent on the quality and labeling of the training data. High-quality, labeled datasets provide the necessary context and examples for LLMs to learn the nuances of language and the relationships between different pieces of information.
Well-annotated data ensures that models can generalize from training examples to real-world applications, improving performance in tasks such as information extraction and content summarization. Conversely, poor-quality or unlabeled data can result in models that misinterpret information or generate inaccurate outputs.
Interaction Between Web Agents and LLMs in Real-Time
Web agents and LLMs interact dynamically to process and interpret web data in real time. Web agents continuously collect fresh data from various online sources and feed this information into LLMs.
This real-time data ingestion allows LLMs to stay updated with the latest information, enhancing their ability to make accurate predictions and decisions. For example, the WebRL framework trains LLM-based web agents through self-evolving online interactions, enabling them to effectively adapt to new data and tasks.
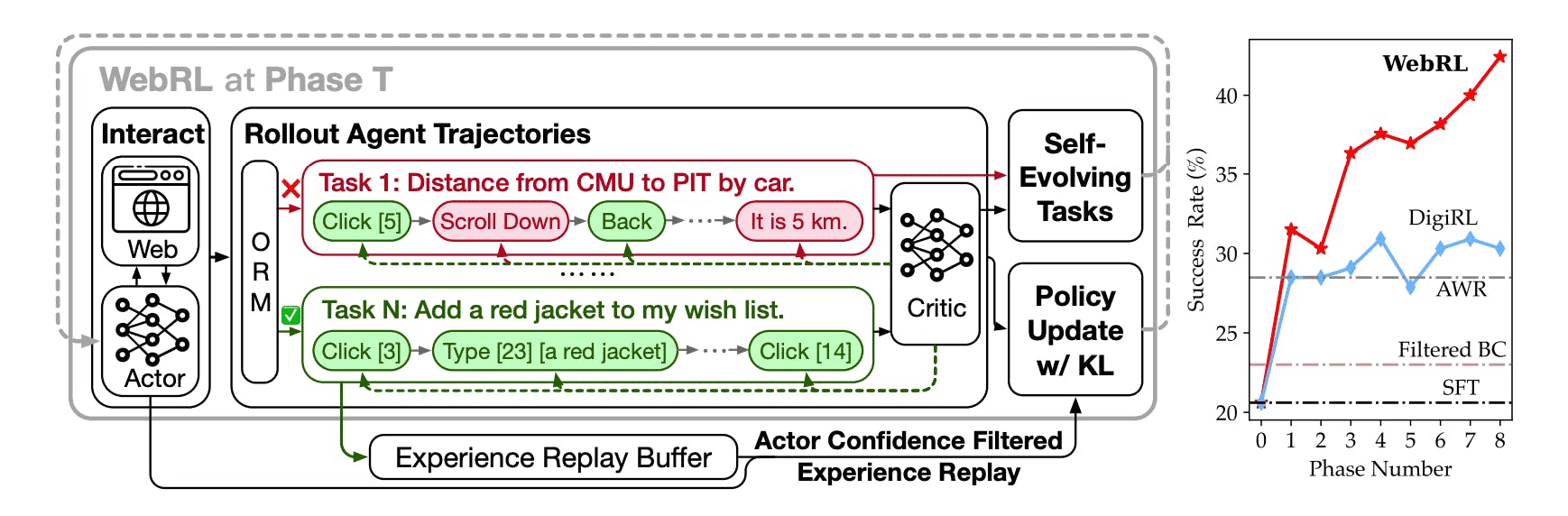
Figure: An overview of the WebRL Framework (Source)
The continuous feedback loop between web agents and LLMs facilitates the refinement of model predictions over time. As web agents gather new data and LLMs process this information, the models learn from any discrepancies between their predictions and actual outcomes.
This iterative learning process allows LLMs to adjust their internal representations and improve their understanding of complex web data. This leads to more accurate and reliable outputs in various applications, including content generation, recommendation systems, and automated customer service.
Why Web Agents & LLMs Matter for Businesses
In the evolving digital landscape, businesses increasingly leverage web agents to enhance operations and maintain a competitive edge. Their ability to aggregate, process, and analyze data in real-time empowers organizations to make smarter decisions and unlock new efficiencies.
Enhancing Data-Driven Decision-Making
As autonomous software programs, web agents can systematically crawl and extract real-time data from various online sources. This capability enables businesses to gain timely market insights, monitor competitor activities, and track emerging industry trends.
By integrating this data into their decision-making processes, companies can make informed choices that align with current market dynamics.
For instance, a business might deploy web agents to monitor social media platforms for customer sentiment analysis, allowing for swift adjustments to marketing strategies based on public perception. Such real-time data collection and analysis are crucial for staying responsive and proactive in a competitive market.
Improving Operational Efficiency
LLMs streamline operations by automating customer support, content moderation, and sentiment analysis tasks. This reduces the need for manual oversight while maintaining high accuracy levels.
By leveraging better-prepared data, businesses can significantly lower operational costs while increasing team productivity. For example, customer support teams can focus on resolving complex issues while LLM-powered chatbots handle common queries.
Competitive Advantage Through Continuous Learning
Combining web agents and LLMs facilitates systems that continuously learn and adapt to new data. This dynamic interaction allows businesses to refine their models, improving predictions and decision-making accuracy.
Such adaptability is essential for long-term competitiveness, enabling companies to swiftly respond to changing market conditions and customer preferences.
By investing in these technologies, businesses position themselves at the forefront of innovation, capable of leveraging AI-driven insights to drive growth and efficiency. Continuous learning ensures the systems evolve alongside the business, providing sustained value over time.
Incorporating web agents and LLMs into business operations is not merely a technological upgrade but a strategic move towards enhanced decision-making, operational efficiency, and sustained competitive advantage.
Building Web Agents: A Step-by-Step Architecture Guide
The web agent architecture draws inspiration from the impressive work presented in the WebVoyager paper by He et al. (2024). Their research introduces a groundbreaking approach to building end-to-end web agents powered by LLMs.
By achieving a 59.1% task success rate across diverse websites, significantly outperforming previous methods, their architecture demonstrates the effectiveness of combining visual and textual understanding in web automation.
Understanding the Core Components
Let's explore how to build a web agent that can navigate websites like a human, breaking down each critical component and its significance.
1. The Browser Environment
INITIALIZE browser with fixed dimensions SET viewport size to consistent resolution CONFIGURE automated browser settings
Significance: Like giving the agent a reliable pair of eyes. The consistent viewport ensures the agent "sees" web pages the same way each time, making its visual understanding more reliable.
2. Observation System
FUNCTION capture_web_state:
TAKE a screenshot of the current page
IDENTIFY interactive elements (buttons, links, inputs)
MARK elements with numerical labels
RETURN marked screenshot and element detailsSignificance: Acts as the agent's sensory system. The marked elements help the agent understand what it can interact with, similar to how humans visually identify clickable elements on a page.
3. Action Framework
DEFINE possible actions:
- CLICK(element_id)
- TYPE(element_id, text)
- SCROLL(direction)
- WAIT(duration)
- BACK()
- SEARCH()
- ANSWER(result)Significance: Provides the agent's "physical" capabilities - what it can do on a webpage, like giving it hands to interact with the web interface.
4. Decision-Making System
FUNCTION decide_next_action:
INPUT: current_screenshot, element_list, task_description
USE multimodal LLM to:
ANALYZE visual and textual information
REASON about next best action
RETURN thought_process and action_commandSignificance: The brain of the operation. The LLM combines visual understanding with task requirements to decide what to do next.
5. Execution Loop
WHILE task not complete:
GET current web state
DECIDE next action
IF action is ANSWER:
RETURN result
EXECUTE action
HANDLE any errors
UPDATE context historySignificance: Orchestrates the entire process, maintaining a continuous cycle of observation, decision, and action - similar to how humans navigate websites.
Why This Architecture Works
The potential of web agent architecture lies in its human-like approach to web navigation.
Combining visual understanding with text processing navigates websites much like a person would - scanning the page, identifying interactive elements, and making informed decisions about what to click or type. This natural interaction style makes it particularly effective at handling real-world websites.
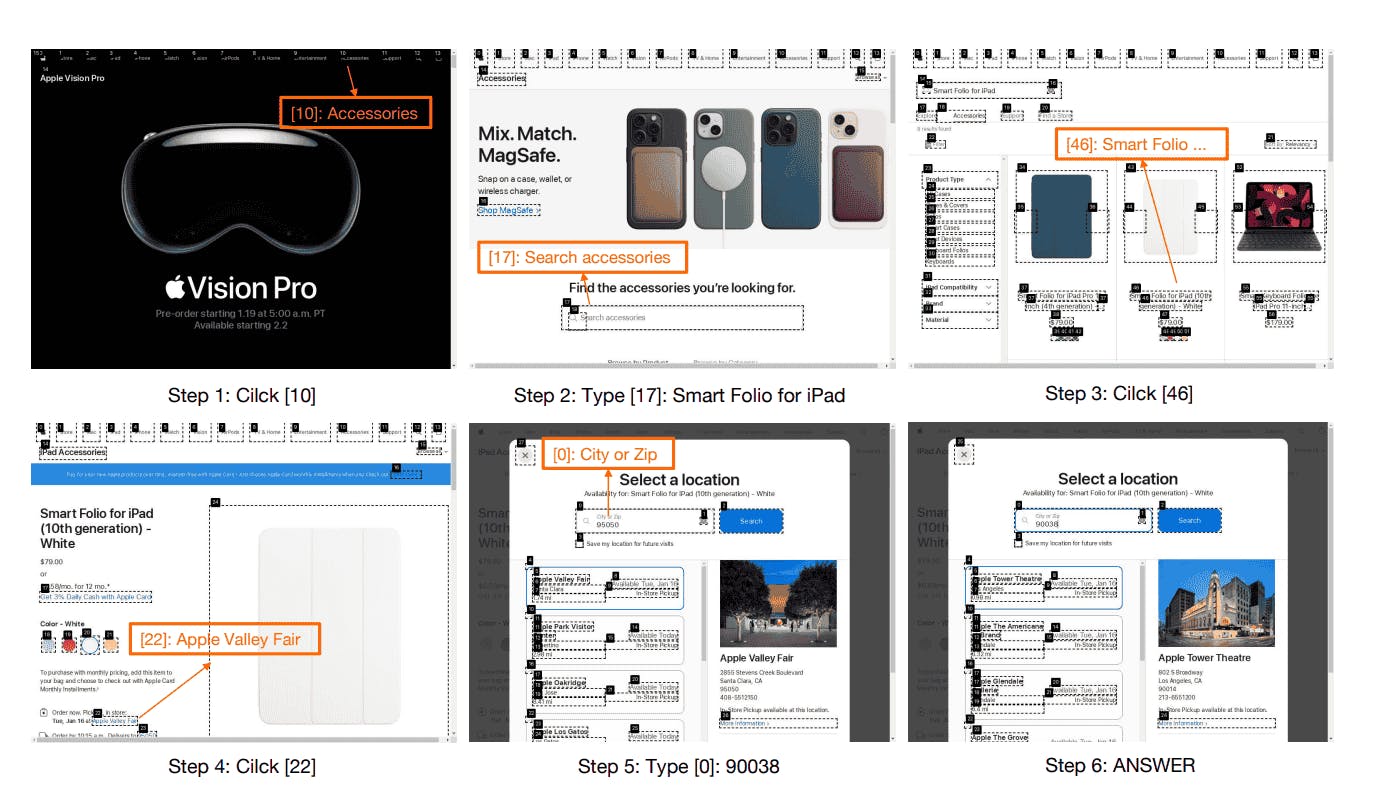
Figure: Example workflow of Web Agents using images (Source)
Natural Interaction
- Mimics human web browsing behavior
- Combines visual and textual understanding
- It makes decisions based on what it actually "sees"
Robustness
- Can handle dynamic web content
- Adapts to different website layouts
- Recovers from errors and unexpected states
Extensibility
- Easy to add new capabilities
- It can be enhanced with more advanced models
- Adaptable to different types of web tasks
This architecture provides a foundation for building capable web agents, balancing the power of AI with structured web automation. As models and tools evolve, we can expect these agents to become even more sophisticated and reliable.
Integrating Encord into Your Workflow
Encord is a comprehensive data development platform designed to seamlessly integrate into your existing workflows, enhancing the efficiency and effectiveness of training data preparation for Web Agents and LLMs.
Accuracy
Encord's platform offers best-in-class labeling tools that enable precise and consistent annotations, ensuring your training data is accurately labeled. This precision directly contributes to the improved decision-making capabilities of your models.
Contextuality
With support for multimodal annotation, Encord allows you to label data across various formats—including images, videos, audio, and text—adding depth and relevance to your datasets. This comprehensive approach ensures that your models are trained with context-rich data, enhancing their performance in real-world applications.

Scalability
Encord's platform is built to scale efficiently with increasing data volumes, accommodating the growth needs of businesses. Encord ensures seamless integration and management of large datasets by leveraging cloud infrastructure without compromising performance. This scalability is supported by best practices outlined in Encord's documentation, enabling organizations to expand their AI initiatives confidently.
Integrating Encord into your workflow allows you to streamline and expedite training data preparation, ensuring it meets the highest accuracy, contextuality, and scalability standards. This integration simplifies the data preparation process and enhances the overall performance of your Web Agents and LLMs, positioning your business for success in the competitive AI landscape.
Conclusion
Integrating web agents and Large Language Models (LLMs) has become a pivotal strategy for businesses aiming to thrive in today's data-driven economy. This synergy enables the efficient extraction, interpretation, and utilization of real-time web data, providing organizations with actionable insights and a competitive edge.
Encord's platform plays a crucial role in this ecosystem by streamlining the training data preparation process. It ensures that data is accurate, contextually rich, and scalable, which is essential for developing robust LLM-driven solutions. Encord accelerates AI development cycles and enhances model performance by simplifying data management, curation, and annotation.
To fully leverage the potential of advanced web agents and LLM integrations, we encourage you to explore Encord's offerings. Take the next step in optimizing your AI initiatives:
Streamline Your Data Preparation: Learn more about how Encord's tools can enhance your data pipeline efficiency.
By embracing these solutions, your organization can harness the full power of AI, driving innovation and maintaining a competitive advantage in the rapidly evolving digital landscape.
Frequently asked questions
Web agents are autonomous software programs designed to perform tasks on the internet that typically require human interaction. They can browse websites, collect data, make decisions, and interact with users. When combined with large language models (LLMs), they become even more powerful, enabling advanced reasoning and decision-making.
Web agents perform three key functions:
Crawling: Systematically exploring web pages to gather data.
Parsing: Analyzing web page content and structure to identify elements like text and images.
Extracting: Collecting and processing relevant information, such as prices, reviews, or trends.
Web agents collect fresh data, feeding it to LLMs for interpretation. LLMs analyze this data, make decisions, and guide the agents' next actions. This continuous feedback loop ensures up-to-date insights and improves decision-making over time.
WebRL is a framework that trains LLM-powered web agents through online interactions. It allows agents to adapt dynamically to new tasks and data, enhancing their real-world application and reliability.
Encord is designed to replace or integrate with existing internally built systems and vendor solutions that organizations may already have in place. This integration helps streamline the machine learning pipeline by consolidating data collection, storage, cleaning, and annotation into one platform.
Yes, Encord is designed to integrate seamlessly with various data management systems, allowing teams to leverage their existing infrastructure. This integration capability ensures that data flows smoothly between systems, enhancing the overall efficiency of the annotation process.
Editor agents in Encord allow users to integrate external custom models directly into the annotation flow. This means that while annotators are working, they can utilize models for tracking and segmentation, enhancing the annotation experience and improving overall accuracy.
Agent nodes in Encord's workflows enable programmatic actions, such as pre-labeling data using a model before human annotation. This feature allows for customized routing based on the outcomes of the pre-labeling process, enhancing the efficiency of the annotation workflow.
Encord's annotation platform is specifically designed for edge deployments, which is crucial for manufacturing environments without internet connectivity. This allows for real-time processing and decision-making directly on the production floor.
Custom metadata plays a crucial role in filtering and analyzing click paths within Encord. By leveraging this metadata, users can investigate patterns of failure in web agents, helping to identify areas for improvement and optimization.
Encord supports data curation specifically for web agents by enabling users to manage and refine HTML data efficiently. This helps facilitate better performance of web agents by ensuring that they operate on high-quality, relevant data.
Encord has a strong background in managing NLP and LLM-based annotation projects. With a focus on agent evaluation and leveraging multiple vendor partnerships, Encord provides a robust platform for handling complex data labeling needs.
Yes, Encord is designed to support various annotation strategies, allowing teams to leverage both in-house resources and third-party contractors. This flexibility enables users to scale their annotation efforts as needed.
Yes, Encord allows users to set up and manage ontologies as part of the annotation workflow. This feature helps in organizing the labeling process by defining the relationships and categories of the data being annotated.