Everything You Need to Know About RAG Pipelines for Smarter AI Models

Co-Founder & CEO at Encord
AI has come a long way in terms of how we interact with it. However, even the most advanced large language models (LLMs) have their limitations - ranging from outdated knowledge to hallucinations.
Enter Retrieval Augmented Generation (RAG) pipelines - a method to build more reliable AI systems.
RAG bridges the gap between generative AI and real-world knowledge by combining two powerful elements: retrieval and generation. This helps the models to fetch relevant and up-to-date information from external sources and integrate it to their outputs.
Whether it’s answering real-time queries or improving decision-making, RAG pipelines are quickly becoming essential for building intelligent AI applications like chatbots.
This guide explores RAG pipelines, starting from its fundamentals to implementation details. By the end, you’ll have a clear understanding of how to develop smarter AI models using RAG and how Encord can help you get there.
What are Retrieval Augmented Generation (RAG) Pipelines?
RAG pipelines combine information retrieval with language generation to build reliable and adaptable AI systems. Unlike traditional LLMs which solely rely on pretraining, RAG pipeline improves the LLM’s generative capabilities by integrating real-time information from external sources.

How RAG Works?
The pipeline operates in two main stages:
- Retrieval: The model sources relevant data from an external knowledge base.
- Generation: The retrieved data is then used as context to generate responses.
Key Components of RAG Pipelines
- Knowledge Retrieval System: This could be a vector database like FAISS, Pinecone or a search engine designed to find the most relevant data based on user queries.
- Generative Model: Models like OpenAI’s GPT-4, Anthropic’s Claude Sonnet, or Meta AI’s Llama 3 or open-source models like Google’s Gemini are used to generate human-like responses by combining the retrieved knowledge with the user’s input.
Why does RAG Matter?
Traditional LLMs struggle with outdated or irrelevant information, leading to unreliable outputs. RAG solves this by enabling models to:
- Incorporate real-time knowledge for dynamic applications like news reporting or customer support.
- Curate responses based on domain-specific knowledge, improving accuracy for niche industries like legal, healthcare, or finance.
Benefits of RAG Applications
- Better Accuracy: By using external knowledge bases, it reduces the chances of hallucinations and inaccuracies.
- Scalability for Domain specific Applications: These pipelines make the LLMs adaptable to any industries. It depends on the type of knowledge base used. From generating legal opinions based on cases to helping in medical research, RAG can be tailored to meet the needs of specific use cases.
- Easy to Adapt: RAG pipelines can easily integrate with various knowledge sources, including private datasets, public APIs, and even unstructured data, allowing organizations to adapt to changing requirements without retraining their models.
- Cost Efficient: Rather than retraining an entire model, RAG pipelines rely on data retrieval to access external data. This reduces the need for expensive compute resources and shortens the development cycle.
Alternatives to RAG Systems
Other than RAG, there are other methods used to improve LLM’s outputs. Here are a few methods that are commonly used and how RAG compares to them.
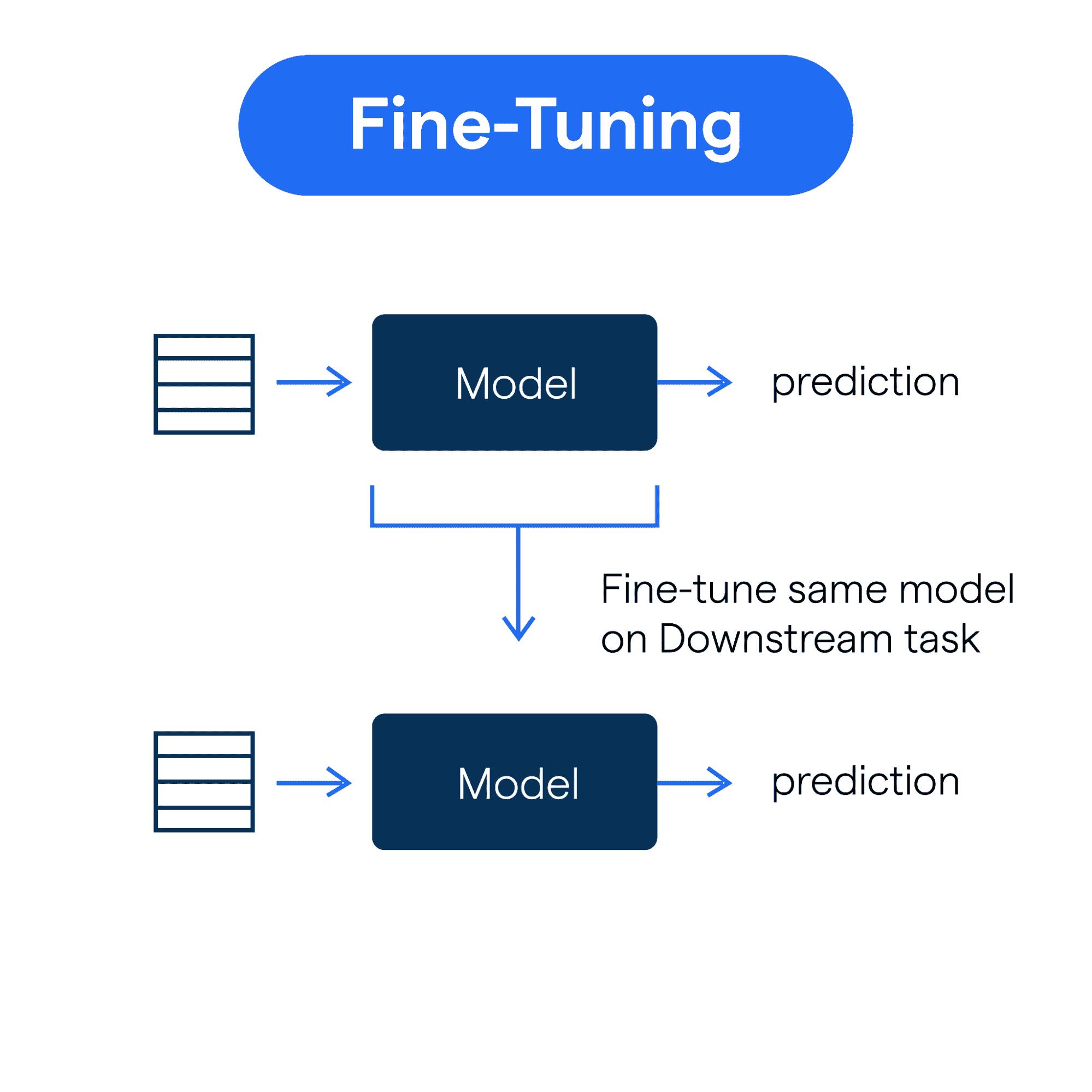
RAG vs Fine Tuning
In fine-tuning, the LLM’s parameters are retrained with curated training data, to create a model tailored to a specific domain or task. However, this requires significant computational resources and does not adapt to new information without further retraining.
RAG vs Semantic Search
Here, in semantic search, relevant documents or information is retrieved based on the contextual meaning or the query. But this information is not used further to generate new content. Whereas, RAG retrieves and uses it to generate informative and contextual outputs.
RAG vs Prompt Engineering
The prompt inputs are planned and designed in order to get desired responses from LLMs without any changes to the model. This method may work well if you are using large-scale LLMs trained on huge training datasets, still there are higher chances of inaccuracies or hallucinated information.
RAG vs Pretraining
Pretraining equips a model with general-purpose factual knowledge. While effective for broad tasks, pretrained models can fail in dynamic or rapidly changing domains. Whereas, RAG models have dynamic updates and provide contextually relevant responses.
Building Blocks of RAG Pipelines
RAG pipelines rely on two interconnected components: retrieval and generation. Each stage has specific responsibilities, tools, and design considerations that ensure the pipeline delivers accurate results.
Stage 1: Retrieval
The information retrieval stage is the backbone of the RAG pipeline, responsible for sourcing relevant information from external data sources or databases. The retrieved information serves as the contextual input for the generative model.
Key Process
- Understanding Query: The input query is encoded into a vector representation. This vector is then used for semantic matching with stored knowledge embeddings.
- Knowledge Retrieval: The relevant data is fetched by comparing the query vector with precomputed embeddings in a vector database or search index.
Methodologies and Tools Used
- Vector Databases: Tools like FAISS, Pinecone, and Weaviate store and retrieve high-dimensional vector embeddings. These systems enable fast, scalable similarity searches, which are useful for handling large datasets.
- Search Engines: ElasticSearch or OpenSearch are commonly used for text based retrieval in indexed databases. These search engines prioritize relevance and speed.
- APIs and External Sources: Integrations with external APIs or proprietary knowledge bases allow dynamic retrieval of information (e.g., live data feeds for news or weather).
Design Considerations
- Dataset Quality: Retrieval systems are only as effective as the quality of the datasets they work with. High-quality, annotated data ensures the retrieval process delivers contextually accurate results.
- Indexing Efficiency: Properly structured indexing reduces latency, especially in applications requiring real-time responses.
- Domain-Specific Embeddings: Using embeddings tailored to the domain improves data retrieval precision.
Key Challenges in Retrieval
Here are some of the key challenges in the retrieval stage of the RAG pipeline:
- Ambiguity in user queries may lead to irrelevant or incomplete data retrievals.
- Stale data in static data sources can affect the accuracy of outputs. It is essential to choose a well maintained database.
- Managing retrieval latency while ensuring relevance remains a technical hurdle. This can be managed by using search engines matching the need of the project.
Stage 2: Generation
The generation stage uses the retrieved data from the earlier stage to generate contextually aligned responses. This stage integrates user input with retrieved knowledge to improve the generative capabilities of the model.
Key Process
- Input Processing: The generative model takes both the user query and retrieved data as inputs, and uses them to generate coherent outputs.
- Response Generation: LLMs like GPT-4o or Llama 3 process the inputs and generate text responses tailored to the query.
Methodologies and Tools Used
- Generative Models: Pretrained models serve as the foundation for generating human-like text. The retrieved data provides additional context for improved relevance.
- Prompt Engineering: The prompt inputs are designed to ensure that the retrieved knowledge is appropriately incorporated into the output response.
Key Challenges in Generation
- Merging the retrieved information with user queries can result in overly verbose or irrelevant outputs.
- Handling cases where no relevant data is retrieved requires fallback mechanisms to maintain trust in the responses.
Building Effective RAG Systems
RAG systems rely on high quality data curation, efficient embedding storage, and a reliable data retrieval system to generate relevant output. Here are the important steps in building an effective RAG pipeline:
Data Curation
The foundation of any RAG pipeline begins with data preparation and curation. Using platforms like Encord which is designed for data centric approaches helps in streamlining this process. It helps in shifting from traditional LLMS to RAG pipeline but streamlining the process of transforming raw data into structures, ready-to-use knowledge bases.
Document Processing
Encord provides automated tools for parsing and structuring documents, regardless of the format. Whether working with PDFs, HTML files, or plain text, the platform ensures the data is uniformly processed.
Content Chunking
Once the documents are processed, it is divided into manageable chunks. These chunks are sized to optimize embedding generation and retrieval accuracy, balancing granularity with contextual preservation. Context-aware chunking ensures that essential relationships within the data are retained, improving downstream performance.
Embedding Generation and Storage
The next step is creating embeddings of the curated data. These embeddings serve as the basis for similarity search and retrieval in the RAG pipeline. These embeddings are stored in vector databases such as FAISS, Pinecone, or Weaviate. These tools ensure that the embeddings are indexed efficiently, enabling fast, scalable retrieval during real-time queries.
Retrieval System Implementation
The information retrieval system is the bridge between the user query and the external knowledge base, ensuring relevant information is delivered to the generative model. The system uses similarity search algorithms to match queries with stored embeddings. For cases needing both keyword precision and contextual understanding, hybrid retrieval approaches combine lexical and semantic search techniques.
Context aware ranking systems then refine the retrieval process of the indexed data. By considering query intent, metadata, and feedback loops, these systems aim the most relevant results. This ensures the generative model receives high-quality inputs, even for complex or ambiguous queries.
Common Pitfalls and How to Avoid Them
While RAG pipelines are efficient, there are key challenges aswell that can affect their effectiveness. Identifying these pitfalls and implementing strategies to avoid them can help build reliable systems.
Poor Data Quality
Low-quality or poorly structured data can lead to irrelevant retrieval and reduce output accuracy. This includes outdated information, incomplete metadata, and unstructured documents.
Solution
Ensure proper data preprocessing, including automated structuring, cleaning, and add metadata. Use platforms like Encord to curate high-quality datasets.
Inefficient Retrieval Systems
A poorly implemented retrieval system may return irrelevant or redundant results, slowing down responses and affecting accuracy.
Solution
Research and try different retrieval techniques to find one apt for the project, such as hybrid retrieval approaches and optimized vector search algorithms, to improve relevance and reduce latency.
Inconsistent Chunking
Chunking content into inappropriate sizes can lead to loss of context or redundant retrieval, negatively impacting the generative stage.
Solution
Use chunking algorithms that preserve the context to balance granularity, ensuring each chunk captures meaningful data.
Embedding Overhead
Using generic embeddings or failing to optimize them for the domain can result in suboptimal retrieval accuracy.
Solution
Use domain-specific embeddings and train models on relevant datasets to improve retrieval precision.
Scalability Bottlenecks
As knowledge bases grow, retrieval systems may struggle with latency and indexing inefficiencies.
Solution
Adopt scalable vector databases and ensure periodic optimization of indexes to handle large-scale data effectively.
Best Practices for RAG Pipeline Development
Here are some key recommendations:
- Data Quality: Prioritize preprocessing and data curation. Make sure the data is annotated, and the data is curated from relevant and up-to-date sources. The databases should be updated constantly.
- Optimize Embeddings for Your Domain: Use embedding models tailored to the target domain. For instance, healthcare applications may require embeddings trained on medical literature to improve retrieval precision.
- Use Hybrid Retrieval Systems: Combine lexical search with semantic search to balance exact matches with contextual understanding. Hybrid retrieval ensures robust handling of diverse query types.
- Monitor and Improve Continuously: Establish feedback loops to monitor pipeline performance. Monitor the performance with evaluation metrics and use these insights to refine data quality, improve ranking systems, and adjust retrieval algorithms.
- Ensure Scalability: Design the RAG pipeline to handle increasing data volumes. Choose scalable storage and retrieval systems and regularly optimize indices for performance.
- Use Intelligent Chunking: Use algorithms that segment content effectively, preserving context while optimizing chunk size for retrieval and generation stages.
Using Encord in RAG Applications
Encord is a comprehensive data platform designed to simplify dataset management, data curation, annotation, and evaluation. It helps you handle complex data workflows effectively.
How Encord Helps in Creating RAG Systems
- Data Curation for Retrieval Systems: Encord supports the creation of high-quality datasets required for accurate knowledge retrieval. Encord supports multimodal data and provides features to create automated annotation workflows to ensure consistent quality of the curated data.
- Annotation for Fine-Tuning and Generation: Encord Annotate allows teams to annotate datasets tailored for specific use cases, ensuring the generative model has contextually relevant inputs. It provides a visual metric to assess the quality of the annotated data.
- Feedback Loops: Encord enables continuous dataset refinement by incorporating user feedback into the pipeline. It provides features to continuously monitor the performance of the model and quality metrics to identify the failure modes and issues in the model.
Conclusion
Retrieval-Augmented Generation is a powerful framework for improving AI systems with real-time, contextually relevant data. By combining retrieval and generation, RAG pipelines enable AI models to overcome the limitations of static knowledge, making them better suited for dynamic, information-rich tasks.
RAG systems have applications across diverse fields, including GenAI-powered chatbots for real-time customer support, personalized education platforms that improve user experience, legal research tools for efficient question-answering, and dynamic content generation systems.
By understanding the building blocks, common pitfalls, and best practices for RAG pipelines, you can unlock the full potential of this approach, creating smarter, more reliable AI solutions tailored to your needs.
Frequently asked questions
RAG (Retrieval-Augmented Generation) pipelines combine information retrieval with language generation to build more accurate and adaptable AI systems. They help models fetch relevant data from external sources and use it to produce contextually informed outputs.
RAG pipelines operate in two key stages:
Retrieval: Fetches relevant data from external sources, like vector databases or APIs.
Generation: Uses this retrieved data to create contextually aligned responses.
Improved Accuracy: Reduces hallucinations by incorporating real-time data.
Scalability: Adaptable to specific industries like healthcare or legal.
Cost-Efficiency: Eliminates the need for frequent model retraining.
Flexibility: Integrates with various knowledge sources, including private datasets and APIs.
Real-time customer support through intelligent chatbots.
Personalized educational platforms.
Legal and medical research tools.
Dynamic content generation for media and publishing.
Yes, Encord can integrate with existing pipelines to provide a centralized user interface for data orchestration. This integration helps streamline processes by tying together different data sources and automating workflows, making it easier to manage data throughout the annotation lifecycle.
Encord provides a range of features that automate data pipeline processes, including data ingestion, label management, and export functionalities. These tools streamline the workflow, making it easier to manage large datasets and integrate them into your machine learning models effectively.
Encord offers a powerful SDK that helps users build and manage data pipelines around the annotation process. This feature ensures that data flows smoothly through the pipeline, facilitating a seamless integration with existing systems and enhancing productivity.
Yes, Encord is designed to integrate seamlessly with existing data architectures and pipelines. Our solutions team works closely with clients to ensure smooth data integration, providing assistance tailored to each organization's unique requirements.
Encord offers seamless integration with ML operations pipelines, ensuring that data annotation and management processes align smoothly with your existing workflows. This integration helps streamline operations and enhances overall efficiency.
Encord offers full SDK support for building data pipelines, allowing users to automate pipeline setups and perform programmatic operations. This flexibility enables users to create custom workflows tailored to their specific project needs.