What is Data Labeling? The Ultimate Guide [2024]

Data labeling constitutes a cornerstone within the domain of machine learning, addressing a fundamental challenge in artificial intelligence: transforming raw data into a format intelligible to machines.
At its core, data annotation solves the issue that unstructured information presents: machines struggle to comprehend the complexities of the real world because they lack human-like cognition.
In this interplay between data and intelligence, data labeling assumes the role of an orchestrator, imbuing raw information with context and significance. This blog explains the importance, methodologies, and challenges associated with data labeling.
Understanding Data Labeling
In machine learning, data is the fuel that propels algorithms to decipher patterns, make predictions, and enhance decision-making processes. However, not all data is equal; the success of a machine learning project hinges on the meticulous process of data labeling, a task akin to providing a roadmap for machines to navigate the complexities of the real world.
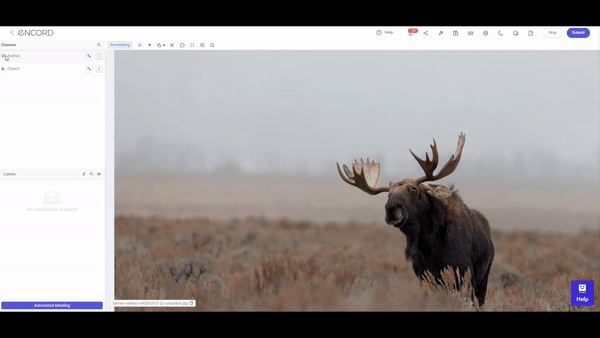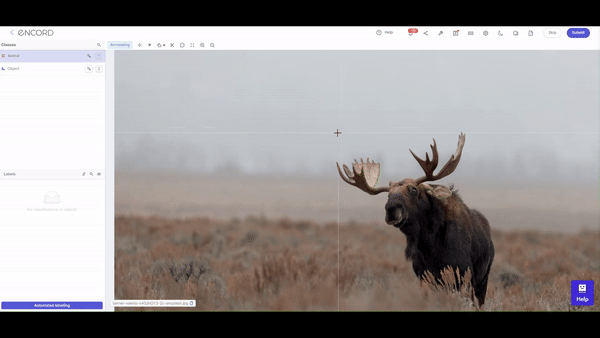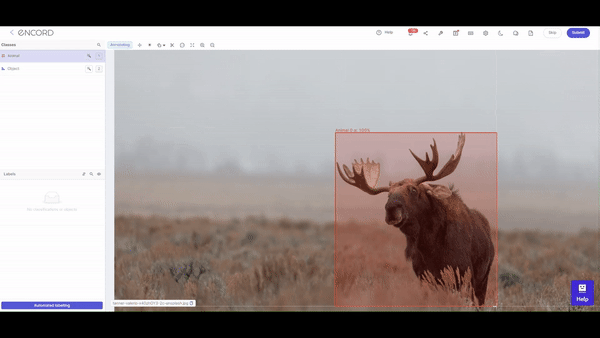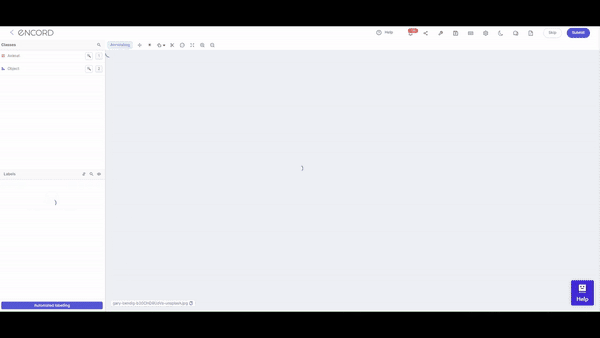
What is Data Labeling?
Data labeling, often called data annotation, involves the meticulous tagging or marking of datasets. These annotations are the signposts that guide machine learning models during their training phase. As models learn from labeled data, the accuracy of these annotations directly influences the model's ability to make precise predictions and classifications.
Significance of Data Labeling in Machine Learning
Data annotation or tagging provides context for the data that machine learning algorithms can comprehend. The algorithms learn to recognize patterns and make predictions based on the labeled data. The significance of data labeling lies in its ability to enhance the learning process, enabling machines to generalize from labeled examples to make informed decisions on new, unlabeled data.
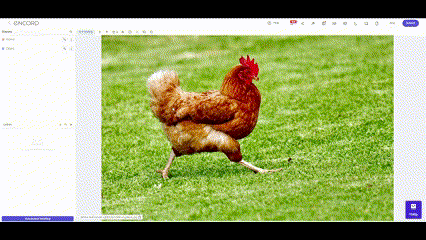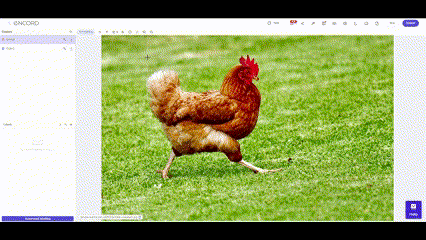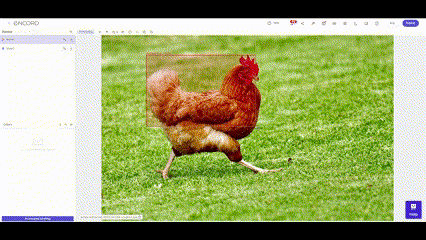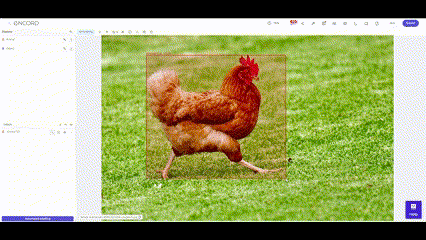
Accurate and well-labeled data sets contribute to creating robust and reliable machine learning models. These models, whether for image recognition, natural language processing, or other applications, heavily rely on labeled data to understand and differentiate between various input patterns. The quality of data labeling directly impacts the model's performance, influencing its precision, recall, and overall predictive capabilities.
In industries such as healthcare, finance, and autonomous vehicles, where the stakes are high, the precision of machine learning models is critical. Properly labeled data ensures that models can make informed decisions, improving efficiency and reducing errors.
How does Data Labeling Work?
Understanding the intricacies of how data labeling operates is fundamental to grasping its impact on machine learning models. This section discusses the mechanics of data labeling, distinguishing between labeled and unlabeled data, explaining data collection techniques, and shedding light on the tagging process.
Labeled vs. Unlabeled Data
In the dichotomy of supervised and unsupervised machine learning, the distinction lies in the presence or absence of labeled data. Supervised learning thrives on labeled data, where each example in the training set is coupled with a corresponding output label. This labeled data becomes the blueprint for the model, guiding it to learn the relationships and patterns necessary for accurate predictions.
Conversely, unsupervised learning operates in the realm of unlabeled data. The algorithm navigates the dataset without predefined labels, seeking inherent patterns and structures. Unsupervised learning is a journey into the unknown, where the algorithm must uncover the latent relationships within the data without explicit guidance.
Data Collection Techniques
The process of data labeling begins with the acquisition of data, and the techniques employed for this purpose play a pivotal role in shaping the quality and diversity of the labeled dataset.
Manual Data Collection
One of the most traditional yet effective methods is manual data collection. Human annotators meticulously label data points based on their expertise, ensuring precision in the annotation process. While this method guarantees high-quality annotations, it can be time-consuming and resource-intensive.
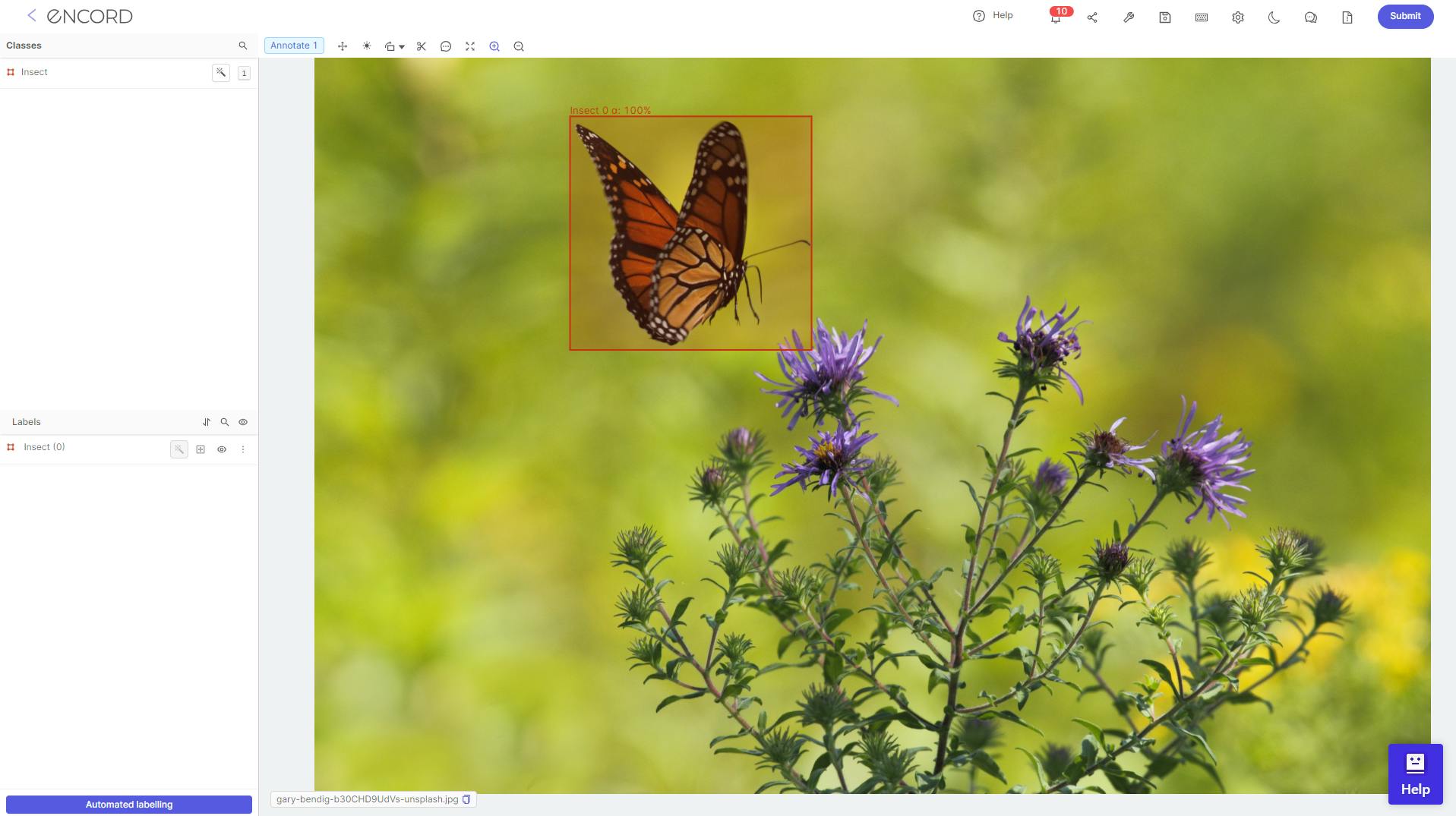
Open-Source Datasets
In the era of collaborative knowledge-sharing, leveraging open-source datasets has become a popular approach. These datasets, labeled by a community of experts, provide a cost-effective means of accessing diverse and well-annotated data for training machine learning models.
Synthetic Data Generation
To address the challenge of limited real-world labeled data, synthetic data generation has gained prominence. This technique involves creating artificial data points that mimic real-world scenarios, augmenting the labeled dataset, and enhancing the model's ability to generalize to new, unseen examples.
Data Tagging Process
The data tagging process is a critical step that demands attention to detail and precision to ensure the resulting labeled dataset accurately represents the real-world scenarios the model is expected to encounter.
Ensuring Data Security and Compliance
With heightened data privacy concerns, ensuring the security and compliance of labeled data is non-negotiable. Implementing robust measures to safeguard sensitive information during the tagging process is imperative. Encryption, access controls, and adherence to data protection regulations are vital components of this security framework.
Data Labeling Techniques
Manual Labeling Process
The manual labeling process involves human annotators meticulously assigning labels to data points. This method is characterized by its precision and attention to detail, ensuring high-quality annotations that capture the intricacies of real-world scenarios. Human annotation brings domain expertise into the labeling process, enabling nuanced distinctions that automated systems might struggle to discern.
However, the manual process can be time-consuming and resource-intensive, necessitating robust quality control measures. Quality control is essential to identify and rectify any discrepancies in annotations, maintaining the accuracy of the labeled dataset. Establishing a ground truth, a reference point against which annotations are compared, is a key element in quality control, enabling the assessment of annotation consistency and accuracy.
Semi-Supervised Labeling
Semi-supervised labeling strikes a balance between labeled and unlabeled data, leveraging the strengths of both. Active learning, a technique within semi-supervised labeling, involves the model actively selecting the most informative data points for labeling. This iterative process optimizes the learning cycle, focusing on areas where the model exhibits uncertainty or requires additional information. Combination labeling, another facet of semi-supervised labeling, integrates labeled and unlabeled data to enhance model performance.
Synthetic Data Labeling
Synthetic data labeling involves creating artificial data points to supplement real-world labeled datasets. This technique addresses the challenge of limited labeled data by generating diverse examples that augment the model's understanding of various scenarios. While synthetic data is a valuable resource for training models, ensuring its relevance and compatibility with real-world data is crucial.
Automated Data Labeling
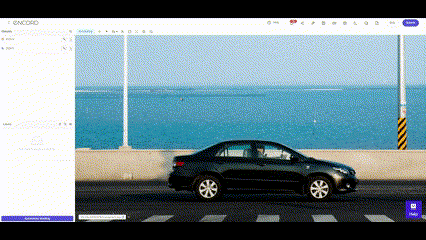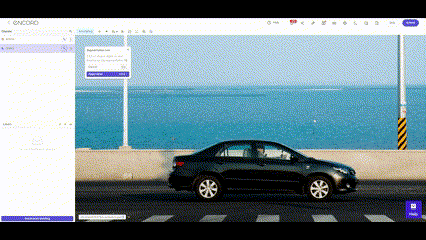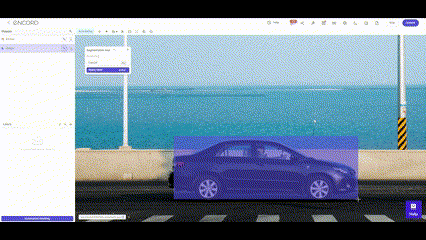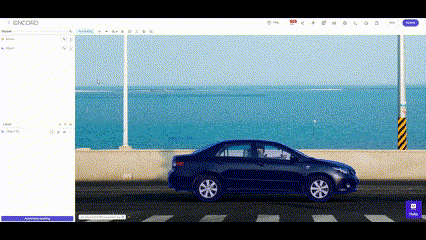
Automatic data labeling employs algorithms to assign labels to data points, streamlining the labeling process. This approach significantly reduces the manual effort required, making it efficient for large-scale labeling tasks. However, the success of automatic labeling hinges on the accuracy of the underlying algorithms, and quality control measures must be in place to rectify any mislabeling or inconsistencies.
Active Learning
Active learning is a dynamic technique where the model actively selects the most informative data points for labeling. This iterative approach optimizes the learning process, directing attention to areas where the model's uncertainty prevails or additional information is essential.
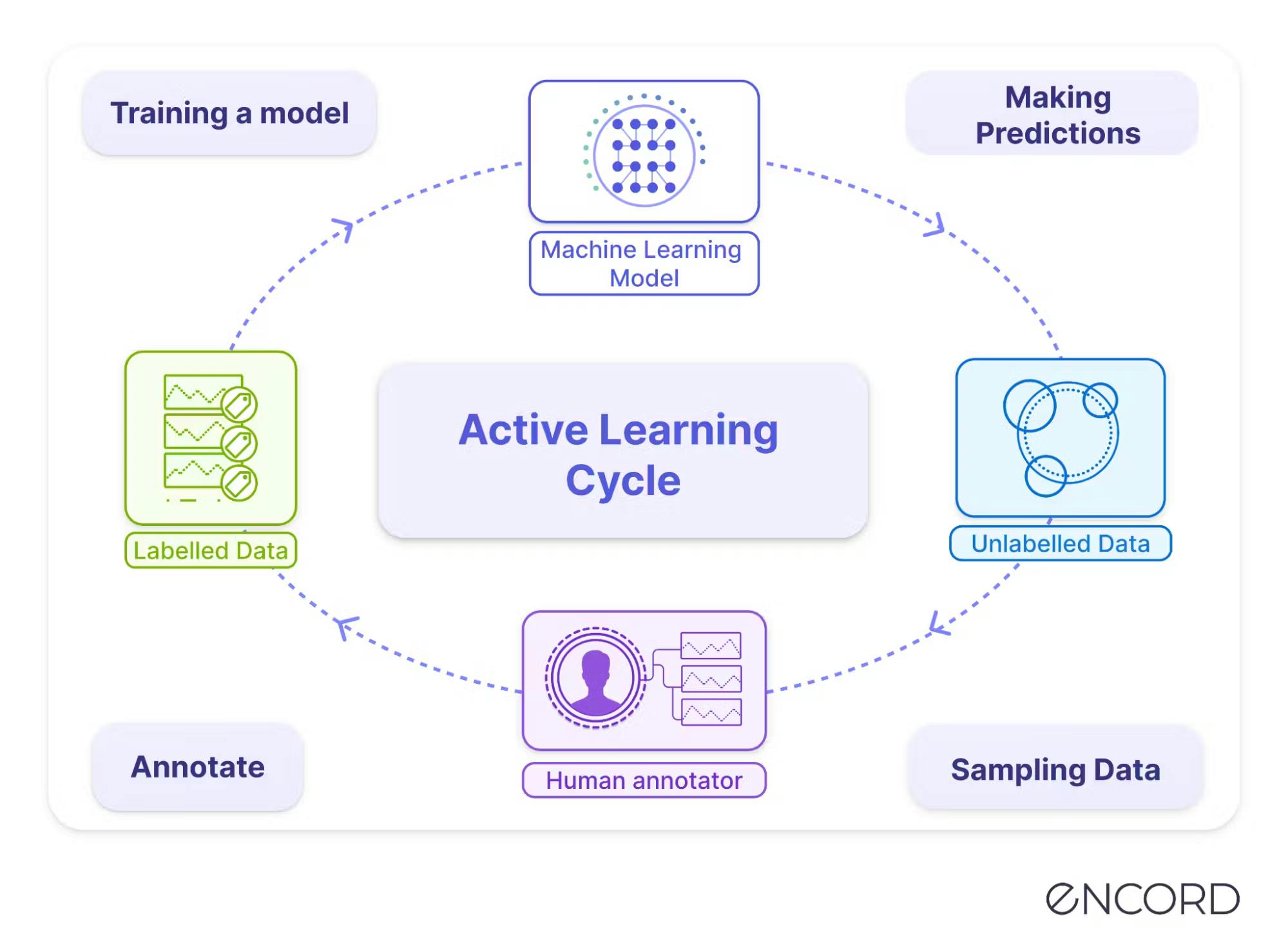
Active learning enhances efficiency by prioritizing the labeling of data that maximizes the model's understanding.
Outsourcing Labeling
Outsourcing data labeling to specialized service providers or crowdsourced platforms offers scalability and cost-effectiveness. This approach allows organizations to tap into a distributed workforce for annotating large volumes of data. While outsourcing enhances efficiency, maintaining quality control and ensuring consistency across annotators are critical challenges.
Crowdsourced Labeling
Crowdsourced labeling leverages the collective efforts of a distributed online workforce to annotate data. This decentralized approach provides scalability and diversity but demands meticulous management to address potential issues of label consistency and quality control.
It takes careful planning to navigate the wide range of data labeling strategies while considering the project's needs, resources, and desired level of control. Achieving the ideal balance between automated efficiency and manual accuracy is essential to the success of the data labeling project.
Types of Data Labeling
Data labeling is flexible enough to accommodate the various requirements of machine learning applications. This section explores the various data labeling techniques tailored to specific domains and applications.
Computer Vision Labeling
Supervised learning
Supervised learning forms the backbone of computer vision labeling. In this paradigm, models are trained on labeled datasets, where each image or video frame is paired with a corresponding label. This pairing enables the model to learn and generalize patterns, making accurate predictions on new, unseen data. Applications of supervised learning in computer vision include image classification, object detection, and facial recognition.
Unsupervised learning
In unsupervised learning for computer vision, models operate on unlabeled data, extracting patterns and structures without predefined labels. This exploratory approach is particularly useful for tasks that discover hidden relationships within the data. Unsupervised learning applications include clustering similar images, image segmentation, and anomaly detection.
Semi-supervised learning
Semi-supervised learning balances labeled and unlabeled data, offering the advantages of both approaches. Active learning, a technique within semi-supervised labeling, involves the model selecting the most informative data points for labeling. This iterative process optimizes learning by focusing on areas where the model exhibits uncertainty or requires additional information. Combination labeling integrates labeled and unlabeled data, enhancing model performance with a more extensive dataset.
Human-in-the-Loop (HITL)
Human-in-the-loop (HITL) labeling acknowledges the strengths of both machines and humans. While machines handle routine labeling tasks, humans intervene when complex or ambiguous scenarios require nuanced decision-making. This hybrid approach ensures the quality and relevance of labeled data, particularly when automated systems struggle.
Programmatic data labeling
Programmatic data labeling involves leveraging algorithms to automatically label data based on predefined rules or patterns. This automated approach streamlines the labeling process, making it efficient for large-scale datasets. However, it requires careful validation to ensure accuracy, as the success of programmatic labeling depends on the quality of the underlying algorithms.
Natural Language Processing Labeling
Named Entity Recognition (NER)
Named Entity Recognition involves identifying and classifying entities within text, such as names of people, locations, organizations, dates, and more. NER is fundamental in extracting structured information from unstructured text, enabling machines to understand the context and relationships between entities.
Sentiment analysis
Sentiment Analysis aims to determine the emotional tone expressed in text, categorizing it as positive, negative, or neutral. This technique is crucial for customer feedback analysis, social media monitoring, and market research, providing valuable insights into user sentiments.
Text classification
Text Classification involves assigning predefined categories or labels to textual data. This technique is foundational for organizing and categorizing large volumes of text, facilitating automated sorting and information retrieval. It finds applications in spam detection, topic categorization, and content recommendation systems.
Audio Processing Labeling
Audio processing labeling involves annotating audio data to train models for speech recognition, audio event detection, and various other audio-based applications. Here are some key types of audio-processing labeling techniques:
Speed data labeling
Speech data labeling is fundamental for training models in speech recognition systems. This process involves transcribing spoken words or phrases into text and creating a labeled dataset that forms the basis for training accurate and efficient speech recognition models. High-quality speech data labeling ensures that models understand and transcribe diverse spoken language patterns.
Audio event labeling
Audio event labeling focuses on identifying and labeling specific events or sounds within audio recordings. This can include categorizing events such as footsteps, car horns, doorbell rings, or any other sound the model needs to recognize. This technique is valuable for surveillance, acoustic monitoring, and environmental sound analysis applications.
Speaker diarization
Speaker diarization involves labeling different speakers within an audio recording. This process segments the audio stream and assigns speaker labels to each segment, indicating when a particular speaker begins and ends. Speaker diarization is crucial for applications like meeting transcription, which helps distinguish between different speakers for a more accurate transcript.
Language identification
Language identification involves labeling audio data with the language spoken in each segment. This is particularly relevant in multilingual environments or applications where the model must adapt to different languages.
Benefits of Data Labeling
The process of assigning meaningful labels to data points brings forth a multitude of benefits, influencing the accuracy, usability, and overall quality of machine learning models. Here are the key advantages of data labeling:
Precise Predictions
Labeled datasets serve as the training ground for machine learning models, enabling them to learn and recognize patterns within the data. The precision of these patterns directly influences the model's ability to make accurate predictions on new, unseen data. Well-labeled datasets create models that can be generalized effectively, leading to more precise and reliable predictions.
Improved Data Usability
Well-organized and labeled datasets enhance the usability of data for machine learning tasks. Labels provide context and structure to raw data, facilitating efficient model training and ensuring the learned patterns are relevant and applicable. Improved data usability streamlines the machine learning pipeline, from data preprocessing to model deployment.
Enhanced Model Quality
The quality of labeled data directly impacts the quality of machine learning models. High-quality labels, representing accurate and meaningful annotations, contribute to creating robust and reliable models. Models trained on well-labeled datasets exhibit improved performance and are better equipped to handle real-world scenarios.
Use Cases and Applications
As discussed before, for many machine learning applications, data labeling is the foundation that enables models to traverse and make informed decisions in various domains. Data points can be strategically annotated to facilitate the creation of intelligent systems that can respond to particular requirements and problems. The following are well-known use cases and applications where data labeling is essential:
Image Labeling
Image labeling is essential for training models to recognize and classify objects within images. This is instrumental in applications such as autonomous vehicles, where identifying pedestrians, vehicles, and road signs is critical for safe navigation.
Text Annotation
Text annotation involves labeling textual data to enable machines to understand language nuances. It is foundational for applications like sentiment analysis in customer feedback, named entity recognition in text, and text classification for categorizing documents.
Video Data Annotation
Video data annotation facilitates the labeling of objects, actions, or events within video sequences. This is vital for applications such as video surveillance, where models need to detect and track objects or recognize specific activities.
Speech Data Labeling
Speech data labeling involves transcribing spoken words or phrases into text. This labeled data is crucial for training accurate speech recognition models, enabling voice assistants, and enhancing transcription services.
Medical Data Labeling
Medical data labeling is essential for tasks such as annotating medical images, supporting diagnostic processes, and processing patient records. Labeled medical data contributes to advancements in healthcare AI applications.
Challenges in Data Labeling
While data labeling is a fundamental step in developing robust machine learning models, it comes with its challenges. Navigating these challenges is crucial for ensuring the quality, accuracy, and fairness of labeled datasets. Here are the key challenges in the data labeling process:
Domain Expertise
Ensuring annotators possess domain expertise in specialized fields such as healthcare, finance, or scientific research can be challenging. Lacking domain knowledge may lead to inaccurate annotations, impacting the model's performance in real-world scenarios.
Resource Constraint
Data labeling, especially for large-scale projects, can be resource-intensive. Acquiring and managing a skilled labeling workforce and the necessary infrastructure can pose challenges, leading to potential delays in project timelines.
Label Inconsistency
Maintaining consistency across labels, particularly in collaborative or crowdsourced labeling efforts, is a common challenge. Inconsistent labeling can introduce noise into the dataset, affecting the model's ability to generalize accurately.
Labeling Bias
Bias in labeling, whether intentional or unintentional, can lead to skewed models that may not generalize well to diverse datasets. Overcoming labeling bias is crucial for building fair and unbiased machine learning systems.
Data Quality
The quality of labeled data directly influences model outcomes. Ensuring that labels accurately represent real-world scenarios, and addressing issues such as outliers and mislabeling, is essential for model reliability.
Data Security
Protecting sensitive information during the labeling process is imperative to prevent privacy breaches. Implementing robust measures, including encryption, access controls, and adherence to data protection regulations, is vital for maintaining data security.
Overcoming these challenges requires a strategic and thoughtful approach to data labeling. Implementing best practices, utilizing advanced tools and technologies, and fostering a collaborative environment between domain experts and annotators are key strategies to address these challenges effectively.
Best Practices in Data Labeling
Data labeling is critical to developing robust machine learning models. Your practices during this phase significantly impact the model's quality and efficacy. A key success factor is the choice of an annotation platform, particularly one with intuitive interfaces. These platforms enhance accuracy, efficiency, and the user experience in data labeling.
Intuitive Interfaces for Labelers
Providing labelers with intuitive and user-friendly interfaces is essential for efficient and accurate data labeling. Such interfaces reduce the likelihood of labeling errors, streamline the process, and improve the data annotation experience of users. Key features like clear instructions with ontologies, customizable workflows, and visual aids are integral to an intuitive interface.
For instance, Treeconomy's use of Encord for tree counting illustrates how a user-friendly interface can facilitate efficient labeling and integrate well with existing systems.
Label Auditing
Regularly validating labeled datasets is crucial for identifying and rectifying errors. It involves reviewing the labeled data to detect inconsistencies, inaccuracies, or potential biases. Auditing ensures that the labeled dataset is reliable and aligns with the intended objectives of the machine learning project.
A robust label auditing practice should possess:
- Quality metrics: To swiftly scan large datasets for errors.
- Customization options: Tailor assessments to specific project requirements.
- Traceability features: Track changes for transparency and accountability.
- Integration with workflows: Seamless integration for a smooth auditing process.
- Annotator management: Intuitive to manage and guide the annotators to rectify the errors
These attributes are features to look for in a label auditing tool. This process can be an invaluable asset in maintaining data integrity.
Active Learning Approaches
Active learning approaches, supported by intuitive platforms, improve data labeling efficiency. These approaches enable dynamic interaction between annotators and models. Unlike traditional methods, this strategy prioritizes labeling instances where the model is uncertain, optimizing human effort for challenging data points. This symbiotic interaction enhances efficiency, directing resources to refine the model's understanding in its weakest areas. Also, the iterative nature of active learning ensures continuous improvement, making the machine learning system progressively adept at handling diverse and complex datasets. This approach maximizes human annotator expertise and contributes to a more efficient, precise, and adaptive data labeling process.
Quality Control Measures With Encord
Encord stands out as a comprehensive solution, offering a suite of quality control measures designed to optimize every facet of the data labeling process. Here are a few quality measures:
Active Learning Optimization
Ensuring optimal model performance and facilitating iterative learning are paramount in machine learning projects. Encord's quality control measures include active learning optimization, a dynamic feature ensuring optimal model performance, and iterative learning. By dynamically identifying uncertain or challenging instances, the platform directs annotators to focus on specific data points, optimizing the learning process and enhancing model efficiency.
Addressing Annotation Consistency
Encord recognizes that consistency in annotations is paramount for high-quality labeled datasets. Addressing this, the platform meticulously labels data, have workflows to review the labels, and use label quality metrics for error identification. With a dedicated development team focus on minimizing labeling errors, Encord ensures annotations are reliable, delivering labeled data that is precisely aligned with project objectives.
Ensuring Data Accuracy
Validation and data quality assurance are the cornerstones of Encord's quality control framework. By implementing diverse data quality metrics and ontologies, our platform executes robust validation processes, safeguarding the accuracy of labeled data. This commitment ensures consistency and the highest standards of precision, fortifying the reliability of machine learning models.
Frequently asked questions
Accurate data labeling forms the foundation of machine learning, influencing model precision and performance. It ensures the creation of reliable datasets, essential for training robust algorithms.
Scalable data labeling faces hurdles in maintaining quality, consistency, and efficiency. Handling large datasets demands automated solutions, balancing speed and accuracy.
Active learning optimizes labeling by directing attention to uncertain instances, enhancing model learning iteratively, and improving efficiency in data annotation.
Industries like healthcare, autonomous vehicles, finance, and e-commerce benefit significantly, relying on precise data labeling for accurate model training.
Anticipate trends like increased automation, advanced AI-assisted labeling tools, and integration of innovative techniques for more efficient and accurate data annotation.
Data labeling is the cornerstone of AI and ML, providing labeled datasets necessary for training models and achieving accurate predictions.
Challenges include ensuring label accuracy, handling diverse data types, managing scalability, addressing bias, and maintaining consistency across annotations.
Data labeling impacts real-world applications by enhancing model accuracy, enabling precise predictions, and fostering advancements across industries such as healthcare, finance, and autonomous systems.
Encord stands out due to its comprehensive features that extend beyond traditional data annotation. It integrates data exploration, curation, and model evaluation into a single platform, facilitating a more streamlined machine learning operations pipeline. This holistic approach allows users to implement an active learning loop, enhancing the efficiency and cost-effectiveness of annotation operations.
Flexible ontologies in Encord allow users to customize their labeling specifications according to specific use cases, such as tracking plant growth, health, and performance. This flexibility helps in accurately capturing the nuances of different plant life stages throughout the annotation process.
Encord provides a robust annotation platform that streamlines labeling tasks, ensuring accuracy and compliance with regulatory requirements. Key features include user tracking for labeling, the ability to integrate multiple users for quality assurance, and exporting JSON files for data analysis.
The label validation flow in Encord is designed to help users verify the accuracy of pre-labeled data by allowing them to view and iterate through label instances. This feature facilitates the presentation of specific examples and ensures that labels have been imported correctly.
Encord provides flexible tools for configuring labeling classes and ontologies tailored to specific project needs. This allows teams to effectively manage their data annotation processes and ensure that the classifications align with their project requirements.
Encord provides a flexible data labeling platform that allows users to customize their workflows according to specific needs. This includes support for various use cases beyond traditional computer vision, accommodating unique requests from users.
Encord's platform supports the labeling of various data types, including audio files, video, and images. Each data type can be annotated according to specific ontologies and classes defined within the platform, allowing for versatile use cases.
Encord includes features for evaluating the quality of labeled data through separate QA stages. Users can review the outputs of the labeling process and ensure that the annotations meet the required standards before finalizing the results.
Setting up an ontology in Encord involves defining the specific categories and attributes relevant to your data. Users can create schematics that guide the labeling process, ensuring that the data is organized and categorized effectively.
Encord offers flexibility in defining labels through its ontology, allowing teams to use simple text captions, multiple choice options, or even nested text sections. This customization helps cater to diverse annotation needs.