How to Improve Datasets for Computer Vision

Machine learning algorithms need vast datasets to train, improve performance, and produce the results the organization needs.
Datasets are the fuel that computer vision applications and models run on. The more data the better. And this data should be high-quality, to ensure the best possible outcomes and outputs from artificial intelligence projects.
One of the best ways to get the data you need to train ML models is to use open-source datasets.
Fortunately, there are hundreds of high-quality, free, and large-volume open-source datasets that data scientists can use to train algorithmically-generated models.
In a previous article, we took a deep dive into where to find the best open-source datasets for machine learning models, including where you can find them depending on your sector/use cases.
Quick recap: What Are The Best Datasets For Machine Learning?
Depending on your sector, and the use cases, some of the most popular machine learning and computer vision datasets include:
- Insurance: Car Damage Assessment Dataset;
- Sports: Multiview Football Dataset I & II (from KTH), and the OpenTTGames Dataset;
- SAR (Synthetic Aperture Radar) machine learning datasets: xView and xView3, both from the Copernicus Sentinel-1 mission of the European Space Agency (ESA), and the EU Copernicus Constellation;
- Smart cities and autonomous vehicles (self-driving cars) datasets: BDD100K and The KITTI Vision Benchmark Suite
Retailers and manufacturers: RPC-Dataset Project - Medical and healthcare: The Cancer Imaging Archive (TCIA) and the NIH Chest X-Rays (on Kaggle)
- Open dataset aggregators: Kaggle and OpenML
In this tutorial, we’ll take a closer look at the steps you need to take to improve the open-source dataset you’re using to train your model.
Training Your Model And Assessing Performance
If you’re using a public, open-source dataset, there’s a good chance the images and videos have already been annotated and labeled. For all intents and purposes, these datasets are as close to being model-ready as possible.
Using a public dataset is something of a useful shortcut to getting a proof of concept (POC) training model up and running. Getting you one step closer to being able to run a fully-tested production model.
However, before simply feeding any of these datasets into a machine learning model, you need to:
- Make sure the data aligns with your project goals and objectives.
- Ensure that the annotations (bounding boxes, image segmentation, etc), and metadata are high quality, with sufficient modalities, and object types.
- Check that there are enough images or videos to reduce bias (for example, in the case of medical imaging datasets, is there a wide enough spread of races, genders, age groups, and patients with or without the diseases being studied?)
- Are there enough images or videos under different conditions (e.g. light vs. dark, day vs. night, shadows vs. no shadows
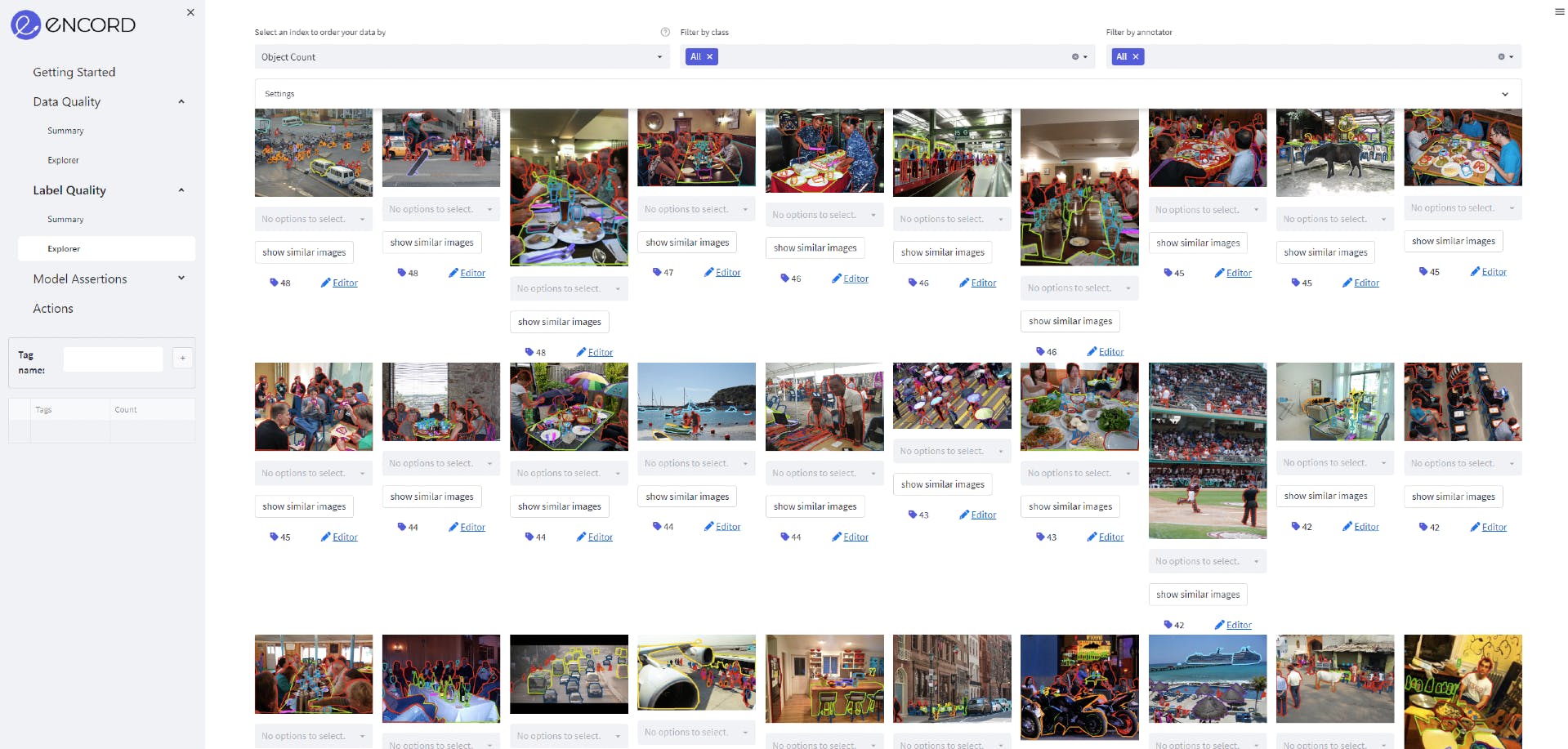
Reviewing label quality in Encord Active
Now you’ve got the data and you’ve checked that it’s suitable, you can start training a machine learning model for carrying out computer vision tasks.
With each training task, you can set a machine learning model to a specific goal. For example, “identify black Ford cars manufactured between 2000 and 2010.”
And to train that model, you might need to show the model tens of thousands of images or videos of cars. Within the training data should be sufficient examples so that it can positively identify the object(s), “X”; in this case: black Ford cars, and only those manufactured between specific years.
It’s equally important that within the training data are thousands of examples of cars that are not Ford’s, the object(s) in question.
To train a machine learning or CV model, you need to show the model enough examples of objects that are the opposite of what it’s being trained to identify. So, in this example, the dataset should include loads of images of cars that are different colors, makes, and models.
ML and computer vision algorithms only train effectively when they’re shown a wide enough range of images and videos that contrast with the target object(s) in question. It’s useful to ensure any public, open-source datasets that you use benefit from extensive environmental factors too, such as light and dark, day and night, shadows, and other variables as required.
Once you start training a model, your team can start assessing its performance.
Don’t expect high-performance outputs from day one. There’s a good chance you could run 100 training tests and only 30% will score high enough to gain any valuable insights into how to turn one or two into working production models.
Training model failure is a natural and normal part of computer vision projects.
Identify Why and Where the Dataset Needs Improvement
Now you’ve started to train the machine learning model (or models) you are using on this dataset, results will start to come in.
These results will show you why and where the model is failing. Don’t worry, as data scientists, data operations, and machine learning specialists know, failure is an inevitable and normal part of the process.
Without failure, there can be no advancement in machine learning models.
At first, expect a high failure rate, or at the very least, a relatively low accuracy rate, such as 70%.
Use this data to create a feedback loop so you can more clearly identify what’s needed to improve the success rate. For example, you might need:
- More images or videos;
- Specific types of images or videos to increase the efficiency outputs and accuracy (for more information on this check out our blog on data augmentation) ;
- An increase in the number of images or videos produces more balance in the results, e.g. reduce bias.
Next, these results often generate another question: If we need more data, where can we get it from?
Collect or Create New Images or Video Data
Solving problems at scale often involves using large volumes of high-quality data to train machine learning models. If you’ve got access to the volumes you need from an open-source or proprietary dataset then keep feeding the model — and adjusting the datasets labels and annotations accordingly — until it starts generating the results you need.
However, if that isn’t possible and you can’t get the data you need from other open-source, real-world datasets, there is another solution.
For example, what if you need thousands of images or videos of car crashes, or train derailments?
How many images and videos do you think exist of things that don’t happen very often? And even when they do happen, these edge cases aren’t always captured clearly in images or videos.
In these scenarios, you need synthetic data.
For more information, here’s An Introduction to Synthetic Training Data
Computer-generated images (CGI), 3D games engines — such as Unity and Unreal — and Generative adversarial networks (GANs) are the best sources for creating realistic synthetic images or videos in the volumes your team will need to train a computer vision model.
There’s also the option of buying synthetic datasets. If you’ve not got the time/budget to wait for custom-made images and videos to be generated. Either way, when your ML team is trying to solve a difficult edge case and there isn’t enough raw data, it’s always possible to create or buy some synthetic data that should improve the accuracy of a training model.
Retrain Machine Learning Model and Reassess Until The Desired Performance Standards Are Achieved
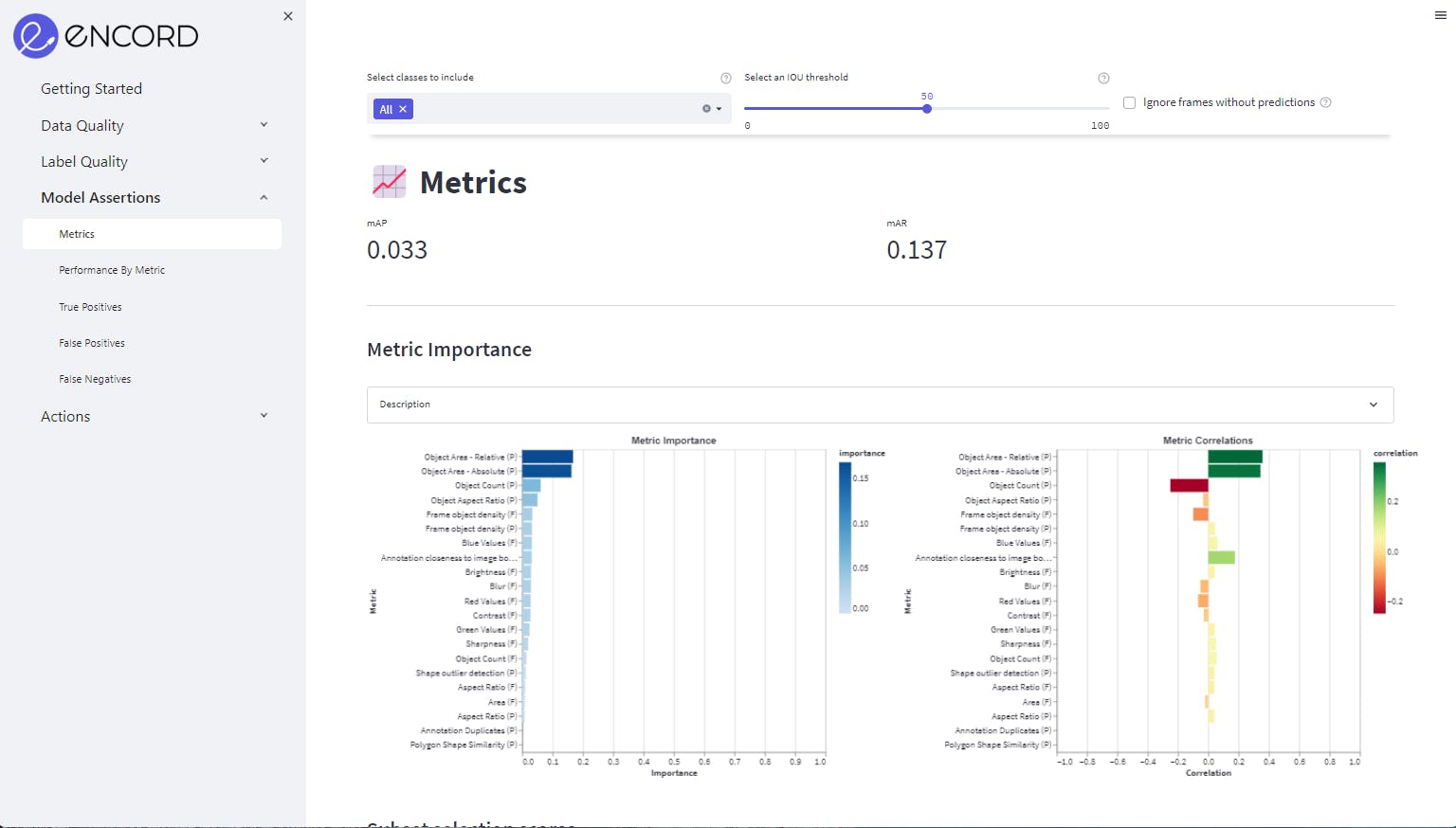
Assessing model performance in Encord
Now you’ve got enough data to keep training and retraining the model, it should be possible to start achieving the performance and accuracy standards you need. Assuming initial results started out at 70%, once results are in the 90-95%+ range then your model is moving in the right direction!
Keep testing and experimenting until you can start benchmarking the model for accuracy.
Once accuracy outcomes are high enough, bias ratings low enough, and the results are on target with the aim of your model, then you can put the working model into production.
Ready to find failure modes in your computer vision model and improve its accuracy?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Frequently asked questions
Encord enhances annotation efficiency by streamlining workflow management and providing tools for better training of annotators. The platform allows users to organize large amounts of data effectively, enabling quicker access and annotation of relevant video frames, which is crucial for projects with extensive datasets.
Encord allows users to create and specify annotation schemas in a user-friendly format, such as JSON. This feature enables different teams to easily upload datasets and define the classes needed for efficient annotation, facilitating collaboration among software engineers and annotators.
Encord offers robust data management solutions that facilitate the curation of evaluation results and human annotations. These capabilities ensure that results from different expert annotators can be effectively organized and accessed, enhancing collaboration and insights across teams.
Encord facilitates model fine-tuning by providing tools to evaluate and curate labeled data effectively. Users can utilize data quality metrics to refine their datasets, ensuring that the best possible data is used for training, which ultimately leads to improved model performance.
Encord offers advanced annotation tools and data management features that enhance the training process for machine learning models. By providing a structured approach to data annotation, teams can ensure high-quality labeled data, which is crucial for model performance.
Yes, Encord can enhance unsupervised learning models by facilitating manual annotation processes that improve model accuracy. By providing tools for human feedback and preference ranking, teams can refine their models post-training for better performance.
Encord offers a modern, streamlined approach to data annotation compared to traditional methods. By leveraging its platform, users can achieve greater efficiency, accuracy, and collaboration, ultimately leading to better outcomes for AI training projects.
Encord offers a robust alternative to traditional internal annotation systems by providing enhanced features and capabilities tailored specifically for sports data. This allows teams to assess the advantages of using Encord over their current solutions.
Encord offers intelligent selection and filtering capabilities that streamline the data curation process, making it easier to push relevant datasets into the annotation workflow. This reduces the manual effort and cumbersome nature of current systems.
Yes, Encord provides tools that assist in selecting the most relevant data for annotation, helping to minimize quality issues. By focusing on high-quality data, teams can enhance their machine learning models and reduce the need for extensive rework.