Florence-2: Microsoft's New Foundation Model Explained

In the world of Artificial General Intelligence (AGI) systems, a significant shift is underway toward leveraging versatile, pre trained representations that exhibit task-agnostic adaptability across diverse applications. This shift started in the field of natural language processing (NLP), and now it’s making its way into computer vision too. That’s where Florence-2 comes in: a vision foundation model designed to address the challenges of task diversity in computer vision and vision-language tasks.
Background
Artificial General Intelligence aims to create systems that can perform well across various tasks, much like how humans demonstrate diverse capabilities. Recent successes with versatile, pre trained models in the field of NLP have inspired a similar approach in the realm of computer vision. While existing large vision models excel in transfer learning, they often struggle when faced with various tasks and simple instructions. The challenge lies in handling spatial hierarchy and semantic granularity inherent in diverse vision-related tasks.
Key challenges include the limited availability of comprehensive visual annotations and the absence of a unified pretraining framework with a singular neural network architecture seamlessly integrating spatial hierarchy and semantic granularity. Existing datasets tailored for specialized applications heavily rely on human labeling, which limits, the development of foundational models capable of capturing the intricacies of vision-related tasks.
Florence-2: An Overview
To tackle these challenges head-on, the Florence-2 model emerges as a universal backbone achieved through multitask learning with extensive visual annotations. This results in a unified, prompt-based representation for diverse vision tasks, effectively addressing the challenges of limited comprehensive training data and the absence of a unified architecture.
Built by Microsoft, the Florence-2 model adopts a sequence-to-sequence architecture, integrating an image encoder and a multi-modality encoder-decoder. This design accommodates a spectrum of vision tasks without the need for task-specific architectural modifications, aligning with the ethos of the NLP community for versatile model development with a consistent underlying structure.
Florence-2 stands out through its unprecedented zero-shot and fine-tuning capabilities, achieving new state-of-the-art results in tasks such as captioning, object detection, visual grounding, and referring expression comprehension. Even after fine-tuning with public human-annotated data, Florence-2 competes with larger specialist models, establishing new benchmarks.

Technical Deep Dive
Carefully designed to overcome the limitations of traditional single-task frameworks, Florence-2 employs a sequence-to-sequence learning paradigm, integrating various tasks under a common language modeling objective.
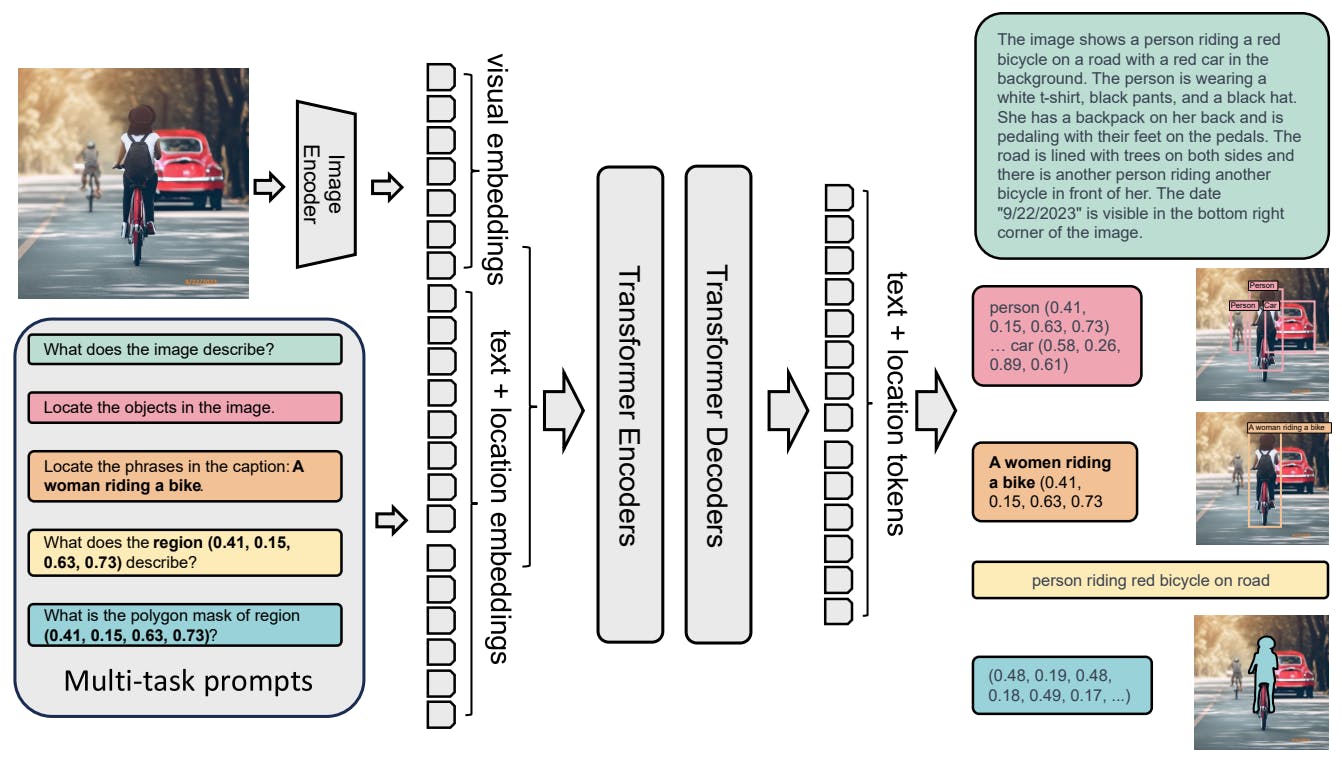
Florence-2’s model architecture. Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Let's dive into the key components that make up this innovative model architecture.
Task Formulation
Florence-2 adopts a sequence-to-sequence framework to address a wide range of vision tasks in a unified manner. Each task is treated as a translation problem, where the model takes an input image and a task-specific prompt and generates the corresponding output response.
Tasks can involve either text or region information, and the model adapts its processing based on the nature of the task. For region-specific tasks, location tokens are introduced to the tokenizer's vocabulary list, accommodating various formats like box representation, quad box representation, and polygon representation.
Vision Encoder
The vision encoder plays a pivotal role in processing input images. To accomplish this, Florence-2 incorporates DaViT (Data-efficient Vision Transformer) as its vision encoder. DaViT transforms input images into flattened visual token embeddings, capturing both spatial and semantic information. The resulting visual token embeddings are concatenated with text embeddings for further processing.
Multi-Modality Encoder-Decoder Transformer
The heart of Florence-2 lies in its transformer-based multi-modal encoder-decoder. This architecture processes both visual and language token embeddings, enabling a seamless fusion of textual and visual information. The multi-modality encoder-decoder is instrumental in generating responses that reflect a comprehensive understanding of the input image and task prompt.
Optimization Objective
To train Florence-2 effectively, a standard language modeling objective is employed. Given the input (combined image and prompt) and the target output, the model utilizes cross-entropy loss for all tasks. This optimization objective ensures that the model learns to generate accurate responses across a spectrum of vision-related tasks.
The Florence-2 architecture stands as a testament to the power of multi-task learning and the seamless integration of textual and visual information. Let’s discuss the multi-task learning setup briefly.
Multi-Task Learning Setup
Multitask learning is at the core of Florence-2's capabilities, necessitating large-scale, high-quality annotated data. The model's data engine, FLD-5B, autonomously generates a comprehensive visual dataset with 5.4 billion annotations for 126 million images. This engine employs an iterative strategy of automated image annotation and model refinement, moving away from traditional single and manual annotation approaches.
The multitask learning approach incorporates three distinct learning objectives, each addressing a different level of granularity and semantic understanding:
- Image-level Understanding Tasks: Florence-2 excels in comprehending the overall context of images through linguistic descriptions. Tasks include image classification, captioning, and visual question answering (VQA).
- Region/Pixel-level Recognition Tasks: The model facilitates detailed object and entity localization within images, capturing relationships between objects and their spatial context. This encompasses tasks like object detection, segmentation, and referring expression comprehension.
- Fine-Grained Visual-Semantic Alignment Tasks: Florence-2 addresses the intricate task of aligning fine-grained details between text and image. This involves locating image regions corresponding to text phrases, such as objects, attributes, or relations.
By incorporating these learning objectives within a multitask framework, Florence-2 becomes adept at handling various spatial details, distinguishing levels of understanding, and achieving universal representation for vision tasks.
Performance and Evaluation
Zero-Shot and Fine-Tuning Capabilities
Florence-2 impresses with its zero-shot performance, excelling in diverse tasks without task-specific fine-tuning. For instance, Florence-2-L achieves a CIDEr score of 135.6 on COCO caption, surpassing models like Flamingo with 80 billion parameters.
In fine-tuning, Florence-2 demonstrates efficiency and effectiveness. Its simple design outperforms models with specialized architectures in tasks like RefCOCO and TextVQA. Florence-2-L showcases competitive state-of-the-art performance across various tasks, emphasizing its versatile capabilities.
Comparison with SOTA Models
Florence-2-L stands out among vision models, delivering strong performance and efficiency. Compared to models like PolyFormer and UNINEXT, Florence-2-L excels in tasks like RefCOCO REC and RES, showcasing its generalization across task levels.
In image-level tasks, Florence-2 achieves a CIDEr score of 140.0 on COCO Caption karpathy test split, outperforming models like Flamingo with more parameters. Downstream tasks, including object detection and segmentation, highlight Florence-2's superior pre-training. It maintains competitive performance even with frozen model stages, emphasizing its effectiveness.
Florence-2's performance in semantic segmentation tasks on the ADE20k dataset also stands out, outperforming previous state-of-the-art models like BEiT pre trained model on ViT-B.
Qualitative Evaluation and Visualization Results
Florence-2 is qualitatively evaluated on the following tasks:
Detailed Image Caption

Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Visual Grounding

Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Open Vocabulary Detection

Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
OCR

Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Region to Segmentation

Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Comparison with SOTA LMMs
The Florence-2 is evaluated against other Large Multimodal Models (LMMs) like GPT 4V, LLaVA, and miniGPT-4 on detailed caption tasks.

Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Conclusion
In conclusion, Florence-2 emerges as a groundbreaking vision foundation model, showcasing the immense potential of multi-task learning and the fusion of textual and visual information. It offers an efficient solution for various tasks without the need for extensive fine-tuning.
The model's ability to handle tasks from image-level understanding to fine-grained visual-semantic alignment marks a significant stride towards a unified vision foundation. Florence-2's architecture, exemplifying the power of sequence-to-sequence learning, sets a new standard for comprehensive representation learning.
Looking ahead, Florence-2 paves the way for the future of vision foundation models. Its success underscores the importance of considering diverse tasks and levels of granularity in training, promising more adaptable and robust machine learning models. As we navigate the evolving landscape of artificial intelligence, Florence-2's achievements open avenues for exploration, urging researchers to delve deeper into the realms of multi-task learning and cross-modal understanding.