Contents
The Training Data Quality Problem
Encord Index: Automated Data Quality and Label Assessment Product
A Quick Tour of the Data Quality Assessment Product
Encord Blog
How to Automate the Assessment of Training Data Quality




When building AI models, machine learning (ML) engineers run into two problems with regard to labeling training data: the quantity problem and the quality problem.
ML engineers were stuck on the quantity problem for a long time. Supervised machine learning models need a lot of labeled data, and the model’s performance depends on having enough labeled training data to cover all the different types of scenarios and edge cases that the model might run into in the real world.
As they gained access to more and more data, machine learning teams had to find ways to label it efficiently.
In the past few years, these teams have started to find solutions to this quantity problem–either by hiring large groups of people to annotate the data or by using new tools that automate the process and generate many labels more systematically.
Unfortunately, the quality problem only truly began to reveal itself once solutions to the quantity problem emerged. Solving the quantity problem first made sense–after all, the first thing you need to train a model is a lot of labeled training data.
However, once you train a model on that data, it becomes apparent pretty quickly that the quality of the model’s performance is not only a function of the amount of training data but also of the quality of that data’s annotations.

The Training Data Quality Problem
Data quality issues arise for several reasons. The quality of the training data depends on having a strong pipeline for sourcing, cleaning, and organizing the data to ensure that your model isn’t trained on duplicate, corrupt, or irrelevant data.
After creating a strong pipeline for sourcing and managing data, machine learning teams must ensure that the labels identifying features in the data are error-free.
That’s no easy task because mistakes in data annotations arise from human error, and the reasons for these errors are as varied as the human annotators themselves.
All annotators can make mistakes, especially if they’re labeling for eight hours a day. Sometimes, annotators don’t have the domain expertise required to label the data accurately.
Sometimes, they haven’t been trained appropriately for the task at hand. Other times, they aren’t conscientious or consistent: they either aren’t careful or haven’t been taught best practices in data annotation.
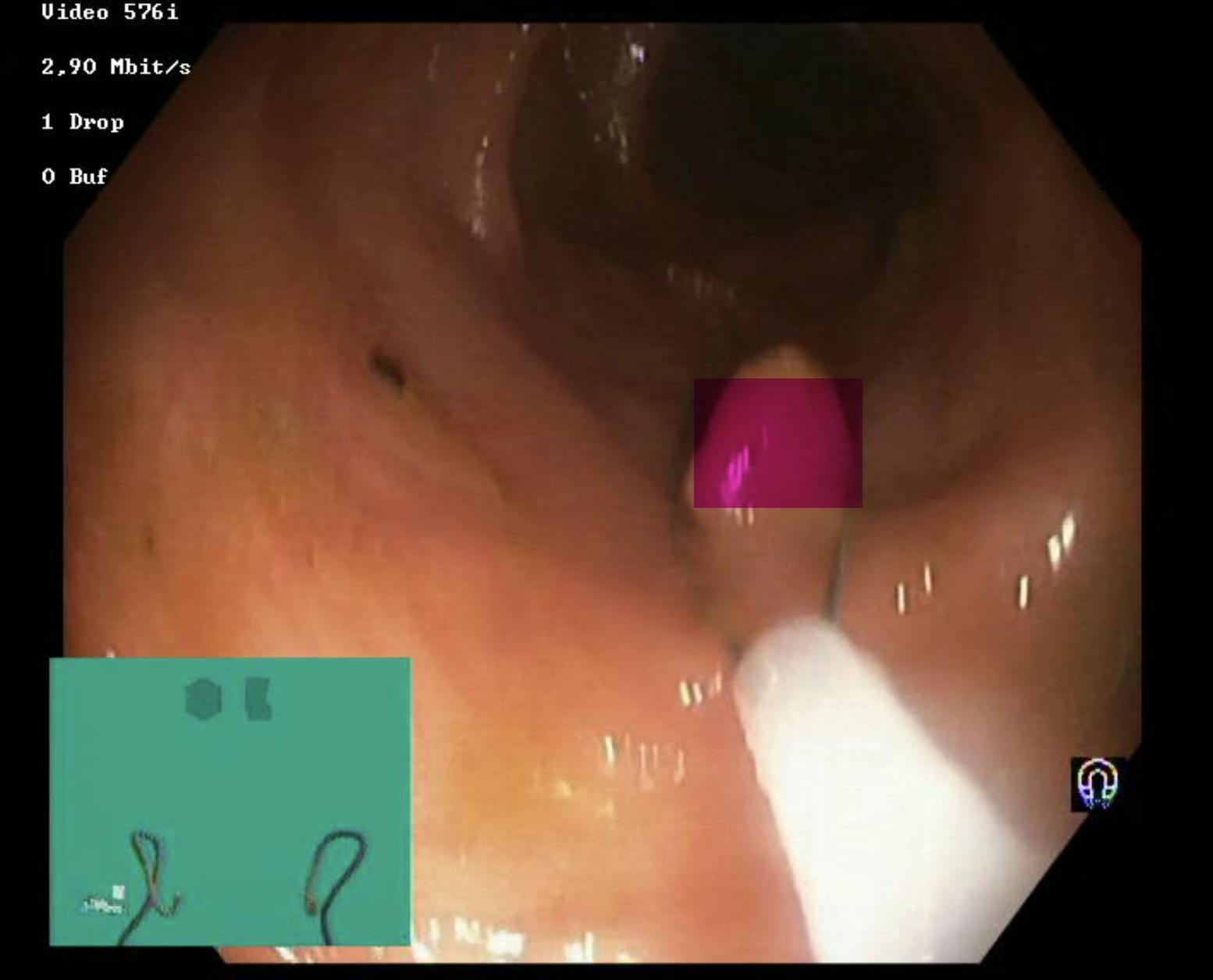
A misplaced box around a polyp (from the Hyper Kvasir dataset)
Regardless of the cause, poor data labeling can result in all types of model errors. For example, if trained on inaccurately labeled data, models might make miscategorization errors, such as mistaking a horse for a cow.
Or, if trained on data where the bounding boxes haven’t been drawn tightly around an object, models might make geometric errors, such as failing to distinguish the target object from the background or other objects in the frame.
A recent study revealed that 10 of the most cited AI datasets have serious labeling errors: the famous ImageNet test set has an estimated label error of 5.8 percent.
Your model suffers when you have label errors because it's learning from incorrect information. When using cases with a high sensitivity to the error about the consequences of a model’s mistake, such as autonomous vehicles and medical diagnosis, the labels must be specific and accurate.
There’s no room for these labeling errors or poor-quality data. In these situations, where a model must operate at 99.99 percent accuracy, small margins in its performance matter.
The breakdown in model performance from poor data quality is an insidious problem because machine learning engineers often don’t know whether the problem is in the model or the data.
They can spin their wheels trying to improve a model only to realize that the model will never improve because the problem is in the labels themselves.
Taking a data-centric rather than a model-centric approach to AI can relieve some headaches. After all, these problems are best addressed by improving the training data quality before looking to improve the quality of the model.
However, data-centric AI can’t reach its potential until we solve the data quality problem.
Currently, assuring data quality depends on manually intensive review processes. This approach to quality is problematic and unscalable because the volume of data that needs to be checked is far greater than the number of human reviewers available.
And reviewers also make mistakes, so there’s human inconsistency throughout the labeling chain. To correct these errors, a company can have multiple reviewers look at the same data, but now the cost and the workload have doubled so it’s not an efficient or economical solution.
Encord Index: Automated Data Quality and Label Assessment Product
When we began Encord, we were focused on the quantity problem. We wanted to solve the human bottleneck in data labeling by automating the process.
However, after talking to many AI practitioners, particularly those at more sophisticated companies, we quickly realised they were stuck on the quality problem.
We also decided to turn our attention to solving the data quality problem from these conversations. We realized that the quantity problem would only be solved if we got smarter about ensuring that the amount of data going into the pot was also high-quality.
Encord has created and launched the first fully automated label and data quality assessment tool for machine learning. This tool replaces the manual process that makes AI development expensive, time-consuming, and difficult to scale.
A Quick Tour of the Data Quality Assessment Product
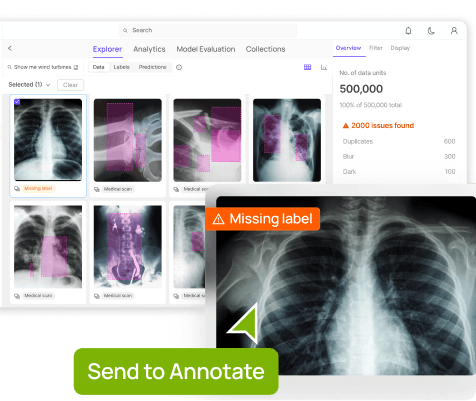
Within Encord’s platform, we have developed a quality feature that detects likely errors within a client's project using a semi-supervised learning algorithm.
The client chooses all the labels and objects they want to inspect from the project, runs the algorithm, and then receives an automated ranking of the labels by the probability of error.
Each label receives a score, so rather than having a human review every individual label for quality, they can intelligently use the algorithm to curate the data for human review.
The score reflects whether the label is likely high or low quality. The client can set a threshold to send everything above a certain score to the model and send anything below a certain score for manual review.
The human can then accept or reject the label based on its quality. The humans are still in the loop, but the data quality assessment software tool saves them as much time as possible. The humans are still in the loop, but the data quality assessment tool saves them as much time as possible, using their time efficiently and when it matters the most.
In the example below, the client has annotated the different teeth in many patients' mouths with a polygon mask. The polygon mask in the image should segment a tooth but for some labels. the mask area isn't as tight to the tooth as it should be. Encord Index automatically flags and surfaces these labels for your human labeler and reviewer to fix.

You can also explore the quality of the data and labels with Encord Index Embeddings view, where you can select specific classes based on the ontology:

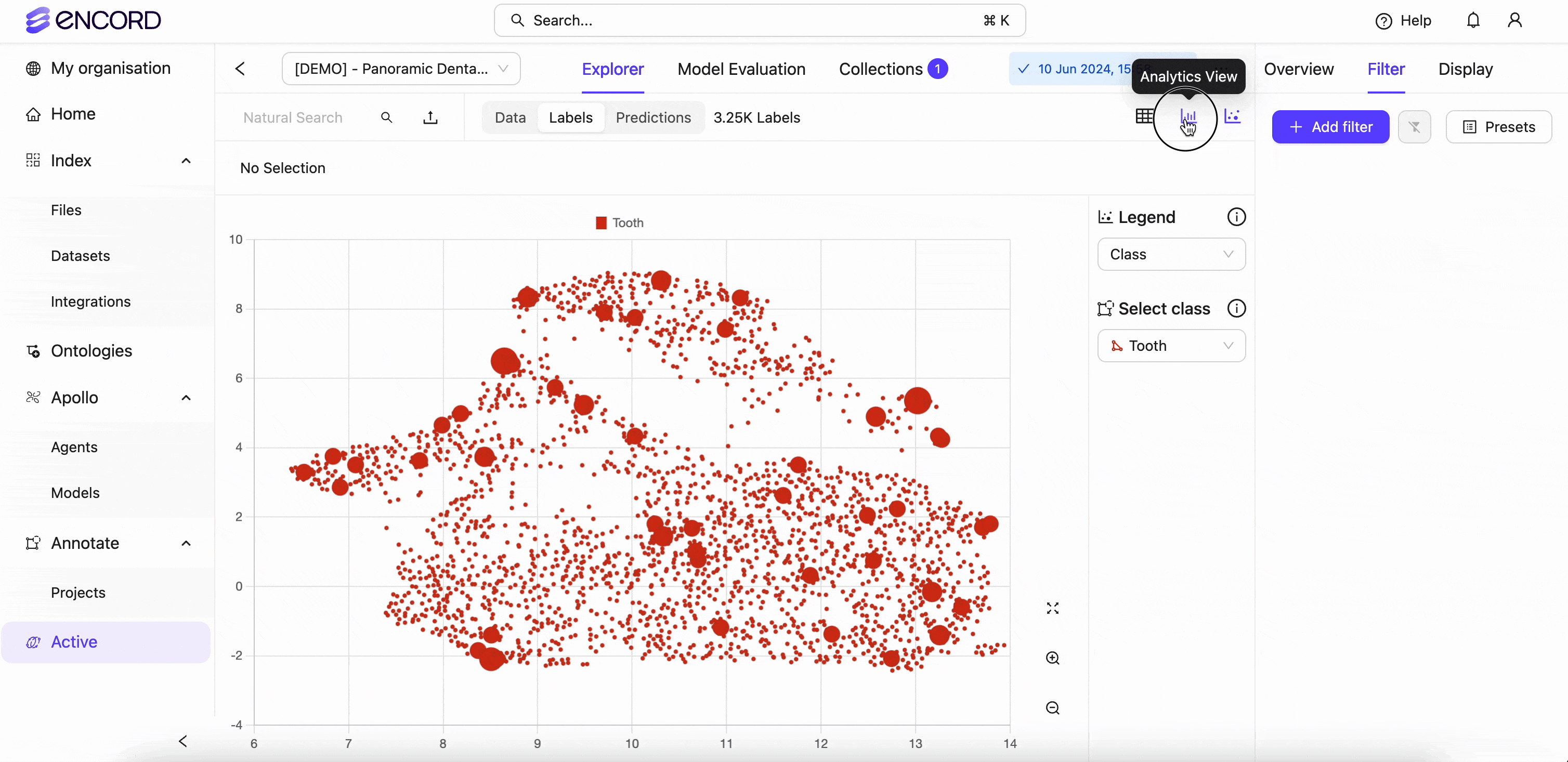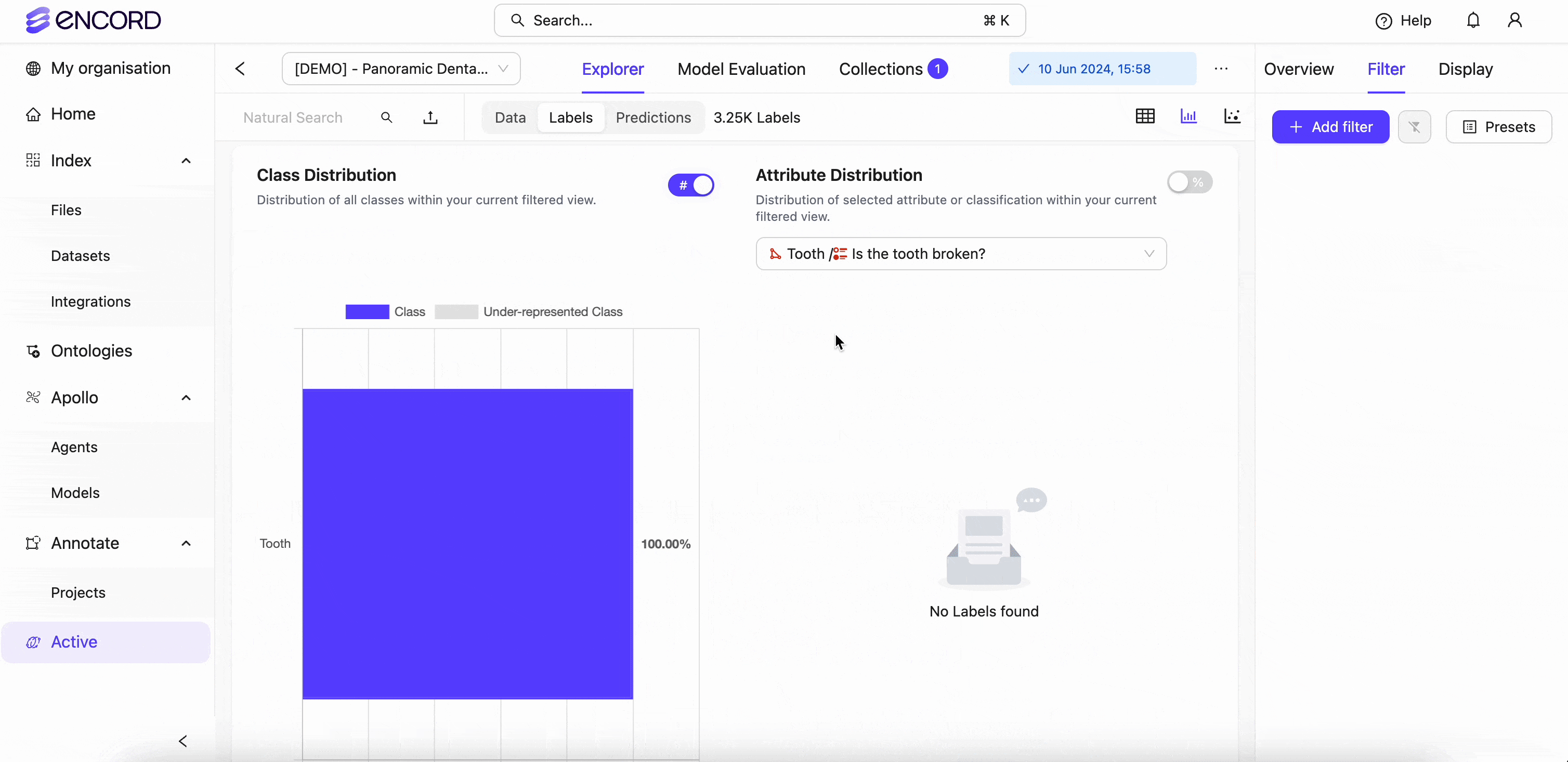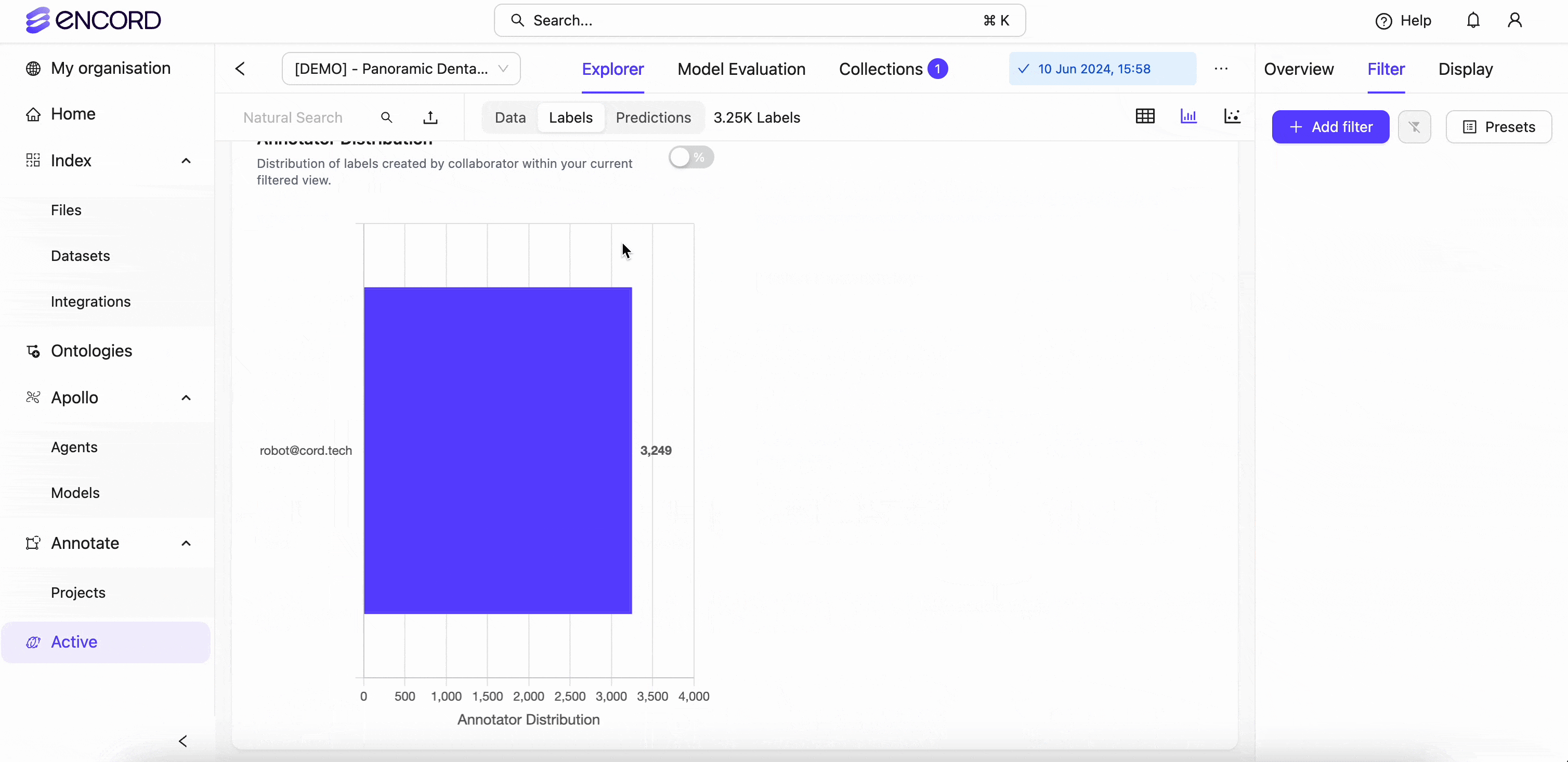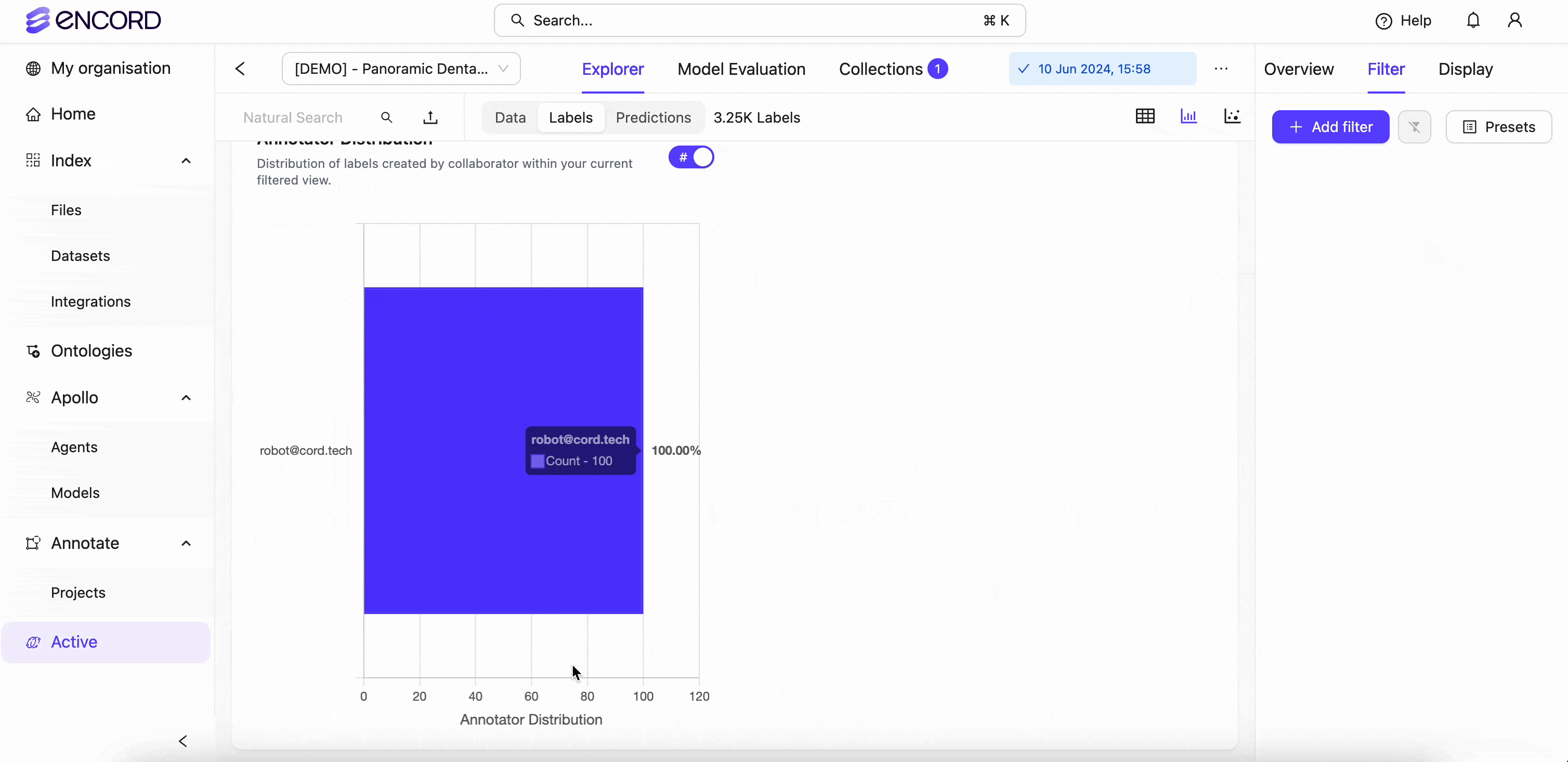
Encord Index also aggregates statistics on the human rejection rate of different labels so machine learning teams can better understand how often humans reject certain labels.
With this information, they can improve labeling for more difficult objects. In the below example, we are visualizing the label and data quality through analytical stats using the Analytics view:

Encord Index works with vision datasets and supports many computer vision tasks and use cases.
Increased Efficiency: Combining Automated Data Labelling with the Quality Data Assessment Tool
Encord Annotate allows you to create labels manually and through automation (e.g. interpolation, tracking, or using our native model-assisted labeling).
Encord Active lets you import model predictions via our API and Python SDK. Labels or imported model predictions are often subjected to manual review to ensure they are of the highest possible quality or to validate results.
Using Encord Index, we see customers performing an automated review of labels, filtering, sorting, searching, and curating the right data to label through bulk classification. They can then automatically label the dataset with custom AI agents or other techniques in Encord Annotate without changing any of their workflows and at scale.
The quality feature reassures customers about the quality of model-generated labels. Our platform aggregates information to show which label-generating agents are doing the best jobs from the human annotator group, the imported labels group, and the automatically produced labels group.
In other words, when ranking the labels within a dataset, the Index doesn’t distinguish between human- and model-produced labels. As a result, this feature helps build confidence in using several different label-generating methods to produce high-quality training data.
With both automated label generation using micro-models and Encord Index, we optimise the human-in-the-loop’s time as much as possible. In doing so, we can cherish people’s time by using it only for the most necessary and meaningful contributions to machine learning.
Ready to automate the assessment of your training data?
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Explore our products
Index
Manage & curate your data
Understand and manage your visual data, prioritize data for labeling, and initiate active learning pipelines.
Annotate
Supporting your labeling needs
Super charge your data annotation with AI-powered labeling — including automated interpolation, object detection and ML-based quality control.
Active
Find & fix data issues with ease
Monitor, troubleshoot, and evaluate the data and labels impacting model performance.