6 Steps to Build Better Computer Vision Models

Computer vision is a branch of artificial intelligence that uses machine learning and deep learning algorithms to teach machines how to see, recognize, and interpret objects in images and videos like humans. It focuses on replicating aspects of the human visual system's complexity and enabling computers to detect and analyze items in photos and videos in the same way that humans do.
Computer vision has made considerable strides in recent years, surpassing humans in various tasks linked to object detection, thanks to breakthroughs in artificial intelligence and innovations in deep learning and neural networks. The amount of data we generate today, which is subsequently utilized to train and improve computer vision, is one of the driving factors behind the evolution of computer vision.
In this article, we will start by looking at how computer vision models are used in the real world, to understand why we need to build better computer vision models. Then we will outline six different ways you can improve your computer vision models by improving how you handle your data. But first, let’s briefly discuss the difference between computer vision and machine learning models.
How are computer vision models different from machine learning models?
Machine learning is a method for enabling computers to learn how to analyze and respond to data inputs, based on precedents established by prior actions. For example, using a paragraph of text to teach an algorithm how to assess the tone of the writer would fall broadly under machine learning. The input data can be many forms in machine learning models: text, images, etc.
Computer vision models are a subset of machine learning models, where the input data is specifically visual data – with computer vision models, the goal is to teach computers how to recognize patterns in visual data in the same manner as people do. So for example, an algorithm that uses images and videos as input to predict results (eg. the cat and dog classifier), is specifically a computer vision model.
Computer vision is becoming increasingly used for automated inspection, remote monitoring, and automation of a process or activity. It has quickly found its application across multiple industries and has become an essential component of technical advancement and digital transformation. Let’s briefly look at a few examples of how computer vision has made its way into the real-world.
Real-time applications of computer vision models
Computer vision is having a massive impact on companies across industries, from healthcare to retail, security, automotive, logistics, manufacturing and agriculture. So, let’s have a look at a few of them:
Healthcare
One of the most valuable sources of information is medical imaging data. However, there is a catch: without the right technology, physicians are required to spend hours manually evaluating patients' data and performing administrative tasks. Thanks to recent advancements in computer vision, the healthcare industry has adopted automation solutions to make things easier. Medical imaging greatly benefits from image classification and object detection, as they offer physicians second opinions and aid in flagging concerning areas in an image. For example, in analyzing CT (computerized tomography) and MRI (magnetic resonance imaging) scans.
Computer vision also plays a key role in improving patient outcomes, from building machine learning models to evaluate radiological images with the same level of accuracy as human doctors (while lowering disease detection time), to building deep learning algorithms that boost the resolution of MRI scans. The analysis made by the models helps doctors detect tumors, internal bleeding, clogged blood vessels, and other life threatening conditions. The automation process has also shown to improve accuracy, as machines can now recognize details that are invisible to the human eye. Cancer detection, digital pathology, X-Ray and movement analysis are some other examples of the uses of computer vision in healthcare.
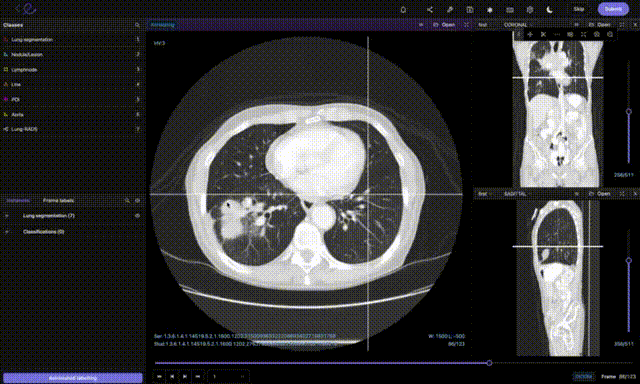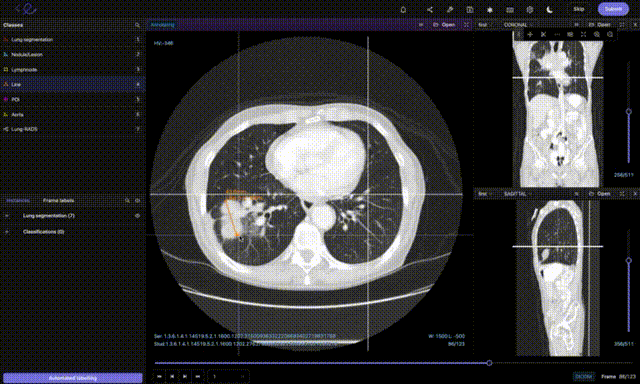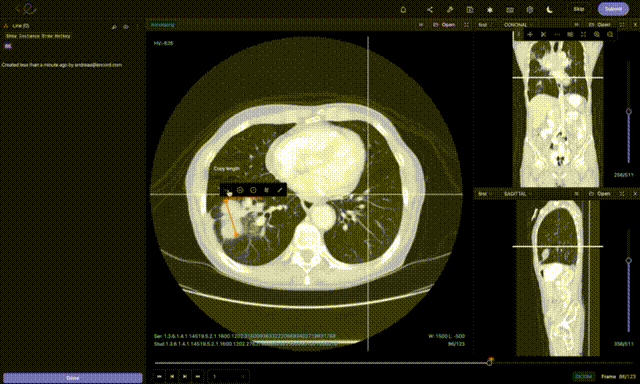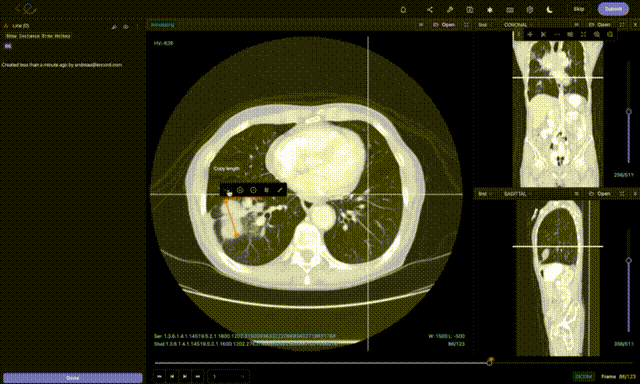
Annotating healthcare images in Encord
Automotive
The growing demand for transportation has accelerated technological development in the automotive industry, with computer vision at the forefront. Intelligent Transportation Systems has become a vital field for improving vehicle safety, parking efficiency and, more broadly, the potential applications of autonomous driving.
Self-driving cars are as difficult as they sound. But with computer vision, engineers are able to quickly build, test and improve the reliability of the cars, contributing to advancements across object detection and classification (e.g., road signs, pedestrians, traffic lights, other vehicles), motion prediction, and more.
In Parking Guidance and Information (PGI) systems, computer vision is already commonly utilized for visual parking lot occupancy detection, as it’s a cheaper alternative to more expensive sensor-based systems which require routine maintenance.
Computer vision models are not just useful in out-of-the-car applications, like parking guidance, traffic flow analysis, and road condition monitoring, but also in monitoring driver health and attentiveness, seat belt status, and more.
Manufacturing
Computer vision in the manufacturing industry helps in the automation of quality control, the reduction of safety risks, and the development of production efficiency.
An example of this is within defect inspection. The manual detection of defects in large-scale manufactured products is not only costly but also inaccurate: 100% accuracy cannot be guaranteed. Deep learning models can use cameras to analyze and identify macro and micro defects in the production line more efficiently, and in real-time.
Many companies leverage computer vision also to automate the product assembly line. Machine learning models can be used to guide robot and human work, identify and track product components, and help enforce packaging standards.
Apart from the industries that we discussed, computer vision is powering a multitude of other fields, especially those where image and video data can be leveraged to automate mundane tasks and achieve higher efficiency. With more and more companies adopting artificial intelligence, we can expect computer vision to be the driving force in many industries. Now, if you are a machine learning engineer, data scientist or a team working on building better computer vision models, here are six ways to improve your models and ensure you are building them efficiently.
Six ways to make your computer vision models better
Building a computer vision model is as difficult as its application makes things easier. It can take months and years to build production-ready solutions, and there is always room for improvement.
Choosing a dataset is the starting point when building a machine learning model, and the quality of the dataset will heavily impact the results you can achieve with the model. That’s why if the solution that you or your team worked on is not yielding the desired results, or if you want to improve them, you first need to shift your focus to your dataset.
Here are six ways to improve how you handle your dataset and build better computer vision models:
- Create a dataset with efficient labels
- Choose the right annotation tool
- Feature engineering
- Feature selection or dimensionality reduction
- Care about missing data
- Use data pipelines
1. Create a dataset with efficient labels
Data is an important component, and the results you can expect from your model performance are heavily dependent on the data you feed it. It’s tempting to jump start to the exciting stage of developing machine learning projects, and lose track of pre-defined data annotation requirements, dataset creation strategies, etc. You want to see the results right away, but skipping the first step will usually prevent you from building a robust model – instead leading to wasted time, energy and resources.
The raw curated data needs to be labeled effectively in order for the team to have a good labeled dataset, which should contain all the information that could be remotely useful to the project. This ensures the engineers are not restricted in model selection and building, since the type of information present in the training data will be defined. In order to get started the right way, it’s important to first pre-define the annotations that need to be extracted – this will not only provide clarity to the annotators, but also make sure the dataset is consistent. A strong baseline can be set to the project by building a dataset with efficient labels.
2. Choose the right annotation tool
It is crucial to use the right annotation tool while building your dataset, and the right tool will be one whose features align with your use case and goals. For example, if you are dealing with an image or a video dataset, you should choose an annotation tool that specializes in handling image or video respectively. It should contain features that will allow you to easily label your data, while maintaining the quality of the dataset.
For example, Encord’s video annotation capabilities are specific to, and optimized for, video annotations, allowing users to upload videos of any length and in a wide range of formats. With other tools, video annotators would need to first shorten their videos, and oftentimes switch over to different platforms based on the format of the video they want to annotate. This is an example of why finding the right annotation tool for your use case is key.
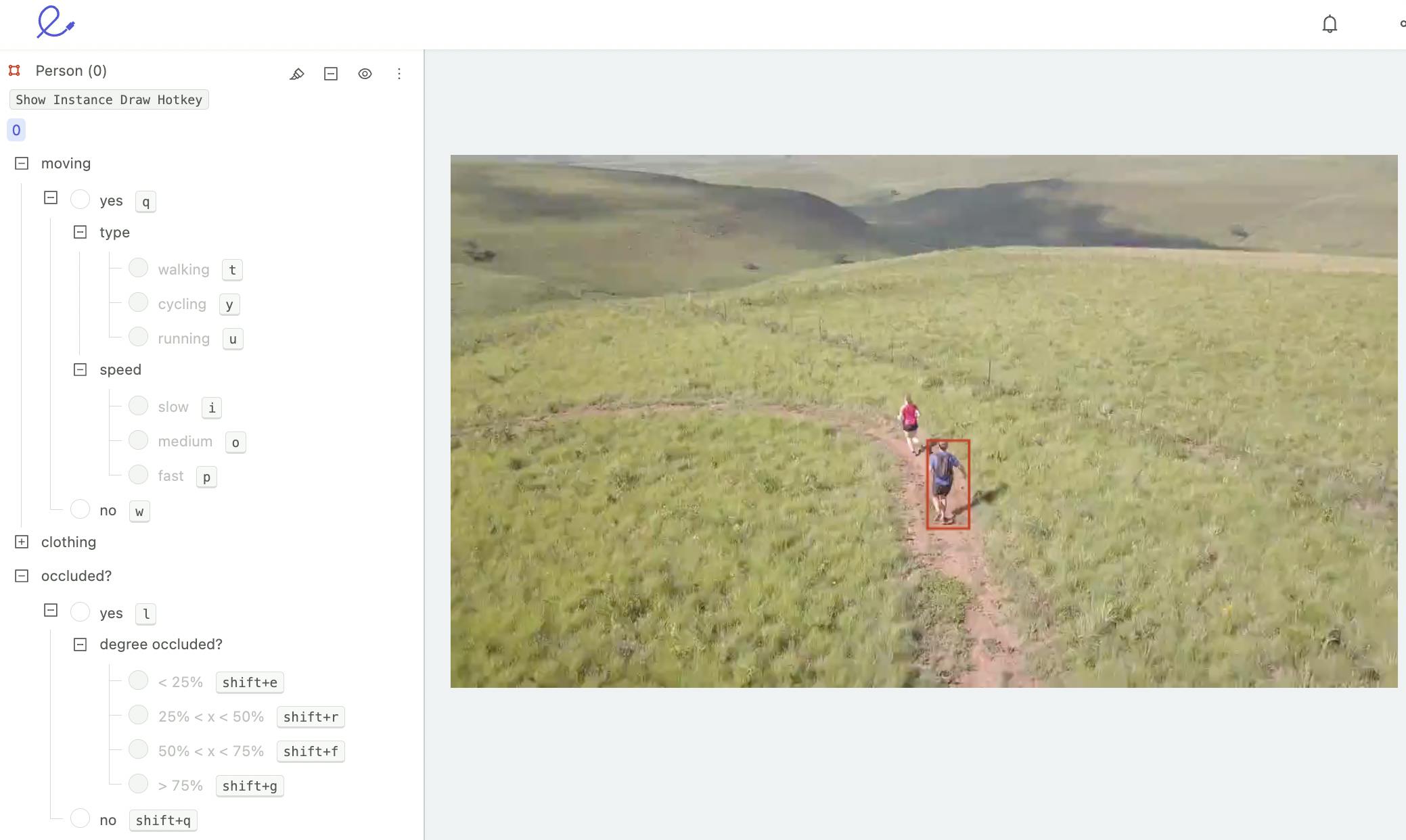
Video annotation in Encord
Similarly, users wanting to annotate images have switched over to Encord from other platforms to be able to stream the annotation directly to their data loaders: this helps make the process of image annotation more efficient, and saves hours of time that would otherwise need to be spent on less valuable parts of the development process.
3. Feature engineering
Features are the fundamental elements of datasets – computer vision models use the features from the dataset to learn, and the quality of the features in the dataset heavily determines the quality of the output of the machine learning algorithm.
Feature engineering is the process of selecting, manipulating, and transforming the dataset into features which can be used to build machine learning algorithms, like supervised learning. It is a broader term for data preprocessing and it entails techniques ranging from simple data cleaning, to transforming existing data in order to create new variables and patterns with features which were undiscovered previously. The goal when creating these features, is to prepare an input from the dataset which is compatible with the machine learning algorithm.
Here is a list of a few common feature engineering techniques that you may employ. Some of these strategies outlined may be more effective with specific computer vision models, but others may be applicable in all scenarios:
- Imputation - Imputation is a technique used to handle missing values. There are two types of imputation: numerical and categorical imputation.
- One-hot encoding - This type of encoding assigns a unique value for each possible case.
- Log transform - It is used to turn a skewed distribution into a normal or less-skewed distribution. This transformation is used to handle confusing data, and the data becomes more approximative to normal applications.
- Handling outliers - Removal, replacing values, capping, discretization are some of the methods of handling the outliers in the dataset. Some models are susceptible to outliers, hence handling them is essential.
4. Feature selection or dimensionality reduction
Having too many features that don’t contribute to the predictive capacity of estimators may lead to overfitting, higher computing costs, and increased model complexity. You can spot these features because they will usually have low variance or be highly correlated with other features. To remove duplicate variables from a dataset, you can either use feature selection, or dimensionality reduction (with Principal Component Analysis - PCA).
The process of feature selection is recommended when you have a thorough understanding of each feature. Only then, you can eliminate features by leveraging domain knowledge or by simply investigating how and why each variable was obtained. Other techniques, such as model-based feature selection can be used after this. Fisher’s score, for example, is a popular supervised feature selection method – it returns the variables’ ranks in descending order based on Fisher's score. The variables can then be chosen based on the circumstances.
Alternatively, Dimensionality reduction with PCA is one of the most effective methods for reducing the amount of features. It projects high-dimensional data to a lower dimension (fewer features) while retaining as much of the original variance as possible. You can directly specify the number of features you want to keep, or indicate the amount of variance by specifying the percentage instead. PCA identifies the minimum number of features that can be accounted for by the passed variance. This method has the disadvantage of requiring a lot of mathematical calculations, which compromises explainability because you won’t be able to interpret the features after PCA.
5. Care about missing data
If you are working with benchmark datasets, employing simple imputation techniques will be enough to deal with missing data: since they are the “best available” datasets, they rarely have many cases of missing data. Instead, when working with large datasets or custom built datasets, it is essential to understand the reason behind the missing data before using imputing techniques.
Broadly there are three types of common missing data:
- Missing Completely at Random (MCAR) - MCAR assumes that the reason for missing data is unrelated to any unobserved data, which means the probability of there being a missing data value is independent of any observation in the dataset. Here, the observed and missing observations are generated from the same distribution. MCAR produces reliable estimates that are unbiased. It results in a loss of power due to poor design, but not due to absence of the data.
- Missing at Random (MAR) - MAR is more common than MCAR. Here, unlike MCAR, the missing and the observed data are no longer coming from the same distribution.
- Missing Not at Random (MNAR) - MNAR analyses are difficult to perform because the distribution of missing data is affected by both observed and unobserved data. In this situation, there is no need to simulate the random part – it may simply be omitted.
6. Use data pipelines
If you want to build a complex computer vision model, or if your dataset is complex, streamlining your data with a data pipeline can help optimize the process. These data pipelines are usually built with SDKs (Software Development Kits), which allow you to build the workflow of the data pipelines easily.
The data pipelines streamline the process of annotation, validation, model training, and auditing, and easily allow team access. This streamlines your data handling procedure and makes complex models more explainable – it also helps in the automation of any step in the process. For example, the automation feature in Encord allows you to manage your data pipelines – it acts as an operating system for your dataset, and its APIs assemble and streamline data pipelines for your team, allowing you to not only manage the data and its quality efficiently, but also scale it. There are many platforms available to build a data pipeline, so testing and finding the platform whose features fit your computer vision project is key.
Apart from these, there are many other criteria to consider in order to improve your model. Algorithmic and model-based improvements require more technical knowledge, insight, and comprehension of the business use case; hence, dealing with the data as efficiently as possible is a good starting point for your model improvement.
Here are a few other model based improvement techniques:
- Hyperparameter tuning
- Custom loss function (to prioritize metrics as per business needs)
- Novel optimizers (to outperform standard optimizers like ReLu)
- Pre-trained models
In the “Further Read” section below, you will find more resources on these model improvement techniques. You should consider diving into model improvement after you have ensured that your data is fit for your project requirement and the model in use.
Conclusion
In this article, we outlined examples of computer vision models and their use cases in the real world, alongside 6 key things to consider when trying to improve your computer vision model. I hope these tips are helpful to you and your team, and motivate you to build better models!
Further Reading
Frequently asked questions
Encord provides robust tools for creating and managing 3D models, allowing teams to simulate complex scenarios effectively. This capability is particularly useful for situations where collecting real-world data is difficult, enabling organizations to augment their datasets with synthetic data while maintaining high-quality annotations.
Encord provides a powerful annotation platform that streamlines the detection of objects such as doors and stairs in video footage. By utilizing advanced features like object detection and video captioning, users can efficiently annotate key moments of interest, significantly reducing the time and effort required for manual tagging.
Encord is designed to assist clients in building better models faster, especially in the video space. By rendering video natively, Encord eliminates the need to break down CCTV footage into individual frames, allowing for seamless tracking of individuals throughout a store, which is crucial for applications like theft prevention.
Encord helps computer vision teams streamline their training data pipelines by providing tools that enhance data management, annotation, and versioning. This allows for more efficient workflows and improved collaboration among team members, ensuring that high-quality training data is readily accessible.
Encord provides tools that enable users to efficiently manage and curate large visual data sets. This capability allows teams to unlock the potential of their data, making it easier to improve model performance and achieve better outcomes in areas like yield forecasting and harvesting timing.
Encord provides robust tools for data pipeline management, allowing teams to efficiently curate, visualize, and annotate their datasets. This streamlines the workflow for model training and development, ensuring that data is organized and accessible for optimal performance.
Encord provides a comprehensive platform that streamlines the entire training data pipeline, from data collection and labeling to model training and deployment. Our tools enable users to automate and optimize these processes, making it easier to manage complex workflows.
For new users, the initial step is to work with image datasets to familiarize themselves with Encord's functionalities. This foundational experience can pave the way for exploring more complex use cases, including video analysis if necessary.
The process includes getting your data into the platform, labeling it, extracting the labels, and training in your own environment. Encord focuses on demonstrating each step of this workflow during the testing period.
Before uploading images to Encord, preprocessing steps may include creating orthophotos, reconstructing images, cleaning them up, and converting their formats, depending on the specific project requirements.