Contents
What is Data Cleaning For Machine Learning Models?
How Does Image and Video Data Cleaning Apply to Computer Vision?
How Do You Know Your Data is Clean?
What Happens if You Put Unclean Data Into A Machine Learning Model?
How Do You Do Image and Video Dataset Cleaning For Machine Learning Models?
Encord Blog
How to Clean Data for Computer Vision



How clean is your data?
Data cleaning for computer vision (CV) and machine learning (ML) projects is an integral part of the process, and something that must be done before annotation and model training can start.
Unclean data costs time and money. According to an IBM estimate published in the Harvard Business Review (HBR), the cost of unclean, duplicate, and poor-quality data is $3.1 trillion.
It can cost tens of thousands of dollars to clean 10,000+ lines of database entries before those datasets can be fed into a text-only ML, Deep Learning (DL), or Artificial Intelligence (AI-based) model.
When it comes to image and video-based datasets, the work involved and, therefore, the cost, is even higher. It’s essential — for the integrity of a machine learning model algorithms, and the outputs and results you want to generate — that the datasets you’re feeding it are clean.
In this article, we review the importance of data cleaning of image and video datasets for computer vision models, and how data ops and annotation teams can clean data before a project starts.
What is Data Cleaning For Machine Learning Models?
Machine learning models are more effective, produce better outcomes, and the algorithms train more efficiently when the data preparation has been done and the data they’re supplied is clean. As the data science saying goes, “Garbage in, garbage out.” If you put unclean data into a machine learning model, especially after the images or videos have been annotated, it will produce poor quality and inaccurate results.
Data cleaning has to happen before annotation work can begin; as a project leader, you need to allocate time/budget to this part of the process, otherwise, you risk wasting crucial time training a model using unclean data.
Otherwise, an annotation team spends too much time trying to clean the datasets before they can apply the relevant annotations and labels. Or if an annotation team doesn’t spot the “dirty data”, then a data ops team will have to fix the mistakes themselves or send the images or videos back to be re-annotated.
In the HBR article where the cost of $3.1 trillion was mentioned, this is known as having an in-house “hidden data factory.” Far too many knowledge economy workers spend the time they shouldn’t have to clean data, especially when teams are up against tight deadlines.
Hidden data factories are expensive and time-consuming productivity black holes. Data cleaning is non-value-added work. It wastes time if datasets aren’t cleaned and processed before annotators can start applying annotations and labels to the images and videos.
How Does Image and Video Data Cleaning Apply to Computer Vision?
As we’ve mentioned, clean data is needed before you can train computer vision model algorithms.
Annotators should be spending all of their time working on images and videos they can annotate and label without worrying about dataset “janitor work”, as The New York Times once eloquently put it.
With image-based datasets, there are numerous data-cleaning issues that can occur. You could have images that are too bright, or too dull, and there can be duplicates, corrupted files, and other problems with the images provided.
All of these issues can influence the outcome of computer vision models. Different file types, incompatible files, or too many greyscale images across a large volume of the dataset can cause problems.
Training a computer vision model involves ensuring the highest quality and volume of annotated images are fed into it. That’s not possible when there are problems with a problematic percentage of the images in a dataset.
Medical images are even more complex, especially when the file formats (such as DICOM) involve numerous layers of images and patient data. Also, given the stringent requirements and regulatory hurdles medical datasets and ML models have to overcome, it’s even more crucial to ensure that the datasets clinical operations teams use are as clean as possible.
With video-based datasets, the challenges can be even more difficult to overcome. Unclean data in the context of videos include corrupted files, duplicate frames, ghost frames, variable frame rates, and other sometimes unknown and unexpected problems.
All of these data-cleaning challenges can be overcome. For the overall success of the machine learning or computer vision model, crucial time and effort is invested in cleaning raw datasets before the annotation team starts work.

How Do You Know Your Data is Clean?
There are a couple of ways you can test the cleanliness of your data before it goes into a machine learning model.
One way, and by far the most time-consuming, would be for someone — ideally a quality assurance/quality control data professional — to go through every image and video manually. Checking every image, video, and frame, to make sure the images or videos are “clean”; without errors, duplicates, corrupted files, or any brightness/dullness problems we’ve previously mentioned.
Whether images or videos are too bright or too dull is a potentially serious problem. Too much or too little of one or the other could unintentionally change the outcome of a machine learning model.
So, a concerted effort in the early stages of a project must be made to ensure the datasets going to the annotation teams are clean. Manual checking and correcting of every image and video is very time-consuming, and often not practical, not when there could be thousands of images and videos in a dataset.
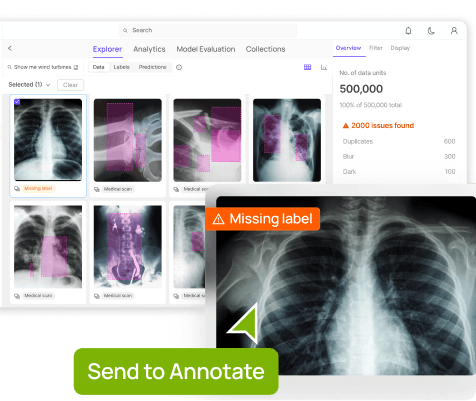
One way to make this easier is to automate the process, and there are automation tools that will help accelerate and simplify data-cleaning tasks. One such tool is Encord Active, an open-source active learning framework for computer vision projects. Encord Active is a “test suite for your labels, data, and models. Encord Active helps you find failure modes in your models, prioritize high-value data for labeling, and find outliers in your data to improve model accuracy.”
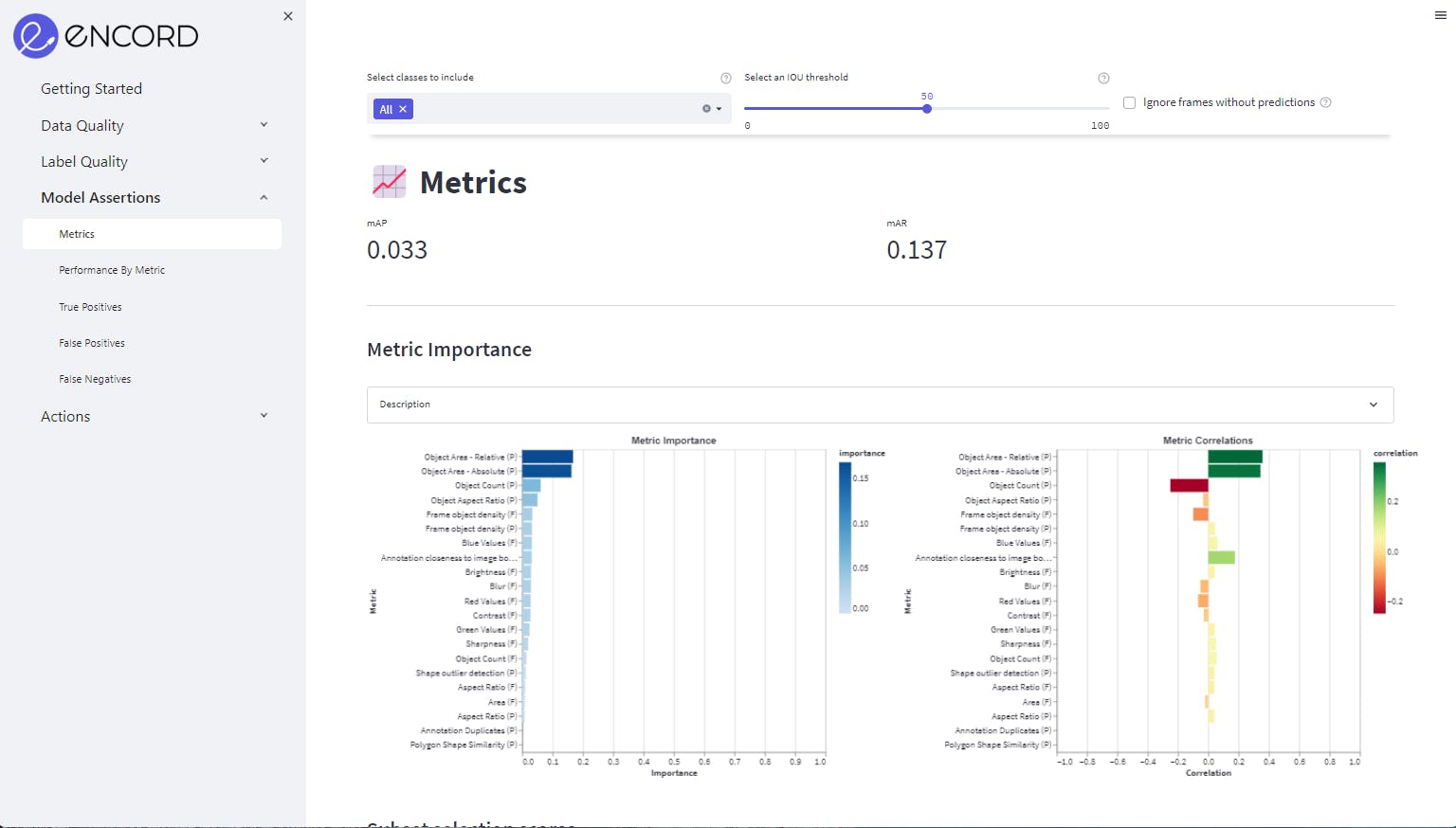
Model assertions in Encord Active
Debug your models and your data before and during the annotation phase of a project, before you start feeding data into your machine learning project or computer vision model for training and validation.
Compared to manual data cleaning, it saves a huge amount of time, and if you need to create or get more images or videos, then an automation tool can inform data ops leaders about the type and volume of data required to train the model.
What Happens if You Put Unclean Data Into A Machine Learning Model?
When “unclean data”, datasets with corrupted and duplicate files, images that are too bright or too dull, and videos with ghost and variable frames, are fed into machine learning algorithms, it will corrupt the outcome. In some cases, a model simply won’t train.
A data operations manager might go home for the night, having put dozens of datasets into models to train, only to find the next day that the models haven’t trained. Or that the accuracy is so poor that the results are meaningless.
A team then needs to investigate the cause of the poor results or untrained models. According to NYT interviews: “far too much handcrafted work — what data scientists call “data wrangling,” “data munging” and “data janitor work” — is still required. Data scientists . . . spend from 50 percent to 80 percent of their time mired in this more mundane labor of [data cleaning].”
Starting over, having annotation teams re-annotate images and videos, or manually cleaning datasets takes time, causing project costs to spiral. Target outcomes and deadlines get pushed further into the future because the data quality isn’t good enough to be introduced to the model yet. Senior leaders and sponsors could lose confidence in the project.
It might also be necessary to either artificially generate more images and videos, to balance out having ones that are either too bright, too dull, or have other issues that could impact the outcome. Videos might need to be re-formatted before they can be re-annotated.
The cost and work involved in fixing unclean data after it goes into a machine learning model can be high. It’s better, whenever possible, to ensure the data going into the model is clean before annotation work starts, and then you can be more confident in the outcomes of the training part of the process.
How Do You Do Image and Video Dataset Cleaning For Machine Learning Models?
In extreme cases, when data is corrupted, it needs to be taken out of datasets. However, that’s always a last resort, as it’s always a case of the more data the better, for the sake of ML and CV models.
Before that needs to happen, images and videos can be reformatted, and manually cleaned up, and automation tools can be used to change brightness levels and other formatting issues. Once as much data cleaning, or sourcing new clean data, has been done, then tools such as Encord Active can be used to debug the data.
It’s also worth pointing out that the labels and annotations applied by the annotation team need to be “clean” before datasets can be fed into ML models. Again, this is where a tool like Encord Active can prove invaluable, to ensure computer vision models are being fed the most effective and efficient training data to produce the outcomes your team and project leaders need.
Ready to clean your data and improve the performance of your computer vision model?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Join our Discord channel to chat and connect.
Data infrastructure for multimodal AI
Click around the platform to see the product in action.
Written by

Frederik Hvilshøj
Explore our products
Index
Manage & curate your data
Understand and manage your visual data, prioritize data for labeling, and initiate active learning pipelines.
Annotate
Supporting your labeling needs
Super charge your data annotation with AI-powered labeling — including automated interpolation, object detection and ML-based quality control.
Active
Find & fix data issues with ease
Monitor, troubleshoot, and evaluate the data and labels impacting model performance.