Automate your AI data pipelines with Agents
Efficiently integrate humans, SOTA models, and your own models into data workflows to reduce the time taken to achieve high-quality multimodal datasets at scale.
Fast-track AI development with better data
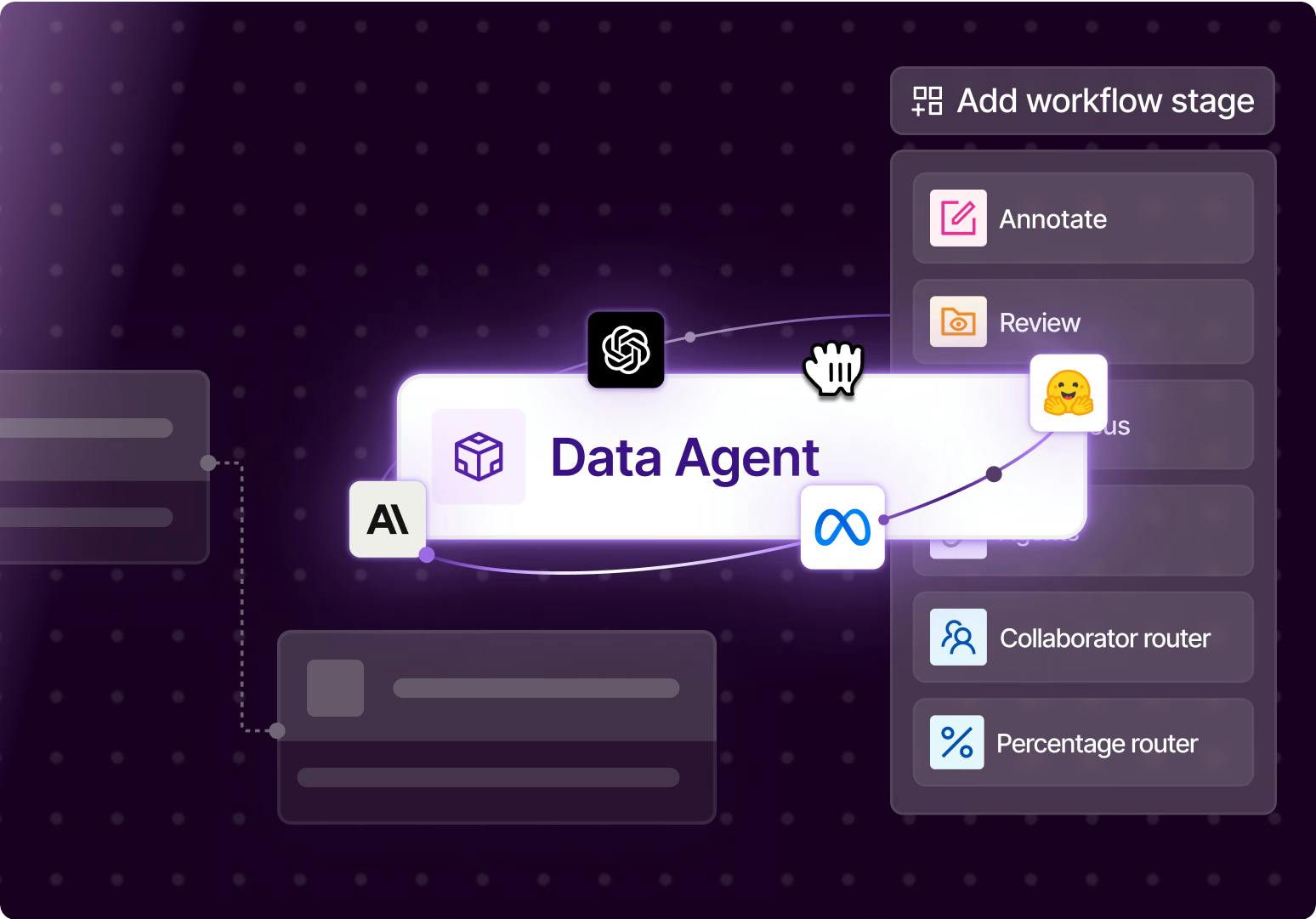
Integrate the right AI model to automate data workflows
Flexibly integrate your own model or SOTA foundation models to enable accurate data preparation, fast. Automate any data task such as pre-labeling, routing by reasoning, evaluation and more.
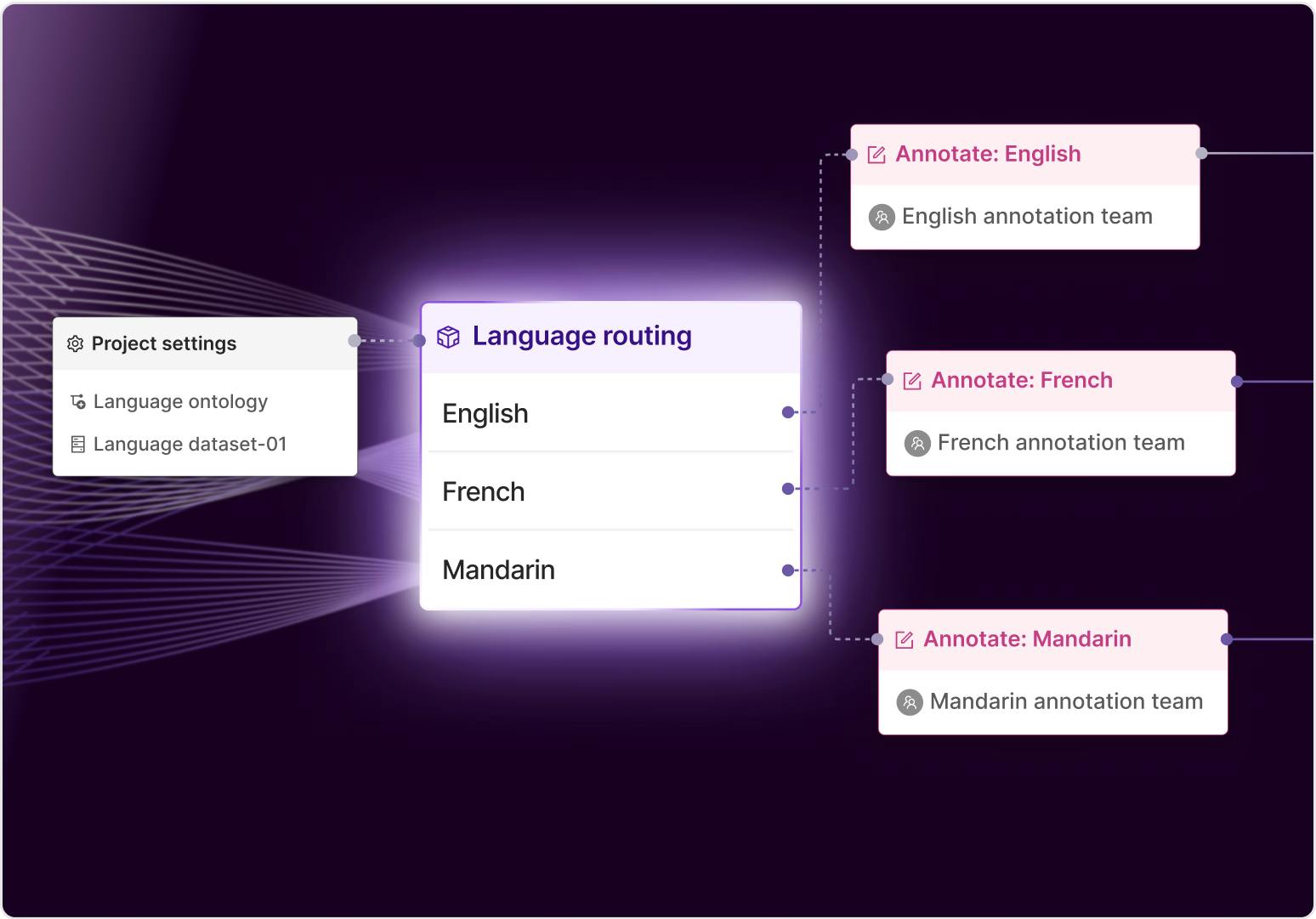
Scale data pipelines without scaling headcount
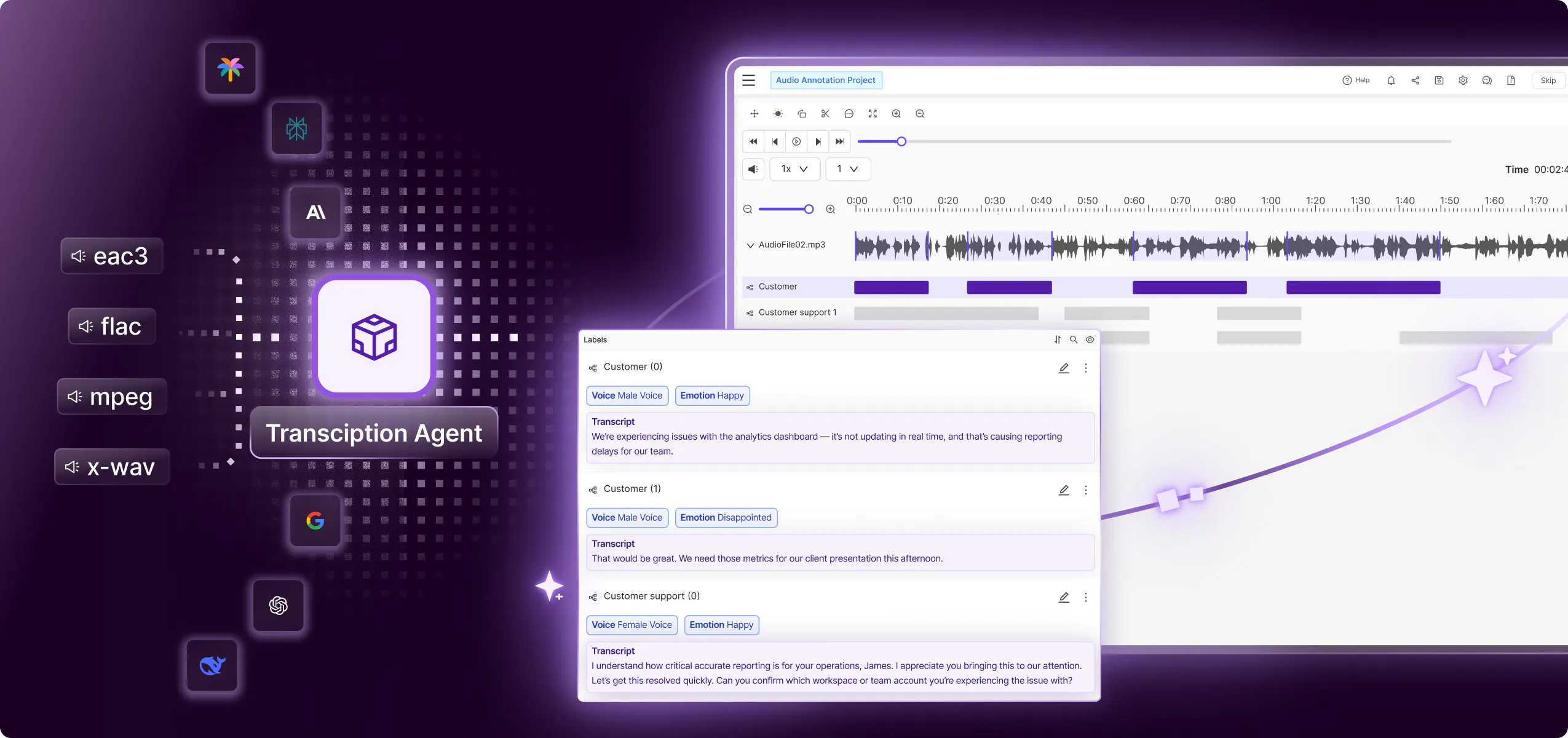
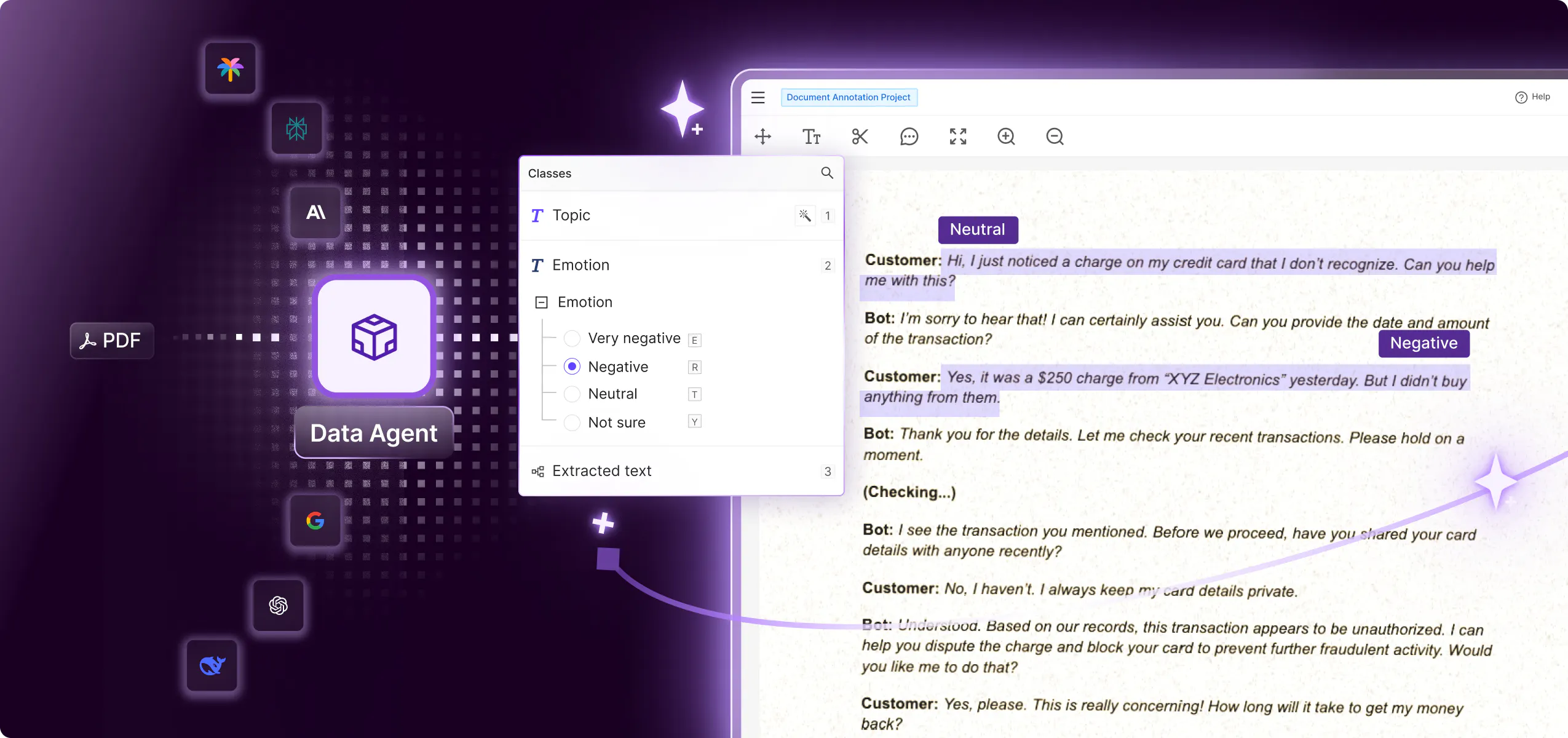
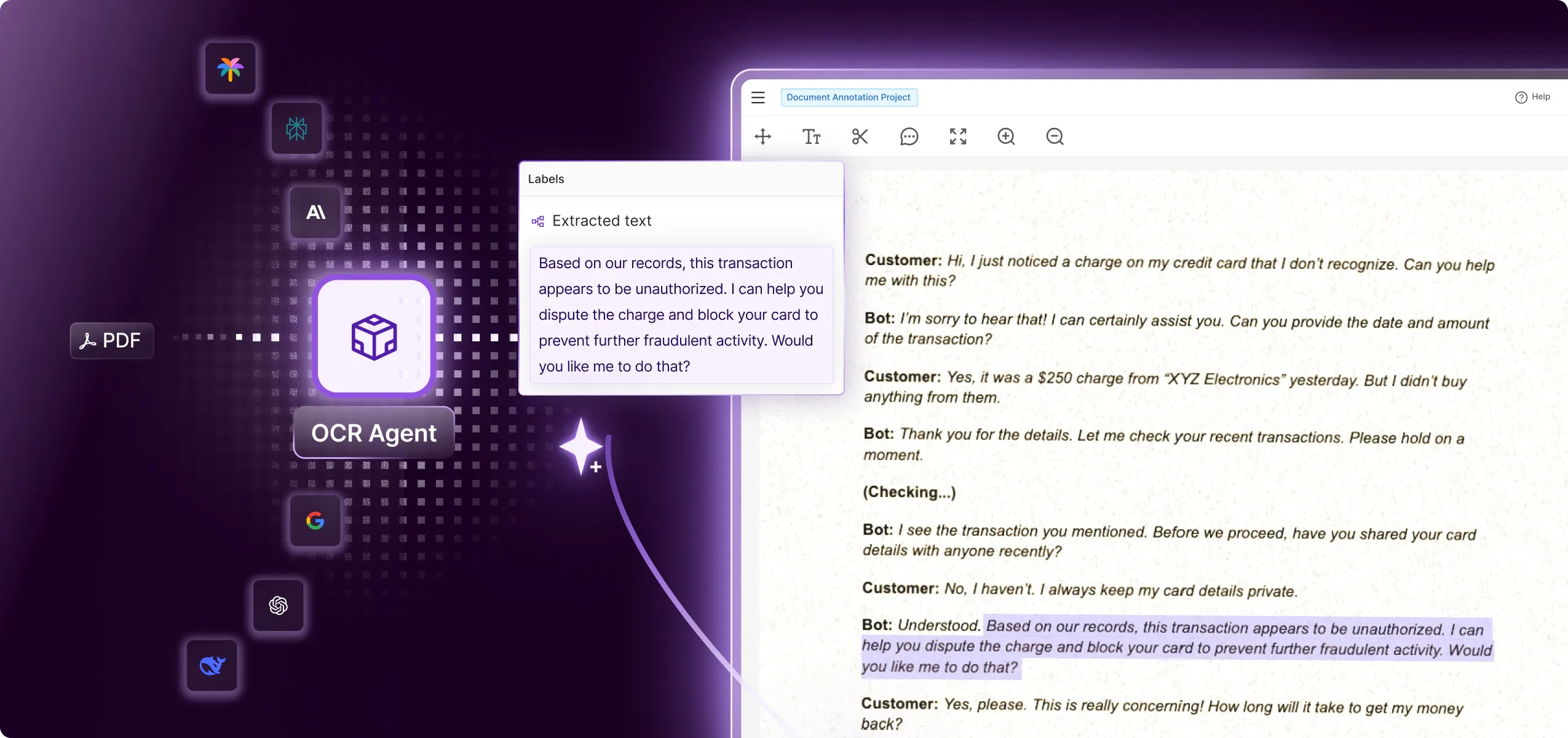
Orchestrate bulk data labeling with AI to future-proof your data workflows to effectively handle large data volumes. Integrate HITL QA to maintain data quality and label accuracy.
Save 1000s of hours, automate any data task
Build multi-step workflows that unite AI models, labeling teams, and reviewers to produce high-quality labeled data. Maintain visibility of annotation progress across multiple teams.
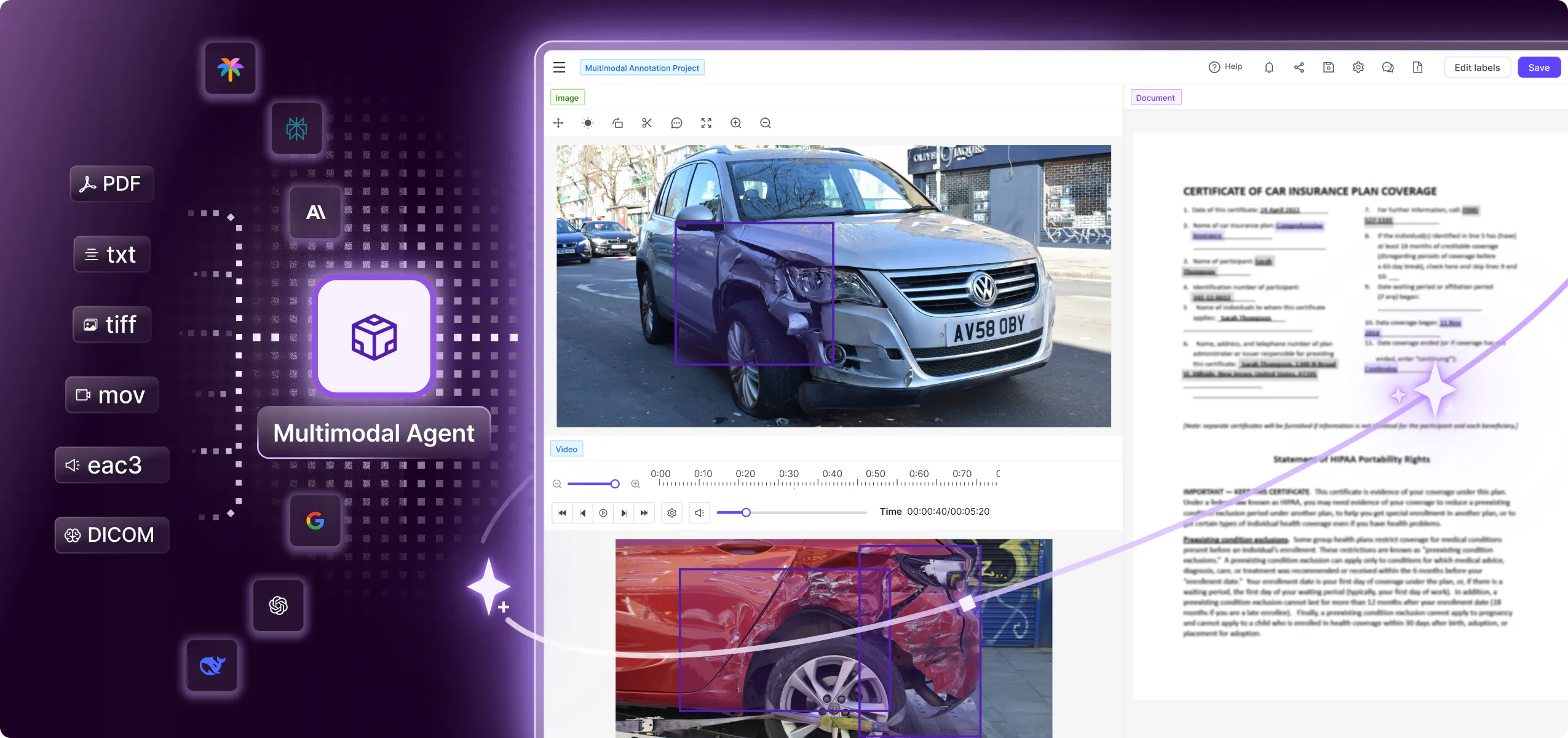
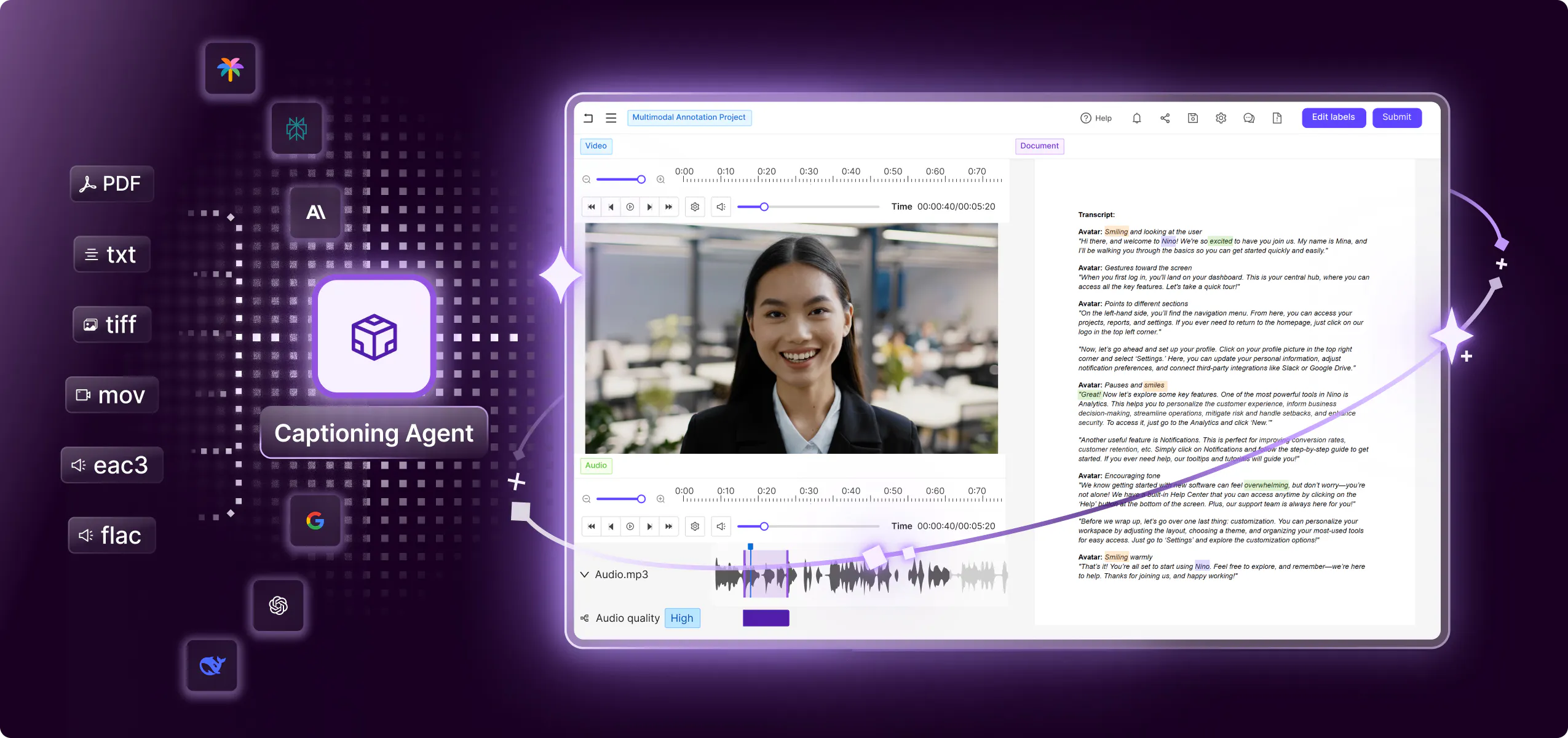


Models
Integrate any SOTA Foundational Model into your data workflow

Open AI’s new flagship model which can reason and generate content across audio, vision, and text in real time. For data pipelines, it can analyze unstructured data and generate contextual labels, enrich metadata, or automate multimodal annotation tasks.

A self-supervised computer vision model that uses the Vision Transformer (ViT) architecture to perform image and pixel-level visual tasks such as image classification, video understanding, and depth estimation.

Models developed by Google that can process text, images, audio and video. Use the model to reason across different modalities to generate text, answer questions and analyze various data.

AI model from Anthropic that is designed to handle complex tasks, such as research, analysis, and task automation. It can process and analyze images, including charts, graphs, technical diagrams, and optical character recognition (OCR).
Bidirectional Encoder Representations from Transformers, understands context, widely used in NLP tasks.
Automatic speech recognition (ASR) model developed by OpenAI. It can accurately transcribe speech into text across multiple languages and dialects, even in noisy environments. Whisper is trained on a massive dataset of diverse audio clips.
More accurate and coherent than LLaMa 3.1, Meta's updated model 3.2 introduces vision-based models, allowing it to process and generate text based on images. This is a major advancement, enabling new applications like image captioning and image-based question answering. LLaMa 3.2 is also multilingual and performs well in text based tasks.

A multimodal foundation model that excels at tasks involving both text and images. It has been trained on a large dataset of paired text and image data, allowing it to understand the relationship between language and visual content.
Text-to-Text Transfer Transformer, translates, summarizes, and generates text.
Open AI’s new flagship model which can reason and generate content across audio, vision, and text in real time. For data pipelines, it can analyze unstructured data and generate contextual labels, enrich metadata, or automate multimodal annotation tasks.
A self-supervised computer vision model that uses the Vision Transformer (ViT) architecture to perform image and pixel-level visual tasks such as image classification, video understanding, and depth estimation.
Models developed by Google that can process text, images, audio and video. Use the model to reason across different modalities to generate text, answer questions and analyze various data.
AI model from Anthropic that is designed to handle complex tasks, such as research, analysis, and task automation. It can process and analyze images, including charts, graphs, technical diagrams, and optical character recognition (OCR).
Bidirectional Encoder Representations from Transformers, understands context, widely used in NLP tasks.
Automatic speech recognition (ASR) model developed by OpenAI. It can accurately transcribe speech into text across multiple languages and dialects, even in noisy environments. Whisper is trained on a massive dataset of diverse audio clips.
More accurate and coherent than LLaMa 3.1, Meta's updated model 3.2 introduces vision-based models, allowing it to process and generate text based on images. This is a major advancement, enabling new applications like image captioning and image-based question answering. LLaMa 3.2 is also multilingual and performs well in text based tasks.
A multimodal foundation model that excels at tasks involving both text and images. It has been trained on a large dataset of paired text and image data, allowing it to understand the relationship between language and visual content.
Text-to-Text Transfer Transformer, translates, summarizes, and generates text.
Enterprise-grade.
Built for scale.
Designed for reliable AI.
Built for scale.
Designed for reliable AI.
API/SDK-first. Zero data migration. Your data stays in your cloud.
Visit trust center


Get the data right
300+ of the best AI teams in the world use Encord. Join them.