Teaching Machines to Read: Advances in Text Classification Techniques

Text classification is a process to teach machines to automatically categorize pieces of text into predefined categories or classes. Think of it like having a smart assistant that can sort your emails into "work," "personal," and "spam" folders, or a system that can determine whether a movie review is positive or negative.

E-Mail Sorting using Text Classification
Now, let's explore how machines actually "read" and understand text, which is quite different from how humans do it. Unlike humans, machines can not naturally understand words and their meanings. Machines work with numbers, not text. Therefore human language is transformed into a format that machines can process mathematically. This is done by converting words into numbers.
Imagine you're teaching a computer to understand text the way you might teach a child to understand a new language using building blocks. The first step is to break down text into smaller pieces. Words are converted to numbers through various methods. One simple approach is "one-hot encoding," where each word gets its own unique number or vector. More advanced methods like "word embeddings" represent words as points in a multi-dimensional space, where similar words are closer together. For example, in a basic number system, the sentence "I love pizza" might become something like [4, 12, 8], where each number represents a word.
Once text is converted to numbers, machines can start recognizing patterns. It learns that certain number combinations (representing words) often appear together in specific categories. For example, in restaurant reviews, positive reviews might often contain number patterns representing words like "delicious," "excellent," "amazing" and negative reviews might show patterns representing "disappointing," "cold," "poor".
Machines also learn the order of words and the meaning of combinations. For better understanding, they break down the following:
- Word order: "The dog chased the cat" is different from "The cat chased the dog"
- Context: The word "bank" means something different in "river bank" versus "bank account"
- Relationships: Understanding that "excellent" and "outstanding" are similar in meaning
Finally, the machine uses this processed information to make classification decisions. It's similar to how you might recognize a song's genre by picking up on certain patterns of instruments, rhythm, and style. For example, If the a machine sees a new sentence like:
"The weather today is sunny and warm."
It might classify it as Sunny Weather because it recognizes patterns from previous examples. While machines process text very differently from humans, the goal is to approximate human-like understanding.
Here’s how this process relates to how humans read:

How Humans Read and Classify Text

How Machines Read and Classify Text
The main difference is that humans naturally understand meaning, while machines rely on patterns and probabilities.
The Evolution of Text Classification Techniques
Over the years, various methods have been developed for text classification. These methods or techniques range from traditional machine learning algorithms to advanced deep learning techniques. Let’s look at some of these methods:
Rule-Based Methods
Rule-based methods are one of the oldest and most intuitive approaches to text classification. These systems rely on manually crafted linguistic rules that are specifically designed to identify patterns or characteristics within the text and assign predefined categories. Despite being traditional, they remain relevant in certain contexts where domain-specific knowledge and interpretability are critical. Rule-based methods classify text by applying logical conditions, often written as if-then rules. These rules use features such as:
- Keywords or Phrases: Specific words or combinations of words that indicate a category. Example: Emails containing words like "win", "lottery", or "prize" might be classified as spam.
- Regular Expressions: Patterns to detect variations of text. Example: Identifying email addresses or phone numbers.
- Linguistic Features: Syntax, parts of speech, or other linguistic markers. Example: A sentence starting with “Dear” could indicate a formal letter.
Traditional Machine Learning Algorithms
Traditional machine learning algorithms are a cornerstone of text classification. Unlike rule-based methods, these algorithms learn patterns from labeled data, making them more scalable and adaptable to diverse tasks. Below is an explanation of some of the most widely used traditional algorithms for text classification.
Naive Bayes Classifier
Naive Bayes is a probabilistic classifier based on Bayes’ Theorem. It assumes that features (words, in text classification) are independent of each other—a "naive" assumption, hence the name. Despite this assumption, it performs well in many real-world scenarios. Calculates the probability of a text belonging to a class using:

The class with the highest probability is chosen as the predicted category.
Support Vector Machines (SVM)
SVM is a powerful supervised learning algorithm that finds the best boundary (hyperplane) to separate classes in a high-dimensional space. It works well with sparse datasets like text. SVM maximizes the margin between data points of different classes and the decision boundary. SVM can handle non-linear relationships using kernels (e.g., polynomial or radial basis function (RBF) kernels).

Support Vector Machines
The above figure shows how SVM separates two classes (Positive and Negative) by finding the optimal hyperplane (black line) that maximizes the margin (blue region) between the closest data points of both classes, called support vectors.
Decision Trees
Decision trees classify data by splitting it based on feature values in a hierarchical manner. The structure resembles a tree where each internal node represents a feature, branches represent decisions, and leaf nodes represent categories. Splits data recursively based on features that maximize information gain or reduce entropy (using criteria like Gini Index or Information Gain). Classification follows the path from the root node to a leaf node.
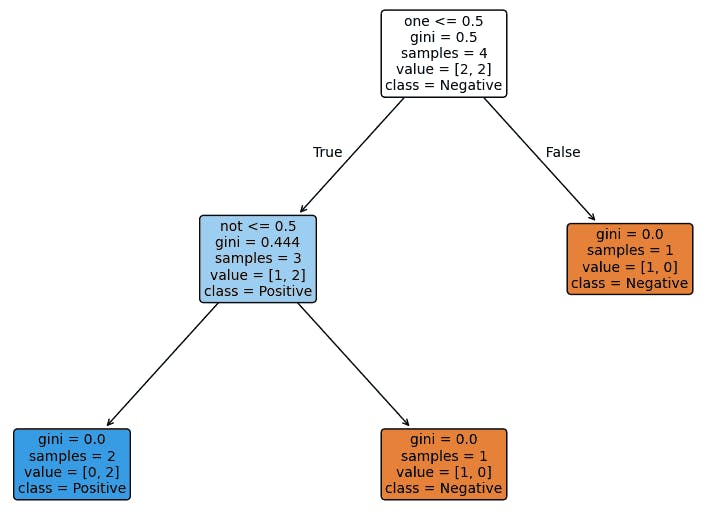
Text Representation of the Decision Tree for Positive and Negative classes
In the above figure, the decision tree predicts sentiment (Positive or Negative) based on the presence of specific words in the text. It evaluates whether words like "one" and "not" appear in the text and uses these conditions to classify the sentiment.
K-Nearest Neighbors (KNN)
KNN is a simple, non-parametric algorithm that classifies data points based on the majority class among their k nearest neighbors in the feature space. It calculates the distance (e.g., Euclidean, cosine) between the new data point and all other points in the dataset. The class of the k closest points is assigned to the new data point.

K-Nearest Neighbors
The above figure illustrates the KNN algorithm. It shows how a new example (yellow square) is classified based on the majority class (Positive or Negative) of its nearest neighbors (k=3 or k=7) in the feature space.
Deep Learning Techniques
Deep learning has revolutionized text classification by introducing methods capable of learning complex patterns and capturing contextual relationships. These techniques have significantly outperformed traditional methods in many NLP tasks. Let’s explore the key players in deep learning-based text classification.
Convolutional Neural Networks (CNNs)
While CNN are widely known for their success in image processing, they are also highly effective for text classification tasks. In text classification, CNNs capture local patterns like n-grams (e.g., phrases or sequences of words) and use these patterns to classify text into predefined categories. Before a CNN can process text, the text must be converted into a numeric format. It first converts text into a numeric format (e.g., word embeddings like Word2Vec or GloVe). Applies convolutional filters over the embeddings to capture local patterns. Uses pooling layers (e.g., max-pooling) to reduce dimensions and focus on the most important features. Final dense layers classify the text into predefined categories.

A CNN Architecture for Text Classification (Source)
Recurrent Neural Networks (RNNs)
RNNs are a type of neural network designed specifically for processing sequential data, making them well-suited for text classification tasks where the order and relationships between words are important. RNNs excel in tasks like sentiment analysis, spam detection, and intent recognition because they can model contextual dependencies within a sequence.
RNNs handle input data as sequences, processing one element at a time. This sequential approach allows them to capture temporal dependencies and patterns within the data. At each time step, the RNN maintains a hidden state that serves as a memory of previous inputs. This hidden state is updated based on the current input and the previous hidden state, enabling the network to retain information over time.
Unlike traditional neural networks, RNNs share the same weights across all time steps. This weight sharing ensures that the model applies the same transformation to each element in the sequence, maintaining consistency in how inputs are processed. At each time step, the RNN produces an output based on the current hidden state. Depending on the task, this output can be used immediately (e.g., in sequence-to-sequence models) or accumulated over time (e.g., in sentiment analysis) to make a final prediction.
Training RNNs involves adjusting their weights to minimize errors in predictions. This is achieved using a process called Backpropagation Through Time, where the network's errors are propagated backward through the sequence to update the weights appropriately. Standard RNNs can struggle with learning long-term dependencies due to issues like the vanishing gradient problem. To address this, architectures such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs) have been developed. These variants include mechanisms to better capture and retain long-term information.

RNN Model for Text Classification (Source)
LSTM
Long Short-Term Memory (LSTM) networks are a type of recurrent neural network (RNN) designed to capture long-range dependencies in sequential data. This makes LSTM effective for text classification tasks. Traditional RNNs can struggle with learning long-term dependencies due to issues like the vanishing gradient problem. LSTMs address this by incorporating memory cells and gating mechanisms that regulate the flow of information. This enables the network to retain or forget information as needed. This architecture allows LSTMs to maintain context over longer sequences which is important for understanding the meaning of text where context can span multiple words or sentences.
A workflow for using LSTMs in text classification involves several key steps:
Text Preprocessing
In text processing it first performs tokenization which splits text into individual words or tokens. Then perform stopword removal to eliminate common words that may not contribute significant meaning (e.g., "and," "the"). After this stemming/lemmatization is performed to reduce words to their base or root form (e.g., "running" to "run").
Text Representation
It converts words into dense vector representations that capture semantic meaning. Pre-trained embeddings like GloVe or Word2Vec are often used to provide meaningful word vectors.
Training
After this training is performed. The LSTM model architecture for text classification consists of following layers:
- Embedding Layer: Transforms input tokens into their corresponding word embeddings.
- LSTM Layer: Processes the sequence of embeddings to capture dependencies and context.
- Dense Layers: Fully connected layers that interpret the LSTM's output and perform the final classification.
The architecture commonly uses binary cross-entropy loss function for binary classification and categorical cross-entropy loss function for multi-class classification. It uses optimizers like Adam for optimizing the model's weights.

LSTM sequence model (Source)
LSTM networks are a powerful tool for text classification tasks, capable of capturing the sequential nature and contextual dependencies inherent in language.
Transformers
A transformer is a deep learning model architecture introduced in the paper "Attention is All You Need" by Vaswani et al. (2017). It is designed to handle sequential data, such as text, by using a mechanism called self-attention to understand the relationships between words in a sentence or a document regardless of their position. Transformers are foundational to many state-of-the-art NLP models like BERT, GPT, and T5.
In traditional sequence models, such as RNNs LSTMs, words are processed sequentially, one at a time. This sequential nature makes it difficult for these models to capture long-range dependencies efficiently, as the information about earlier words may fade as processing continues. Transformers, however, process all words in a sequence simultaneously, allowing them to capture both short-range and long-range dependencies effectively.
While the original transformer architecture (introduced in "Attention is All You Need") did use an encoder-decoder structure, many modern transformers used for text classification (like BERT) are actually encoder-only models. They don't have a decoder component. This is because text classification doesn't require the generative capabilities that the decoder provides. The encoder comprises multiple layers of self-attention mechanisms and feedforward neural networks. Each word in the input sequence is first converted into a dense numerical representation called an embedding. These embeddings are then processed by the self-attention mechanism, which computes the importance of each word relative to others in the context of the sequence. This allows the model to focus on the most relevant words for a given task while still considering the entire sequence.
For text classification, the typical workflow with transformers involves the following steps:
- First, the text goes through tokenization (e.g. WordPiece or Byte-Pair Encoding etc.). Imagine breaking down a sentence "The cat sat" into pieces like ["The", "cat", "sat"]. The transformer actually breaks it into even smaller subword units, so "walking" might become ["walk", "ing"]. This helps it handle words it hasn't seen before.
- These tokens are then converted into numerical vectors called embeddings. Each token gets transformed into a long list of numbers that capture its meaning. The word "cat" might become something like [0.2, -0.5, 0.8, ...]. These numbers encode semantic relationships - similar words will have similar number patterns.
- Next comes the heart of the transformer, the self-attention mechanism. This is where the model looks at relationships between all words in your text simultaneously. When processing the word "it" in a sentence, the model might pay strong attention to a noun mentioned earlier to understand what "it" refers to. The model calculates attention scores between every pair of words, creating a web of relationships.
- The transformer has multiple layers (called transformer blocks) that each perform this attention process. In each layer, the word representations get refined based on their contexts. Early layers might capture basic grammar, while deeper layers understand more complex relationships and meaning.
- For classification transformers use a special [CLS] token added at the start of the text. This token acts like a summary through all those attention layers. Think of it as the model's way of taking notes about the overall meaning.
- After all the transformer layers, the final [CLS] token representation goes through a classification head - typically a simple neural network that maps this rich representation to your target classes. If you're doing sentiment analysis, it might map to "positive" or "negative". For topic classification, it could map to categories like "sports", "politics", etc.
- The output layer applies a softmax function to convert these final numbers into probabilities across your possible classes. The highest probability indicates the model's prediction.
For instance, in a sentiment analysis task, the transformer learns to focus on words or phrases like "excellent," "terrible," or "average" in their respective contexts. By training on a labeled dataset, the model adjusts its parameters to associate specific patterns in the embeddings of the input text with corresponding class labels (e.g., positive, negative, or neutral sentiment).

BERT for text classification (Source)
Teaching Machines to Read and Classify Text
Text classification is a task in NLP where machines are trained to assign predefined categories to pieces of text. It plays a critical role in tasks like sentiment analysis, spam detection, topic categorization, and intent detection in conversational AI.
Key Components of Text Classification Systems
- Text Input: The system processes raw text such as sentences, paragraphs, or entire documents.
- Preprocessing: Text is cleaned, tokenized, and converted into numerical representations (embeddings) that models can understand.
- Modeling: A machine learning model, often based on transformers like BERT or DistilBERT, learns patterns and relationships in the text to classify it into one or more categories.
- Output: The system outputs a category label or probability distribution over multiple categories.
Here’s a simple example of how to train a text classification model using Transformers in a Google Colab notebook. We’ll use the Hugging Face transformers library, which provides a user-friendly interface for working with transformer models like BERT. Following are the steps:
- Import the required libraries.
- Load a pre-trained transformer model.
- Use a small dataset (e.g., the IMDb dataset for sentiment analysis).
- Fine-tune the model for text classification.
Now we will see step-by-step example:
First install the required libraries
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments from datasets import load_dataset import torch
Step 1: Load the Dataset
In this step, we load the IMDb movie review dataset, which contains movie reviews labeled as either positive or negative. We then split the dataset into two parts: one for training the model and one for testing its performance. A smaller subset of 2000 training samples and 500 test samples is used for faster processing.
# Step 1: Load the dataset
dataset = load_dataset("imdb")
# Split into train and test
train_dataset = dataset['train'].shuffle(seed=42).select(range(2000)) # Use a subset for quick training
test_dataset = dataset['test'].shuffle(seed=42).select(range(500))Step 2: Load the Tokenizer and Model
We load a pre-trained BERT model and its associated tokenizer. The tokenizer converts text into numerical format (tokens) that the model can understand. The BERT model is set up for a sequence classification task with two possible outputs: positive or negative sentiment.
# Step 2: Load the tokenizer and model model_name = "bert-base-uncased" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
Step 3: Preprocess the Dataset
Here, we prepare the dataset for the model by tokenizing the text reviews. Tokenization ensures all reviews are represented as sequences of numbers, with longer reviews truncated to a maximum length of 128 tokens and shorter ones padded to maintain consistency.
The original text column is removed from the dataset since the model only needs the tokenized data. The dataset is also converted into a format that the PyTorch framework can process.
# Step 3: Preprocess the dataset
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True, padding=True, max_length=128)
train_dataset = train_dataset.map(preprocess_function, batched=True)
test_dataset = test_dataset.map(preprocess_function, batched=True)
# Remove unnecessary columns
train_dataset = train_dataset.remove_columns(["text"])
test_dataset = test_dataset.remove_columns(["text"])
train_dataset.set_format("torch")
test_dataset.set_format("torch")Step 4: Define Training Arguments
We define the settings for training the model. This includes the number of epochs (3), batch size (16), learning rate, logging frequency, and saving the best model after training. These arguments control how the model learns and evaluates its performance during training.
# Step 4: Define training arguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=10,
save_strategy="epoch",
load_best_model_at_end=True,
)Step 5: Initialize the Trainer
We set up the Hugging Face Trainer, which simplifies the training and evaluation process. The Trainer combines the model, training settings, and datasets, making it easier to manage the training pipeline.
# Step 5: Initialize the Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)Step 6: Train the Model
In this step, the model learns to classify the sentiment of reviews (positive or negative) by training on the prepared dataset. It iteratively adjusts its internal parameters to minimize the error in its predictions.
# Step 6: Train the model trainer.train()

Training Results on Weights & Biases (W&B)
Step 7: Evaluate the Model
Finally, the trained model is evaluated on the test dataset. This step calculates metrics like loss and provides insights into how well the model performs on unseen data.
# Step 7: Evaluate the model results = trainer.evaluate()
Step 8: Test the model
This step evaluates how well the trained model performs on the test dataset. It involves generating predictions for the test samples, comparing these predictions to the actual labels, and calculating accuracy manually.
# Step 8: Test the model
# Get predictions and labels from the evaluation
predictions, labels, _ = trainer.predict(test_dataset)
# Convert logits to predicted class indices
predicted_classes = predictions.argmax(axis=-1)
# Calculate accuracy manually
accuracy = (predicted_classes == labels).mean()
print(f"Test Accuracy: {accuracy:.4f}")Following is the output

Step 9: Test on a Sample Text
This step demonstrates how to use the trained model to classify a single piece of text. It involves preparing the text, passing it through the model, and interpreting the result.
# Step 9: Test on a sample text
# Check if GPU is available and use it
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Move the model to the appropriate device
model = model.to(device)
# Test on a sample text
sample_text = "This movie was amazing, I loved it!"
inputs = tokenizer(sample_text, return_tensors="pt", truncation=True, padding=True, max_length=128)
# Move inputs to the same device as the model
inputs = {key: value.to(device) for key, value in inputs.items()}
# Perform inference
output = model(**inputs)
# Interpret the Prediction
prediction = output.logits.argmax(dim=1).item()
# Display the Result
print(f"Prediction: {'Positive' if prediction == 1 else 'Negative'}")Following it the output

Advancements in Pre-trained Language Models
BERT, GPT, and other pre-trained models have revolutionized text classification by providing contextualized understanding, transfer learning, and generalization. They outperform traditional methods in accuracy, scalability, and adaptability. As these models evolve, they continue to redefine the boundaries of NLP and text classification.
Transformers have the ability to model complex language relationships and can enhance text classification tasks. By introducing innovative architectures like attention mechanisms and pre-training on massive datasets, these models bring contextual understanding and efficiency to natural language understanding and text classification. Here's how transformers like BERT and GPT improve text classification under key aspects:
Contextualized Understanding
Traditional approaches to text classification often relied on static word embeddings (e.g., Word2Vec, GloVe), where a word's representation remained the same regardless of its context. Transformers revolutionized this by generating dynamic embeddings, where the meaning of a word adapts based on its surrounding words. For example, the word "bank" in "river bank" versus "financial bank" is understood differently by models like BERT. This ability to model both short-range and long-range dependencies ensures better comprehension of sentence structure and meaning, which is critical for accurate classification tasks such as sentiment analysis or spam detection.
Bidirectional Context
Models like BERT introduced a concept of reading text in both directions (left-to-right and right-to-left). This bidirectional nature enables a richer understanding of context compared to unidirectional models because it considers the entire sentence when interpreting a word. For example, in the sentence "The movie was not great," a bidirectional model correctly interprets "not" in relation to "great" to identify a negative sentiment. This depth of understanding makes BERT particularly powerful for nuanced tasks such as intent classification or fake news detection.
Attention Mechanisms
Transformers use self-attention mechanisms, which allow the model to focus on the most relevant words or phrases in a sentence, regardless of its position. This is useful for classifying long texts, where critical information may appear far apart in the document. For example, in classifying legal or academic documents, a transformer can prioritize key phrases that determine the overall category, even if they are scattered throughout the text.
Pre-training and Fine-tuning
Transformers are pre-trained on a large database. It helps transforms to learn a broad understanding of language, and then fine-tuned on task-specific data. This two-stage process reduces the need for large labeled datasets for classification tasks. For example, a pre-trained BERT model can be fine-tuned on a smaller dataset to classify customer reviews into positive, neutral, or negative sentiments with high accuracy. This approach not only improves performance but also lowers the barrier to deploying high-quality classification models.
Few-shot and Zero-shot Learning
Generative transformers like GPT have brought forward the capability of few-shot and zero-shot learning. These models can generalize to new classification tasks with minimal or no additional training by using prompts. For example, GPT-4o can classify emails as "important" or "not important" with just a few examples provided as part of the input prompt. This flexibility is a major leap forward, enabling rapid deployment of classification models without extensive labeled data.
Scalability and Multi-task Learning
Transformers like RoBERTa and T5 extend the capabilities of BERT and GPT by improving pre-training objectives and scalability. These models can handle multiple classification tasks simultaneously, such as categorizing customer queries by department and detecting sentiment in the same input. This scalability is invaluable for businesses that need robust systems for diverse text classification needs.
Transfer Learning
By transfer learning, transformers have drastically reduced the time and computational resources needed to build robust text classification models. Once a model like BERT or GPT is pre-trained, it can be fine-tuned for diverse tasks like topic classification or intent detection, even with limited domain-specific data. This versatility has made text classification more accessible across industries, from healthcare to finance.
Encord's Approach to Text Classification Workflows
Encord is an AI data development platform for managing, curating and annotating large-scale text and document datasets, as well as evaluating LLM performance. AI teams can use Encord to label document and text files containing text and complex images and assess annotation quality using several metrics. The platform has robust cross-collaboration functionality across:
Encord offers features for text classification workflows. Encord enables efficient data management, annotation, and model training for various NLP tasks. Here's how Encord supports text classification:
Document and Text Annotation
Encord's platform facilitates the annotation of documents and text files, supporting tasks such as:
- Text Classification: Categorize entire documents or specific text segments into predefined topics or groups, essential for organizing large datasets.
- Named Entity Recognition (NER): Identify and label entities like names, organizations, locations, dates, and times within text, aiding in information extraction.
- Sentiment Analysis: Label text to reflect sentiments such as positive, negative, or neutral, valuable for understanding customer feedback and social media monitoring.
- Question Answering and Translation: Annotate text to facilitate question-answering systems and translation tasks, enhancing multilingual support and information retrieval.
Multimodal Data Support
Encord platform is designed to handle various data types, including text, images, videos, audio, and DICOM files. It assists in centralizing and organizing diverse datasets within a single platform, simplifying data handling and reducing fragmentation. It also assists in annotating and analyzing multiple data types and providing context and improving the quality of training data for complex AI models.
Advanced Annotation Features
To enhance the efficiency and accuracy of text classification tasks, Encord provides:
- Customizable Ontologies: It helps in defining structured frameworks with specific categories, labels, and relationships to ensure consistent and accurate annotations across projects.
- Automated Labeling: It integrates state-of-the-art models like GPT-4o to automate and accelerate the annotation process which reduces manual effort and increases productivity.
Seamless Integration and Scalability
Encord platform is built to integrate smoothly into existing workflows. It allows programmatically managing projects, datasets, and labels via API and SDK access. It facilitates automation and integration with other tools and machine learning frameworks. Encord can handle large-scale datasets efficiently, supporting the growth of AI projects and accommodating increasing data volumes without compromising performance.
Key Takeaways
Teaching machines to read and learn through text classification involves enabling them to understand, process, and categorize text data into meaningful categories. This blog highlights the journey of text classification advancements and provides insights into key methods and tools. Here's a summary of the main points:
- Advancements in Text Classification: Text classification has evolved from rule-based systems and traditional machine learning methods like Naive Bayes and SVM to advanced deep learning techniques such as LSTMs, CNNs, and transformers.
- Impact of Pre-trained Language Models: Models like BERT, GPT, and RoBERTa have revolutionized text classification by enabling contextual understanding, bidirectional context, and scalability, making them effective for nuanced tasks like sentiment analysis and topic categorization.
- Transformers and Attention Mechanisms: Transformers introduced self-attention mechanisms, enabling efficient handling of long-range dependencies and improving text classification accuracy, especially for complex and lengthy texts.
- Practical Applications and Workflows: Modern text classification workflows utilizes pre-trained models, tokenization, and fine-tuning processes, reducing dependency on extensive labeled datasets while achieving high accuracy in tasks like sentiment analysis and spam detection.
- Encord’s Role in Text Classification: Encord enhances text classification workflows by offering advanced annotation tools, automated labeling with AI integration, multimodal data support, and seamless scalability, ensuring efficient and accurate NLP model development.
Frequently asked questions
Text classification is the process of teaching machines to categorize pieces of text into predefined categories or classes, such as sorting emails into "work," "personal," and "spam" folders or determining the sentiment of a movie review.
Machines don't naturally understand text like humans do. Instead, text is transformed into numerical representations through methods like:
One-Hot Encoding: Assigns a unique number/vector to each word.
Word Embeddings: Represents words as points in a multi-dimensional space, grouping similar words closer together.
Rule-Based Methods: Relies on manually crafted rules using keywords, regular expressions, or linguistic features.
Traditional Machine Learning Algorithms: Includes Naive Bayes, Support Vector Machines (SVM), Decision Trees, and K-Nearest Neighbors (KNN).
Deep Learning Techniques: Uses advanced models like CNNs, RNNs, LSTMs, and transformers for better context and accuracy.
Transformers, like BERT and GPT, revolutionize text classification by:
Using self-attention mechanisms to understand word relationships.
Capturing both short- and long-range dependencies.
Offering pre-trained models for contextual understanding, which can be fine-tuned for specific tasks.
Sentiment Analysis: Understanding customer opinions in reviews or social media.
Spam Detection: Identifying spam emails or messages.
Topic Categorization: Organizing articles or documents into relevant categories.
Named Entity Recognition (NER): Extracting information like names, dates, or locations.
CNNs: Focus on capturing local patterns (like phrases) in text using convolutional filters. Ideal for short, context-independent tasks.
RNNs: Process text sequentially, retaining contextual information across the entire sequence. Suitable for tasks requiring understanding of word order and context.
Pre-training enables models to develop a broad understanding of language using large datasets. This general knowledge is fine-tuned on specific tasks, reducing the need for extensive labeled data and improving performance.
Encord's platform is versatile and can be used to annotate a variety of data types, particularly those related to architectural plans and compliance documents. Users can create annotations for specific objects, such as smoke detectors, egress points, and structural elements, which are critical for ensuring compliance with municipal codes.
In Encord, text can be annotated in a couple of ways, including outlining specific phrases, highlighting text, and using the annotation tools to apply relevant tags. Users can also annotate directly on flattened PDF files by clicking and dragging, providing a versatile approach to document annotation.
Encord is designed to support organizations that require high-volume document annotation, with processes that can scale to meet increasing demands. By leveraging automation and efficient workflows, Encord can help reduce annotation timelines and costs while maintaining high-quality standards.
Encord supports a wide range of annotation types, including temporal annotation detection and various other tasks suitable for different dataset sizes. Users are encouraged to experiment with these tasks during the trial phase to fully understand the platform's capabilities.
Users can build and manage ontologies in Encord through a user-friendly interface or programmatically using the SDK. The platform allows for flexible object classification and supports frame-level classifications, providing detailed information for each annotated object.
Encord features an indexing system that organizes files for easy access during annotation. Users can manage their data effectively by utilizing folders and categories, ensuring that all relevant files are easily retrievable, which streamlines the annotation process.
Encord offers robust text annotation features including entity recognition for extracting names, dates, and other key entities from documents. Additionally, it supports NLP tasks such as classifying text into predefined categories or determining sentiment.
Encord offers robust metadata filtering capabilities, allowing users to sort and filter data based on various criteria such as guest names or specific topics discussed. This helps in quickly identifying relevant content across video and audio files.
Encord supports various annotation methods, including named entity recognition (NER) and general text annotation practices. This flexibility allows users to cater to specific project needs and improve the quality of their machine learning models.
Encord supports a variety of annotation types, including bounding boxes, polygons, and classifications. This flexibility enables users to tailor their annotation to the specific requirements of their projects, accommodating diverse data types.