Structured Vs. Unstructured Data: What is the Difference?

Product Manager at Encord
Data, often called oil for its resource value, is crucial in machine learning (ML). Machine learning has evolved significantly since its inception in the 1940s thanks to contributions from pioneers like Turing and McCarthy and developments in neural networks and algorithms. This evolution underscores the transition of data from mere information to a driver of growth and innovation.
Data can be categorized into structured and unstructured types. Structured data is organized in databases, making it easily searchable. It is also ideal for quantitative analysis due to its organization. This type includes data in rows and columns, such as financial records in spreadsheets or customer information in CRM systems.
In contrast, unstructured data forms the bulk of today's data generation and is not confined to a specific format. This includes different forms like images, videos, text, and audio files. They provide valuable insights but also pose analytical challenges. Unstructured data is complex with diverse data structures. It requires advanced AI and ML technologies for effective processing.
Understanding data types is crucial because it directly impacts the accuracy and effectiveness of machine learning models. Proper selection and processing of data types enable more precise algorithms and inform innovation and decision-making in AI applications.
By the end of this article, readers will gain a comprehensive understanding of the differences between structured and unstructured data and how each type impacts the field of machine learning and data-driven decision-making.
Structured Data
What is Structured Data?
Structured data is organized in a specific format, typically rows and columns, to facilitate processing and analysis by computer systems. This data type adheres to a clear structure defined by a schema or data model. Examples include numerical data, dates, and strings in relational databases like SQL. Structured data can be efficiently indexed and queried, making it ideal for various applications, from business intelligence to data analytics.
Sources of Structured Data
Structured data sources are diverse and include various systems and platforms where data is methodically organized. Key sources include:
- Relational Databases (RDBMS): Stores data in a structured format using tables. Examples include MySQL, PostgreSQL, and Oracle. They are widely used for managing large volumes of structured data in enterprises.
- Customer Relationship Management (CRM) Systems: These platforms manage customer data, interactions, and business information in a structured format, enabling businesses to track and analyze customer activities and trends like gym owners managing their customer data through gym CRM software
- Online Transaction Processing (OLTP) Systems: They manage transaction-oriented applications. OLTP systems are designed to process high volumes of transactions efficiently and typically structure the data to support quick, reliable transaction processing.
- Enterprise Resource Planning (ERP) Systems: ERP systems integrate various business processes and manage related datasets within an organization. They store and process the data in a structured format for functions like finance, HR, and supply chain management. For example, ERPNext is an open-source ERP system that simplifies managing these processes with a user-friendly approach.
- Spreadsheets and CSV Files: Common in business and data analysis contexts, spreadsheets and CSV files structure data in rows and columns, making it easy to organize, store, and analyze information.
- Data Warehouses: These systems are used for reporting and analysis, acting as central repositories of integrated data from one or more sources. Data warehouses store structured data extracted from various operational systems and are used for creating analytical reports.
- APIs and Web Services: Many modern APIs and web services return data in a structured format, like JSON or XML, which can be easily parsed and integrated into various applications.
- Internet of Things (IoT) Devices: Many IoT devices generate and transmit data in a structured format, which can be used for monitoring, analysis, and decision-making in various applications, including smart homes, healthcare, and industrial automation.
Structured data sources are vast, ranging from traditional databases to modern IoT devices, each playing a pivotal role in the data ecosystem.
Use Cases of Structured Data
- SEO Tools: Web developers use structured data to enhance SEO. By embedding microdata tags into the HTML of a webpage, they provide search engines with more context, improving the page's visibility in search results. Additionally, implementing professional SEO services can further optimize these efforts, ensuring that the structured data is correctly implemented and maximally effective at boosting search rankings.
- Machine Learning: Structured data is pivotal in training supervised machine learning algorithms. Its well-defined nature facilitates the creation of labeled datasets that guide machines to learn specific tasks.
- Data Management: In business intelligence, structured data is essential for managing core data like customer information, financial transactions, and login credentials. Tools like SQL databases, OLAP, and PostgreSQL are commonly employed.
- ETL Processes: In ETL (Extract, Transform, Load) processes, structured data is extracted from various sources, transformed for consistency, and loaded into a data warehouse for analysis. For instance, migrating data from DynamoDB to Snowflake is a common use case where businesses need to move structured data from a NoSQL database to a scalable data warehouse, ensuring better performance and more advanced analytics.
Advantages of Structured Data
- Accessibility and Manageability: The well-defined organization of structured data makes it easily accessible and manageable. It simplifies data storage, retrieval, and analysis, particularly for users with varying technical expertise.
- Data Analysis: Structured data allows for stable and reliable analytics workflows due to its standardized nature. This enables businesses to derive insights and make informed decisions more effectively.
- Support with Mature Tools: A wide array of mature tools and models are available to process structured data, making it easier for organizations to integrate it into their decision-making processes.
- Facilitates Data Democratization: The simplicity and accessibility of structured data empower an organization's broader range of professionals to leverage data for decision-making, promoting a data-informed culture.
Limitations of Structured Data
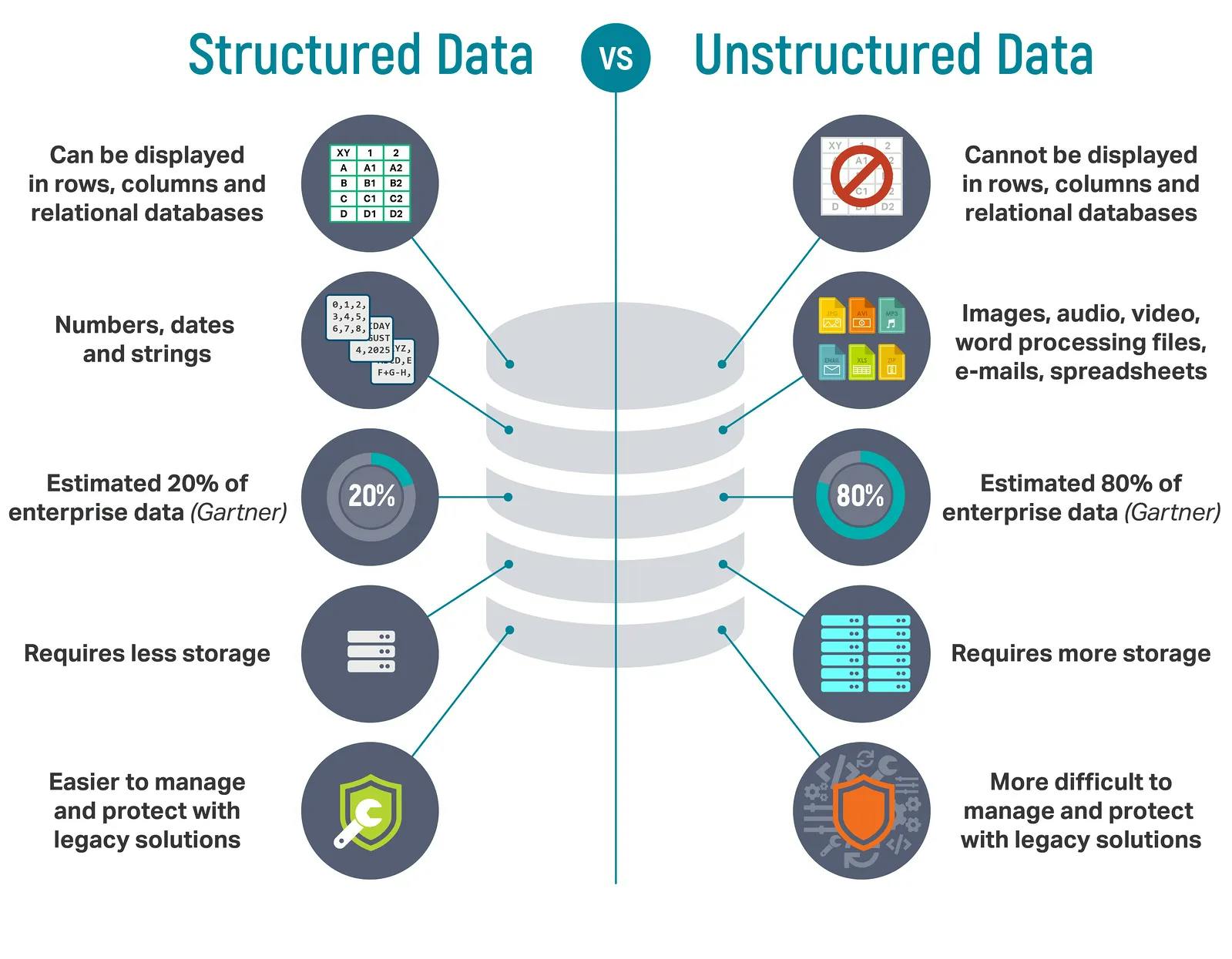
- Limited Scope: Structured data accounts for about 20% of enterprise data, providing a narrow view of business functions. Relying solely on structured data means missing out on insights you could derive from unstructured data.
- Rigidity: Structured data is often rigid in its format, making it less flexible for various data manipulation and analysis techniques. This can be restrictive when diverse data needs arise.
- Cost Implications: Structured data is typically stored in relational databases or data warehouses, which can be more expensive than data lakes used for unstructured data storage.
- Disruption in Workflow: Changes in reporting or analytics requirements can disrupt existing ETL and data warehousing workflows due to the structured nature of the data.
While structured data remains essential in many business applications due to its organized format and ease of use, it is necessary to consider its limitations and the potential benefits of integrating unstructured data into the data strategy. The balance between structured and unstructured data handling can provide more comprehensive insights for business growth and decision-making.
Unstructured Data
What is Unstructured Data?
Unstructured data refers to information that does not have a predefined data model or schema. This data type is typically qualitative and includes various formats such as text, video, audio, images, and social media posts. Unlike structured data, which is easy to search and analyze in databases or spreadsheets, unstructured data is more challenging to process and research due to its lack of organization. For example, while the structure of web pages is defined in HTML code, the actual content, which can be text, images, or video, remains unstructured.
Sources of Unstructured Data
- Web Pages: The internet is a vast source of unstructured data. Web pages contain diverse content like text, images, and unstructured videos.
- Open-Ended Survey Responses: Surveys with open-ended questions generate unstructured data through textual responses. This data provides more nuanced insights compared to structured, multiple-choice survey data.
- Images, Audio, and Video: Multimedia files are considered unstructured data. Technologies like speech-to-text and facial recognition software analyze these data types.
- Emails: Emails are a form of semi-structured data where the metadata (like sender, recipient, and date) is structured but the email content remains unstructured. An SPF record checker help companies ensure the authenticity of incoming emails, protecting against phishing attacks.
- Social Media and Customer Feedback: Social media posts, blogs, product reviews, and customer feedback generate a significant amount of unstructured data. This data includes customer preferences, market trends, and brand perception insights.
Use Cases of Unstructured Data
- Social Media Monitoring: Social media platforms generate vast unstructured data through posts, comments, and interactions. Businesses utilize machine learning tools to analyze this data, gaining insights into brand perception, customer satisfaction, and market trends.
- Customer Feedback Analysis: Companies collect feedback from online reviews, surveys, and emails. Analyzing this unstructured data helps understand customer needs, preferences, and areas for improvement.
- Content Analysis of Webpages: The internet, with its myriad of webpages containing text, images, and videos, is a significant source of unstructured data. Businesses use this data for competitive analysis, market research, and understanding public sentiment.
- Analysis of Open-Ended Survey Responses: Surveys often include open-ended questions where respondents answer in their own words. Analyzing these responses uncovers nuanced insights that can guide business strategies and product development.
- Multimedia Analysis: The analysis of images, audio, and video files, though challenging, can reveal crucial information. Advancements in speech-to-text and image recognition make extracting and analyzing data from these sources easier.
Advantages of Unstructured Data
Unstructured data presents a vast and largely untapped resource for engineers seeking to extract valuable insights and drive innovation. Unlike structured data, which adheres to a predefined schema, unstructured data possesses inherent advantages that can unlock new possibilities across various disciplines.
- Richer Insights: Unstructured data captures the real-world nuance and complexity often missing in structured datasets. This includes text, audio, video, and images, allowing engineers to analyze human sentiment, behavior, and interactions in their natural forms.
- Increased Flexibility: Unstructured data's lack of rigid schema allows for greater flexibility and adaptability. ML and Data Engineers can explore diverse data sources without being constrained by predefined formats.
- Enhanced Innovation: Unstructured data fuels the engine of innovation by providing ML models with a broader and deeper understanding of the world around them.
- Scalability and Cost-Effectiveness: With the increasing affordability of data storage and processing technologies, handling vast amounts of unstructured data becomes more feasible.
- Competitive Advantage: In today's data-driven world, embracing the power of unstructured data is critical for gaining a competitive advantage.
However, it's essential to acknowledge that unstructured data also presents inherent challenges despite its advantages.
Limitations of Unstructured Data
The inherent lack of structure in unstructured data presents several limitations that you must consider.
- Difficulty in Processing: Due to their diverse formats and need for standardized schema, analyzing unstructured data requires specialized tools and techniques such as Natural Language Processing (NLP) algorithms, text analytics software, and machine learning models.
- Data Bias: Unstructured data can be susceptible to biases inherent in its source or collection process. This can lead to accurate or misleading insights if addressed appropriately.
- Data Privacy and Security: Unstructured data often contains sensitive information that requires robust security measures to protect individual privacy.
- Data Quality Concerns: Unstructured data can be incomplete, noisy, and inconsistent, demanding significant effort to clean and prepare before you can analyze it effectively.
- Lack of Standardization: Unstandardized formats and structures in unstructured data present data integration and interoperability challenges.
Despite these limitations, the potential benefits of unstructured data outweigh the challenges. By developing the necessary skills and expertise, you can effectively address the limitations and unlock the vast potential of this valuable resource, driving innovation and gaining a competitive edge in the data-driven world.
Structured vs Unstructured Data
Semi-Structured Data
What is Semi-Structured Data?
Semi-structured data is rapidly becoming ubiquitous across various industries, posing unique challenges and opportunities for data engineers. This section delves into the technical aspects of semi-structured data, exploring its characteristics, sources, and critical considerations for effective management and utilization.
Traditional data storage methods, such as relational databases, rely on rigid schema structures. However, the increasing proliferation of diverse data sources, including sensor readings, social media posts, and weblogs, necessitates flexible approaches. Enter semi-structured data, characterized by its reliance on self-describing formats like JSON, XML, and YAML and lack of a predefined schema.
Sources of Semi-Structured Data
The requirement for semi-structured data stems from its inherent flexibility, making it ideal for capturing complex and evolving information. Key sources include:
- Web Applications: User interactions, log files, and API responses often utilize semi-structured formats for easy data exchange and representation.
- Internet of Things (IoT) Devices: Sensor data, device logs, and operational information are frequently represented in semi-structured formats for efficient transmission and analysis.
- Social Media Platforms: User posts, comments, and interactions generate vast amounts of semi-structured data valuable for social listening and sentiment analysis.
- Scientific Research: Experiment results, gene sequencing data, and scientific observations often utilize semi-structured formats for flexible data representation and analysis.
Use Cases of Semi-Structured Data
- Real-time Analytics: Analyze real-time sensor data, social media feeds, and website traffic to make informed decisions and identify problems quickly.
- Fraud Detection: Spot fraudulent activity in financial transactions and online interactions by looking for patterns in semi-structured data.
- Customer Personalization: Make product recommendations and content more relevant for each user based on their preferences and behavior data.
- Log Analysis: Find the root causes of system errors and performance bottlenecks by analyzing log files in their native semi-structured formats.
- Scientific Research: Manage and analyze complex scientific data, like gene sequences, experimental results, and scientific observations, effectively using the flexibility of semi-structured formats.
Advantages of Semi-Structured Data
- Flexible: Adapt your data model as needed without changing the schema. This lets you add new information and handle changes easily.
- Scalable: Efficiently store and process large datasets by eliminating unnecessary structure and overhead.
- Enables Deep Analysis: Capture the relationships and context within your data to gain deeper insights.
- Cost-Effective: Often cheaper to store and process than structured data.
Limitations of Semi-Structured Data
- Complexity: You'll need specialized tools and techniques to handle and process semi-structured data. It doesn't have a standard format, so finding the right tools can be tricky.
- Data Quality: Semi-structured data can be inconsistent, missing, or noisy. You'll need to clean and process it before you can use it.
- Security and Privacy: Ensure you have robust security measures to protect sensitive information in your semi-structured data.
- Interoperability: Sharing data between different systems can be complex because of the need for standardized formats.
- Limited Tools and Techniques: There are fewer established tools and techniques for analyzing semi-structured data than structured data.
You can unlock its vast potential by learning how to handle semi-structured data effectively and using the right tools.
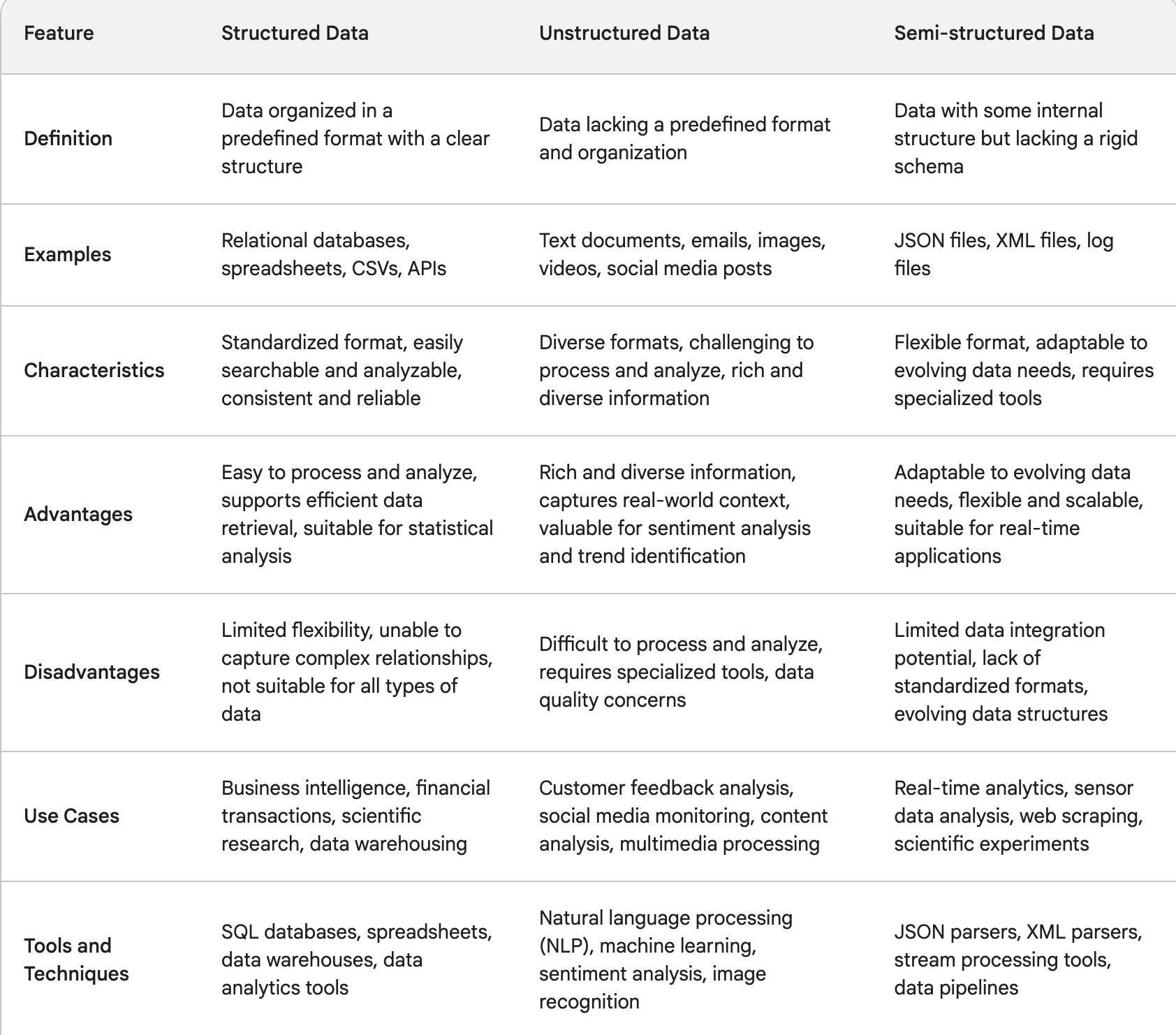
Structured Vs. Unstructured Data vs Semi-Structured Data
I have outlined some key differentiating characteristics of the different data sources in the table below.
Best Practices in Data Management
Effective data management is the cornerstone of data-driven decision-making and AI success. By implementing the following best practices, you can establish a robust and efficient data management system that empowers them to leverage the full potential of their data:
- Process Mapping and Stakeholder Identification: Clearly define data workflows and identify all stakeholders involved in data creation, storage, and utilization. This transparency facilitates collaboration, ensures accountability, and prevents confusion.
- Data Ownership and Responsibility: Establish clear ownership for data quality and ensure accountability at every data lifecycle stage. This promotes consistent data management practices, reduces errors, and facilitates data reliability.
- Efficient Data Capture: Implement reliable mechanisms for capturing relevant data accurately and comprehensively. This might involve utilizing scraping techniques, web scraping APIs, or sensor data collection tools tailored to the specific data source.
- Standardize Data Naming Conventions: Establish consistent naming conventions for data elements to increase data discoverability, accessibility, and analysis. Standardized names facilitate easier identification, retrieval, and manipulation of specific data points.
- Centralized Data Storage: Utilize a centralized data storage solution, such as a data lake or data warehouse, to enable efficient access, retrieval, and analysis of data from various sources. This centralized approach promotes data accessibility and allows for data aggregation and integration.
- Data Quality Management: Prioritize data quality by implementing data quality checks and cleansing processes. This ensures data accuracy, completeness, and consistency, reducing the risk of errors and misinterpretations in data analysis and decision-making.
- Robust Data Security: Implement robust data security measures to protect sensitive information and comply with regulatory requirements. This might involve data encryption, access controls, intrusion detection systems, and data security protocols tailored to the specific data types and organizational needs.
- Data-Driven Culture: Foster a data-driven culture within the organization. This involves providing engineers and other stakeholders access to relevant data and encouraging its use in problem-solving, strategic planning, and data-driven decision-making across all levels.
- Collaboration and Communication: Foster effective collaboration and communication between data engineers and stakeholders, such as business analysts and domain experts. This ensures data is collected, managed, and utilized in a way that aligns with business objectives and drives organizational success.
- Continuous Monitoring and Improvement: Regularly monitor data management processes and performance metrics. Analyze the collected data to identify areas for improvement and implement changes to optimize data management practices and ensure data accessibility, reliability, and security.
By adopting these best practices, organizations can establish a data management system that empowers them to unlock the full potential of data for informed decision-making and innovative solutions, driving success and competitive advantage.
Structured Vs. Unstructured Data: Key Takeaways
In the ever-evolving data landscape, harnessing the potential of diverse data types necessitates a comprehensive approach to data management. By understanding the unique characteristics of structured, semi-structured, and unstructured data (quantitative, qualitative), organizations can leverage the strengths of each type and overcome inherent challenges. Utilizing APIs and choosing appropriate file formats (XML, CSV, JSON) ensures data accessibility and interoperability across different systems and applications, further enhancing data utilization.
Adopting best practices, including utilizing cloud-based storage solutions and implementing efficient data pipelines (ETL), ensures scalability and the ability to handle increasing data volumes. Additionally, addressing data quality concerns through cleansing processes is crucial for reliable data-driven decisions that impact every aspect of an organization's operations (decision-making, scalability).
Embracing a data-driven culture fosters collaboration and communication (APIs) across various teams, including data scientists and programmers using diverse programming languages. This collaborative approach unlocks the full potential of data, driving innovation and long-term success. Furthermore, adhering to ethical considerations in data collection and usage protects individual privacy rights, builds trust, and ensures responsible data management practices.
Ultimately, organizations can unlock valuable insights, gain a competitive edge, and navigate the ever-changing, data-driven world by effectively managing and utilizing data in all its forms. By embracing the challenges and opportunities presented by different data types, organizations can position themselves for continued growth and success.
Frequently asked questions
Structured data, stored in relational databases like SQL or RDBMS, follows a predefined schema with a format like tables or spreadsheets, ideal for quantitative analysis. Unstructured data, including text files, social media posts, and audio and video files, needs a predefined format to provide qualitative insights. Semi-structured data, like JSON or XML files, doesn't fit entirely in relational databases but has some organizational properties, like metadata, aiding in data management.
Combining structured, unstructured, and semi-structured data enables machine learning algorithms to leverage comprehensive datasets from various sources, like CRM systems, IoT sensor data, and social media, enhancing decision-making and predictive analytics in business intelligence and data science.
Technologies like NLP and data mining can convert unstructured data into a structured or semi-structured format, making it compatible with analytics tools and databases like MySQL or NoSQL for use in data science and machine learning applications.
Applications include healthcare predictive modeling using EHR datasets, customer behavior analysis in CRM, and fraud detection in finance by combining transactional data with unstructured customer interaction logs.
Integrating structured, unstructured, and semi-structured data stored in data warehouses or lakes is vital for providing a holistic view. This aids in accurate data analysis and effective data management and supports scalability in AI and machine learning projects.
Encord plays a pivotal role in integrating various data types, including image, text, and structured data, to enhance diagnostic capabilities in healthcare. By enabling the combination of these data sources, Encord helps research teams develop more comprehensive AI models that can provide better insights and improve patient outcomes.
In Encord, metadata fields are specific to each data item, but the formatting of these fields is consistent across the platform. This allows users to filter datasets efficiently. If a data item lacks a specific metadata field, it simply won't appear in the filter results, which avoids clutter and confusion.
When data is streamed from S3 into Encord, it appears in the index portion of the platform as raw files. This structure allows users to create multiple datasets from the same files, facilitating better organization and access while maintaining a clear overview of all available series in the index.
Encord offers unstructured data management solutions tailored for AI teams, which include annotation, validation within loop flows, data curation, and data visualization. These features help manage and govern data effectively, addressing significant challenges in the ADAS space.
Encord's indexing feature enables users to manage and navigate vast amounts of unstructured data effectively. By organizing data into index folders, users can easily find and access relevant information, facilitating a more efficient workflow for data annotation and analysis.
Encord can utilize various data types, including CCTV footage, sensor data from safety equipment, and historical incident reports. This diverse data integration allows for comprehensive analysis and improved safety measures tailored to specific construction site needs.
Yes, Encord is designed to manage unstructured data effectively, including brand guidelines and design files. The platform's advanced filtering and labeling tools help users organize and annotate this type of content for better usability in projects.
Data integration into Encord involves registering the platform and uploading relevant metadata along with the files. This ensures that all necessary information is available for efficient filtering and searching within the platform.
Encord allows users to provide various types of data including images, videos, sensor data, and metadata. This flexibility enables comprehensive data exploration and filtering to suit different use cases.
Encord offers various ways to bring data into its platform, including cloud integrations. Users can easily upload datasets, facilitating a seamless data management experience.