Contents
Does A Market Exist for Computer Vision Machine Learning Startups?
What Are The Prerequisites For Building a Computer Vision Company?
What’s Your Computer Vision Startup Idea and How Do You Test It?
What Visual Data Do You Need and Where Do You Find It?
What Computer Vision Model Could You Use (or should you create your own)?
How to Create Your First Datasets and Ensure Data Quality
How to Train Your Computer Vision Machine Learning Model?
How to Test Your Computer Vision Machine Learning Model?
Next Steps For Building a Computer Vision Machine Learning Model Startup
Encord Blog
How to Start a Computer Vision Startup



Computer vision and machine learning is a vast and growing market, currently worth around $12 billion, and is continuing to grow, making this the ideal time to launch a computer vision machine learning startup.
Although it’s a high-growth sector, launching and building a computer vision machine learning startup isn’t easy. As a startup founder, you often feel like a participant in the deadly Netflix series, Squid Game.
Building a computer vision or machine learning startup involves finding and solving a real-world problem, with commercial applications and use cases. Your biggest challenge is producing a working machine learning model that takes annotated datasets of images or videos (from photos to SAR to DICOM and anything else) and turns them into solutions that companies are willing to pay for.
Computer vision and machine learning startups are often founded by software and big data engineers, recent research graduates, and even students. Before you can consider applying for funding from investors, you need a working proof of concept (POC) machine learning model.
Only then can you consider starting to turn that into a multi-million dollar startup that investors want to fund, the best engineers want to work for, and clients want to spend budget with.
In this post, we outline the steps an aspiring computer vision startup founder needs to take to transform an idea into a working production model.
Does A Market Exist for Computer Vision Machine Learning Startups?
The market for computer vision machine learning startups is huge and growing. The sector is expected to grow to over $20 billion in 2030, with a compound annual growth rate (CAGR) of 7%, according to several research reports.
Computer vision (CV) and machine learning (ML) models have hundreds of use cases across dozens of sectors. Any sector or industry where there’s value within vast datasets of images and videos — and you need an ML or CV model to unlock vital information — is a viable environment for creating a solution to problems people in that sector need solving. It’s supply and demand. Applications of computer vision can include:
- Healthcare diagnostics
- Robotics
- Facial recognition
- Image processing
- Object recognition and object detection
- Self-driving cars (autonomous vehicles)
However, to start with, you need to work out the most effective solutions to those problems, and testing your idea is the first step down this road.
What Are The Prerequisites For Building a Computer Vision Company?
Before building a computer vision company, it helps to have the following:
- An academic background in a relevant subject, such as computer vision, machine learning, big data, software engineering, data science, computer science, artificial intelligence (AI), deep learning (DL), or related research fields;
- Knowledge of key programming languages (especially Python)
- Experience developing software, or working knowledge of open-source applications, research, and methodologies in this field;
- Experience researching or publishing papers, or contributing to open-source development tools, communities, and platforms. Some experience with imaging or video-based datasets is useful too;
- An idea and a working concept of how to test that idea;
- Knowledge of computer vision algorithms and models you could use, or a concept for a model you could create;
- A way of sourcing training data to train and optimize the machine learning model on;
- A way to test these datasets to ensure the highest quality possible for the training stage when developing a proof of concept AI solution;
- And finally, a simple go-to-market model, or way of working with customers during the proof of concept stage so that once you have a viable working model you can already demonstrate that it’s market-tested with valid and proven use cases.
Now we cover each of these in more detail, so you’re clear on the steps you can take to build a computer vision startup.
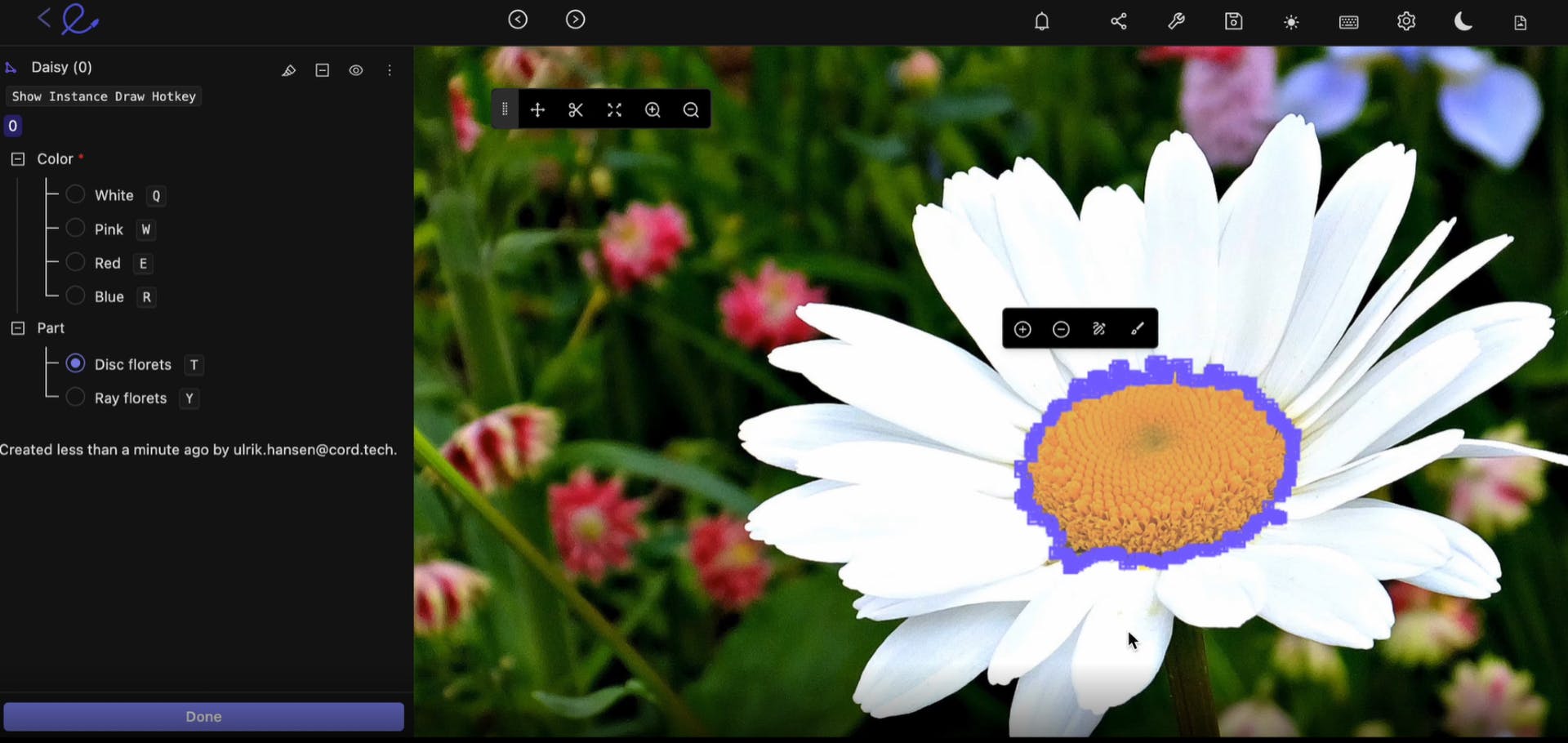
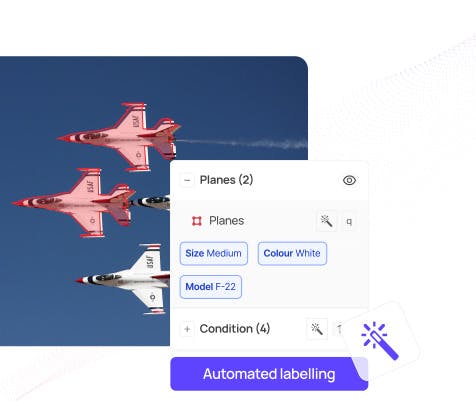
Segmenting images in Encord to create training data
What’s Your Computer Vision Startup Idea and How Do You Test It?
Every startup — in every sector, niche, and vertical — starts with a minimum viable product (MVP); also known as Proof of Concept (POC), in the computer vision and machine learning field.
Many of these in this sector begin life as spin-offs from research projects. However, to turn an idea into something commercially viable it needs to have commercial applications. We can’t stress that enough. Otherwise, it’s not a startup. It will remain a research project that you can seek grants and funding for, but not something that investors could back and clients will pay for.
Start with the problems in sectors you’ve had some experience in (either through work or academic research) that need solutions. This is either a problem that has no existing solution, or one where you’re confident computer vision systems could be used to create a more effective solution.
For example, “How can radiologists identify rare tumors more effectively, with much higher accuracy than current models they are using?”
Providing your idea is commercially viable then it’s worth testing.
But what’s the best way to validate an idea’s commercial potential?
- Speak to potential customers/users. Start small. You don’t need to sample hundreds. All you need is enough validation that your idea is worth testing and pursuing.
- Make sure you’ve got a clear understanding of any problems current models have, and crucially, what organizations will pay to have a solution for this problem.
- Once you’re clear on the problem that needs solving, and that your solution is commercially viable, then you can start testing your idea.
- Testing an idea in the computer vision space involves getting your hands on image or video datasets. Labeling and annotating them. Finding or building an ML or CV model. And then running those datasets through experiments to test the model, until you’ve got a viable, proven, machine learning model, with the test data results to show for it.
What Visual Data Do You Need and Where Do You Find It?
Sourcing data is one of the most significant challenges for machine learning startups.
There are dozens of open-source datasets for machine learning models. Unfortunately, unless you’re doing something radically different, there’s a good chance these datasets have already been used to prove similar concepts.
Open-source datasets might be useful when benchmarking your model against other algorithms. But, for this stage in the process, you need proprietary data that is hard to find and cost-effective to scale. Search for sources within the sector you are trying to solve the problem for. Aim to get the data you need from the sorts of organizations you want to win as clients.
Hence the advantage of speaking to potential customers at the earliest opportunity. These organizations could help you prove the model you want to test and supply the data you need to train and test the model.
Failing that, work to find ways to get comparable data (volume, quality, etc.) that will prove the use case without it costing a fortune to find it.
What Computer Vision Model Could You Use (or should you create your own)?
In the early stages of developing a computer vision model, founders can go pretty far with numerous open-source options.
There are dozens, if not hundreds, of open-source models to choose from, such as YOLO, Residual Steps Network (RSN), AlphaPose, or Regional Multi-Person Pose Estimation (RMPE), MediaPipe, and numerous others.
We cover these and others in this comprehensive glossary of 39 computer vision terms you need to know.
As these models are open-source, you can always iterate on what’s available to test your own theories and datasets. Or take what you’ve learned from open-source and other computer vision and machine learning models to improve on what you’ve found.
Failing that, you can develop your own machine-learning model. Creating proprietary algorithms will give you intellectual property (IP) that you can patent in the future, giving your startup an advantage. However, taking this approach will take longer and cost more than using readily-available open-source models.
It comes down to every startup founder’s challenge: Do I build or buy?
Early on, it may make more sense to use open-source ML or CV models and tools. But it can become expensive and time consuming when you start to build your own solutions, even when based on an open-source tool. Your own use case is rarely going to be so specific and special that there isn’t an off the shelf tool that will do the job (allowing you to concentrate on the product you’re trying to build).
How to Create Your First Datasets and Ensure Data Quality
Next, you need to create your first dataset and ensure the data is high-quality before feeding it into your ML or CV model. Annotating the data is an essential first step.
Manual annotation takes time, depending on the volume of data and the number of labels and annotations that are needed. You will need a team for this, and ideally, automation tools to accelerate the process. You don’t need to build your own, there are some powerful data labeling automation tools on the market, such as Encord.
How to Train Your Computer Vision Machine Learning Model?
Training your computer vision model is the next step. You need to run numerous datasets through your ML model to train them for accuracy, validating several possible use cases to test one theory against another. This stage is crucial. It demonstrates whether the model works, especially for the commercial use cases you’ve set out to solve.
How to Test Your Computer Vision Machine Learning Model?
Testing your trained models with the annotated datasets is the final stage in the process. You need to evaluate the data outcomes against objectives. Test it against industry-accepted metrics, such as F1 scores. Benchmark the data and results against benchmarking datasets for computer vision models, such as COCO.
Encord has recently launched Encord Active to help with this. Encord Active is an open-source machine learning, and computer vision model debugging tool, for the model and data testing stage of the development pipeline.
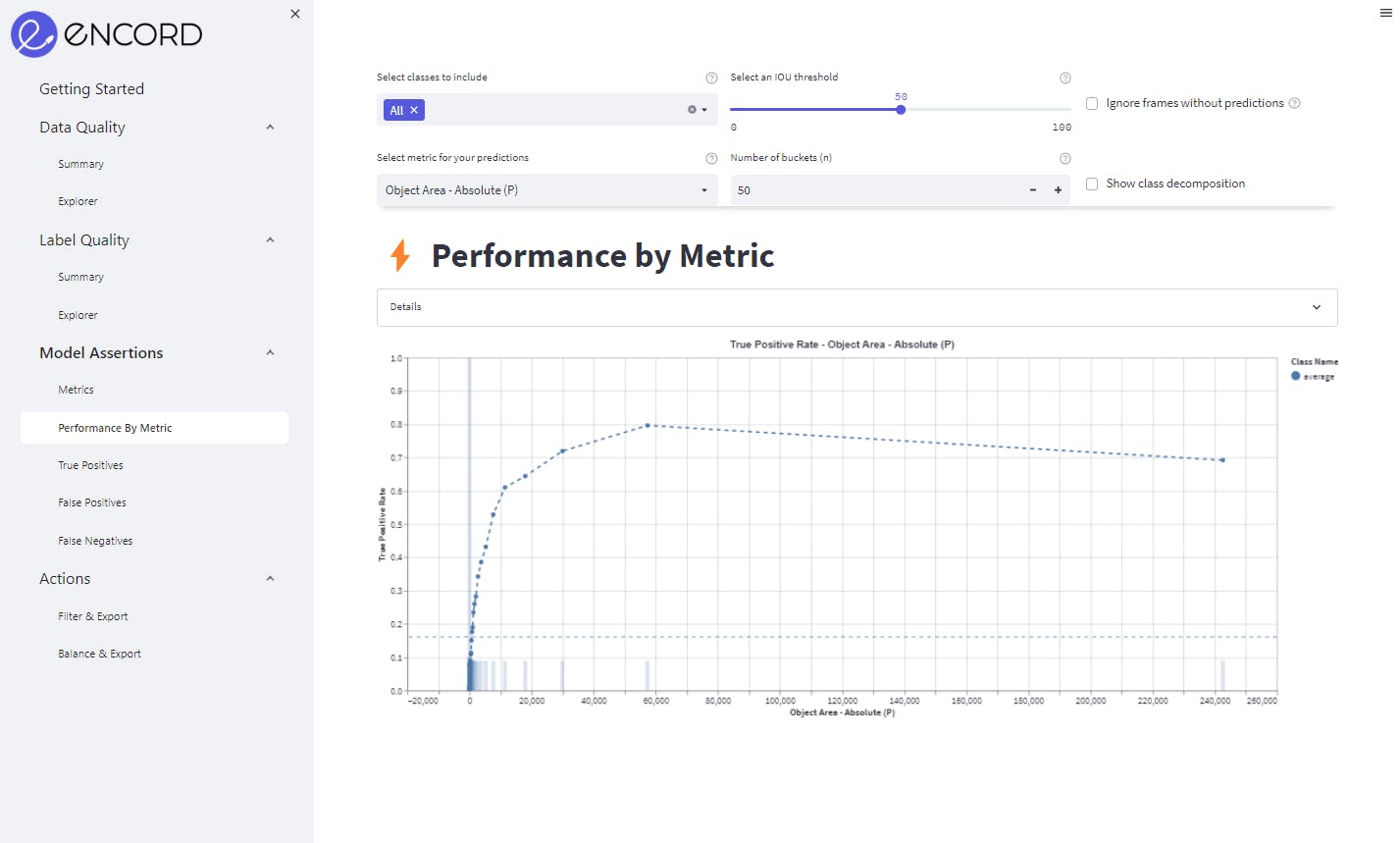
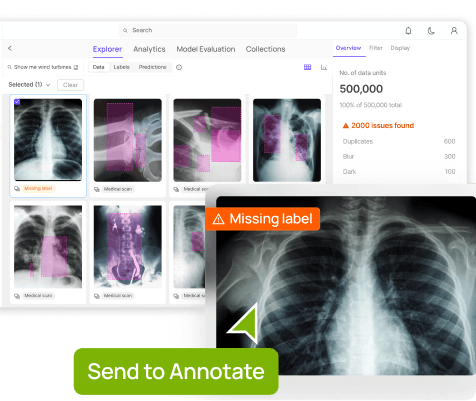
Reviewing model performance within Encord
Next Steps For Building a Computer Vision Machine Learning Model Startup
Once a machine learning model is trained, tested, validated, and benchmarked, then you’ve got something you can take to market. Especially if this model and the datasets you’ve used are from commercial partners, and the use case has been developed working with the types of organizations you want to win as clients.
That is, by far, the most effective way to test a computer vision model. As it demonstrates the commercial viability and usefulness of the model you’ve developed with a proof of concept created with a business objective at the center. It shows the model works and solves the problems it was intended to solve, making it more commercially viable and investable than if you developed it without commercial support.
And there we go . . . we hope you’ve found this helpful, especially if you’re considering launching your own computer vision startup!
Experience Encord in action. Dramatically reduce manual video and image annotation tasks, generating massive savings and efficiencies. Try it for free today.
Data infrastructure for multimodal AI
Click around the platform to see the product in action.
Written by

Ulrik Stig Hansen
Explore our products
Index
Manage & curate your data
Understand and manage your visual data, prioritize data for labeling, and initiate active learning pipelines.
Annotate
Supporting your labeling needs
Super charge your data annotation with AI-powered labeling — including automated interpolation, object detection and ML-based quality control.
Active
Find & fix data issues with ease
Monitor, troubleshoot, and evaluate the data and labels impacting model performance.