Meta-Transformer: Framework for Multimodal Learning

The human brain seamlessly processes different sensory inputs to form a unified understanding of the world. Replicating this ability in artificial intelligence is a challenging task, as each modality (e.g. images, natural language, point clouds, audio spectrograms, etc) presents unique data patterns.
But now, a novel solution has been proposed: Meta-Transformer.
No, it’s not a new Transformers movie!

And, no, it’s not by Meta!
The Meta-Transformer framework was jointly developed by the Multimedia Lab at The Chinese University of Hong Kong and the OpenGVLab at Shanghai AI Laboratory.
This cutting-edge framework is the first of its kind, capable of simultaneously encoding data from a dozen modalities using the same set of parameters. From images to time-series data, Meta-Transformer efficiently handles diverse types of information, presenting a promising future for unified multimodal intelligence.
Let's analyze the framework of Meta-Transformer in detail to break down how it achieves multimodal learning.
Meta-Transformer: Framework
The Meta-Transformer is built upon the transformer architecture. The core of the Meta-Transformer is a large unified multimodal model that generates semantic embeddings for input from any supported modality.
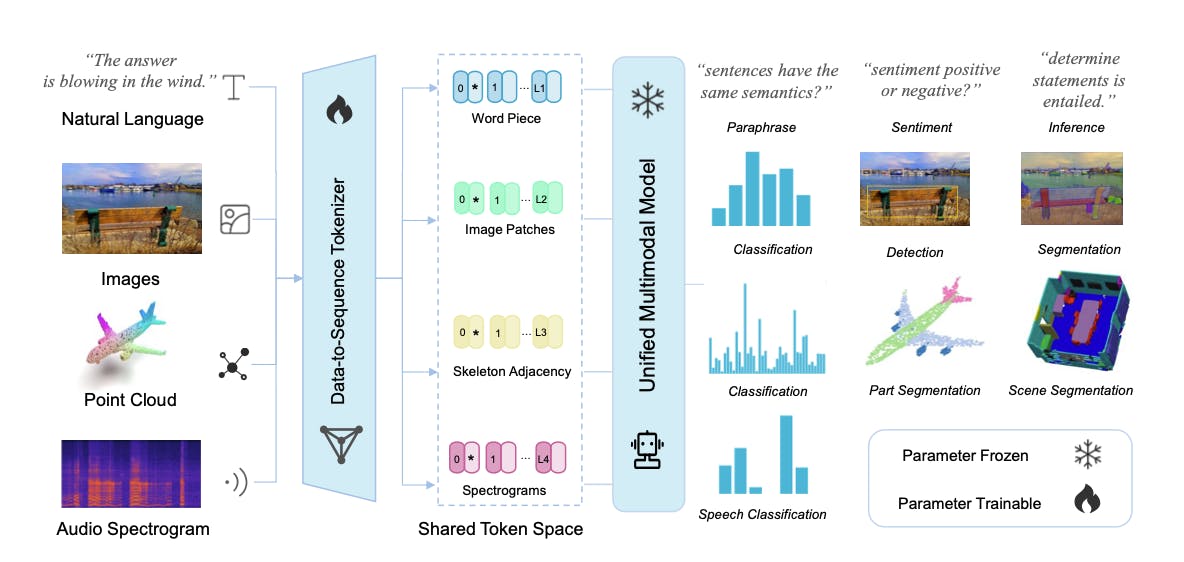
Meta-Transformer: A Unified Framework for Multimodal Learning
These embeddings capture the meaning of the input data and are then used by smaller task-specific models for various downstream tasks like text understanding, image classification, and audio recognition.
The Meta-Transformer consists of three key components: a data-to-sequence tokenizer that converts data into a common embedding space, a unified feature encoder responsible for encoding embeddings from various modalities, and task-specific heads used for making predictions in downstream tasks.
Data-to-Sequence Tokenization
Data-to-sequence tokenization is a process in the Meta-Transformer framework where data from different modalities (e.g. text, images, audio, etc.) is transformed into sequences of tokens. Each modality has a specialized tokenizer that converts the raw data into token embeddings within a shared manifold space. This facilitates the transformation of input data into a format that can be processed by the Transformer, allowing the Meta-Transformer to efficiently process and integrate diverse data types, and enabling it to perform well in multimodal learning tasks.
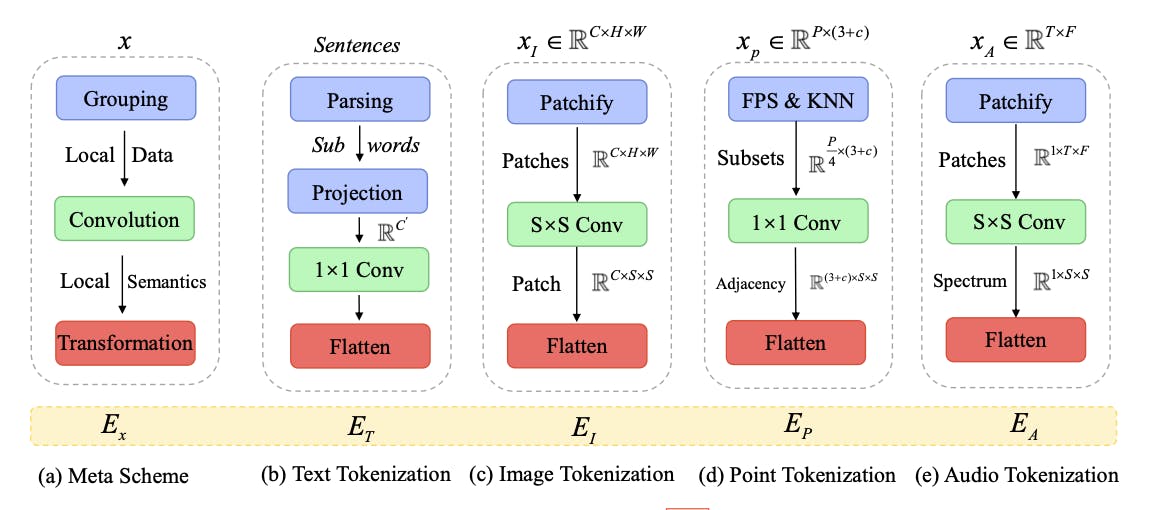
Meta-Transformer: A Unified Framework for Multimodal Learning
Natural Language
For processing text input, the authors use a popular method in NLP for tokenization called WordPiece embedding. In WordPiece, original words are broken down into subwords. Each subword is then mapped to a corresponding token in the vocabulary, creating a sequence of tokens that form the input text. These tokens are then projected into a high-dimensional feature space using word embedding layers.
Images
To process 2D images, the input images are reshaped into flattened 2D patches, and a projection layer converts the embedding dimension. The same operation applies to infrared images, whereas hyperspectral images use linear projection. The video inputs are also converted to 2D convolutions from 3D convolutions.
Point Cloud
To apply transformers to 3D patterns in point clouds, the raw input space is converted to a token embedding space. Farthest Point Sampling (FPS) is used to create a representative skeleton of the point cloud with a fixed sampling ratio. Next, K-Nearest Neighbor (KNN) is used to group neighboring points. These grouped sets with local geometric priors help construct an adjacency matrix. This contains comprehensive structural information on the 3D objects and scenes. These are then aggregated to generate point embeddings.
Audio Spectrogram
The audio spectrogram is pre-processed using log Mel filterback for a fixed duration. After that, a humming window is applied to split the waveform into intervals on the frequency scale. Next, This spectrogram is divided into patches with overlapping audio patches on the spectrogram. Finally, the whole spectrogram is further split and these patches are flattened into token sequences.

Unified Feature Encoder
The primary function of the Unified Feature Encoder is to encode sequences of token embeddings from different modalities into a unified representation that effectively captures essential information from each modality.
To achieve this, the encoder goes through a series of steps. It starts with pretraining a Vision Transformer (ViT) as the backbone network on the LAION-2B dataset using contrastive learning. This pretraining phase reinforces the ViT's ability to encode token embeddings efficiently and establishes a strong foundation for subsequent processing. For text comprehension, a pre-trained text tokenizer from CLIP is used, segmenting sentences into subwords and converting them into word embeddings.
Once the pretraining is complete, the parameters of the ViT backbone are frozen to ensure stability during further operations. To enable modality-agnostic learning, a learnable token is introduced at the beginning of the sequence of token embeddings. This token is pivotal as it produces the final hidden state, serving as the summary representation of the input sequence. This summary representation is commonly used for recognition tasks in the multimodal framework.
The transformer encoder is employed in the next stage, and it plays a central role in unifying the feature encoding process. The encoder is composed of multiple stacked layers, with each layer comprising a combination of multi-head self-attention (MSA) and multi-layer perceptron (MLP) blocks. This process is repeated for a specified depth, allowing the encoder to capture essential relationships and patterns within the encoded representations.
Throughout the encoder, Layer Normalization (LN) is applied before each layer, and residual connections are employed after each layer, contributing to the stability and efficiency of the feature encoding process.
 💡For more insight on contrastive learning, read the Full Guide to Contrastive Learning.
💡For more insight on contrastive learning, read the Full Guide to Contrastive Learning. Task Specific Heads
In the Meta-Transformer framework, task-specific heads play a vital role in processing the learned representations from the unified feature encoder. These task-specific heads are essentially Multi-Layer Perceptrons (MLPs) designed to handle specific tasks and different modalities. They serve as the final processing units in the Meta-Transformer, tailoring the model's outputs for various tasks.
💡Read the paper Meta-Transformer: A Unified Framework for Multimodal Learning. Meta-Transformer: Experiments
The performance of the Meta-Transformer was thoroughly evaluated across various tasks and datasets, spanning 12 different modalities. What sets the framework apart is its ability to achieve impressive results without relying on a pre-trained large language model, which is commonly used in many state-of-the-art models. This demonstrates the Meta-Transformer's strength in independently processing multimodal data. Furthermore, the model benefits from a fine-tuning process during end-task training, which leads to further improvements in model performance. Through fine-tuning, the unified multimodal model can adapt and specialize for specific tasks, making it highly effective in handling diverse data formats and modalities.

Meta-Transformer: A Unified Framework for Multimodal Learning
In the evaluation, the Meta-Transformer stands out by outperforming ImageBind, a model developed by Meta AI that can handle some of the same modalities. This showcases the effectiveness and superiority of the Meta-Transformer in comparison to existing models, particularly in scenarios where diverse data formats and modalities need to be processed.
💡 For more details on ImageBind, read ImageBind MultiJoint Embedding Model from Meta Explained Let’s dive into the experiment and results of different modalities.
Natural Language Understanding Results
The Natural Language Understanding (NLU) results of the Meta-Transformer are evaluated on the General Language Understanding Evaluation (GLUE) benchmark, encompassing various datasets covering a wide range of language understanding tasks. When employing frozen parameters pre-trained on images, the Meta-Transformer-B16F achieves competitive scores. And after fine-tuning, the Meta-Transformer-B16T exhibits improved performance.
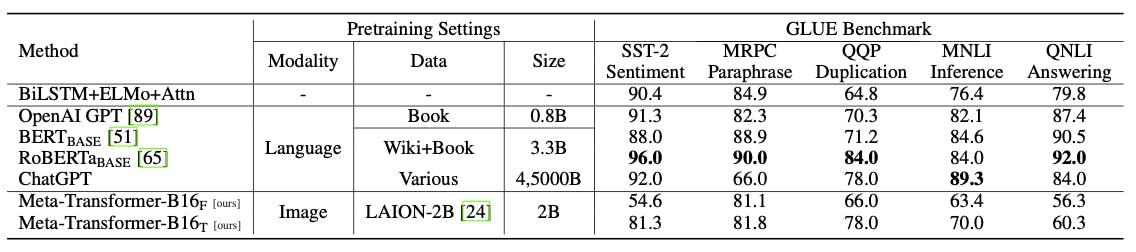
Meta-Transformer: A Unified Framework for Multimodal Learning
The Meta-Transformer doesn’t surpass the performance of BERT, RoBERTa, or ChatGPT on the GLUE benchmark.
Image Understanding Results
In image classification on the ImageNet-1K dataset, the Meta-Transformer achieves remarkable accuracy with both the frozen and fine-tuned models. With the assistance of the CLIP text encoder, the zero-shot classification is particularly impressive.
The Meta-Transformer exhibits excellent performance in object detection and semantic segmentation, further confirming its versatility and effectiveness in image understanding.
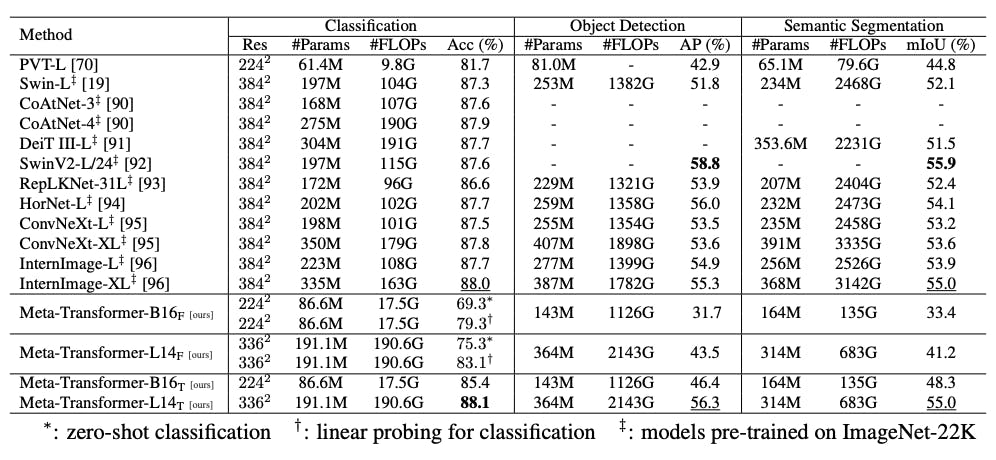
Meta-Transformer: A Unified Framework for Multimodal Learning
The Swin Transformer outperforms the Meta-Transformer in both object detection and semantic segmentation. The Meta-Transformer demonstrates competitive performance.
3D Point Cloud Understanding Results
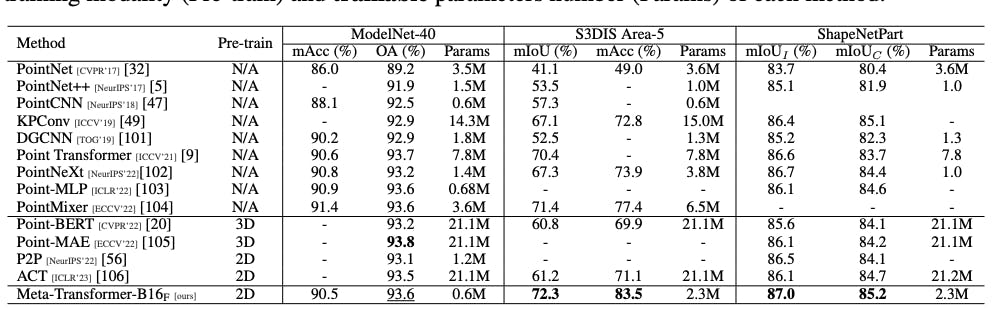
Meta-Transformer: A Unified Framework for Multimodal Learning
The Point Cloud Understanding results of the Meta-Transformer are assessed on the ModelNet-40, S3DIS, and ShapeNetPart datasets. When pre-trained on 2D data, it achieves competitive accuracy on the ModelNet-40 dataset and outperforms other methods on the S3DIS and ShapeNetPart datasets, achieving high mean IoU and accuracy scores with relatively fewer trainable parameters. The Meta-Transformer proves to be a powerful and efficient model for point cloud understanding, showcasing advantages over other state-of-the-art methods.
Infrared, Hyperspectral, and X-Ray Results
The Meta-Transformer demonstrates competitive performance in infrared, hyperspectral, and X-Ray data recognition tasks. In infrared image recognition, it achieves a Rank-1 accuracy of 73.50% and an mAP of 65.19% on the RegDB dataset. For hyperspectral image recognition on the Indian Pine dataset, it exhibits promising results with significantly fewer trainable parameters compared to other methods.

Meta-Transformer: A Unified Framework for Multimodal Learning
In X-Ray image recognition, the Meta-Transformer achieves a competitive accuracy of 94.1%.

Meta-Transformer: A Unified Framework for Multimodal Learning
Audio Recognition Results
In audio recognition using the Speech Commands V2 dataset, the Meta-Transformer-B32 model achieves an accuracy of 78.3% with frozen parameters and 97.0% when tuning the parameters, outperforming existing audio transformer series such as AST and SSAST.
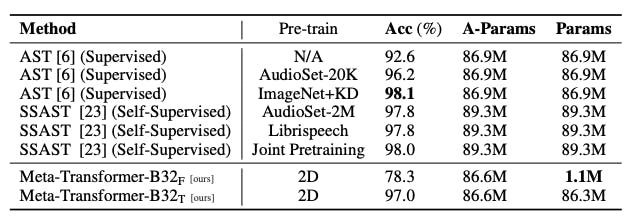
Meta-Transformer: A Unified Framework for Multimodal Learning
Video Recognition Results
In video recognition on the UCF101 dataset, the Meta-Transformer achieves an accuracy of 46.6%. Although it doesn't surpass other state-of-the-art video understanding models, the Meta-Transformer stands out for its significantly reduced trainable parameter count of 1.1 million compared to around 86.9 million parameters in other methods. This suggests the potential benefit of unified multi-modal learning and less architectural complexity in video understanding tasks.
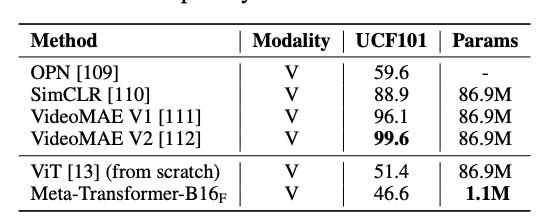
Meta-Transformer: A Unified Framework for Multimodal Learning
Time-series Forecasting Results
In time-series forecasting, the Meta-Transformer outperforms existing methods on benchmarks like ETTh1, Traffic, Weather, and Exchange datasets. Despite using very few trainable parameters, it surpasses Informer and even Pyraformer with only 2M trained parameters. These results highlight the potential of Meta-Transformers for time-series forecasting tasks, offering promising opportunities for advancements in this area.
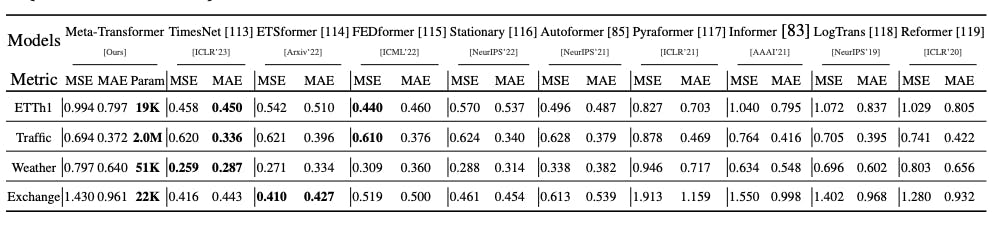
Meta-Transformer: A Unified Framework for Multimodal Learning
Tabular Data Understanding Results
In tabular data understanding, the Meta-Transformer shows competitive performance on the Adult Census dataset and outperforms other methods on the Bank Marketing dataset in terms of accuracy and F1 scores. These results indicate that the Meta-Transformer is advantageous for tabular data understanding, particularly on complex datasets like Bank Marketing.

Meta-Transformer: A Unified Framework for Multimodal Learning
Graph and IMU Data Understanding Results
In graph understanding, the performance of the Meta-Transformer on the PCQM4M-LSC dataset is compared to various graph neural network models. While Graphormer shows the best performance with the lowest MAE scores, Meta-Transformer-B16F achieves higher MAE scores, indicating its limited ability for structural data learning.
For IMU sensor classification on the Ego4D dataset, Meta-Transformer achieves an accuracy of 73.9%.

Meta-Transformer: A Unified Framework for Multimodal Learning
However, there is room for improvement in the Meta-Transformer architecture for better performance in graph understanding tasks.
💡 Find the code on GitHub. Meta-Transformer: Limitations
The Meta-Transformer has some limitations. Its complexity leads to high memory costs and a heavy computation burden, making it challenging to scale up for larger datasets. The O(n^2 × D) computation required for token embeddings [E1, · · ·, En] adds to the computational overhead.
In terms of methodology, Meta-Transformer lacks temporal and structural awareness compared to models like TimeSformer and Graphormer, which incorporate specific attention mechanisms for handling temporal and structural dependencies. This limitation may impact its performance in tasks where understanding temporal sequences or structural patterns is crucial, such as video understanding, visual tracking, or social network prediction.
While the Meta-Transformer excels in multimodal perception tasks, its capability for cross-modal generation remains uncertain. Generating data across different modalities may require additional modifications or advancements in the architecture to achieve satisfactory results.
Meta-Transformer: Conclusion
In conclusion, Meta-Transformer is a unified framework for multimodal learning, showcasing its potential to process and understand information from various data modalities such as texts, images, point clouds, audio, and more. The paper highlights the promising trend of developing unified multimodal intelligence with a transformer backbone, while also recognizing the continued significance of convolutional and recurrent networks in data tokenization and representation projection.
The findings in this paper open new avenues for building more sophisticated and comprehensive AI models capable of processing and understanding information across different modalities. This progress holds tremendous potential for advancing AI's capabilities and solving real-world challenges in fields like natural language processing, computer vision, audio analysis, and beyond. As AI continues to evolve, the integration of diverse neural networks is set to play a crucial role in shaping the future of intelligent systems.
Frequently asked questions
Yes, Encord allows users to import custom metadata, providing great flexibility in how data is managed. Users can define their own metadata sets, enabling tailored sorting and filtering based on specific project needs.
Encord allows users to set a metadata schema that is associated with each dataset during the upload process. This ensures that all relevant information is organized and easily accessible.