Stream-based Selective Sampling
Encord Computer Vision Glossary
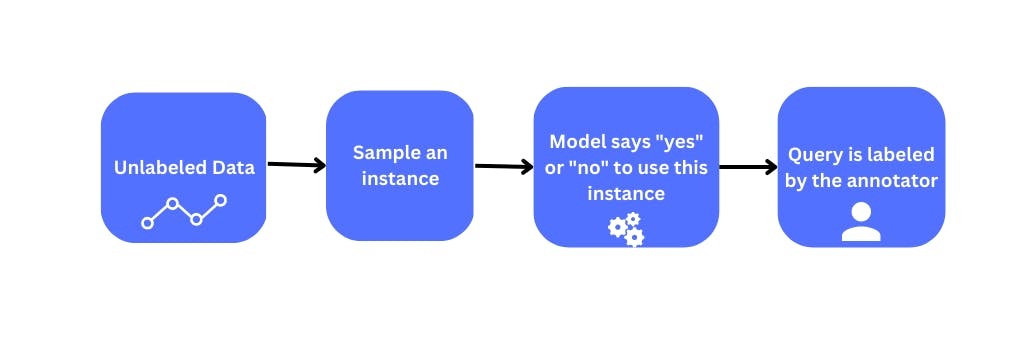
Stream-based selective sampling is a query strategy used in active learning for continuous data streams, such as those found in online or real-time data analysis. In this approach, the algorithm selects a subset of the current stream and decides whether to label it based on the current state of the model.
When the model is already performing well on the current data stream, the algorithm may choose not to label any new data to reduce computational cost. Conversely, if the model is not performing well on the current data stream, the algorithm may decide to label new data in hopes of improving the model's performance.
This approach has several advantages and disadvantages which should be considered before selecting this query strategy.
Advantages
- Reduced labeling cost: Stream-based selective sampling reduces the cost of labeling as it allows the algorithm to selectively label only the most informative samples in the data stream. This can be especially useful when the cost of labeling is high, and labeling all incoming data is not feasible.
Scale your annotation workflows and power your model performance with data-driven insightsTry Encord today
- Adaptability to changing data distribution: This strategy is highly adaptive to changes in the data distribution. As new data is constantly arriving in the stream, the model can quickly adapt to changes and adjust its predictions accordingly.
- Improved scalability: Steam-based selective sampling allows for improved scalability since it can handle large amounts of incoming data without requiring the storage of all the data.
Disadvantages
- Potential for bias: Stream-based selective sampling can introduce bias into the model if it only labels certain types of data. This can lead to a model that is only optimized for certain types of data and may not generalize well to new data.
- Difficulty in sample selection: This sampling strategy requires careful selection of which samples to label as the algorithm only labels a small subset of the incoming data. Selection of the wrong samples to label can result in a model that is less accurate than a model trained with a randomly selected labeled dataset.